Что такое машинное обучение
Что такое машинное обучение
Введение в машинное обучение
Обучение — это универсальный навык, который присущ любому живому организму на планете.
Обучение — это приобретение знаний и навыков посредством опыта или учебы. Это то, что нас объединяет и в то же время делает уникальными. Это то, что развивается с течением времени.

Что, если я скажу: «Машины тоже могут учиться»?
Мы живем в удивительное время развития роботизации, искусственного интеллекта и машинного обучения. Машинное обучение по-прежнему довольно новая концепция. Мы можем научить машины тому, как учиться, а некоторые машины могут учиться самостоятельно. Магия!
Эта статья познакомит вас с основами машинного обучения.
Самое главное, что вы должны понять: машины могут предсказывать будущее, основываясь на прошлом.
Что такое машинное обучение
Машинное обучение предполагает, что компьютер распознает шаблоны на примерах, а не программируется с помощью определенных правил. Эти шаблоны содержатся в данных.
Машинное обучение — создание алгоритмов (набора правил), которые учатся на сложных функциях (шаблонах) из данных и делает прогнозы.
Это происходит в 3 этапа:
1) Анализ данных
2) Нахождение шаблонов
3) Предсказание на основе шаблона
Применение машинного обучения
Краткий обзор, где можно использовать машинное обучение
Не хочу вас запутать, поэтому просто скажу, что машины учатся, находя похожие данные в больших массивах данных. Чем больше данных передается машине, тем «умнее» она становится.
Не все данные одинаковы. Представьте, что вы пират и ваша цель — найти клад где-то на острове. Для того, чтобы это сделать, понадобится большое количество информации. Как и данные, эта информация может вести вас либо в правильном направлении, либо в неправильном. Чем точнее полученная информация/данные, тем больше шансов на успех. Поэтому важно учитывать тип данных, с помощью которых будет проходить обучение.
Тем не менее, после достаточного объема данных, машина может делать прогнозы. Машины могут предсказывать будущее до тех пор, пока будущее не будет сильно отличаться от прошлого.
Типы машинного обучения
Существует три основные категории машинного обучения:
Supervised learning (обучение с учителем): Машина учится по выбранным данным. Обычно, данные отмечаются людьми.
Unsupervised learning (обучение без учителя): Машина учится не по выбранным данным. Смысл в том, что среди данных нет «правильного» ответа, машина должна найти зависимость между объектами.
Reinforcement learning (обучение с подкреплением): Машина учится через систему на основе вознаграждения.
1. Supervised learning (обучение с учителем)
Обучение с учителем — наиболее распространенный и изученный тип машинного обучения, ведь легче обучить машину с выбранными данными. В зависимости от того, что вы хотите предсказать, обучение с учителем может использоваться для решения двух типов задач: задача регрессии и задача классификации.
Задача регрессии:
Если вы хотите спрогнозировать непрерывные значения, например, попытаться спрогнозировать стоимость дома или погоду на улице в градусах, используйте регрессию. Этот тип задач не имеет определенного ограничения значений, поскольку значение может быть любым числом без ограничений.
Если требуется спрогнозировать дискретные значения, например классифицировать что-либо по категориям, используйте классификацию. Вопрос «Будет ли человек делать покупку», имеет ответ, который попадает в две конкретные категории: да или нет. Число допустимых ответов конечно.
2. Unsupervised learning (обучение без учителя)
Поскольку у машин нет отмеченных данных для обучения, цель машинного обучения без учителя — обнаружение закономерностей в данных и их группировка.
Обучение без учителя решает 2 типа задач: задача кластеризации и задача поиска ассоциациативных правил.
Обучение без учителя решает задачу кластеризации, находя сходства в данных. Если существует общий кластер или группа, алгоритм будет классифицировать их в определенной форме. Примером этого может быть группировка клиентов на основе их прошлых покупок.
Задача поиска ассоциациативных правил:
Обучение без учителя решает эту задачу, пытаясь понять правила и смысл разных групп. Яркий пример — поиск взаимосвязи между покупками клиентов. Магазины могут узнавать, какие продукты были приобретены вместе и использовать эту информацию для продаж. Одно исследование показало, что есть тесная взаимосвязь между покупкой пива и подгузников. Выяснилось, что мужчины, которые вышли купить подгузники для своих детей, также склонны покупать пиво для себя.
3. Reinforcement learning (обучение с подкреплением)
Этот тип машинного обучения требует использования системы вознаграждения/штрафа. Цель — вознаградить машину, когда она учится правильно, и наказать машину, когда она учится неправильно.
Примеры обучения с подкреплением
Мы рассказали об основах машинного обучения, тема интересная и перспективная, поэтому не жалейте времени, чтобы изучить подробнее.
Машинное обучение: просто о сложном
За последние 15 лет машинное обучение (machine learning, ML) получило широкое распространение, но большинство людей не до конца не осознает его роль в повседневной жизни. Многие из нас ежедневно используют приложения, в основе которых лежат технологии искусственного интеллекта (ИИ) и машинного обучения. Эти технологии уже стали причиной революции во многих отраслях, например, способствовали появлению виртуальных помощников, таких, как Siri или семейства виртуальных ассистентов Салют (Сбер, Джой, Афина), позволили осуществлять прогнозирование трафика с помощью Google Maps. Рассказываем простыми словами, что такое machine learning, что оно представляет из себя сегодня и какие преимущества способно обеспечить компаниям из разных сфер деятельности.
Что такое машинное обучение?
Машинное обучение — это специализированный способ, позволяющий обучать компьютеры, не прибегая к программированию. Отчасти это похоже на процесс обучения младенца, который учится самостоятельно классифицировать объекты и события, определять взаимосвязи между ними.
ML открывает новые возможности для компьютеров в решении задач, ранее выполняемых человеком, и обучает компьютерную систему составлению точных прогнозов при вводе данных. Оно стимулирует рост потенциала искусственного интеллекта, являясь его незаменимым помощником, а в представлении многих даже синонимом.
Наконец, машинное обучение — одна из наиболее распространенных форм применения искусственного интеллекта современным бизнесом. Если компания еще не использует ML, то в ближайшее время наверняка оценит его потенциал, а ИИ станет основным двигателем IT-стратегии многих предприятий. Ведь искусственный интеллект уже сегодня играет огромную роль в трансформации развития ИТ-индустрии: клиенты больше внимания уделяют интеллектуальным приложениям, чтобы развивать свой бизнес с помощью ИИ. Он применим к любому рабочему процессу, реализованному в программном обеспечении, — не только в рамках традиционной деловой части предприятий, но также в исследованиях, производственных процессах и, во все большей степени, самих продуктах.
Необычайный успех machine learning привел к тому, что исследователи и эксперты в области ИИ сегодня по умолчанию выбирают этот метод для решения задач.
Machine Learning: принципы и задачи
В основе машинного обучения лежат три одинаково важных компонента:
Доверие к результатам машинного обучения должно строиться на понимании: они хороши настолько, насколько хороши данные, на которых обучается алгоритм.
В основу существования и развития машинного обучения легли три основных принципа:
Задачи, которые способно решить машинное обучение, напрямую определяют выгоды для бизнеса и возможности решения социальных проблем государствами разных стран. К основным задачам относятся:
Как видим, спектр задач машинного обучения широк, что подтверждает его перспективность в использовании как коммерческими предприятиями, так и в социальных проектах.
Как это работает: типы машинного обучения
Для простоты восприятия типы машинного обучения принято разделять на три категории:
Обучение с учителем
Этот тип максимально похож на процесс познания окружающего мира ребенком, только в роли малыша выступает алгоритм. Данные, подготовленные для анализа, изначально содержат правильный ответ, поэтому цель алгоритма — не ответить, а понять, «Почему именно так?» путем выявления взаимосвязей. Результатом становится способность выстраивать корректные прогнозы и модели.
Обучение без учителя
Для данного типа обучения ключевым понятием является паттерн — обрабатывая значительные массивы данных, алгоритм должен сперва самостоятельно выявлять закономерности. На следующем этапе на основе выявленных закономерностей машина интерпретирует и систематизирует данные.
Обучение с подкреплением
Принципы обучения с подкреплением заимствованы из психологических экспериментов: машина пытается найти оптимальные действия, которые будет предпринимать, находясь в наборе различных сценариев. Эти действия могут иметь как краткосрочные, так и долгосрочные последствия, а от алгоритма требуется обнаружить эти связи.
Инструменты machine learning
Инструменты машинного обучения используют на следующих этапах:
Для выполнения каждого из этих этапов применяются специализированные платформы. Они различаются по языку программирования (Python, Cython, C, C++, CUDA, Java), операционным системам (Linux, Mac OS, Windows) и тому, какие задачи можно решить с их помощью.
Сегодня на рынке представлено несколько десятков программных инструментов:
Практическое применение ML-технологий
Машинное обучение уже применяется во всех сферах деятельности человека. Еще в 2017 году под управлением Стэнфордского университета был запущен новый индекс AI100 для отслеживания динамики в сфере ИИ. Согласно данным, полученным университетом, количество стартапов с 2000 по 2018 год выросло в 14 раз. Рассмотрим, в каких областях нас ждут технологические прорывы благодаря ML.
Робототехника
В будущем роботы станут самообучаться ранее поставленным перед ними задачам. К примеру, смогут работать над добычей полезных ископаемых — нефти, газа и других. Они смогут, например, изучать морские глубины, тушить пожары. Программисты могут самостоятельно не писать массивные и сложные программы, опасаясь допустить ошибку в коде. ИИ повлияет и на повышение качества частной жизни человека: у нас уже есть беспилотные автомобили, роботы-пылесосы, трекеры сна, физической активности и здоровья и прочие продукты интернета поведения.
Маркетинг
Самый наглядный пример использования машинного обучения в маркетинге — поисковые системы Google и Яндекс, которые с его помощью контролируют релевантность рекламных объявлений.Социальные сети FaceBook, ВКонтакте, Instagram и другие применяют собственные аналитические машины для исследования интересов пользователей и совершенствования персонализации новостной ленты.Маркетинговые исследования, предваряющие разработку и релиз продуктов компании, станут проще с точки зрения реализации, а итоговые данные будут более точными. Выделение кластеров в группах со схожими параметрами превратит кастомизированные предложения в реальность — можно будет решать задачи не групп потребителей, а каждого в отдельности.
Безопасность
Современную сферу обеспечения безопасности невозможно представить без машинного обучения. Системы распознавания лиц в метро и использование камер, сканирующих лица и номера машин при движении по автодорогам, стали неотъемлемой частью человеческой жизни и незаменимыми помощниками для полиции в поиске преступников и потерявшихся людей.
Финансовый сектор и страхование
Более точные биржевые прогнозы и оценка капитализации брендов, решения о выдаче кредитных продуктов частным лицам и предприятиям, определение стоимости и целесообразности страховки и даже снижение очередей в офисах при параллельном сокращении издержек на персонал — только часть возможностей, которые станут доступны в этой сфере.
Общественное питание
На основе Big Data разрабатываются специальные предложения для гостей с учетом загрузки посадочных мест в ресторанах и кафе, функционируют сервисы по планированию закупок для поваров.
Примечание
Воронежская пивоварня Brewlok и разработчики из NewShift решили использовать возможности Big Data для разработки рецепта идеального пива. На протяжении месяца они собирали отзывы и выделяли критерии оценки вкуса, аромата и цвета. На основе полученных данных из почти двух с половиной тысяч отзывов аналитики сформулировали описание «идеального пива», которое легло в основу рецепта.
Медицина
В медицинских учреждениях машинное обучение позволяет быстро обрабатывать данные пациента, производить предварительную диагностику и подобрать индивидуальное лечение, опираясь на сведения о заболеваниях пациента из базы данных. ML также позволяет автоматически выделять группы риска при появлении новых штаммов вирусных заболеваний.
Добыча полезных ископаемых
Анализ почвы доказывает или опровергает наличие полезных ископаемых, помогает очертить площадь будущей разработки.
Серьезным препятствием для повсеместного использования технологий машинного обучения был недостаток у значительного количества компаний финансовых ресурсов и инфраструктуры. Специалисты SberCloud разработал ML Space — платформу для ML-разработки полного цикла и совместной работы Data Science-команд над созданием и развертыванием моделей машинного обучения. Сервис предоставляет уникальную возможность эффективного внедрения машинного обучения в бизнес-процессы.
Резюме
Технологии машинного обучения уже стали частью повседневной жизни, при этом количество стартапов и продуктов на основе машинного обучения активно растет. Будучи причиной технологических революций в некоторых сферах экономики, ML способно быть драйвером в масштабах бизнеса и государств. Сегодня самое время задуматься об интеграции машинного обучения в бизнес-процессы, чтобы не утратить конкурентоспособность.
Технологии искусственного интеллекта и машинного обучения уже определяют экономический успех предприятий. По данным консалтинговой компании Gartner порядка 50% процессов в сфере обработки и анализа данных будут автоматизированы с помощью ИИ к 2025 году, что снизит острую нехватку высококвалифицированных специалистов. Компания SberCloud следует самым современным трендам. ИИ является неотъемлемой частью разработки наших продуктов и услуг. SberCloud располагает достаточными материальными ресурсами: это и самый мощный в России суперкомпьютер “Кристофари”, облачная инфраструктура и платформа ML Space. Платформа позволяет ускорить, оптимизировать и упростить процесс обучения моделей, препроцессинга данных и развертывания моделей на высокопроизводительной инфраструктуре с целью последующего обращения к этим моделям для распознавания или прогнозирования по новым данным. Сегодня ML Space — это единственная в мире облачная платформа, позволяющая обучать модели более чем на 1000 графических процессоров (GPU) Мария Рябенко Старший технический писатель направления AI Cloud
Что такое Machine Learning и каким оно бывает
Что такое машинное обучение
Machine Learning (ML, с английского – машинное обучение) — это методики анализа данных, которые позволяют аналитической системе обучаться в ходе решения множества сходных задач. Машинное обучение базируется на идее о том, что аналитические системы могут учиться выявлять закономерности и принимать решения с минимальным участием человека.
Давайте представим, что существует программа, которая может проанализировать погоду за прошедшую неделю, а также показания термометра, барометра и анемометра (ветрометра), чтобы составить прогноз. 10 лет назад для этого написали бы алгоритм с большим количеством условных конструкций If (если):
От программиста требовалось описать невероятное количество условий, чтобы код мог предсказывать изменение погоды. В лучшем случае использовался многомерный анализ данных, но и в нем все закономерности указывались вручную. Но даже если такую программу называли искусственным интеллектом, это была лишь имитация.

Большая часть программ с искусственным интеллектом на самом деле состоит из условных конструкций
Машинное обучение же позволяет дать программе возможность самостоятельно строить причинно-следственные связи. ИИ получает задачу и сам учится ее решать. То есть компьютер может проанализировать показатели за несколько месяцев или даже лет, чтобы определить, какие факторы оказывали влияние на изменение погоды.
Вот хороший пример от гугловского DeepMind:

DeepMind от Google самостоятельно научился ходить
Программа получала информацию от виртуальных рецепторов, а ее целью было перевести модель из точки А в точку Б. Никаких инструкций по этому поводу не было – разработчики лишь создали алгоритм, по которому программа обучалась. В результате она смогла самостоятельно выполнить задачу.
ИИ, словно ребенок, пробовал разные методы, чтобы найти тот, который лучше всего поможет добиться результата. Также он учитывал особенности моделей, заставляя четвероногую прыгать, человекообразную – бежать. Также ИИ смог балансировать на двигающихся плитах, обходить препятствия и перемещаться по бездорожью.
Для чего используется машинное обучение
В примере выше описывалась ходьба – это поможет человечеству создавать обучаемых роботов, которые смогут адаптироваться, чтобы выполнять поставленные задачи. Например, тушить пожары, разбирать завалы, добывать руду и так далее. В этих случаях машинное обучение гораздо эффективнее, чем обычная программа, потому что человек может допустить ошибку во время написания кода, из-за чего робот может впасть в ступор, потому что не знает, как взаимодействовать с камнем той формы, которую не прописал разработчик.
Но до этого пройдет еще несколько лет или даже десятилетий. А что же сейчас? Разве машинное обучение еще не начали использовать для решения практических задач? Начали, технология широко используется в области data science (науки о данных). И чаще всего эти задачи маркетинговые.
Amazon использует ИИ с машинным обучением, чтобы предлагать пользователям тот товар, который они купят с наибольшей вероятностью. Для этого программа анализирует опыт других пользователей, чтобы применить его к новым. Но пока у системы есть свои недостатки – купив однажды шапку, пользователь будет видеть предложения купить еще. Программа сделает вывод, что раз была нужна одна шапка, то и несколько сотен других не повредят.
Похожую систему использует Google, чтобы подбирать релевантную рекламу, и у него такие же проблемы – стоит поискать информацию о том, какие виды велосипедов бывают, как Google тут же решит, что пользователь хочет погрузиться в эту тему с головой. Тем же самым занимается и «Яндекс» в своем сервисе «Дзен» – там МО используется для формирования ленты, точно так же, как и в Twitter, Instagram, Facebook, «ВКонтакте» и других социальных сетях.
Вы также могли работать с голосовыми помощниками вроде Siri – они используют системы распознавания речи, основанные на ML. В будущем они могут заменить секретарей и операторов кол-центров. Если вы загорелись этой идеей, можете попробовать сервис аудиоаналитики Sounds от VK.
Есть и другие примеры использования систем с машинным обучением:
То есть применение МО может быть самым разным. И даже вы можете использовать его в своих приложениях – для этого понадобится приобрести, настроить и поддерживать инфраструктуру обучения машинных моделей. Альтернатива — воспользоваться готовыми средствами машинного обучения на платформе VK Cloud (бывш. MCS).
Введение в машинное обучение
1.1 Введение
Благодаря машинному обучению программист не обязан писать инструкции, учитывающие все возможные проблемы и содержащие все решения. Вместо этого в компьютер (или отдельную программу) закладывают алгоритм самостоятельного нахождения решений путём комплексного использования статистических данных, из которых выводятся закономерности и на основе которых делаются прогнозы.
Технология машинного обучения на основе анализа данных берёт начало в 1950 году, когда начали разрабатывать первые программы для игры в шашки. За прошедшие десятилетий общий принцип не изменился. Зато благодаря взрывному росту вычислительных мощностей компьютеров многократно усложнились закономерности и прогнозы, создаваемые ими, и расширился круг проблем и задач, решаемых с использованием машинного обучения.
Чтобы запустить процесс машинного обучение, для начала необходимо загрузить в компьютер Датасет(некоторое количество исходных данных), на которых алгоритм будет учиться обрабатывать запросы. Например, могут быть фотографии собак и котов, на которых уже есть метки, обозначающие к кому они относятся. После процесса обучения, программа уже сама сможет распознавать собак и котов на новых изображениях без содержания меток. Процесс обучения продолжается и после выданных прогнозов, чем больше данных мы проанализировали программой, тем более точно она распознает нужные изображения.
Благодаря машинному обучению компьютеры учатся распознавать на фотографиях и рисунках не только лица, но и пейзажи, предметы, текст и цифры. Что касается текста, то и здесь не обойтись без машинного обучения: функция проверки грамматики сейчас присутствует в любом текстовом редакторе и даже в телефонах. Причем учитывается не только написание слов, но и контекст, оттенки смысла и другие тонкие лингвистические аспекты. Более того, уже существует программное обеспечение, способное без участия человека писать новостные статьи (на тему экономики и, к примеру, спорта).
1.2 Типы задач машинного обучения
Все задачи, решаемые с помощью ML, относятся к одной из следующих категорий.
1)Задача регрессии – прогноз на основе выборки объектов с различными признаками. На выходе должно получиться вещественное число (2, 35, 76.454 и др.), к примеру цена квартиры, стоимость ценной бумаги по прошествии полугода, ожидаемый доход магазина на следующий месяц, качество вина при слепом тестировании.
2)Задача классификации – получение категориального ответа на основе набора признаков. Имеет конечное количество ответов (как правило, в формате «да» или «нет»): есть ли на фотографии кот, является ли изображение человеческим лицом, болен ли пациент раком.
3)Задача кластеризации – распределение данных на группы: разделение всех клиентов мобильного оператора по уровню платёжеспособности, отнесение космических объектов к той или иной категории (планета, звёзда, чёрная дыра и т. п.).
4)Задача уменьшения размерности – сведение большого числа признаков к меньшему (обычно 2–3) для удобства их последующей визуализации (например, сжатие данных).
5)Задача выявления аномалий – отделение аномалий от стандартных случаев. На первый взгляд она совпадает с задачей классификации, но есть одно существенное отличие: аномалии – явление редкое, и обучающих примеров, на которых можно натаскать машинно обучающуюся модель на выявление таких объектов, либо исчезающе мало, либо просто нет, поэтому методы классификации здесь не работают. На практике такой задачей является, например, выявление мошеннических действий с банковскими картами.
1.3 Основные виды машинного обучения
Основная масса задач, решаемых при помощи методов машинного обучения, относится к двум разным видам: обучение с учителем (supervised learning) либо без него (unsupervised learning). Однако этим учителем вовсе не обязательно является сам программист, который стоит над компьютером и контролирует каждое действие в программе. «Учитель» в терминах машинного обучения – это само вмешательство человека в процесс обработки информации. В обоих видах обучения машине предоставляются исходные данные, которые ей предстоит проанализировать и найти закономерности. Различие лишь в том, что при обучении с учителем есть ряд гипотез, которые необходимо опровергнуть или подтвердить. Эту разницу легко понять на примерах.
Машинное обучение с учителем
Предположим, в нашем распоряжении оказались сведения о десяти тысячах московских квартир: площадь, этаж, район, наличие или отсутствие парковки у дома, расстояние от метро, цена квартиры и т. п. Нам необходимо создать модель, предсказывающую рыночную стоимость квартиры по её параметрам. Это идеальный пример машинного обучения с учителем: у нас есть исходные данные (количество квартир и их свойства, которые называются признаками) и готовый ответ по каждой из квартир – её стоимость. Программе предстоит решить задачу регрессии.
Ещё пример из практики: подтвердить или опровергнуть наличие рака у пациента, зная все его медицинские показатели. Выяснить, является ли входящее письмо спамом, проанализировав его текст. Это всё задачи на классификацию.
Машинное обучение без учителя
В случае обучения без учителя, когда готовых «правильных ответов» системе не предоставлено, всё обстоит ещё интереснее. Например, у нас есть информация о весе и росте какого-то количества людей, и эти данные нужно распределить по трём группам, для каждой из которых предстоит пошить рубашки подходящих размеров. Это задача кластеризации. В этом случае предстоит разделить все данные на 3 кластера (но, как правило, такого строгого и единственно возможного деления нет).
Если взять другую ситуацию, когда каждый из объектов в выборке обладает сотней различных признаков, то основной трудностью будет графическое отображение такой выборки. Поэтому количество признаков уменьшают до двух или трёх, и становится возможным визуализировать их на плоскости или в 3D. Это – задача уменьшения размерности.
1.4 Основные алгоритмы моделей машинного обучения
1. Дерево принятия решений
Это метод поддержки принятия решений, основанный на использовании древовидного графа: модели принятия решений, которая учитывает их потенциальные последствия (с расчётом вероятности наступления того или иного события), эффективность, ресурсозатратность.
Для бизнес-процессов это дерево складывается из минимального числа вопросов, предполагающих однозначный ответ — «да» или «нет». Последовательно дав ответы на все эти вопросы, мы приходим к правильному выбору. Методологические преимущества дерева принятия решений – в том, что оно структурирует и систематизирует проблему, а итоговое решение принимается на основе логических выводов.
2. Наивная байесовская классификация
Наивные байесовские классификаторы относятся к семейству простых вероятностных классификаторов и берут начало из теоремы Байеса, которая применительно к данному случаю рассматривает функции как независимые (это называется строгим, или наивным, предположением). На практике используется в следующих областях машинного обучения:
Всем, кто хоть немного изучал статистику, знакомо понятие линейной регрессии. К вариантам её реализации относятся и наименьшие квадраты. Обычно с помощью линейной регрессии решают задачи по подгонке прямой, которая проходит через множество точек. Вот как это делается с помощью метода наименьших квадратов: провести прямую, измерить расстояние от неё до каждой из точек (точки и линию соединяют вертикальными отрезками), получившуюся сумму перенести наверх. В результате та кривая, в которой сумма расстояний будет наименьшей, и есть искомая (эта линия пройдёт через точки с нормально распределённым отклонением от истинного значения).
Линейная функция обычно используется при подборе данных для машинного обучения, а метод наименьших квадратов – для сведения к минимуму погрешностей путем создания метрики ошибок.
4. Логистическая регрессия
Логистическая регрессия – это способ определения зависимости между переменными, одна из которых категориально зависима, а другие независимы. Для этого применяется логистическая функция (аккумулятивное логистическое распределение). Практическое значение логистической регрессии заключается в том, что она является мощным статистическим методом предсказания событий, который включает в себя одну или несколько независимых переменных. Это востребовано в следующих ситуациях:
Это целый набор алгоритмов, необходимых для решения задач на классификацию и регрессионный анализ. Исходя из того что объект, находящийся в N-мерном пространстве, относится к одному из двух классов, метод опорных векторов строит гиперплоскость с мерностью (N – 1), чтобы все объекты оказались в одной из двух групп. На бумаге это можно изобразить так: есть точки двух разных видов, и их можно линейно разделить. Кроме сепарации точек, данный метод генерирует гиперплоскость таким образом, чтобы она была максимально удалена от самой близкой точки каждой группы.
SVM и его модификации помогают решать такие сложные задачи машинного обучения, как сплайсинг ДНК, определение пола человека по фотографии, вывод рекламных баннеров на сайты.
6. Метод ансамблей
Он базируется на алгоритмах машинного обучения, генерирующих множество классификаторов и разделяющих все объекты из вновь поступающих данных на основе их усреднения или итогов голосования. Изначально метод ансамблей был частным случаем байесовского усреднения, но затем усложнился и оброс дополнительными алгоритмами:
Кластеризация заключается в распределении множества объектов по категориям так, чтобы в каждой категории – кластере – оказались наиболее схожие между собой элементы.
Кластеризировать объекты можно по разным алгоритмам. Чаще всего используют следующие:
8. Метод главных компонент (PCA)
Метод главных компонент, или PCA, представляет собой статистическую операцию по ортогональному преобразованию, которая имеет своей целью перевод наблюдений за переменными, которые могут быть как-то взаимосвязаны между собой, в набор главных компонент – значений, которые линейно не коррелированы.
Практические задачи, в которых применяется PCA, – визуализация и большинство процедур сжатия, упрощения, минимизации данных для того, чтобы облегчить процесс обучения. Однако метод главных компонент не годится для ситуаций, когда исходные данные слабо упорядочены (то есть все компоненты метода характеризуются высокой дисперсией). Так что его применимость определяется тем, насколько хорошо изучена и описана предметная область.
9. Сингулярное разложение
В линейной алгебре сингулярное разложение, или SVD, определяется как разложение прямоугольной матрицы, состоящей из комплексных или вещественных чисел. Так, матрицу M размерностью [m*n] можно разложить таким образом, что M = UΣV, где U и V будут унитарными матрицами, а Σ – диагональной.
Одним из частных случаев сингулярного разложения является метод главных компонент. Самые первые технологии компьютерного зрения разрабатывались на основе SVD и PCA и работали следующим образом: вначале лица (или другие паттерны, которые предстояло найти) представляли в виде суммы базисных компонент, затем уменьшали их размерность, после чего производили их сопоставление с изображениями из выборки. Современные алгоритмы сингулярного разложения в машинном обучении, конечно, значительно сложнее и изощрённее, чем их предшественники, но суть их в целом нем изменилась.
10. Анализ независимых компонент (ICA)
Это один из статистических методов, который выявляет скрытые факторы, оказывающие влияние на случайные величины, сигналы и пр. ICA формирует порождающую модель для баз многофакторных данных. Переменные в модели содержат некоторые скрытые переменные, причем нет никакой информации о правилах их смешивания. Эти скрытые переменные являются независимыми компонентами выборки и считаются негауссовскими сигналами.
В отличие от анализа главных компонент, который связан с данным методом, анализ независимых компонент более эффективен, особенно в тех случаях, когда классические подходы оказываются бессильны. Он обнаруживает скрытые причины явлений и благодаря этому нашёл широкое применение в самых различных областях – от астрономии и медицины до распознавания речи, автоматического тестирования и анализа динамики финансовых показателей.
1.5 Примеры применения в реальной жизни
Пример 1. Диагностика заболеваний
Пациенты в данном случае являются объектами, а признаками – все наблюдающиеся у них симптомы, анамнез, результаты анализов, уже предпринятые лечебные меры (фактически вся история болезни, формализованная и разбитая на отдельные критерии). Некоторые признаки – пол, наличие или отсутствие головной боли, кашля, сыпи и иные – рассматриваются как бинарные. Оценка тяжести состояния (крайне тяжёлое, средней тяжести и др.) является порядковым признаком, а многие другие – количественными: объём лекарственного препарата, уровень гемоглобина в крови, показатели артериального давления и пульса, возраст, вес. Собрав информацию о состоянии пациента, содержащую много таких признаков, можно загрузить её в компьютер и с помощью программы, способной к машинному обучению, решить следующие задачи:
Пример 2. Поиск мест залегания полезных ископаемых
В роли признаков здесь выступают сведения, добытые при помощи геологической разведки: наличие на территории местности каких-либо пород (и это будет признаком бинарного типа), их физические и химические свойства (которые раскладываются на ряд количественных и качественных признаков).
Для обучающей выборки берутся 2 вида прецедентов: районы, где точно присутствуют месторождения полезных ископаемых, и районы с похожими характеристиками, где эти ископаемые не были обнаружены. Но добыча редких полезных ископаемых имеет свою специфику: во многих случаях количество признаков значительно превышает число объектов, и методы традиционной статистики плохо подходят для таких ситуаций. Поэтому при машинном обучении акцент делается на обнаружение закономерностей в уже собранном массиве данных. Для этого определяются небольшие и наиболее информативные совокупности признаков, которые максимально показательны для ответа на вопрос исследования – есть в указанной местности то или иное ископаемое или нет. Можно провести аналогию с медициной: у месторождений тоже можно выявить свои синдромы. Ценность применения машинного обучения в этой области заключается в том, что полученные результаты не только носят практический характер, но и представляют серьёзный научный интерес для геологов и геофизиков.
Пример 3. Оценка надёжности и платёжеспособности кандидатов на получение кредитов
С этой задачей ежедневно сталкиваются все банки, занимающиеся выдачей кредитов. Необходимость в автоматизации этого процесса назрела давно, ещё в 1960–1970-е годы, когда в США и других странах начался бум кредитных карт.
Лица, запрашивающие у банка заём, – это объекты, а вот признаки будут отличаться в зависимости от того, физическое это лицо или юридическое. Признаковое описание частного лица, претендующего на кредит, формируется на основе данных анкеты, которую оно заполняет. Затем анкета дополняется некоторыми другими сведениями о потенциальном клиенте, которые банк получает по своим каналам. Часть из них относятся к бинарным признакам (пол, наличие телефонного номера), другие — к порядковым (образование, должность), большинство же являются количественными (величина займа, общая сумма задолженностей по другим банкам, возраст, количество членов семьи, доход, трудовой стаж) или номинальными (имя, название фирмы-работодателя, профессия, адрес).
Для машинного обучения составляется выборка, в которую входят кредитополучатели, чья кредитная история известна. Все заёмщики делятся на классы, в простейшем случае их 2 – «хорошие» заёмщики и «плохие», и положительное решение о выдаче кредита принимается только в пользу «хороших».
Более сложный алгоритм машинного обучения, называемый кредитным скорингом, предусматривает начисление каждому заёмщику условных баллов за каждый признак, и решение о предоставлении кредита будет зависеть от суммы набранных баллов. Во время машинного обучения системы кредитного скоринга вначале назначают некоторое количество баллов каждому признаку, а затем определяют условия выдачи займа (срок, процентную ставку и остальные параметры, которые отражаются в кредитном договоре). Но существует также и другой алгоритм обучения системы – на основе прецедентов.
Введение в машинное обучение
Полный курс на русском языке можно найти по этой ссылке.
Оригинальный курс на английском доступен по этой ссылке.

Выход новых лекций запланирован каждые 2-3 дня.
Интервью с Себастьяном Труном, CEO Udacity
— И снова всем привет, с вами я, Пейдж и сегодня со мной гость — Себастьян.
— Привет, я Себастьян!
— … человек у которого невероятная карьера, успевшего сделать множество потрясающих вещей! Вы являетесь со-основателем Udacity, вы основали Google X, вы професcор в Стэнфорде. Вы занимались невероятными исследованиями и глубоким обучением на всём протяжении своей карьеры. Что приносило вам наибольшее удовлетворение и в какой из областей вы получали наибольшее вознаграждение за проделанную работу?
— Скажу честно, я очень люблю находиться в Кремниевой долине! Мне нравится находится рядом с людьми, которые значительно умнее меня, и я всегда рассматривал технологии, как инструмент менющий правила игры различными способами — начиная от образования и заканчивая логистикой, здравохранением и т.д. Всё это меняется настолько быстро, и возникает невероятное желание быть участником этих изменений, наблюдать за ними. Ты смотришь на окружающее тебя и понимаешь, что большинство из того, что ты видишь вокруг, не работает так, как это должно — всегда можно изобрести нечто новое!
— Ну что ж, это очень оптимистичный взгляд на технологии! Какой момент на протяжении всей вашей карьеры был самой большой «эврикой»?
— Господи, их было так много! Помню один из дней, когда Ларри Пейдж позвонил мне и предложил создать автопилотируемые автомобили, которые смогли бы проезжать по всем улицам Калифорнии. В то время я считался экспертом, меня к таковым причисляли и, я был тем самым человеком, который сказал «нет, этого нельзя сделать». После этого Ларри убедил меня, что, в принципе, это возможно сделать, стоит только начать и сделать попытку. И мы сделали это! Это был момент, когда я осознал, что даже эксперты ошибаются и говоря «нет» мы на 100% становимся пессимистами. Я думаю мы должны быть более открыты новому.
— Или, например, если вам звонит Ларри Пейдж и говорит, — «Хэй, сделай крутую вещь вроде Google X» и получается нечто достаточно крутое!
— Да, это точно, жаловаться не приходится! Я имею ввиду, что всё это — процесс, который проходит через множество обсуждений на пути к реализации. Мне, действительно, повезло работать и я горжусь этим, в Google X и над другими проектами.
— Потрясающе! Итак, этот курс полностью о работе с TensorFlow. У вас есть опыт использования TensorFlow или может быть вы знакомы (слышали) с ним?
— Да! Я, в буквальном смысле, люблю TensorFlow, конечно! В моей собственной лаборатории мы используем его часто и много, одна из самых значимых работ на основе TensorFlow вышла около двух лет назад. Мы узнали, что iPhone и Android могут быть эффективнее в определении рака кожи, чем лучшие дерматологи в мире. Своё исследование мы опубликовали в Nature и это произвело своего рода переполох в медицине.
— Звучит потрясающе! Значит вы знаете и любите TensorFlow, что само по себе здорово! Вы уже успели поработать с TensorFlow 2.0?
— Нет, к сожалению пока не успел.
— Он будет просто восхитителен! Все студенты этого курса будут работать с этой версией.
— Я завидую им! Обязательно попробую!
— Прекрасно! На нашем курсе очень много студентов, которые в своей жизни ни разу не занимались машинным обучение, от слова «совсем». Для них область может быть нова, возможно для кого-то само программирование будет вновинку. Какой у вас совет для них?
— Я бы пожелал им оставаться открытыми — к новым идеям, методикам, решениям, позициям. Машинное обучение, на самом деле, проще, чем программирование. В процессе программирования вам необходимо учитывать каждый случай в исходных данных, адаптировать под него логику программы и правила. В это самое время, используя TensorFlow и машинное обучение вы, по сути, тренируете компьютер используя примеры, предоставляя компьютеру самому находить правила.
— Это невероятно интересно! Мне не терпится рассказать студентам этого курса немного больше о машинном обучении! Себастьян, благодарю, что нашел время и пришёл сегодня к нам!
— Благодарю! Оставайтесь на связи!
Что такое машинное обучение?
Итак, давайте начнём со следующей задачи — даны входные и выходные значения.

Когда в качестве входного значения у вас значение 0, то в качестве выходного значения — 32. Когда в качестве входного значения у вас 8, то в качестве выходного значения — 46.4. Когда в качестве входного значения у вас 15, то в качестве выходного значения — 59 и так далее.
Присмотритесь к этим значениям и позвольте мне задать вам вопрос. Можете ли вы определить, каким будет выходное значение, если на входе мы получим 38?

Если вы ответили 100.4, то оказались правы!

Итак, как мы могли решить эту задачу? Если присмотреться внимательнее к значениям, то можно заметить, что они связаны выражением:

Где С — градусы Цельсия (входные значения), F — Фаренгейта (выходные значения).
То, что сейчас сделал ваш мозг — сопоставил входные значения и выходные значения и нашел общую модель (связь, зависимость) между ними, — именно это и делает машинное обучение.
По входным и выходным значениям алгоритмы машинного обучения найдут подходящий алгоритм преобразования входных значений в выходные. Это можно представить следующим образом:


Решение, при подходе с точки зрения традиционной разработки программного обеспечения, может быть реализовано на любом языке программирования с использованием функции:

Итак, что мы имеем? Функция принимает входное значение C, затем вычисляет выходное значение F используя явно заданный алгоритм, а затем возвращает вычисленное значение.
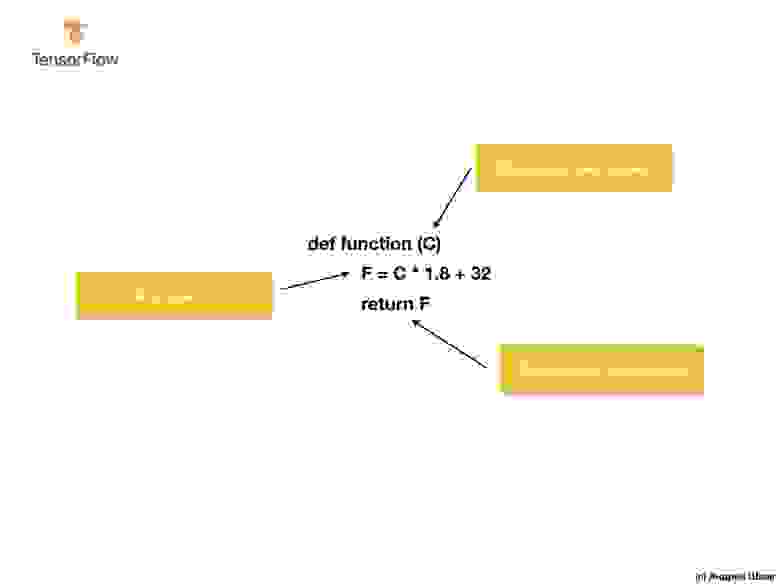
С другой стороны, в подходе с машинным обучением, у нас есть только входные и выходные значения, но не сам алгоритм:

Подход с машинным обучением основывается на использовании нейронных сетей для нахождения отношений между входными и выходными значениями.

Вы можете думать о нейронных сетях, как о стопке слоёв, каждый из которых состоит из заранее известной математики (формул) и внутренних переменных. Входное значение поступает в нейронную сеть и проходит сквозь стопку слоёв нейронов. Во время прохождения через слои, входное значение преобразовывается согласно математике (заданным формулам) и значениям внутренних переменных слоёв, производя выходное значение.
Для того, чтобы нейронная сеть смогла обучиться и определить правильные отношения между входными и выходными значениями, нам необходимо её обучить — натренировать.
Мы тренируем нейронную сеть через повторяющиеся попытки сопоставить входные значения выходным.

В процессе тренировки происходит «подгонка» (подбор) значений внутренних переменных в слоях нейронной сети до тех пор, пока сеть не научится генерировать соответствующие выходные значения соответствующим входным значениям.
Как мы увидим в последующем, для того чтобы обучить нейронную сеть и позволить ей подобрать наиболее подходящие значения внутренних переменных, производят тысячи или десятки тысяч итераций (тренировок).

В качестве упрощенного варианта понимания машинного обучения вы можете представить себе алгоритмы машинного обучения как функции, которые подбирают значения внутренних переменных таким образом, чтобы соответствующим входным значениям соответствовали корректные выходные значения.
Существует множество типов архитектур нейронных сетей. Однако, вне зависимости от того, какую архитектуру вы выберете, математика внутри (какие вычисления выполняются и в каком порядке) останется неизменной в процессе тренировки. Вместо изменения математики, меняются внутренние переменные (веса и смещения) во время тренировки.
Например, в задаче конвертации из градусов Цельсия в Фаренгейты, модель начинает с умножения входного значения на некоторое число (вес) и добавления другого значения (смещения). Обучение модели заключается в нахождении подходящих значений для этих переменных, без изменения выполняемых операций умножения и сложения.
А вот одна крутая вещь над которой стоит задуматься! Если вы решили задачу преобразования градусов Цельсия в Фаренгейты, которая обозначена в видео и в тексте ниже, вы, вероятно, решили её потому, что обладали неким предыдущим опытом или знанием, как производить подобного рода преобразования из градусов Цельсия в Фаренгейты. Например, вы могли просто знать, что 0 градусов Цельсия соответствуют 32 градусам по Фаренгейту. С другой стороны, системы основанные на машинном обучении не обладают предыдущими вспомогательными знаниями для решения поставленной задачи. Они учатся решать подобного рода задачи не основываясь на предыдущих знаниях и при их полном отсутствии.
Довольно разговоров — переходим к практической части лекции!
CoLab: преобразуем градусы Цельсия в градусы Фаренгейта
Основы: обучение первой модели
Добро пожаловать в CoLab, где мы будем тренировать нашу первую модель машинного обучения!
Мы постараемся сохранять простоту преподносимого материала и ввести только базовые понятия необходимые для работы. Последующие CoLabs будут содержать более продвинутые техники.
Задача, которую мы будем решать — преобразование градусов Цельсия в градусы Фаренгейта. Формула преобразования выглядит следующим образом:

Безусловно, было бы проще просто написать функцию конвертации на Python или любом другом языке программирования, которая бы выполняла непосредственные вычисления, но в таком случае это не было бы машинным обучением 🙂
Вместо этого мы подадим на вход TensorFlow имеющиеся у нас входные значения градусов Цельсия (0, 8, 15, 22, 38) и их соответствующие градусы по Фаренгейту (32, 46, 59, 72, 100). Затем мы натренируем модель таким образом, чтобы та примерно соответствовала приведённой выше формуле.
Импорт зависимостей
Подготовка данных для тренировки
Создаём модель
Строим сеть
Мы назовём слой l0 (layer и ноль) и создадим его, инициализировав tf.keras.layers.Dense со следующими параметрами:
Преобразуем слои в модель
Примечание
Достаточно часто вы будете сталкиваться с определением слоёв прямо в функции модели, нежели с их предварительным описанием и последующим использованием:
Компилируем модель с функцией потерь и оптимизаций
Перед тренировкой модель должна быть скомпилирована (собрана). При компиляции для тренировки необходимы:
Функция потерь и функция оптимизации используются во время тренировки модели ( model.fit(. ) упоминаемая ниже) для выполнения первичных вычислений в каждой точке и последующей оптимизации значений.
Действие вычисления текущих потерь и последующее улучшение этих значений в модели — это именно то, чем является тренировка (одна итерация).
Во время тренировки, функция оптимизации используется для подсчета корректировок значений внутренних переменных. Цель — подогнать значения внутренних переменных таким образом в модели (а это, по сути, математическая функция), чтобы те отражали максимально приближённо существующее выражение конвертации градусов Цельсия в градусы Фаренгейта.
TensorFlow использует численный анализ для выполнения подобного рода операций оптимизации и вся эта сложность скрыта от наших глаз, поэтому мы не будем вдаваться в детали в этом курсе.
Что полезно знать об этих параметрах:
Функция потерь (среднеквадратичная ошибка) и функция оптимизации (Adam), используемые в этом примере, являются стандартными для подобных простых моделей, но кроме них доступно множество других. На данном этапе нам не важно каким образом работают эти функции.
Тренируем модель
Во время тренировки модель получает на вход значения градусов Цельсия, выполняет преобразования используя значения внутренних переменных (называемые «весами») и возвращает значения, которые должны соответствовать градусами по Фаренгейту. Так как первоначальные значения весов установлены произвольными, то и результатирующие значения будут далеки от корректных значений. Разница между необходимым результатом и фактическим вычисляется с использованием функции потерь, а функция оптимизации определяет каким образом должны быть подкорректированы веса.
Отображаем статистику тренировок

Используем модель для предсказаний
Теперь у нас есть модель, которая была обучена на входных значениях celsius_q и выходных значениях fahrenheit_a для определения взаимосвязи между ними. Мы можем воспользоваться методом предсказания для вычисления тех значений градусов Фаренгейта по которым ранее нам неизвестны были соответствующие градусы Цельсия.
Например, сколько будет 100.0 градусов Цельсия по Фаренгейту? Попробуйте угадать перед тем как запускать код ниже.
Правильный ответ 100×1.8+32=212, так что наша модель справилась достаточно хорошо!
Смотрим на веса
Значение первой переменной близко к
32. Эти значения (1.8 и 32) являются непосредственными значениями в формуле конвертации градусов Цельсия в градусы Фаренгейта.
Так как представления одинаковые, то и значения внутренних переменных модели должны были сойтись к тем, которые представлены в фактической формуле, что и произошло в итоге.
При наличии дополнительных нейронов, дополнительных входных значений и выходных значений, формула становится немного сложнее, но суть остаётся той же.
Немного экспериментов
Как вы могли уже заметить, текущая модель тоже способна достаточно хорошо предсказывать соответствующие значения градусов Фаренгейта. Однако, если взглянуть на значения внутренних переменных (веса) нейронов по слоям, то никаких значений похожих на 1.8 и 32 мы уже не увидим. Добавленная сложность модели скрывает «простую» форму преобразования градусов Цельсия в градусы Фаренгейта.
Оставайся на связи и в следующей части мы рассмотрим то, каким образом работают Dense-слои «под капотом».
Краткое резюме
Поздравляем! Вы только что обучили свою первую модель. Мы на практике увидели, каким образом по входным и выходным значениям модель научилась умножать входное значение на 1.8 и прибавлять к нему 32 для получения корректного результата.

Это было по-настоящему впечатляюще, учитывая то, сколько строчек кода нам понадобилось написать:
Приведённый выше пример — общий план для всех программ машинного обучения. Вы будете использовать подобные конструкции для создания и обучения нейронных сетей и для решения последующих задач.
Процесс тренировки
Процесс тренировки (происходящий в методе model.fit(. ) ) состоит из весьма простой последовательности действий, результатом которых должны стать значения внутренних переменных дающих максимально близкий к исходному результаты. Процесс оптимизации, благодаря которому достигаются такие результаты, называется градиентным спуском, использует численный анализ для поиска максимально подходящих значений для внутренних переменных модели.
Чтобы заниматься машинным обучением вам, в принципе, нет необходимости разбираться в этих деталях. Но для тех, кому всё-таки интересно узнать больше: градиентный спуск посредством итераций изменяет значения параметров по-немногу, «вытягивая» их в нужном направлении, до тех пор пока не будут получены наилучшие результаты. В данном случае «лучшие результаты» (лучшие значения) означают, что любое последующее изменение параметра только ухудшит результат модели. Функция, которая измеряет насколько хороша или плоха модель на каждой итерации называется «функцией потерь», и цель каждого «вытягивания» (корректировки внутренних значений) — уменьшить значение функции потерь.
Процесс тренировки начинается с блока «прямое распространение», при котором входные параметры поступают на вход нейронной сети, следуют к скрытым нейронам и затем идут к выходным. Затем модель применяет внутренние преобразования над входными значениями и внутренними переменными для предсказания ответа.
В нашем примере, входным значением является температура в градусах Цельсия и модель предсказывала соответствующее значение в градусах Фаренгейта.
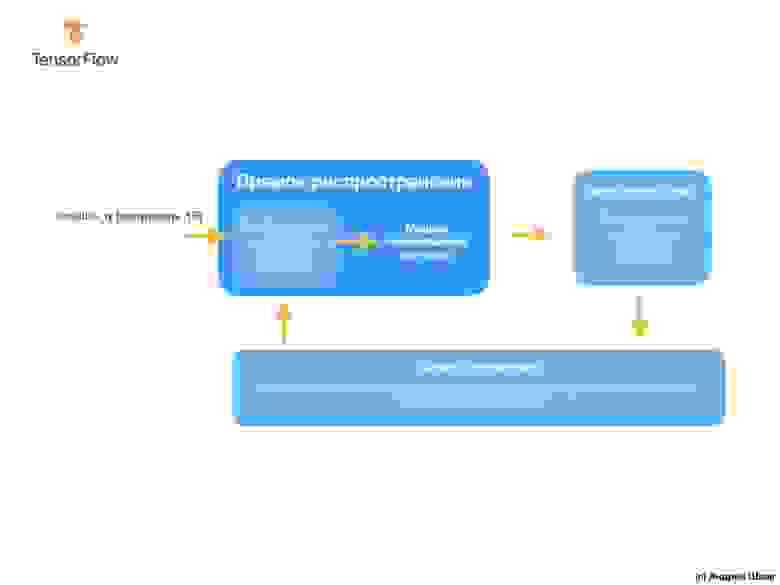
После вычисления значения потери, внутренние переменные (веса и смещения) всех слоёв нейронной сети подвергаются корректировке для минимизации значения потери с целью приближения выходного значения к корректному исходному эталонному значению.
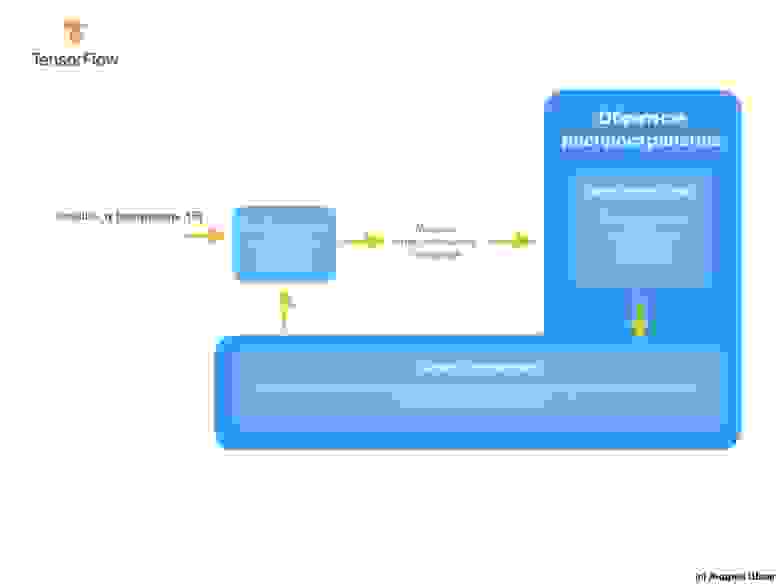
Для этого курса не является обязательным понимание принципов работы процесса тренировки, однако, если вы достаточно любопытны, то можете найти больше информации в Google Crash Course (перевод и практическая часть всего курса заложены у автора в планах к публикации).
К этому моменты вы уже должны быть знакомы со следующими терминами:
Dense-слои
В предыдущей части мы создали модель, которая конвертирует градусы Цельсия в градусы Фаренгейта, используя простую нейронную сеть для нахождения зависимости между градусами Цельсия и градусами Фаренгейта.
Наша сеть состоит из единственного полносвязного слоя. Но что такое полносвязный слой? Чтобы в этом разобраться давайте создадим более сложную нейронную сеть у которой 3 входных параметра, один скрытый слой с двумя нейронами и один выходной слой с единственным нейроном.
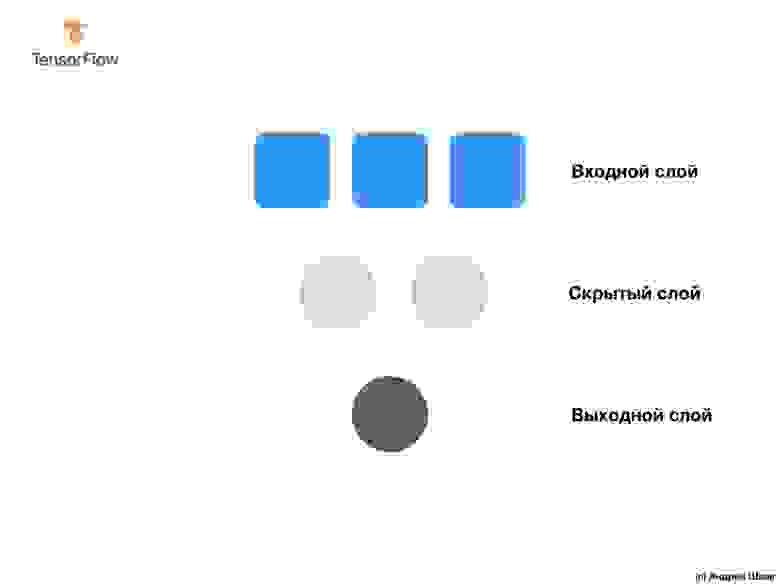

Чтобы создать приведенную выше нейронную сеть нам достаточно следующих выражений:
Итак, мы разобрались с тем, что такое нейроны и как они связаны между собой. Но как на самом деле работают полносвязные слои?
Чтобы понять, что же на самом деле там происходит и что они делают, нам понадобится заглянуть «под капот» и разобрать внутреннюю математику нейронов.
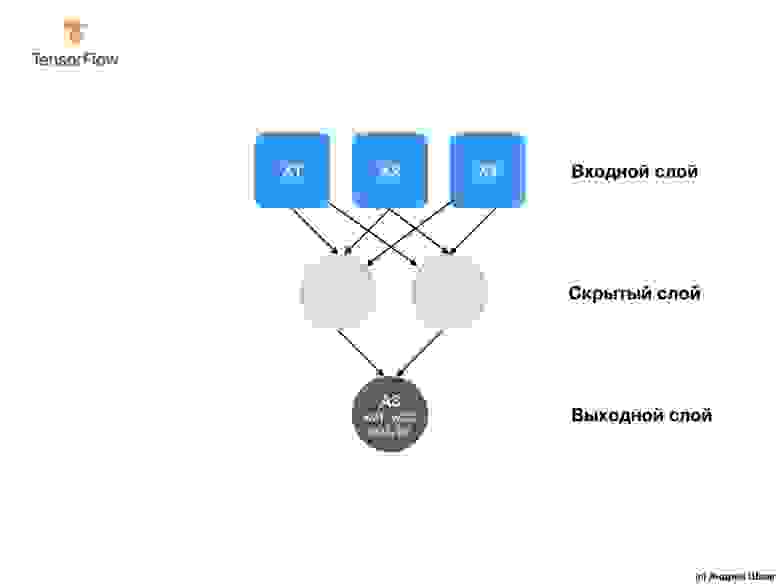

Что обязательно стоит иметь ввиду — внутренняя математика нейрона остаётся неизменной. Другими словами, в процессе тренировки меняются только веса и смещения.
Когда начинаешь изучать машинное обучение это может показаться странным — тот факт, что это действительно работает, но именно так работает машинное обучение!
Давайте теперь вернёмся к нашему примеру конвертации градусов Цельсия в градусы Фаренгейта.

Если мы вернёмся к результатам работы нашей модели из практической части, то обратим внимание на то, что показатели веса и смещения были «откалиброваны» таким образом, что примерно соответствуют значениям из формулы.
Мы целенаправленно создали именно такой практический пример, чтобы наглядно показать точное сопоставление между весами и смещениями. Применяя машинное обучение на практике, мы никогда не сможем подобным образом сопоставить значения переменных с целевым алгоритмом, как в приведённом выше примере. Как мы сможем это сделать? Никак, потому что мы даже не знаем целевого алгоритма!
Решая задачи машинного обучения мы тестируем различные архитектуры нейронных сетей с различным количеством нейронов в них — методом проб и ошибок находим наиболее точные архитектуры и модели и надеемся, что они решат поставленную задачу в процессе обучения. В следующей практической части мы сможем изучить конкретные примеры такого подхода.
Оставайтесь на связи, потому что сейчас начнётся самое интересное!
Итоги
… и стандартные call-to-action — подписывайся, ставь плюс и делай share 🙂
Краткое введение в Машинное обучение
Пару лет назад я рассказывал жене сказки, что когда я буду старым маразматиком, мое ближайшее окружение не будет страдать от этого, ведь за мной будут ухаживать роботы. Новости о прогрессе искусственного интеллекта впечатляли меня (нейросетки то, нейросетки сё), свет в конце тоннеля манил, как и зарплаты специалистов в этой области. Разумеется, я не смог пройти мимо и решил погрузиться в Machine Learning.
Для старта хотелось почитать что-то совсем базовое, но поиск по строкам «машинное обучение для чайников» вменяемых результатов не дал. Все статьи начинались с тривиальных рассуждений, а потом перепрыгивали на загадочные формулы без особых пояснений. Я не сдавался и добыл несколько книг с хорошими отзывами, но получил то же самое, только уже на 600 страниц. Спустя полгода поисков могу сообщить вам следующее: при текущих темпах развития AI я не увижу роботов в старости, для работы с Machine Learning на самом деле не нужна математика, и как минимум одна статья «машинное обучение для чайников» существует, вы ее сейчас читаете.
Итак, ознакомившись с этой статьей вы поймете, что вообще представляет собой группа технологий ML. Имея эту базу вам будет проще двигаться дальше, и даже формулы в книгах станут понятнее. Раз уж зашел разговор о книгах, то сразу порекомендую ту, с которой у меня начался реальный прогресс: Andrew Glassner, «DEEP LEARNING: From Basics to Practice». В русском варианте она называется «Глубокое обучение без математики»: автор разжевывает алгоритмы не прибегая к формулам. После томов, полных математического пафоса, это был просто глоток свежего воздуха. Еще один важный момент: постарайтесь читать англоязычную литературу, т.к. перевод терминов на русский язык местами сильно страдает. Человеку, который ввел фразу «Обучение с учителем» должно быть очень стыдно.
Создадим модель и обучим ее
Начнем с классики жанра: у нас есть база данных недвижимости с десятком атрибутов (стоимость, площадь, количество комнат и т.д.), на ее основе надо научиться предсказывать стоимость других домов. Тут вы скажете: «Стопэ! Нам надо нейросетку, которая убирает купальники с фотографий, а ты пихаешь нам примитивную задачу о расчете усредненной стоимости!». Я поначалу тоже был в шоке, что эти задачи являются существенной частью ML. И я пришел в ужас от того, что в ML распознавание объектов на фотографии работает по такому же принципу, что и наше предсказание стоимости. Тут ключевое слово «Работает», так что давайте продолжим, сейчас все станет понятно.
Задача сводится к двум шагам: выбрать модель (подобрать подходящую формулу расчета) и затем найти ее коэффициенты. Модель для нашего примера возьмем упрощенную:

Теперь мы будем перебирать значения коэффициентов A до тех пор, пока уровень ошибки не станет приемлемым, это и называется Обучением модели.
Ошибку каждый раз вычисляем, конечно же, по нашей базе данных (Обучающей выборке, Training Set), алгоритм очень простой: для каждого дома находим разницу между расчетной и фактической стоимостью, возводим разницу в квадрат (чтобы избавиться от отрицательных чисел) и находим среднее значение всех этих отклонений. Формула для вычисления ошибки называется Функцией потерь (Loss Function), описанный алгоритм расчета популярный, но не единственный.
Если ошибку не удается снизить до вменяемых значений, значит мы неудачно выбрали модель: возможно, надо количество комнат брать в квадрат, или Удаленность от центра не плюсовать, а делить. Вариантов много, математики не могут ответить на вопрос «Как выбрать модель», поэтому просто сидим и пробуем разные, пока не получится (тут становятся понятны некоторые шутки про Data Scientist-ов).
А что насчет распознавания объектов на фотографиях? Идея простая: если сделать огромную формулу, которая на вход принимает миллион значений (пиксели фотографии) и внутри имеет сотню тысяч коэффициентов, то после удачного «обучения» она начнет на выходе выдавать «Вероятность наличия собаки на фото» (значение от 0.0 до 1.0). И это прокатило, такие формулы действительно работают, это называют Глубоким обучением (Deep Learning). Есть две сложности: формулу такого размера руками не написать, а ее коэффициенты даже на супер-компьютере методом простого перебора не вычислить. Приступаем к оптимизации.
Перцептрон и Нейронная сеть

В книгах вы прочитаете, что идея создания Перцептрона была навеяна структурой нашего мозга (нейронами), но сходство там очень отдаленное. Перцептрон работает гораздо проще, это всего лишь графическое представление обычного линейного уравнения:


Всего одной строкой мы рассчитали стоимости всех домов в нашей базе: в одномерный массив W закидываем все веса перцептрона, в двумерный массив X помещаем всю базу недвижимости (кроме стоимости), а в выходном одномерном массиве Y получаем все рассчитанные стоимости. Но краткостью записи все достоинства матриц и заканчиваются. С вычислительной точки зрения здесь нет никакого ускорения (если вы конечно пишите не на Python), а сама операция сведется к трем вложенным циклам с расчетом все того же линейного уравнения. Отказ от матриц, напротив, дает больше пространства для маневра и оптимизаций, но это повод для отдельной статьи.
На практике вам не придется работать с матрицами, готовые библиотеки избавят вас от этой мороки, так что кроме как в книгах вы эти матричные формулы больше нигде не увидите (ну еще в статьях на Хабре).
На одном линейном уравнении далеко не уедешь, пока что наша модель не сможет корректно предсказать стоимость, не говоря уже о собаке на фото:

Для большей гибкости перцептроны объединяют в нейронные сети (на таких рисунках не показывают Веса, но свой набор есть у каждого перцептрона в сети):

Тут нас ждет сюрприз: какие бы сложные комбинации связей мы ни рисовали, в итоге получим наше исходное линейное уравнение. Ни одно из входных значений x не будет возведено в степень, т.к. перцептроны соединяются между собой через операцию Сложения. Чтобы как-то исправить ситуацию на выходе каждого перцептрона добавили Функцию активации (Activation function):

Эта функция Ψ обязательно нелинейная, конечно же есть популярные варианты, которые вы найдете в любой книге (рисунки с Wikipedia):

Какую функцию использовать в вашей модели? Математики также не могут ответить на этот вопрос, пробуйте разные и смотрите что лучше работает в вашем случае. Сигмоид относительно требователен к вычислительным ресурсам, поэтому его чаще ставят только на выходе нейросети, чтобы получить красивое значение от 0.0 до 1.0 (именно для красоты, на выходе он не влияет на работу сети). Говорят, что и обычный Косинус работает неплохо (если таки углубиться в математику и взглянуть на Ряд Фурье, то возникает ощущение, что именно им и надо пользоваться, но я сам пока не пробовал). Для полного понимания работы функций активации давайте взглянем, во что превратилось уравнение нашего перцептрона в случае Сигмоида:

Наша модель выглядит сложнее, а если попытаться нарисовать формулу для всей нейронной сети, то будет вообще мясо, даже в матричном виде ее уже не пытаются изобразить. Благодаря функциям активации гибкость достигнута.
Как разработчику, вам не потребуется прописывать все эти формулы, готовые библиотеки избавят вас и от этой мороки. Есть теорема, которая доказывает, что с помощью линейных уравнений с функциями активации можно смоделировать любой процесс. Теорема правда не говорит, сколько весов должно быть в модели и как долго вы ее будете обучать.
Обучение модели
Простой перебор весов займет очень длительное время, т.к. после любой их корректировки надо прогонять через нейронную сеть всю обучающую выборку, чтобы посмотреть, как изменилась ошибка. Здесь нам помогут два метода: Градиентный спуск (Gradient Descent) и в дополнение к нему Обратное распространение (Backpropagation). Детальное вменяемое описание работы этой пары вы найдете все в той же книге «DEEP LEARNING: From Basics to Practice», а я приведу только самую суть.
Шаг 1: после создания нейронной сети проставляем начальные значения всем весам (обычно, маленькие случайные числа), прогоняем через нее обучающую выборку и вычисляем ошибку (Loss function). Если ошибка равна нулю, то Бог есть и он сегодня с вами. Все остальные пройдемте к шагу два.
Шаг 2: теперь нам надо поправить веса так, чтобы ошибка стала меньше. Взглянем, например, на вес W508, в какую сторону будем его двигать?

Для этого нам требуется производная от Функции потерь, что уже требует знаний математики (кажется 11 класс школы), но вас это не должно беспокоить, все производные для стандартных Функций потерь уже найдены и заботливо упакованы в библиотеки. Вам требуется только общее понимание, как это работает, чтобы суметь разобраться в причинах сбоев при обучении.

По градиенту мы видим не только в какую сторону менять вес, но и как сильно это делать (по крутизне наклона). По этой методике поочередно находим градиент для каждого веса и меняем их значения, это и есть Метод градиентного спуска.
Шаг 3: опять прогоняем обучающую выборку через сеть, вычисляем ошибку, вычисляем новые градиенты для весов:

И видим прогресс: ошибка действительно изменилась в меньшую сторону, а новый Градиент имеет меньший угол наклона, значит мы близки к минимальному значению ошибки на графике. Повторяем процесс до посинения тех пор, пока модель не перестанет обучаться, в этом случае градиенты станут почти горизонтальными линиями.
Какие есть подводные камни? А давайте все-таки построим полный график для Веса W508

Оказывается, мы шли не в том направлении, потому что начальное значение веса (случайное число) упало не в ту часть графика. Мы достигли, так называемого, локального минимума, и на графике их может быть очень много. Как с этим бороться? Запускаем обучение заново и надеемся, что в этот раз исходное случайное значение веса упадет в нужную область. Метод проб и ошибок все еще наш лучший друг.
А что там с Backpropagation? Вроде все посчитали, все работает, он нам зачем? Вычисление градиента для каждого из весов, описанное выше, относительно затратная процедура. Метод обратного распространения сильно упрощает этот процесс: зная градиент для правой части нейронной сети мы легко вычисляем градиенты для весов, находящихся левее. Двигаясь по сети все левее и левее мы постепенно обновляем все веса. Из-за этого движения справа налево метод и назвали «Обратным».
Таким образом, Backpropagation занимается только вычислением градиентов, а обновление весов по найденным градиентам выполняется с помощью Метода градиентного спуска. В реальной жизни часто упоминают только Backpropagation, опуская вторую составляющую, но вы должны понимать, что они идут в паре.
Виды нейронных сетей
Выше уже был показан вариант Полносвязной нейронной сети (Fully connected neural network), но они бывают еще и такими:

Кстати о картинках: в Полносвязную сеть пиксели изображения подаются построчно:

Это не очень-то логично, гораздо лучше близлежащие пиксели отправлять в нейросеть также рядышком:

Так и появились Сверточные нейронные сети (Convolutional neural network), или просто CNN. Это все еще набор перцептронов с функциями активации внутри, но набор связей между ними специфический, уже не все со всеми. Обучаются они все тем же методом Backpropagation.

Выделенную на рисунке цветом область называют «Фильтр». Обычно это квадрат со стороной 3-5 пикселей. Фильтр накладывают на изображение: значения x умножаем на веса и суммируем их, т.е. пропускаем значения через перцептрон. Результат сохраняем в новый двумерный массив. Далее снова накладываем этот же фильтр на изображение, но уже сдвинув его вправо на один пиксель (иногда используют большее смещение), и так пробегаем по всему изображению. Все это повторяем с другими фильтрами (еще несколько перцептронов с другими значениями весов), сохраняя результаты в отдельные массивы. Отфильтрованные изображения прогоняем еще через несколько фильтров, подвергаем дополнительным обработкам, и результат можно, например, подать на полносвязную сеть.

В литературе их часто называют нейросетями с памятью, но так можно сказать с очень большой натяжкой. Также в учебниках вы часто увидите попытку объяснить работу RNN через графы, но можно не забивать себе этим голову. Работают они очень просто:

В перцептрон добавилось Состояние (массив S): это переменные, в которых мы сохраняем результат вычисления всего перцептрона (домножив на веса), чтобы использовать их при следующем вызове перцептрона. При первом запуске Состояние заполняется нулями. Если вы уже распознали какой-то блок текста (например, e-mail) и готовы перейти к следующему независимому блоку данных, то Состояние принудительно обнуляется.
Если вы пытаетесь предсказать температуру на завтра, то такая нейросеть будет оперировать не только текущими показаниями (облачность, сила и направление ветра), но и предыдущим значением температуры, что очень логично.
Для Состояния есть несколько усложнений, которые повышают качество работы RNN. Если мы хотим учитывать не только последнее выходное значение, но и несколько предыдущих, то формула вычисления Состояния немного меняется (исходный код, не математическая формула):

Таким образом мы не полностью перезаписываем значение, а добавляем некоторое изменение, в зависимости от выходного значения.
Решаемые задачи
Алгоритмы машинного обучения подразделяют на «Обучение с учителем» (Supervised Learning, привет переводчику) и «Обучение без учителя» (Unsupervised Learning). Года два назад я был уверен, что речь идет о самообучаемых алгоритмах и о тех, за которыми надо присматривать. На самом деле здесь идет речь о двух группах:
Рассмотрим сами алгоритмы, начнем с Классификации, выше уже был пример: что находится на фото (кошка, собака и т.д.)? Другие классические примеры: является ли письмо спамом (бинарная классификация, т.к. ответ да/нет), распознавание букв и цифр на изображениях.
Генерация контента, можно выполнить с помощью Автокодировщика. Для этого используется специфическая нейронная сеть с «бутылочным горлышком»:

При обучении такую сеть заставляют на выходе генерировать точно такие же данные, что поступили на вход, например, в обучающую выборку включают разные фото травы. После завершения обучения сеть разрывают:

Теперь, подавая на вход пару чисел, на выходе мы можем получить совершенно новые изображения травы (либо белеберду, как повезет). Внутри Автокодировщика можно использовать полносвязные сети, CNN и RNN, а также любые их комбинации, важно только создать бутылочное горлышко.
За что же платят так много денег?
Как мы увидели выше, ничего особо сложного в Машинном обучении нет. Вся математика скрыта в недрах библиотек, количество алгоритмов ограничено, вариантов оптимизации не слишком много, сиди да подбирай коэффициенты случайным образом. Почему же зарплаты Data Scientist так высоки? Чтобы быть успешным в этом деле надо все-таки включать голову.
Успех складывается из двух вещей:
у вас есть очень много данных в обучающей выборке и очень мощные серверы для их обработки (тогда достаточно взять готовую GPT-3 и обучить ее русскому языку);
вы отлично знаете предметную область, в которой пытаетесь применить машинное обучение.
Меняя количество перцептронов в нейронной сети вы можете немного повысить качество ее работы, но настоящий прорыв возможен, если вы усовершенствуете алгоритм в целом. Например, декомпозируете задачу: с помощью первой нейронной сети преобразуем фотографию в простейшие фигуры (треугольник, круг, волнистые линии), а второй нейронкой определяем, что же там нарисовано.

Заключение
В этой статье я привел лишь самые базовые вещи. Есть еще огромное количество нюансов, которые вы почерпнете из книг и статей, но у вас теперь есть основной вектор движения.
Что такое машинное обучение и как оно работает

Что такое машинное обучение?
Единого определения для machine learning (машинного обучения) пока нет. Но большинство исследователей формулируют его примерно так:
Машинное обучение — это наука о том, как заставить ИИ учиться и действовать как человек, а также сделать так, чтобы он сам постоянно улучшал свое обучение и способности на основе предоставленных нами данных о реальном мире.
Вот как определяют машинное обучение представители ведущих ИТ-компаний и исследовательских центров:
Nvidia: «Это практика использования алгоритмов для анализа данных, изучения их и последующего определения или предсказания чего-либо».
Университет Стэнфорда: «Это наука о том, как заставить компьютеры работать без явного программирования».
McKinsey & Co: «Машинное обучение основано на алгоритмах, которые могут учиться на данных, не полагаясь на программирование на основе базовых правил».
Вашингтонский университет: «Алгоритмы машинного обучения могут сами понять, как выполнять важные задачи, обобщая примеры, которые у них есть».
Университет Карнеги Меллон: «Сфера машинного обучения пытается ответить на вопрос: «Как мы можем создавать компьютерные системы, которые автоматически улучшаются по мере накопления опыта и каковы фундаментальные законы, которые управляют всеми процессами обучения?»
История машинного обучения
Дмитрий Ветров, профессор-исследователь, заведующий Центром глубинного обучения и байесовских методов Факультета компьютерных наук ВШЭ, отмечает: изначально компьютеры использовались для задач, алгоритм решения которых был известен человеку. И только в последние годы пришло понимание, что они могут находить способ решать задачи, для которых алгоритма решения нет или он не известен человеку. Так появился искусственный интеллект в широком смысле и технологии машинного обучения в частности.
Как связаны машинное и глубокое обучение, ИИ и нейросети
Нейросети — один из видов машинного обучения.
Глубокое обучение — это один из видов архитектуры нейросетей.

Глубокое обучение также включает в себя исследование и разработку алгоритмов для машинного обучения. В частности — обучения правильному представлению данных на нескольких уровнях абстракции. Системы глубокого обучения за последние десять лет добились особенных успехов в таких областях как обнаружение и распознавание объектов, преобразование текста в речь, поиск информации.
Какие задачи решает машинное обучение?
С помощью машинного обучения ИИ может анализировать данные, запоминать информацию, строить прогнозы, воспроизводить готовые модели и выбирать наиболее подходящий вариант из предложенных.
Особенно полезны такие системы там, где необходимо выполнять огромные объемы вычислений: например, банковский скоринг (расчет кредитного рейтинга), аналитика в области маркетинговых и статистических исследований, бизнес-планирование, демографические исследования, инвестиции, поиск фейковых новостей и мошеннических сайтов.
В Леруа Мерлен используют Big Data и Machine Learning, чтобы находить остатки товара на складах.
В маркетинге и электронной коммерции машинное обучение помогает настроить сервисы и приложения так, чтобы они выдавали персональные рекомендации.
Стриминговый сервис Spotify с помощью машинного обучения составляет для каждого пользователя персональные подборки треков на основе того, какую музыку он слушает.
Сегодня ключевые исследования сфокусированы на разработке машинного обучения с эффективным использованием данных — то есть систем глубокого обучения, которые могут обучаться более эффективно, с той же производительностью, за меньшее время и с меньшими объемами данных. Такие системы востребованы в персонализированном здравоохранении, обучении роботов с подкреплением, анализе эмоций.
Китайский производитель «умных» пылесосов Ecovacs Robotics обучил свои пылесосы распознавать носки, провода и другие посторонние предметы на полу с помощью множества фотографий и машинного обучения.
«Умная» камера на базе микрокомпьютера Raspberry Pi 3B+ с помощью фреймворка TensorFlow Light научилась распознавать улыбку и делать снимок ровно в этот момент, а также — выполнять голосовые команды.
В сфере инвестиций алгоритмы на базе машинного обучения анализируют рынок, отслеживают новости и подбирают активы, которые выгоднее всего покупать именно сейчас. При этом с помощью предикативной аналитики система может предсказать, как будет меняться стоимость тех или иных акций за конкретный период и корректирует свои данные после каждого важного события в отрасли.
Согласно исследованию BarclayHedge, более 50% хедж-фондов используют ИИ и машинное обучение для принятия инвестиционных решений, а две трети — для генерации торговых идей и оптимизации портфелей.
Наконец, машинное обучение способствует настоящим прорывам в науке.
Нейросеть AlphaFold от DeepMind в 2020 году смогла расшифровать механизм сворачивания белка. Над этой задачей ученые-биологи бились больше 50 лет.
Как устроено машинное обучение
По словам Дмитрия Ветрова, процесс машинного обучения выглядит следующим образом.
Есть большое число однотипных задач, в которых известны условие и правильный ответ или один из возможных ответов. Например, машинный перевод, где условие — фраза на одном языке, а правильный ответ — ее перевод на другой язык.
Модель машинного обучения, например, глубинная нейронная сеть, работает по принципу «черного ящика», который принимает на вход условие задачи, а на выходе выдает произвольный ответ. Например, какой-либо текст на втором языке.
У «черного ящика» есть дополнительные параметры, которые влияют на то, как будет обрабатываться входной сигнал. Процесс обучения нейросети заключается в поиске таких значений параметров, при которых она будет выдавать ответ, максимально близкий к правильному. Когда мы настроим параметры нужным образом, нейросеть сможет правильно (или максимально близко к этому) решать и другие задачи того же типа — даже если никогда не знала ответов к ним.

Основные виды машинного обучения
1. Классическое обучение
Это простейшие алгоритмы, которые являются прямыми наследниками вычислительных машин 1950-х годов. Они изначально решали формальные задачи — такие, как поиск закономерностей в расчетах и вычисление траектории объектов. Сегодня алгоритмы на базе классического обучения — самые распространенные. Именно они формируют блок рекомендаций на многих платформах.

Но классическое обучение тоже бывает разным:
Обучение с учителем — когда у машины есть некий учитель, который знает, какой ответ правильный. Это значит, что исходные данные уже размечены (отсортированы) нужным образом, и машине остается лишь определить объект с нужным признаком или вычислить результат.
Такие модели используют в спам-фильтрах, распознавании языков и рукописного текста, выявлении мошеннических операций, расчете финансовых показателей, скоринге при выдаче кредита. В медицинской диагностике классификация помогает выявлять аномалии — то есть возможные признаки заболеваний на снимках пациентов.
Обучение без учителя — когда машина сама должна найти среди хаотичных данных верное решение и отсортировать объекты по неизвестным признакам. Например, определить, где на фото собака.
Эта модель возникла в 1990-х годах и на практике используется гораздо реже. Ее применяют для данных, которые просто невозможно разметить из-за их колоссального объема. Такие алгоритмы применяют для риск-менеджмента, сжатия изображений, объединения близких точек на карте, сегментации рынка, прогноза акций и распродаж в ретейле, мерчендайзинга. По такому принципу работает алгоритм iPhoto, который находит на фотографиях лица (не зная, чьи они) и объединяет их в альбомы.
2. Обучение с подкреплением
Это более сложный вид обучения, где ИИ нужно не просто анализировать данные, а действовать самостоятельно в реальной среде — будь то улица, дом или видеоигра. Задача робота — свести ошибки к минимуму, за что он получает возможность продолжать работу без препятствий и сбоев.
Обучение с подкреплением инженеры используют для беспилотников, роботов-пылесосов, торговли на фондовом рынке, управления ресурсами компании. Именно так алгоритму AlphaGo удалось обыграть чемпиона по игре Го: просчитать все возможные комбинации, как в шахматах, здесь было невозможно.
3. Ансамбли
Это группы алгоритмов, которые используют сразу несколько методов машинного обучения и исправляют ошибки друг друга. Их получают тремя способами:
Ансамбли работают в поисковых системах, компьютерном зрении, распознавании лиц и других объектов.
4. Нейросети и глубокое обучение
Самый сложный уровень обучения ИИ. Нейросети моделируют работу человеческого мозга, который состоит из нейронов, постоянно формирующих между собой новые связи. Очень условно можно определить их как сеть со множеством входов и одним выходом. Нейроны образуют слои, через которые последовательно проходит сигнал. Все это соединено нейронными связями — каналами, по которым передаются данные. У каждого канала свой «вес» — параметр, который влияет на данные, которые он передает.
ИИ собирает данные со всех входов, оценивая их вес по заданным параметрами, затем выполняет нужное действие и выдает результат. Сначала он получается случайным, но затем через множество циклов становится все более точным. Хорошо обученная нейросеть работает, как обычный алгоритм или точнее.
Настоящим прорывом в этой области стало глубокое обучение, которое обучает нейросети на нескольких уровнях абстракций.
Здесь используют две главных архитектуры:
Нейросети с глубоким обучением требуют огромных массивов данных и технических ресурсов. Именно они лежат в основе машинного перевода, чат-ботов и голосовых помощников, создают музыку и дипфейки, обрабатывают фото и видео.
Проблемы машинного обучения
Перспективы машинного обучения: не начнет ли ИИ думать за нас?
Вопрос о том, не сделает ли машинное обучение ИИ умнее человека, изначально не совсем корректный. Дело в том, что в природе нет универсальной иерархии в плане интеллекта. Мы по умолчанию считаем себя умнее остальных существ, но, к примеру, белка способна запоминать местонахождения тысячи тайников с запасами, что не под силу даже очень умному человеку. А у осьминогов каждое щупальце способно мыслить и действовать самостоятельно.
Так же и с ИИ: он уже превосходит нас во всем, что касается сложных вычислений, но по-прежнему не способен сам ставить себе новые задачи и решать их, подбирая нужные данные и условия. Это ограничение в последние годы пытаются преодолеть в рамках сильного ИИ, но пока безуспешно. Надежду на решение этой проблемы внушают квантовые компьютеры, которые выходят за пределы обычных вычислений.
Зато мы в ближайшем будущем сможем заметно расширить свои возможности с помощью ИИ, передавая ему рутинные и затратные операции, общаясь и управляя техникой при помощи нейроинтерфейсов.
Общие понятия
Содержание
Понятие машинного обучения в искусственном интеллекте [ править ]
Одним из первых, кто использовал термин «машинное обучение», был изобретатель первой самообучающейся компьютерной программы игры в шашки А. Л. Самуэль в 1959 г. [1]
| Определение: |
| Машинное обучение (англ. Machine learning) — процесс, который даёт возможность компьютерам обучаться выполнять что-то без явного написания кода. |
Это определение не выдерживает критики, так как не понятно, что означает наречие «явно». Более точное определение дал намного позже Т. М. Митчелл. [2]
Задача обучения [ править ]
$X$ — множество объектов (англ. object set, or input set)
$Y$ — множество меток классов (англ. label set, or output set)
$\hat y∶ X → Y$ — неизвестная зависимость (англ. unknown target function (dependency))
Признаки [ править ]
[math] F = ||f_j(x_i)||_ <[l \times n]>= \begin
Типы задач [ править ]
Классификация (англ. classification)
Цель: научиться определять, к какому классу принадлежит объект.
Примеры: распознавание текста по рукописному вводу; определение того, находится на фотографии человек или кот; определение, является ли письмо спамом.
Методы: метод ближайших соседей, дерево решений, логистическая регрессия, метод опорных векторов, байесовский классификатор, cверточные нейронные сети.
Восстановление регрессии (англ. regression)
Цель: получать прогноз на основе выборки объектов.
Примеры: предсказание стоимости акции через полгода; предсказание прибыли магазина в следующем месяце; предсказание качества вина на слепом тестировании.
Методы: линейная регрессия, дерево решений, метод опорных векторов.
Цель: научиться по множеству объектов получать множество рейтингов, упорядоченное согласно заданному отношению порядка.
Примеры: выдача поискового запроса; подбор интересных новостей для пользователя.
Методы: поточечный подход, попарный подход, списочный подход.
Кластеризация (англ. clustering)
Цель: разбить множество объектов на подмножества (кластеры) таким образом, чтобы объекты из одного кластера были более похожи друг на друга, чем на объекты из других кластеров по какому-либо критерию.
Примеры: разбиение клиентов сотового оператора по платёжеспособности; разбиение космических объектов на похожие (галактики, планеты, звезды).
Методы: иерархическая кластеризация, эволюционные алгоритмы кластеризации, EM-алгоритм.
Вспомогательные типы задач [ править ]
Уменьшение размерности (англ. dimensionality reduction)
Выявление аномалий (англ. anomaly detection)
Цель: научиться выявлять аномалии в данных. Отличительная особенность задачи от классификации — примеров аномалий для тренировки модели очень мало, либо нет совсем; поэтому для ее решения необходимы специальные методы.
Примеры: определение мошеннических транзакций по банковской карте; обнаружение событий, предвещающих землетрясение.
Методы: экстремальный анализ данных, аппроксимирующий метод, проецирующие методы.
Классификация задач машинного обучения [ править ]
Обучение с учителем (англ. Supervised learning [3] ) [ править ]
Обучение без учителя (англ. Unsupervised learning) [ править ]
Изучает широкий класс задач обработки данных, в которых известны только описания множества объектов (обучающей выборки), и требуется обнаружить внутренние взаимосвязи, зависимости, закономерности, существующие между объектами. Т.е. тренировочные данные доступны все сразу, но ответы для поставленной задачи неизвестны.
Задачи, которые могут решаться этим способом: кластеризация, нахождение ассоциативных правил, выдача рекомендаций (например, реклама), уменьшение размерности датасета, обработка естественного языка.
Обучение с частичным привлечением учителя (англ. Semi-supervised learning [4] ) [ править ]
Занимает промежуточное положение между обучением с учителем и без учителя. Каждый прецедент представляет собой пару «объект, ответ», но ответы известны только на части прецедентов (Размечено мало, либо малоинформативная часть).
Примером частичного обучения может послужить сообучение: два или более обучаемых алгоритма используют один и тот же набор данных, но каждый при обучении использует различные — в идеале некоррелирующие — наборы признаков объектов.
Обучение с подкреплением (англ. Reinforcement learning) [ править ]
Частный случай обучения с учителем, сигналы подкрепления (правильности ответа) выдаются не учителем, а некоторой средой, с которой взаимодействует программа. Размеченность данных зависит от среды.
Окружение обычно формулируется как марковский процесс принятия решений (МППР) с конечным множеством состояний, и в этом смысле алгоритмы обучения с подкреплением тесно связаны с динамическим программированием. Вероятности выигрышей и перехода состояний в МППР обычно являются величинами случайными, но стационарными в рамках задачи.
При обучении с подкреплением, в отличие от обучения с учителем, не предоставляются верные пары «входные данные-ответ», а принятие субоптимальных решений (дающих локальный экстремум) не ограничивается явно. Обучение с подкреплением пытается найти компромисс между исследованием неизученных областей и применением имеющихся знаний (англ. exploration vs exploitation tradeoff).
Активное обучение (англ. Active learning) [ править ]
Отличается тем, что обучаемый имеет возможность самостоятельно назначать следующий прецедент, который станет известен. Применяется когда получение истиной метки для объекта затруднительно. Поэтому алгоритм должен уметь определять, на каких объектах ему надо знать ответ, чтобы лучше всего обучиться, построить наилучшую модель.
Обучение в реальном времени (англ. Online learning) [ править ]
Может быть как обучением с учителем, так и без учителя. Специфика в том, что тренировочные данные поступают последовательно. Требуется немедленно принимать решение по каждому прецеденту и одновременно доучивать модель зависимости с учётом новых прецедентов. Здесь существенную роль играет фактор времени.
Примеры задач [ править ]
Признаками являются данные геологической разведки.
Обучающая выборка состоит из двух классов:
При поиске редких полезных ископаемых количество объектов может оказаться намного меньше, чем количество признаков. В этой ситуации плохо работают классические статистические методы. Задача решается путём поиска закономерностей в имеющемся массиве данных. В процессе решения выделяются короткие наборы признаков, обладающие наибольшей информативностью — способностью наилучшим образом разделять классы («синдромы» месторождений).
Эта задача решается банками при выдаче кредитов. Объектами в данном случае являются физические или юридические лица, претендующие на получение кредита.
В случае физических лиц признаковое описание состоит из:
Можно выделить следующие признаки:
Обучающая выборка составляется из заёмщиков с известной кредитной историей.
На стадии обучения производится синтез и отбор информативных признаков и определяется, сколько баллов назначать за каждый признак, чтобы риск принимаемых решений был минимален. Чем выше суммарное число баллов заёмщика, набранных по совокупности информативных признаков, тем более надёжным считается заёмщик.
В роли объектов выступают пациенты. Признаки характеризуют результаты обследований, симптомы заболевания и применявшиеся методы лечения.
Признаковое описание пациента является, по сути дела, формализованной историей болезни.
Накопив достаточное количество данных, можно решать различные задачи:
Ценность такого рода систем в том, что они способны мгновенно анализировать и обобщать огромное количество прецедентов — возможность, недоступная специалисту-врачу.
Машинное обучение — это легко
Для кого эта статья?
Каждый, кому будет интересно затем покопаться в истории за поиском новых фактов, или каждый, кто хотя бы раз задавался вопросом «как же все таки это, машинное обучение, работает», найдёт здесь ответ на интересующий его вопрос. Вероятнее всего, опытный читатель не найдёт здесь для себя ничего интересного, так как программная часть оставляет желать лучшего несколько упрощена для освоения начинающими, однако осведомиться о происхождении машинного обучения и его развитии в целом не помешает никому.

В цифрах
С каждым годом растёт потребность в изучении больших данных как для компаний, так и для активных энтузиастов. В таких крупных компаниях, как Яндекс или Google, всё чаще используются такие инструменты для изучения данных, как язык программирования R, или библиотеки для Python (в этой статье я привожу примеры, написанные под Python 3). Согласно Закону Мура (а на картинке — и он сам), количество транзисторов на интегральной схеме удваивается каждые 24 месяца. Это значит, что с каждым годом производительность наших компьютеров растёт, а значит и ранее недоступные границы познания снова «смещаются вправо» — открывается простор для изучения больших данных, с чем и связано в первую очередь создание «науки о больших данных», изучение которого в основном стало возможным благодаря применению ранее описанных алгоритмов машинного обучения, проверить которые стало возможным лишь спустя полвека. Кто знает, может быть уже через несколько лет мы сможем в абсолютной точности описывать различные формы движения жидкости, например.
Анализ данных — это просто?
Да. А так же интересно. Наряду с особенной важностью для всего человечества изучать большие данные стоит относительная простота в самостоятельном их изучении и применении полученного «ответа» (от энтузиаста к энтузиастам). Для решения задачи классификации сегодня имеется огромное количество ресурсов; опуская большинство из них, можно воспользоваться средствами библиотеки Scikit-learn (SKlearn). Создаём свою первую обучаемую машину:
Вот мы и создали простейшую машину, способную предсказывать (или классифицировать) значения аргументов по их признакам.
— Если все так просто, почему до сих пор не каждый предсказывает, например, цены на валюту?
С этими словами можно было бы закончить статью, однако делать я этого, конечно же, не буду (буду конечно, но позже) существуют определенные нюансы выполнения корректности прогнозов для поставленных задач. Далеко не каждая задача решается вот так легко (о чем подробнее можно прочитать здесь)
Ближе к делу
— Получается, зарабатывать на этом деле я не сразу смогу?
Итак, сегодня нам потребуются:
Дальнейшее использование требует от читателя некоторых знаний о синтаксисе Python и его возможностях (в конце статьи будут представлены ссылки на полезные ресурсы, среди них и «основы Python 3»).
Как обычно, импортируем необходимые для работы библиотеки:
— Ладно, с Numpy всё понятно. Но зачем нам Pandas, да и еще read_csv?
Иногда бывает удобно «визуализировать» имеющиеся данные, тогда с ними становится проще работать. Тем более, большинство датасетов с популярного сервиса Kaggle собрано пользователями в формате CSV.
— Помнится, ты использовал слово «датасет». Так что же это такое?
Датасет — выборка данных, обычно в формате «множество из множеств признаков» → «некоторые значения» (которыми могут быть, например, цены на жильё, или порядковый номер множества некоторых классов), где X — множество признаков, а y — те самые некоторые значения. Определять, например, правильные индексы для множества классов — задача классификации, а искать целевые значения (такие как цена, или расстояния до объектов) — задача ранжирования. Подробнее о видах машинного обучения можно прочесть в статьях и публикациях, ссылки на которые, как и обещал, будут в конце статьи.
Знакомимся с данными
Предложенный датасет можно скачать здесь. Ссылка на исходные данные и описание признаков будет в конце статьи. По представленным параметрам нам предлагается определять, к какому сорту относится то или иное вино. Теперь мы можем разобраться, что же там происходит:
Работая в Jupyter notebook, получаем такой ответ:

Это значит, что теперь нам доступны данные для анализа. В первом столбце значения Grade показывают, к какому сорту относится вино, а остальные столбцы — признаки, по которым их можно различать. Попробуйте ввести вместо data.head() просто data — теперь для просмотра вам доступна не только «верхняя часть» датасета.
Простая реализация задачи на классификацию
Переходим к основной части статьи — решаем задачу классификации. Всё по порядку:
Создаем массивы, где X — признаки (с 1 по 13 колонки), y — классы (0ая колонка). Затем, чтобы собрать тестовую и обучающую выборку из исходных данных, воспользуемся удобной функцией кросс-валидации train_test_split, реализованной в scikit-learn. С готовыми выборками работаем дальше — импортируем RandomForestClassifier из ensemble в sklearn. Этот класс содержит в себе все необходимые для обучения и тестирования машины методы и функции. Присваиваем переменной clf (classifier) класс RandomForestClassifier, затем вызовом функции fit() обучаем машину из класса clf, где X_train — признаки категорий y_train. Теперь можно использовать встроенную в класс метрику score, чтобы определить точность предсказанных для X_test категорий по истинным значениям этих категорий y_test. При использовании данной метрики выводится значение точности от 0 до 1, где 1 100% Готово!
— Неплохая точность. Всегда ли так получается?
Для решения задач на классификацию важным фактором является выбор наилучших параметров для обучающей выборки категорий. Чем больше, тем лучше. Но не всегда (об этом также можно прочитать подробнее в интернете, однако, скорее всего, я напишу об этом ещё одну статью, рассчитанную на начинающих).
— Слишком легко. Больше мяса!
Для наглядного просмотра результата обучения на данном датасете можно привести такой пример: оставив только два параметра, чтобы задать их в двумерном пространстве, построим график обученной выборки (получится примерно такой график, он зависит от обучения):

Да, с уменьшением количества признаков, падает и точность распознавания. И график получился не особенно-то красивым, но это и не решающее в простом анализе: вполне наглядно видно, как машина выделила обучающую выборку (точки) и сравнила её с предсказанными (заливка) значениями.
Предлагаю читателю самостоятельно узнать почему и как он работает.
Последнее слово
Надеюсь, данная статья помогла хоть чуть-чуть освоиться Вам в разработке простого машинного обучения на Python. Этих знаний будет достаточно, чтобы продолжить интенсивный курс по дальнейшему изучению BigData+Machine Learning. Главное, переходить от простого к углубленному постепенно. А вот полезные ресурсы и статьи, как и обещал:
Материалы, вдохновившие автора на создание данной статьи
Более углубленное изучение использования машинного обучения с Python стало возможным, и более простым благодаря преподавателям с Яндекса — этот курс обладает всеми необходимыми средствами объяснения, как же работает вся система, рассказывается подробнее о видах машинного обучения итд.
Файл сегодняшнего датасета был взят отсюда и несколько модифицирован.
Где брать данные, или «хранилище датасетов» — здесь собрано огромное количество данных от самых разных источников. Очень полезно тренироваться на реальных данных.
Буду признателен за поддержку по улучшению данной статьи, а так же готов к любому виду конструктивной критики.