Что такое ocr
Что такое ocr
Что такое OCR и как это работает
Иногда вам необходимо отсканировать документы, которые содержат рукописные заметки или страницы из печатной книги. Именно здесь может пригодиться оптическое распознавание символов (OCR). Эта полезная технология анализирует печатный или рукописный текст и превращает его в редактируемый цифровой файл. В данной статье мы обсудим, как работает эта технология и почему она так полезна.
Что такое OCR
OCR создает цифровую копию отсканированных, напечатанных или напечатанных символов. Этот метод широко используется для импорта данных, особенно для различных типов данных, записанных на бумаге, например, счета, паспорта, документы, визитки, письма или распечатки.
Когда текст оцифрован, поиск и редактирование текста могут быть выполнены в электронном виде. Кроме того, технология позволяет сохранять документы более компактно, а также отображать их в Интернете.

Как работает OCR
Когда сканированная или рукописная страница проходит процесс сканирования, она сохраняется как растровый файл формата TIF. Мы можем прочитать это изображение, когда оно отображается на экране. Однако для компьютера это всего лишь серия белых и черных точек. Он просматривает каждую строку изображения и определяет, соответствуют ли серии точек определенному числу или букве.

Преимущества OCR
1. Поиск и обработка данных
Возможность распознавания текста для создания текстовой версии отсканированных документов позволяет искать текст и находить разделы документа путем поиска по ключевым словам. Данная технология также позволяет редактировать документ с помощью текстового редактора.
2. Помощь для слепых и слабовидящих
Программы чтения с экрана могут декодировать машиночитаемый текст и считывать слова на экране, чтобы люди с нарушениями зрения могли понимать данных документ.
3. Более быстрый ввод данных
Как правило, OCR может значительно повысить эффективность и результативность офисной работы. Это связано с тем, что в большинстве офисов выполняется много операций сканирования с большим количеством документов и существует большая потребность в высокой производительности и более эффективных процессах.

Что программное обеспечение OCR может сделать для вас

В дополнение к OCR, PDFelement также объединяет создание, редактирование и преобразование PDF в один пакет. Вы можете редактировать PDF-текст, изображения и страницы, комментировать и отмечать PDF-файлы или конвертировать PDF-файлы в файлы различных типов или получать информацию из них.

Publicado por Clara Durand
Atualizado: 08/09/2022
Что такое оптическое распознавание символов?
Оптическое распознавание символов (OCR) позволяет извлекать печатный или рукописный текст из изображений, таких как фото вывесок и продуктов, а также из документов — счетов, ведомостей, финансовых отчетов, статей и т. д. Технологии OCR Майкрософт поддерживают извлечение печатного текста на нескольких языках.
Чтобы приступить к работе с REST API или клиентским пакетом SDK, следуйте инструкциям из краткого руководства. Вы также можете быстро и легко опробовать возможности OCR в браузере с помощью Vision Studio.

Эта документация включает статьи следующих видов:
Чтобы узнать о более структурированном подходе, изучите модуль обучения OCR.
API чтения
API чтения Компьютерного зрения — это новейшая технология оптического распознавания символов (узнайте о новых возможностях), которая позволяет извлекать печатный текст (на нескольких языках), рукописный текст (только на английском языке), а также цифры и символы валют из изображений и многостраничных PDF-документов. Она оптимизирована для извлечения текста из изображений с большим объемом текста и многостраничных PDF-документов на различных языках. API может извлекать печатный и рукописный текст из одного и того же изображения или документа.

Требования к входным данным
При вызове Read в качестве входных данных используются изображения и документы. Для них действуют следующие требования:
Поддерживаемые языки
Последняя общедоступная модель API чтения поддерживает 164 языка для печатного и 9 языков для рукописного текста.
OCR для печатного текста включает поддержку английского, французского, немецкого, итальянского, португальского, испанского, китайского, японского, корейского, русского, арабского, хинди и других международных языков, использующих латиницу, кириллицу, арабское письмо и символы деванагари.
Распознавание рукописного текста включает поддержку английского, испанского, итальянского, китайского (упрощенное письмо), корейского, немецкого, португальского, французского и японского языков.
Узнайте, как указать версию модели для использования предварительных версий поддержки языков и функций. См. полный список языков, поддерживаемых OCR.
Основные возможности
Функция Read API включает следующие функции.
Использование облачного API или развертывание в локальной среде
Для большинства клиентов рекомендуется использовать облачные версии API чтения версии 3.x: их легко интегрировать и начать с ними работу. Azure и служба Компьютерное зрение обеспечивают масштабирование, производительность, безопасность данных и соответствие требованиям, а вы можете сосредоточиться на обслуживании своих клиентов.
Контейнер Docker для чтения (предварительная версия) позволяет развертывать новые возможности OCR в собственной локальной среде. Контейнеры соответствуют конкретным требованиям к безопасности и управлению данными.
Операции RecognizeText и ocr Компьютерного зрения более не поддерживаются и находятся в процессе вывода из эксплуатации. Вместо них следует использовать API чтения, рассмотренные в этой статье. Существующим клиентам следует перейти на использование API чтения.
Конфиденциальность и безопасность данных
Как и в случае со всеми другими Cognitive Services, разработчикам, использующим API компьютерного зрения, следует учитывать политику корпорации Майкрософт касательно клиентских данных. Дополнительные сведения см. на странице о Cognitive Services Центра управления безопасностью Майкрософт.
Из пикселей — в буквы: как работает распознавание текста
— Я угадаю это слово с трех букв! — Угадывай! Рассказываем о том, как устроены системы оптического распознавания символов (OCR)

Что такое OCR?
OCR (англ. optical character recognition, оптическое распознавание символов) — это технология автоматического анализа текста и превращения его в данные, которые может обрабатывать компьютер.
Когда человек читает текст, он распознает символы с помощью глаз и мозга. У компьютера в роли глаз выступает камера сканера, которая создает графическое изображение текстовой страницы (например, в формате JPG). Для компьютера нет разницы между фотографией текста и фотографией дома: и то, и другое — набор пикселей.

Именно OCR превращает изображение текста в текст. А с текстом уже можно делать что угодно.
Как это устроено?
Представьте, что в алфавите есть только одна буква «А». Сделает ли это задачу преобразования картинки в текст проще? Нет. Дело в том, что у каждой буквы (и любой другой графемы) есть аллографы — различные варианты начертания.
Человек легко поймет, что все это буква «А». Для компьютера же есть два способа решения проблемы: распознавать символы целостно (распознавание паттерна) или выделять отдельные черты, из которых состоит символ (выявление признаков).
В 1960-х годах был создан специальный шрифт OCR-A, который использовался в документах типа банковских чеков. Каждая буква в нем была одинаковой ширины (т.н. шрифт фиксированной ширины или моноширинный шрифт).
Принтеры для чеков работали с этим шрифтом, и для его распознавания было разработано программное обеспечение. Поскольку шрифт был стандартизирован, его распознавание стало относительно простой задачей. Следующим шагом стало обучение программ OCR распознавать символы еще в нескольких самых распространенных шрифтах (Times, Helvetica, Courier и т.д.).
Этот способ еще называют интеллектуальным распознаванием символов (англ. intelligent character recognition, ICR). Представьте, что вы — OCR-программа, которой дали множество разных букв, написанных разными шрифтами. Как вам отобрать из этого множества все буквы «А», если каждая из них немного отличается от другой?
Можно использовать такое правило: если видишь две линии, сходящиеся наверху в центре под углом, а посередине между ними горизонтальная линия, то это буква «А». Это правило поможет распознать все буквы «А» независимо от шрифта. Вместо распознавания паттерна выделяются характерные индивидуальные черты, из которых состоит символ. Большинство современных омнишрифтовых (умеющих распознавать любой шрифт) OCR-программ работают по этому принципу. Чаще всего в них используются классификаторы на основе машинного обучения (т.к. фактически перед нами стоит задача классификации картинок по классам-буквам) в последнее время некоторые OCR-движки перешли на нейронные сети.
Что делать с рукописным вводом?
Человек способен догадаться о смысле предложения, даже если оно написано самым неразборчивым почерком (если речь не идет о рецепте на лекарства, конечно).
Задачу для компьютера иногда упрощают. Например, людей просят писать почтовый индекс в специальном месте на конверте специальным шрифтом. Формы, созданные для дальнейшей обработки компьютером, обычно имеют отдельные поля, которые просят заполнять печатными буквами.
Планшеты и смартфоны, которые поддерживают рукописный ввод, часто используют принцип выявления признаков. При написании буквы «А» экран «чувствует», что сначала пользователь написал одну линию под углом, затем вторую, и, наконец, провел горизонтальную черту между ними. Компьютеру помогает то, что все признаки появляются последовательно, один за другим, в отличие от варианта, когда весь текст уже записан от руки на бумаге.
OCR по шагам
Чем лучше качество исходного текста на бумажном носителе, тем лучше будет качество распознавания. А вот старый шрифт, пятна от кофе или чернил, заломы бумаги понижают шансы.
Большинство современных OCR-программ сканируют страницу, распознают текст, а затем сканируют следующую страницу. Первый этап распознавания заключается в создании копии черно-белого цвета или в оттенках серого. Если исходное отсканированное изображение идеально, то все черное — это символы, а все белое — фон.
Хорошие OCR-программы автоматически отмечают трудные элементы структуры страницы — колонки, таблицы и картинки. Все OCR-программы распознают текст последовательно, символ за символом, словом за словом и строчка за строчкой.
Сначала OCR-программа объединяет пиксели в возможные буквы, а буквы — в возможные слова. Затем система сопоставляет варианты слов со словарем. Если слово найдено, оно отмечается как распознанное. Если слово не найдено, программа предоставляет наиболее вероятный вариант и, соответственно, качество распознавания будет не таким высоким.
Некоторые программы дают возможность просмотреть и исправить ошибки на каждой странице. Для этого они используют встроенную проверку орфографии и выделяют неверно написанные слова, что может указывать на неправильное распознавание. Продвинутые OCR-программы используют так называемый метод поиска соседа, чтобы найти слова, которые часто встречаются рядом. Этот метод позволяет исправить неверно распознанное словосочетание «тающая собака» на «лающая собака».
Кроме того, некоторые проекты, которые занимаются оцифровкой и распознаванием текстов, прибегают к помощи волонтеров: распознанные тексты выкладываются в открытый доступ для вычитки и проверки ошибок распознавания.
Для высокой точности распознавания исторического текста с необычными графическими символами, отличающимися от современных шрифтов, необходимо извлечь соответствующие изображения из документов. Для языков с небольшим набором символов это можно сделать вручную, но для языков со сложными системами письменности (например, иероглифических) ручной сбор этих данных нецелесообразен.
Для распознавания исторических китайских текстов требуется внести в OCR-программу как минимум 3000 символов, которые имеют разную частотность. Если для распознавания исторических английских текстов достаточно ручной разметки нескольких десятков страниц, то аналогичный процесс для китайского языка потребует анализа десятков тысяч страниц.
В то же время многие исторические варианты китайской письменности имеют высокую степень сходства с современным письмом, поэтому модели распознавания символов, обученные на современных данных, часто могут давать приемлемые результаты на исторических данных, хоть и со сниженной точностью. Этот факт вместе с использованием корпусов позволяет создать систему для распознавания исторических китайских текстов. Для этого исследователь Д. Стеджен (Donald Sturgeon) из Гарварда обработал два корпуса: корпус транскрибированных исторических документов и корпус отсканированных документов желаемого стиля.
После предварительной обработки изображений и этапов сегментации символов процедура извлечения обучающих данных состояла из:
1) применения модели распознавания символов, обученной исключительно на современных документах, к историческим документам для получения промежуточного результата оптического распознавания с низкой точностью;
2) использование этого промежуточного результата для соотнесения изображения с его вероятной транскрипцией;
3) извлечение изображений размеченных символов на основе этого соотнесения;
4) выбор из размеченных символов подходящих обучающих примеров.
Полученные данные могут использоваться без проверки для обучения новой модели распознавания символов, позволяющей достичь более высокой точности на аналогичном материале.
В 2018 году Антиплагиат анонсировал большую новость. Сайт внедряет в свою систему проверки, модуль OCR. По заявлениями разработчиков компании Анти-плагиат, внедрение данного модуля автоматически означает, что искусственное повышение уникальности текста (кодирование, макросы, технический подъем) теперь будут неэффективны.
Так ли это? Давайте разбираться. В статье мы расскажем, что такое модуль OCR в антиплагиате и так ли он страшен и непроходим, как о нем говорят.
Модуль ОCR на практике (при проверке)
Как обойти ОCR в Антиплагиате
OCR – дословно, переводится как “оптическое распознавание символов”. Для лучшего понимания приведем пример. Все знают, что такое сканер. И многие не раз делали такую процедуру – сканировали какой нибудь текст с книги, а затем, с помощью программы (самая известная Abbyy FineReader) производили распознавание текста. В результате текст с книги оказывался в печатном виде на компьютере.
Именно это и внедрил Антиплагиат в свою систему проверки, пока правда, только в платную его версию Антиплагиат ВУЗ.
На нашем сервисе вы можете заказать проверку документа через Антиплагиат ВУЗ вместе с модулем ОCR. Также мы поможем вам повысить уникальность текста. За пару минут ваша работа получить высокий процент оригинальности до 80-90%. При этом ваш текст не изменится, только файл будет перекодирован незаметно для человеческого глаза.
Заказывайте повышение прямо сейчас и мы пришлем вам готовый вариант бесплатно. Сначала выубедитесь в том, что кодировка текста реально работает. Заранее ничего платить не нужно.
МОДУЛЬ OCR – КАК ЭТО РАБОТАЕТ?
По замыслу разработчиков Антиплагиата, при анализе текста с помощью модуля OCR (оптическое распознование текста), система будет, по простому говоря, делать фотографию проверяемого – видимого текста, после чего он будет распознаваться онлайн и именно уже распознанный текст, будет подвергаться проверке на уникальность в программе.
Логично, что если это действительно будет работать, то все фишки со скрытым текстом, символами и прочими махинациями с текстом, направленные на повышения уникальности, будет неэффективны. Они попросту не будут распознаны.
МОДУЛЬ ОКР НА ПРАКТИКЕ (ПРИ ПРОВЕРКЕ)
На практике, дела обстоят совершенно иначе.
Данная функция уже больше года присутствует в системах проверки антиплагиата и ей уже можно пользоваться, однако, алгоритм с распознаванием не работает.
Антиплагиат заявляет, что оптическое распознавание символов внедрено, но по факту его нет. Это мы проверили на практике.
На деле, никакого оптического рапознавания не происходит, а вместо OCR происходит более глубокий анализ документа с показанием более низкого процента.
Включение модуля OCR действительно делает процесс технического повышения уникальности текста более сложным, но все равно обойти антиплагиат возможно, без больших проблем.
К тому же данный модуль в антиплагиате не включен автоматически. Чтобы его активировать, нужно нажать на галочку(см.фото)
На практике преподаватели практически не пользуются OCR при проверках. Лишь 1 преподаватель из 10000 подключает данную функцию перед проверкой документа.
Несколько десятков вузов вообще отказались от данной функции, ведь стоит она дорого, а эффекта особого не приносит.
Настоящее оптическое распознавание символов (ОКР) в антиплагиате это утопия. Кто активно пользуется системой Антиплагиат, часто сталкиваются с дикими перегрузками на сайте, даже в обычные месяцы.
А в месяцы сессии, одну работу система может проверять по часу. Сервера по-просту не выдерживают нагрузки.
Если же внедрить полноценный модуль OCR в антиплагиат, чтобы он работал, действительно используя распознавание текста, процесс анализа документов затянется на часы.
Системе антиплагиат нужно будет вначале сделать фото текста, затем совершить онлайн распознавание текст и лишь затем, провести его проверку на оригинальность.
Проверять работу по несколько десятков минут и даже часов никому не интересно, в результате от системы Антиплагиат будут отказываться. Речь идет именно о вузовской версии Антиплагиат вуз, за которую ежегодно, компания получает около 1 миллиона рублей с учебного заведения.
Более того, создать непроходимую систему антиплагиата, элементарно, невыгодно самим разработчикам.
Сегодня более 80% студентов повышают антиплагиат, используя кодирование и технический подъем. Если система станет не проходимой, нас ждет миллионы отчисленных студентов, что вызовет огромный общественный резонанс и возможно, отмену системы Антиплагиат в принципе.
“Хозяевам” антиплагиата это совершенно не выгодно. Ведь кормушка под названием “Антиплагиат” приносит колосальные прибыли их владельцам.
Вы наверняка часто слышали фразу «В нашем вузе используется супер-мега-крутой антиплагиат, и никто не сможет его обмануть». Мы решили узнать, что конкретно может помешать пройти проверку на уникальность, кроме OCR. Посмотрите наше видео, чтобы узнать правду.
КАК ОБОЙТИ OCR В АНТИПЛАГИАТЕ
Если вам необходимо повысить уникальность текста таким образом, чтобы при проверке с OCR процент показало высокий, можете обратиться к нам, мы поможем сделать это каждому клиенту.
Мы имеет доступ к системе Антиплагиат ВУЗ в которой подключен данный модуль, и сделаем кодировку таким образом, что документ пройдет проверку на уникальность даже с подключением OCR.
Мы работаем без предоплаты. Высылаем работу вперед, оплатить услугу можно после проверки текста на уникальность.
OCR-конвейер для обработки документов
Сегодня я расскажу о том, как создавалась система для переноса текста из бумажных документов в электронную форму. Мы рассмотрим два основных этапа: выделение областей с текстом на сканах документов и распознавание символов в них. Кроме того, я поделюсь сложностями, с которыми пришлось столкнуться, способами их решения, а также вариантами развития системы.

Первичным переводом документа в электронную форму является его сканирование или фотографирование, в результате которого получается графический файл в виде фотографии или скана. Однако такие файлы, особенно высокого разрешения, занимают много места на диске, и текст в них невозможно редактировать. В связи с этим, целесообразно извлекать текст из графических файлов, что успешно делается с применением OCR.
Про OCR и цели
Оптическое распознавание символов (OCR) — перевод изображений машинописного, рукописного или печатного текста в электронные текстовые данные. Обработка данных при помощи OCR может применяться для самых различных задач:
В настоящее время все больше организаций переходят от бумажной формы документооборота к электронной. На одном из моих недавних проектов для компании с большими объемами бумажных документов, требовалось перенести информацию, накопившуюся в сканах (около нескольких петабайт), в электронную форму и добавить возможность обработки новых отсканированных документов.
Мы выяснили, что использование готовых продуктов для решения нашей задачи приводило бы к большим затратам и низкой производительности, вызванной ограничениями объемов обрабатываемых документов. Поэтому мы решили разработать собственную систему OCR по принципу конвейера (OCR-pipeline), в которой последовательно выполняются следующие операции:
Извлечение слов и строк
Перед распознаванием символов из изображения документа целесообразно извлечь части, которые ограничивают слова или строки текста. Способов извлечения много. Существует два основных подхода — нейросетевой и с использованием компьютерного зрения. Остановимся на них подробнее.
В последнее время для детекции слов на изображениях все активнее применяются нейронные сети. При помощи сетей семейства resnet можно выделить прямоугольные рамки с текстом. Однако если документы содержат много слов и строк, то данные сети работают довольно медленно. Мы установили, что вычислительные затраты в этих случаях существенно превышают затраты с использованием методов компьютерного зрения.
Кроме того, нейронные сети resnet имеют сложную архитектуру и применительно к данной задаче их сложнее обучить, так как они больше предназначены для классификации изображений и обнаружения небольшого количества блоков текста. Их использование значительно замедлило бы разработку конвейера и в некоторых случаях снизило бы производительность. Поэтому мы решили остановиться на методах детекции строк посредством компьютерного зрения, в частности, на методе Максимальных Стабильных Экстремальных Регионов (MSER) [1].

Примеры MSER-детекции строк в документах
В ходе MSER-детекции текст в бинаризованном изображении скана предварительно «размазывается» в пятна. На основе субпиксельных вычислений полученные пятна ограничиваются связными областями и обрамляются в прямоугольные рамки. Таким образом, происходит сжатие исходных данных — из скана с документом извлекаются изображения, ограничивающие слова и строки. Стоит отметить, что данный метод не зависит от цвета извлекаемого текста. Важно лишь только то, чтобы он был достаточно контрастен по отношению к фону.
OCR AI
Следующим этапом после MSER-извлечения изображений с текстом является распознавание символов в них. В последнее время исследования в области AI показали, что распознавание символов на изображениях успешней всего выполняется на основе глубокого машинного обучения. В частности, используются нейронные сети, содержащие много уровней (глубокие нейронные сети), которые способны самостоятельно накапливать признаки и представления в обрабатываемых данных.
Генерация данных для обучения
Нейронные сети глубокого обучения, как правило, требуют больших объемов обучающих выборок для качественного распознавания. Ручная разметка и сбор обучающих данных занимают много времени и требуют больших трудозатрат, поэтому все чаще используются готовые датасеты или искусственно генерируются уже размеченные данные. При формировании обучающих выборок для устойчивости системы OCR к искажениям важно использовать как наборы строк хорошего качества, так и строки с различными эффектами и искажениями, обусловленные особенностями сканирования или плохим качеством печати в документах.

В качестве обучающей выборки мы использовали датасет University of Washington (UW3), состоящий из более чем 80K строк из сканированных страниц с современным деловым и научным английским языком. Однако набор геометрических и фотометрических искажений, а также количество используемых шрифтов в строках оказались недостаточными. Поэтому мы решили дополнить обучающую выборку искусственно сгенерированными строками при помощи разработанного автоматического генератора строк текста разного шрифта, цвета, фона, интерлиньяжа и т. п. Использовались 10 наиболее популярных шрифтов, встречающихся в документах: Times New Roman, Helvetica, Baskerville, Computer Modern, Arial и другие.
Дополнительной универсальности относительно шрифтов удалось достичь благодаря использованию информации из Font Map, в которой взаимное расположение шрифтов определяет их сходство — чем ближе два шрифта друг к другу, тем более они похожи. Для дообучения сети было дополнительно отобрано 10 шрифтов на карте, наиболее удаленных от тех, на которых модель уже обучена.
Карта шрифтов Font Map fontmap.ideo.com
Архитектура сети CNN
Входные данные для обучения и распознавания сети — это части изображений сканов со строками или словами, извлеченные на этапе MSER-детекции. Выходные данные — это упорядоченные наборы символов, формирующие текст в электронном формате.
Для распознавания символов в картинках эффективно используются сверточные нейронные сети CNN [2], формирующие представления частей изображений подобно зрительной системе человека.
Сверточная нейронная сеть обычно представляет собой чередование сверточных и пулинговых слоев, объединенных в сверточные блоки (сonvolutional blocks) и полносвязных слоев на выходе (fully connected layers). В сверточном слое веса объединяются в так называемые карты признаков (feature maps). Каждый из нейронов карты признаков связан с частью нейронов предыдущего слоя.

Сети CNN базируются на математических операциях свертки (convolutions) и последующих сокращениях размерности (pooling) с применением пороговых функций, исключающих отрицательные значения весов. Карты признаков после всех преобразований в сверточных блоках конкатенируются в единый вектор (concatenation) на вход полносвязной сети. Рассмотрим операции свертки и сокращения размерности подробнее.
Вычисления в сверточной сети
В сверточном слое входное исходное изображение или карта предыдущего сверточного блока (input data) подвергаются операции свертки (сonvolution) при помощи матрицы небольшого размера (ядра свертки, сonvolution kernel), которую двигают по матрице, описывающей входные данные (input data). Выходными данными (output data) является матрица, состоящая из значений суммы попарных произведений соответствующей части входных данных с ядром свертки. На рисунке показан пример сверточного слоя с ядром свертки размера 3X3.

В слое пулинга уменьшается размерность выходных данных сверточного слоя в два этапа.

На рисунке показан пример слоя пулинга с сокращением размерности в два раза с применением ReLU и max-pooling. Выходные значения передаются на вход следующего сверточного блока или вытягиваются в вектор для полносвязного слоя, если сверточных блоков больше нет.
Архитектура сети для OCR
В нашем случае одних сверточных блоков недостаточно, поскольку обрабатываются большие объемы данных и необходим учет последовательности символов в строках. Поэтому мы использовали гибридную архитектуру, состоящую из
Вычислительные эксперименты
В ходе обучения мы провели серию экспериментов относительно наборов строк в обучающих выборках. Выделим основные из них: на основе только сгенерированных строк (10 наиболее популярных шрифтов + 10 шрифтов из Font Map), на основе сгенерированных строк с тремя наиболее используемыми в документах шрифтами (Times New Roman, Helvetica, Computer Modern) со строками из датасета UW3 и на основе сгенерированных строк (10 + 10 шрифтов) со строками из датасета UW3.

Отметим, что к концу итерационного процесса максимальная точность (accuracy) на валидационной выборке практически одинакова. Точность по тестовой выборке, напротив, имеет существенное различие — добавление строк из датасета UW3 к сгенерированным строкам повышает точность распознавания. При этом увеличение количества шрифтов в искусственно сгенерированных строках также несколько увеличивает точность распознавания.
Обучение нейросети происходило по принципу «раннего останова»: через определенное количество итераций выполнялось распознавание случайно выбранного подмножества строк из обучающей (валидационной) выборки. Если в течение нескольких таких проверок максимальное значение точности не изменялось, то итерационный процесс обучения прекращался и сохранялись веса нейронной сети для распознавания строк из документов. Время обучения рассчитывалось от начала итерационного процесса до останова. Использовались графические ускорители GPU Nvidia семейства Tesla (K8 и V100).
Рассматривались документы с разрешением сканирования от 96dpi на английском языке, в том числе с присутствием цветного текста. Построенная архитектура позволила достичь точности распознавания символов до 95-99%.
Таким образом, в качестве выходных данных мы получаем символы, объединенные в слова или строки, формирующие электронные документы.
Конвейер
Значительное ускорение обработки документов было достигнуто благодаря организации нашей системы распознавания по принципу конвейера с минимизацией простоев, а также за счет распараллеливания вычислений в CPU и GPU и рационального использования памяти. Система развертывалась с помощью Docker и Kubernetes.
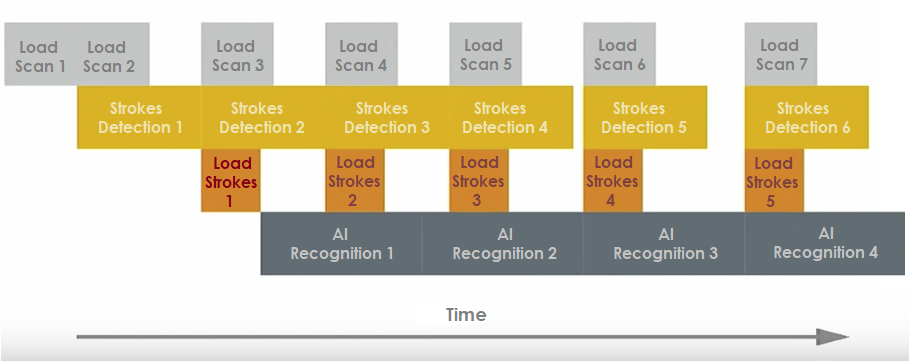
Организация системы OCR AI распознавания по принципу конвейера.
Длина прямоугольных блоков, описывающих процедуру обработки, схематично соответствует интервалу времени. Время выполнения каждой из процедур может различаться в зависимости от количества символов в документе.
Load Scan i — загрузка скана i-го документа,
Strokes Detection i — извлечение строк из i-го документа при помощи MSER,
Load Strokes i — OpenCV-предобработка и нормализация извлеченных строк i-го документа и загрузка на вход сети,
AI Recognition i — распознавание символов в строках i-го документа на основе построенной глубокой сети.
Для повышения качества MSER-детекции мы дополнительно применяли математические методы цифровой обработки изображений, которые в том числе исключали нежелательные шумы, естественно возникающие при сканировании бумажных документов. Обработка изображений и MSER-детекция слов и строк реализовывалась на языке Python с использованием библиотеки компьютерного зрения OpenCV.
Для повышения качества обучения, защиты от переобучения и последующего распознавания в нейронной сети AI мы применяли адаптивное обновление весов сети [5], dropout-прореживание [6] и батч-нормализацию [7]. Реализация нейронной сети глубокого обучения также была написана на Python c использованием фреймворка TensorFlow. Вычисления на GPU от Nvidia поддерживались благодаря внедрению технологий CUDA и cuDNN.
Дополнительного прироста производительности предполагается достичь при помощи технологии TensorRT [8], заточенной под оптимальное использование весов сети при вычислениях в GPU, производимых Nvidia (например, таких, как Tesla или k8). При этом веса обученных моделей преобразуются в более сжатый формат с плавающей точкой. Это позволяет более чем в 40 раз повысить скорость вычислений в GPU по сравнению с CPU без видимых потерь точности распознавания.
Что дальше?
Выделим несколько направлений развития нашей системы.
Что такое OCR или Оптическое распознавание символов
Что такое OCR?

OCR – это технология оптического распознавания символов и их извлечения из картинок, сканов и PDF-файлов. Технология обрабатывает символы и превращает их в код, который может быть прочитан компьютером. Каждый символ сканируется отдельно, поэтому в результате вы получаете полноценные редактируемые текстовые файлы, а не набор JPEG-картинок.
О технологии OCR нужно знать три основных пункта, которые скрыты в аббревиатуре:
Человек распознает символы с помощью глаз и мозга. Компьютер использует камеру сканера, которая создает графическое изображение страницы текста. Для компьютера нет разницы между сканом текстового документа и изображением: и то, и другое – набор пикселей.
Под символами мы понимаем любую композицию пикселей или элементов, которые образуют букву. Отличительная особенность технологии: она работает как с печатными шрифтами, так и с рукописными.
OCR использует комбинацию технологии и оборудования. Оптический сканер помогает создать цифровое изображение. Программное обеспечение OCR идентифицирует буквы на этом изображении и преобразует их в слова.
Этот метод работает путем идентификации символа в целом. Мы можем определить строку текста, найдя ряды белых пикселей с рядами черных пикселей между ними. Таким же образом мы можем увидеть, где начинается и заканчивается отдельный символ.
Программа распознавания преобразует файл изображения с символами в двоичную матрицу: белые пиксели – это 0, а черные – 1. Затем она сопоставляет символ с конкретной буквой шрифта.
Следующим шагом было повышение точности OCR. Позже для этого стали использовать искусственный интеллект.
Вы знаете, что взять слова с экрана компьютера и перенести их на физический лист бумаги довольно просто – достаточно нажать кнопку печати, и через несколько мгновений документ будет у вас в руках.
Но перенести отсканированный бумажный документ в ваш компьютер – на самом деле немного сложнее. Очевидно, что сканеры довольно понятны в использовании, но они, по сути, создают лишь цифровое изображение документа и сохраняют его в компьютере. Это изображение обычно не очень четкое из-за сжатия файла и частичек пыли в сканере.

Но самое главное – вы не можете редактировать отсканированные документы с помощью текстового редактора. Это происходит потому, что сканер не распознает каждый отдельный символ.
А вот как программное обеспечение OCR понимает, на что оно смотрит:
Процесс извлечения данных начинается после того, как вы загрузите документ.
Первый шаг – отсечь артефакты, чтобы программа OCR могла сосредоточиться на тексте – она удаляет дефекты изображения и графику.
Программа OCR выравнивает текст и преобразует любые цвета или оттенки серого на изображении в черно-белые. При этом черный цвет рассматривается как символы, а белый – как фон.
Следующий шаг – определить, какие символы находятся на странице. Более простые формы OCR сравнивают каждую отсканированную букву пиксель за пикселем с базой данных шрифтов и принимают решение о наиболее близком совпадении. Более интеллектуальная технология OCR разбивает каждый символ на элементы, такие как кривые и прямые линии. Он сопоставляет физические особенности и реальные буквы.
Иногда OCR также использует встроенный словарь, который помогает распознать слово, если в нем была допущена опечатка.
Когда символ идентифицирован, он преобразуется в код ASCII, который может быть использован компьютерными системами. Перед сохранением для последующего использования обработанные тексты необходимо проверить на наличие ошибок.
Как можно применить OCR?
Эта технология замечательна тем, что ее можно использовать в любой отрасли, где компании имеют дело с текстовыми данными. Так что, по сути, она подходит для всех отделов: финансового, юридического, продаж и маркетинга, HR, закупок.

Некоторые варианты использования OCR:
Сканирование печатных документов в версии, которые можно редактировать с помощью обычных редакторов текста.
Индексирование печатного материала для поисковых систем.
Автоматизированная обработка и ввод данных.
Расшифровка документов в текст, который может быть прочитан вслух для пользователей с нарушениями зрения.
Извлечение данных и передача в бухгалтерские программы (квитанции, счета).
Размещение важных подписанных юридических документов в электронной базе данных.
Сортировка писем для доставки почты.
Перевод слов в изображении на заданный язык.
Обеспечение поиска отсканированных книг.
Сегодня каждая компания старается повысить производительность, не тратя при этом много денег.
Вы можете помочь своим текущим и потенциальным клиентам повысить эффективность работы их команд с помощью OCR. Поверьте, эта технология значительно усилит ваше портфолио предоставляемых услуг.
Ваши клиенты знают, что производительность труда снижается, когда их команда завалена десятком бумажных документов. Обработка документов занимает много времени, особенно это касается PDF-файлов, которые нельзя скопировать, вставить или отредактировать.
OCR помогает извлекать данные из таких файлов и передавать их в нужные системы. Это сокращает количество рутинных задач бухгалтеров, юристов, менеджеров по продажам и других специалистов.
Оптическое распознавание символов позволяет командам ваших клиентов работать более продуктивно. Это очень важная часть автоматизации процессов. Они могут сэкономить много часов для сотрудников и позволить им сосредоточиться на увеличении дохода для компании.
Технология OCR может стать частью вашей модели “Автоматизация как услуга” (Automation-as-a-Service). RPA и OCR имеют много взаимодополняющих функций. Внедрив одну из технологий, компания рано или поздно примет на вооружение и вторую. Как поставщик IT-услуг, вы имеете больше шансов выстроить стабильный доход, предлагая эти две технологии вместе.
OCR помогает извлекать текст из любых изображений и файлов и редактировать его.
Любая компания может начать использовать OCR для сокращения ручного труда, что приведет к увеличению доходов.
OCR можно использовать вместе с другими инструментами автоматизации для повышения производительности.
Помогите прочитать, что здесь написано? (OCR)
Тонны архивных бумаг, чеков и счетов проходят сканирование и оцифровку во многих отраслях: в розничной торговле, логистике, банковских услугах и т.п. Компании получают конкурентное преимущество, если быстро оцифровывают и находят нужную информацию.
В 2020 году нам тоже пришлось решать проблему качественной оцифровки документов, и над этим проектом мы с коллегами работали совместно с компанией Verigram. Вот как мы проводили оцифровку документов на примере заказа клиентом SIM-карты прямо из дома.
Оцифровка позволила нам автоматически заполнять юридические документы и заявки на услуги, а также открыла доступ к аналитике фискальных чеков, отслеживанию динамики цен и суммарных трат.
Для преобразования различных типов документов (отсканированные документы, PDF-файлы или фото с цифровой камеры) в редактируемые форматы с возможностью поиска мы используем технологию оптического распознавания символов – Optical Character Recognition (OCR).

Работа со стандартными документами: постановка задачи
Заказ SIM-карты для пользователя выглядит так:
пользователь решает заказать SIM-карту;
фотографирует удостоверение личности для автоматического заполнения анкеты;
курьер доставляет SIM-карту.

Важно: пользователь фотографирует удостоверение личности своим смартфоном со специфическим разрешением камеры, качеством, архитектурой и другими особенностями. А на выходе мы получаем текстовое представление информации загруженного изображения.
Цель проекта OCR: построить быструю и точную кросc-платформенную модель, занимающую небольшой объем памяти на устройстве.

Верхнеуровневая последовательность обработки изображения стандартного документа выглядит так:
Выделяются границы документа, исключая не интересующий нас фон и исправляя перспективу изображения документа.
Выделяются интересующие нас поля: имя, фамилия, год рождения и т.п. На их основе можно построить модель предсказания соответствующего текстового представления для каждого поля.
Post-processing: модель вычищает предсказанный текст.

Локализация границ документа
Загруженное с камеры устройства изображение документа сравнивается с набором заранее подготовленных масок стандартных документов: фронтальная или задняя часть удостоверения, документ нового или старого образца, страницы паспорта или водительские права.

Предварительно делаем pre-processing обработку изображения и в результате ряда морфологических операций получаем соответствующее бинарное (черно-белое) представление.
Техника работает так: в каждом типе документа есть фиксированные поля, не меняющиеся по ширине и высоте. Например, название документа в правом верхнем углу как на картинке ниже. Они служат опорными полями, от которых рассчитывается расстояние до других полей документа. Если количество обнаруженных полей от опорного выше определенного порога для проверочной маски, мы останавливаемся на ней. Так подбирается подходящая маска.
 Так выглядит подбор подходящей маски
Так выглядит подбор подходящей маски
исправляется перспектива изображения;
определяется тип документа;
изображение обрезается по найденной маске c удалением фона.
В нашем примере мы выявили, что загруженное фото — это фронтальная часть удостоверения личности Республики Казахстан образца позднее 2014 года. Зная координаты полей, соответствующие этой маске, мы их локализуем и вырезаем для дальнейшей обработки.

Следующий этап — распознавание текста. Но перед этим расскажу, как происходит сбор данных для обучения модели.
Распознавание текста
Данные для обучения
Мы подготавливаем данные для обучения одним из следующих способов.
Первый способ используется, если достаточно реальных данных. Тогда мы выделяем и маркируем поля с помощью аннотационного инструмента CVAT. На выходе получаем XML-файл с названием полей и их атрибутами. Если вернуться к примеру, для обучения модели по распознаванию текста, на вход подаются всевозможные локализованные поля и их соответствующие текстовые представления, считающиеся истинными.

Но чаще всего реальных данных недостаточно или полученный набор не содержит весь словарь символов (например, в реальных данных могут не употребляться некоторые буквы вроде «ъ» или «ь»). Чтобы получить большой набор бесплатных данных и избежать ошибок аннотаторов при заполнении, можно создать синтетические данные с аугментацией.
Сначала генерируем рандомный текст на основе интересующего нас словаря (кириллица, латиница и т.п.) на белом фоне, накладываем на каждый текст 2D-трансформации (повороты, сдвиги, масштабирование и их комбинации), а затем склеиваем их в слово или текст. Другими словами, синтезируем текст на картинке.
 Примеры 2D-трансформаций
Примеры 2D-трансформаций
Показательный пример 2D-трансформации представлен в библиотеке для Python Text-Image-Augmentation-python. На вход подается произвольное изображение (слева), к которому могут применяться разные виды искажений.
 Применяем разные виды искажений
Применяем разные виды искажений 

 Дисторсия, перспектива и растяжение изображения с помощью библиотеки Text-Image-Augmentation-python
Дисторсия, перспектива и растяжение изображения с помощью библиотеки Text-Image-Augmentation-python
После 2D-трансформации на изображение текста добавляются композитные эффекты аугментации: блики, размытия, шумы в виде линий и точек, фон и прочее.
 Пример изображений в сформированной нами обучающей выборке на основе применения аугментации
Пример изображений в сформированной нами обучающей выборке на основе применения аугментации
Так можно создать обучающую выборку.
 Обучающая выборка
Обучающая выборка
Распознавание текста
Следующий этап — распознавание текста стандартного документа. Мы уже подобрали маску и вырезали поля с текстовой информацией. Дальше можно действовать одним из двух способов: сегментировать символы и распознавать каждый по отдельности или предсказывать текст целиком.
Посимвольное распознавание текста

В этом методе строится две модели. Первая сегментирует буквы: находит начало и конец каждого символа на изображении. Вторая модель распознает каждый символ по отдельности, а затем склеивает все символы.
Предсказывание локального текста без сегментации (end-2-end-решение)

Мы использовали второй вариант — распознавание текста без сегментирования на буквы, потому что этот метод оказался для нас менее трудозатратным и более производительным.
В теории, создается нейросетевая модель, которая выдает копию текста, изображение которого подается на вход. Так как текст на изображении может быть написан от руки, искажен, растянут или сжат, символы на выходе модели могут дублироваться.
 Отличие результатов распознавания реальной и идеальной модели
Отличие результатов распознавания реальной и идеальной модели
Чтобы обойти проблему дублирования символов, добавим спецсимвол, например «-», в словарь. На этапе обучения каждое текстовое представление кодируется по следующим правилам декодировки:
два и более повторяющихся символа, встретившиеся до следующего спецсимвола, удаляются, остается только один;
повторение спецсимвола удаляется.

Так во время тренировочного процесса на вход подается изображение, которое проходит конволюционный и рекуррентный слои, после чего создается матрица вероятностей встречаемости символов на каждом шаге.

Истинное значение получает различные представления с соответствующей вероятностью за счет СТС-кодировки. Задача обучения — максимизировать сумму всех представлений истинного значения. После распознавания текста и выбора его представления проводится декодировка, описанная выше.
Архитектура модели по распознаванию текста
Мы попробовали обучить модель на разных архитектурах нейросетей с использованием и без использования рекуррентных слоев по схеме, описанной выше. В итоге остановились на варианте без использования рекуррентных слоев. Также для придания ускорения inference части, мы использовали идеи сетей MobileNet разных версий. Граф нашей модели выглядел так:
 Схема итоговой модели
Схема итоговой модели
Методы декодирования
Хочу выделить два наиболее распространенных метода декодирования: CTC_Greedy_Decoder и Beam_Search.
CTC_Greedy_Decoder-метод на каждом шаге берет индекс, с наибольшей вероятностью соответствующий определенному символу. После чего удаляются дублирующиеся символы и спецсимвол, заданный при тренировке.
Метод «Beam_Search» — лучевой алгоритм, в основании которого лежит принцип: следующий предсказанный символ зависит от предыдущего предсказанного символа. Условные вероятности совстречаемости символов максимизируются и выводится итоговый текст.
Post-processing

Есть вероятность, что в продакшене при скоринге на новых данных модель может ошибаться. Нужно исключить такие моменты или заранее предупредить пользователя о том, что распознавание не получилось, и попросить переснять документ. В этом нам помогает простая процедура постобработки, которая может проверять на предсказание только ограниченного словаря для конкретного поля. Например, для числовых полей выдавать только число.
Другим примером постобработки являются поля с ограниченным набором значений, которые подбираются по словарю на основе редакторского расстояния. Проверка на допустимость значений: в поле даты рождения не могут быть даты 18 века.
Оптимизация модели
Техники оптимизации
На предыдущем этапе мы получили модель размером 600 килобайт, из-за чего распознавание были слишком медленным. Нужно было оптимизировать модель с фокусом на увеличение скорости распознавания текста и уменьшение размера.
В этом нам помогли следующие техники:
Квантование модели, при котором вычисления вещественных чисел переводятся в более быстрые целочисленные вычисления.
«Стрижка» (pruning) ненужных связей. Некоторые веса имеют маленькую магнитуду и оказывают малый эффект на предсказание, их можно обрезать.

Для увеличения скорости распознавания текста используются мобильные версии архитектур нейросеток, например, MobileNetV1 или MobileNetV2.
Так, в результате оптимизации мы получили снижение качества всего на 0,5 %, при этом скорость работы увеличилась в 6 раз, а размер модели снизился до 60 килобайт.
Вывод модели в продуктив
Процесс вывода модели в продуктив выглядит так:

Мы создаем 32-битную TensorFlow модель, замораживаем ее и сохраняем с дополнительными оптимизациями типа weight или unit pruning. Проводим дополнительное 8-битное квантование. После чего компилируем модель в Android- или iOS-библиотеку и деплоим ее в основной проект.
Рекомендации
На этапе развертывания задавайте статическое выделение тензоров в графе модели. Например, в нашем случае скорость увеличилась в два раза после указания фиксированного размера пакета (Batch size).
Не используйте LSTМ- и GRU-сети для обучения на синтетических данных, так как они проверяют совстречаемость символов. В случайно сгенерированных синтетических данных последовательность символов не соответствует реальной ситуации. Помимо этого они вызывают эффект уменьшения скорости, что важно для мобильных устройств, особенно для старых версий.
Аккуратно подбирайте шрифты для обучающей выборки. Подготовьте для вашего словаря набор шрифтов, допустимых для отрисовки интересующих символов. Например, шрифт OCR B Regular не подходит для кириллического словаря.

Пробуйте тренировать собственные модели, поскольку не все opensource-библиотеки могут подойти. Перед тем как тренировать собственные модели, мы пробовали Tesseract и ряд других решений. Так как мы планировали развертывать библиотеку на Android и iOS, их размер был слишком большим. Кроме того, качество распознавания этих библиотек было недостаточным.
Сложности применения технологий OCR в DLP-системах, или Как мы OCR готовим
 Решение задачи распознавания изображений (OCR) сопряжено с различными сложностями. То картинку не получается распознать из-за нестандартной цветовой схемы или из-за искажений. То заказчик хочет распознавать все изображения без каких-либо ограничений, а это далеко не всегда возможно. Проблемы разные, и решить их сходу не всегда удается. В этом посте мы дадим несколько полезных советов, исходя из опыта разруливания реальных ситуаций у заказчиков.
Решение задачи распознавания изображений (OCR) сопряжено с различными сложностями. То картинку не получается распознать из-за нестандартной цветовой схемы или из-за искажений. То заказчик хочет распознавать все изображения без каких-либо ограничений, а это далеко не всегда возможно. Проблемы разные, и решить их сходу не всегда удается. В этом посте мы дадим несколько полезных советов, исходя из опыта разруливания реальных ситуаций у заказчиков.
Но сначала немного истории. Прошло немало времени с момента выхода статьи о том, как мы переписывали сервис фильтрации. В ней мы немного рассказали о фильтрации и обработке сообщений, о том, как устроен наш сервис фильтрации в целом. В этот раз мы постараемся ответить на вопрос «А как же мы обрабатываем изображения, как взаимодействуют сервисы, и что происходит с системой под нагрузкой?» Если оперировать статьей про сервис фильтрации, то сейчас мы будем рассматривать только одну ветку взаимодействия сервисов – это взаимодействие сервиса фильтрации и OCR.

Что такое OCR?
Прежде чем говорить о взаимодействии сервисов и проблемах применения OCR попробуем понять, что такое OCR. Возьмем сложное определение из Википедии.
Оптическое распознавание символов (англ. optical character recognition, OCR) — механический или электронный перевод изображений рукописного, машинописного или печатного текста в текстовые данные, использующиеся для представления символов в компьютере (например, в текстовом редакторе).
Если говорить просто, то взяли картинку, отправили на распознавание, дальше магия вне Хогвартса и получили текст.

Еще можно взять опредление OCR с сайта ABBYY, которое выглядит проще.
Оптическое распознавание символов (англ. Optical Character Recognition – OCR) – это технология, которая позволяет преобразовывать различные типы документов, такие как отсканированные документы, PDF-файлы или фото с цифровой камеры, в редактируемые форматы с возможностью поиска.
А зачем оно (распознавание изображений) нам нужно?
Распознавание изображений мы можем использовать хоть на домашнем ПК для преобразования цифровых изображений в редактируемые текстовые данные.Но стоящая перед нами задача гораздо шире (DLP-система все-таки): нам нужно контролировать поток информации в организации.
DLP-системы давно появились на рынке и сейчас входят в привычный арсенал корпоративных СЗИ (средств защиты информации). Перед DLP стоит задача контроля движения графической информации (отсканированных документов, скриншотов, фотографий). Причем не просто контроля движения графических файлов, а в первую очередь, анализа их содержимого. Система должна уметь понимать, с какой именно информацией она столкнулась, сравнить с образцами защищаемой информации и обеспечить возможности для дальнейшего поиска этой информации пользователем. Применение других средств анализа, таких, как сравнение с цифровыми отпечатками, вычисление хэша, анализ по формату, размеру и структуре файла, также являются ценными источниками информации, но не позволяют ответить на вопрос: «а какой текст передается в данной картинке?» А между тем текст все еще является самым распространённым носителем структурированной информации, в том числе в графических файлах.
Традиционно для распознавания графической информации используют технологию OCR (что это такое мы уже определили). На самом деле OCR – это вообще единственный класс технологий, которые предоставляют возможности извлечения текстовой информации из изображений. Поэтому тут речь не то чтобы о традиционном подходе, а скорее об отсутствии выбора.
Сколько изображений приходит на обработку в DLP-систему?
Неужели нельзя обойтись без OCR? На самом ли деле так много изображений приходит в DLP, что нужно применять OCR? Ответ на этот вопрос – «Да!». За сутки в систему может попадать более миллиона изображений, и во всех этих изображениях может содержаться текст.

OCR в составе DLP-системы «Ростелеком–Солар» используются в компаниях нефтегазовой отрасли и госструктурах. Все заказчики используют возможности OCR для детектирования конфиденциальных данных в отсканированных документах. Что может содержаться в такой «графике»? Да все, что угодно. Это могут быть сканы различных внутренних документов, например, содержащие ПДн. Или информация из категории коммерческой тайны, ДСП (для служебного пользования), финансовая отчетность и т.п.
Как OCR распознает изображения?
Процесс выглядит следующим образом: DLP перехватывает сообщение, содержащее изображение (скан документа, фотографию и т.п.), определяет, что изображение действительно есть в сообщении, извлекает его и отправляет на распознавание в модуль OCR. На выходе DLP получает информацию о содержимом изображения (да и сообщения в целом) в виде извлеченного TEXT/PLAIN.
Если говорить о взаимодействии сервисов непосредственно в нашей системе Solar Dozor, то сервис фильтрации отправляет изображения (если они есть) из сообщения в сервис извлечения текста изображений (OCR). Последний, после завершения распознавания, отдаёт полученный текст в mailfilter. Получается что-то вроде жонглирования изображениями и текстом.

Рассмотрим механизм распознавания глубже на примере работы OCR-технологий ABBYY, которые мы используем в собственной DLP.
Пожалуй, главной проблемой для OCR при распознавании текста является написание того или иного символа. Если взять любую букву алфавита (например, русского или английского), то для каждой мы найдем несколько вариантов написания. OCR-движки решают эту задачу несколькими способами:
Про работу OCR достаточно много различных статей. Подробно о работе OCR можно почитать, например, здесь https://sysblok.ru/knowhow/iz-pikselej-v-bukvy-kak-rabotaet-raspoznavanie-teksta/
Как готовить OCR в целом для распознавания?
Мы уже выяснили, что в DLP может попадать более миллиона изображений. Но все ли изображения из этого миллиона нам полезны?
Ответ на вопрос более чем очевиден – конечно, нет. Но почему нам будут полезны не все изображения? Ответ на этот вопрос тоже достаточно прозрачен: в почте «гуляет» очень много картинок из подписей в сообщениях. Наверное, 90% сообщений (если не больше) будут содержать логотип компании.
Подобные картинки слишком мелкие для распознавания, текста в них может не быть совсем. Здесь мы можем посоветовать (и даже настойчиво порекомендовать) задавать ограничения на размер распознаваемых изображений. При этом ограничения необходимо задавать как по нижней границе, так и по верхней. Вероятность отправки на обработку тяжелых файлов ниже, чем для картинок из подписи, но все же достаточно высока.
Стоит отметить, что цифровые изображения часто имеют разные дефекты. Маловероятно, что в DLP всегда будут попадать сканы документов в хорошем разрешении. Скорее наоборот, сканы всегда будут не в лучшем качестве и с большим количеством дефектов.
Например, в цифровом фото может быть искажена перспектива, оно может оказаться засвеченным или перевернутым, строки скана – изогнутыми. Такие искажения могут усложнять распознавание. Поэтому OCR-движки могут предварительно обрабатывать изображения, чтобы подготовить их к распознаванию. Например, изображение можно покрутить, преобразовать в ч/б, инвертировать цвета, скорректировать перекосы строк. Все это можно задать в настройках OCR и, как следствие, эти инструменты могут помочь улучшить распознавание текста в изображениях.
В итоге мы пришли к базовым принципам подготовки OCR к распознаванию:
Какие челленджи возможны при эксплуатации OCR в DLP под большой нагрузкой?
1. Слишком широкие лимиты на размеры распознаваемых изображений
Начнем с того, о чем мы уже упомянули, – с лимитов.
Исходя из нашей практики, заказчики часто устанавливают слишком широкие лимиты на размеры распознаваемых графических файлов. Да, чтобы OCR работал хорошо, нужно ограничивать размеры изображений. Но заказчики стремятся контролировать все подряд, полагая, что даже в картинке размером 100×100 pixels и 5 Кб могут утечь ценные данные. В целом, конечно, 100х100 pixels и 5 Кб тоже ограничения, но слишком уж низки эти пороги.
Другая крайность – стремление распознать тяжелые файлы по несколько сотен Мб. Понятно, что через корпоративную почту такие изображения не пролезут из-за ограничений на размер пересылаемых сообщений. Но вот по другим каналам перехвата (например, с корпоративных сетевых шар) увесистые файлы настойчиво стремятся распознавать. Если же заказчик хочет добавить к этому еще и большой объем high-res изображений, то для этого нужно иметь соответствующие серверные мощности. В итоге, при столь широких минимальных и максимальных порогах на размер распознаваемых файлов создается высокая нагрузка на процессор на серверах, что замедляет работу всех подсистем.
Что здесь можно порекомендовать? Прежде всего проанализировать, в какой используемой в компании «графике» содержатся конфиденциальные данные, после чего прикинуть разумные минимальные и максимальные ограничения на размеры контролируемых изображений. Обычно мы рекомендуем заказчикам зафиксировать нижнюю границу разрешения изображения от 200 pixels, в идеале от 400 pixels (по осям X и Y), и размера файлов не меньше 20 Кб, лучше больше. Также не имеет смысла отправлять в OCR тяжеловесные изображения – они элементарно перегрузят ваши сервера и не факт, что будут распознаны.
2. Очереди на фильтрацию и таймауты обработки запросов
Чрезмерная нагрузка на серверы, возникающая по вышеописанным причинам, ведет по цепочке к увеличению времени распознавания изображений и обработки запросов в целом. В результате в DLP-системе начинает увеличиваться очередь сообщений на фильтрацию. Кроме того, в OCR-модуль могут приходить графические файлы, которые в принципе невозможно распознать (тяжелые файлы, низкое качество и т.п.), в результате чего возникают таймауты обработки изображений. Если нераспознаваемых файлов поступает много, а в системе установлены высокие таймауты на распознавание, сервис фильтрации ждёт, пока этот таймаут наступит, и только потом приступает к обработке следующего запроса. Весь процесс обработки может серьезно тормозиться.
Что можем посоветовать? При возникновении очереди на обработку графических изображений нужно посмотреть настройки OCR в DLP-системе и попробовать найти причину торможения. Это может происходить, например, из-за проблем межпроцессного взаимодействия на самом сервере. Вообще, эти проблемы заслуживают отдельного разговора. Некоторые подробности по общим вопросам можно узнать из статьи «Знакомство с межпроцессным взаимодействием на Linux».
Кроме этого важным моментом при настройке OCR является выставление адекватных таймаутов на распознавание изображений. В общем случае достаточно 90 секунд, чтобы изображение точно распозналось. Если из изображения не извлекся текст за 90 секунд, то можно предположить, что OCR не распознает изображение в принципе. В этом месте также могут возникать проблемы конфигурирования OCR, когда выставляют высокие таймауты на распознавание и тем самым делаются попытки распознать нераспознаваемое.
Что еще может стать причиной таймаута? Здесь мы снова вернемся к вопросу конфигурирования системы. Сервис фильтрации, как и сервис OCR, оперирует тредами, которые обрабатывают сообщения и изображения. Система может быть некорректно сконфигурирована в части количества обработчиков сервиса фильтрации и количества обработчиков OCR. Например, у сервиса фильтрации будет много тредов-обработчиков, а у OCR всего один. В такой ситуации в какие-то моменты OCR может просто не успевать обрабатывать все запросы на распознавание, и таким образом будут появляться таймауты обработки изображений.
Подобное поведение системы наводит на мысли о проблемах проектирования и багах в архитектуре, но на самом деле это не так. Архитектура нашей DLP предоставляет возможности гибкой конфигурации системы и настройки её под нужды заказчиков. Например, мы можем достаточно просто настроить один OCR на работу с двумя сервисами фильтрации без ущерба производительности.
3. Нераспознаваемые изображения
Если в DLP-систему попадает на анализ изображение, которое OCR не может распознать, существует несколько вариантов решения проблемы.
По каким причинам изображения могут не распознаваться? Например, по следующим:
1. Нестандартная цветовая схема изображения.
2. Низкое разрешение изображения.
3. Неправильная ориентация изображения и содержащегося в нем текста в пространстве.
4. Перекосы строк и искажения пропорций текста в изображении и др.
Приведем пример: у одного из заказчиков в процессе мониторинга выяснилось, что OCR не распознает pdf-документы, выполненные в нестандартной цветовой схеме. То есть изображение извлекалось из PDF-документа в штатном режиме, но когда дело доходило до обработки OCR-модулем, тот не понимал цветовую схему картинки и выдавал на выходе «квадрат Малевича». В нашем интерфейсе картинка выглядела примерно так:

В OCR-движках заложены различные функции автоматической коррекции изображения, которые сильно повышают шансы на успешное распознавание содержащегося в нем текста. Однако, на практике эти волшебные инструменты не всегда срабатывают. В данном конкретном случае мы донастроили для заказчика OCR-модуль таким образом, чтобы он распознавал эту нестандартную цветовую схему.
5. Несоответствие одного из параметров документа заданным размерам распознаваемых
изображений.
Например, в конфигурации системы заданы границы размеров распознаваемых изображений 200х1000 pixels, а в OCR поступил файл размером 500х1500 pixels (верхний лимит превышен). В этом случае необходимо исправить настройки OCR для распознавания таких изображений.
Это, пожалуй, один из самых популярных сценариев донастройки системы после того, как нам говорят, что OCR не работает.
Почему OCR не на агентах?
OCR в DLP-системах реализуется в двух вариантах – на агентах и на серверах. Мы являемся сторонниками второго подхода, поскольку распознавание изображений прямо на рабочей станции создает высокую нагрузку на ее процессор и, соответственно, тормозит работу других приложений. OCR сама по себе весьма прожорливая технология даже для серверов, и её применение требует правильного планирования процессорных мощностей и контроля эффективности.
При этом многие отечественные компании, в особенности в госсекторе, до сих пор владеют достаточно старым парком ПК. Что происходит в этом случае? Пользователи начинают жаловаться ИТ-подразделению на «торможение» ПК, а айтишники в конце концов выясняют, что причиной торможения является OCR-модуль DLP-системы. Это раздражает и их, и пользователей, которые не могут оперативно решать рабочие задачи. В конечном итоге все это складывается в головную боль для безопасника, у которого и других задач полно.
Использование OCR на агентах оправдано лишь тогда, когда DLP-система работает «в разрыв». В этом случае распознавание изображения должно происходить ровно в тот момент, когда пользователь совершает действия с этим графическим файлом на своей рабочей станции. То есть DLP-система должна мгновенно решить судьбу документа, содержащего это изображение – разрешить его к отправке/копированию или запретить. Но на практике только единицы заказчиков используют DLP-систему в режиме активной блокировки, и это касается не только нашей собственной DLP. Здесь работает принцип «все, что можно вынести для проверок на сервер, должно выполняться на сервере».
Итого
Технологии OCR предоставляют возможности распознавания графических изображений, а мы в дополнение всегда даем общие рекомендации по конфигурированию системы. Однако в конкретном проекте может возникать необходимость донастройки работы OCR-модуля под специфические потребности заказчика как на этапе пилотирования и внедрения решения, так и на этапе его промышленной эксплуатации. Это не просто нормально – это единственно верный путь, который даст ощутимый результат, сделает работу OCR в компании максимально эффективной и снизит до минимума утечки конфиденциальной информации через графические изображения.
Никита Игонькин, ведущий инженер сервиса компании «Ростелеком-Солар»
Блог компании ArtisMedia
Как перейти от бумажного к цифровому документообороту, чтобы сэкономить время и деньги? Как переместить тонны бумажной информации на небольшой жесткий диск или даже в облако? Благодаря технологии оптического распознавания символов (OCR) преобразовать отсканированные документы в доступные для чтения и редактирования цифровые файлы достаточно просто. 
OCR – это использование технологии для идентификации и преобразования отсканированных рукописных или печатных текстовых символов в электронную форму, более легко распознаваемую компьютерами и другими программами. Базовый процесс распознавания включает изучение текста и перевод символов в код, который можно использовать для обработки данных. OCR иногда также называют распознаванием текста.
Технология состоит из сочетания аппаратного и программного обеспечения, которое используется с целью преобразования физических документов в машиночитаемый текст. Аппаратное обеспечение, такое как оптический сканер или специализированная монтажная плата, используется для копирования или чтения текста, в то время как программное обеспечение отвечает за расширенную обработку. Программное обеспечение может использовать искусственный интеллект для реализации более совершенных методов интеллектуального распознавания (ICR), таких как идентификация языков или стилей рукописного ввода.
OCR чаще всего используется для преобразования печатных юридических или исторических документов в PDF-файлы. После этого полученные электронные копии пользователи могут редактировать, форматировать при помощи обычных редакторов текста.
Как работает OCR
Первым шагом процесса оптического распознавания является использование сканера с целью обработки физической формы документа. После копирования всех страниц программа OCR преобразует документ в двухцветную или черно-белую версию. Отсканированное растровое изображение анализируется на наличие светлых и темных областей. При этом темные области идентифицируются как символы, которые необходимо распознать, а светлые области – как фон. После этого темные области обрабатываются для поиска букв или цифр.
Существующие программы распознавания могут иметь разные методы работы, но, как правило, все они включают таргетинг на один символ, слово или блок текста. Для идентификации символов используются два основных алгоритма.
Когда символ идентифицирован, он преобразуется в код ASCII, который может использоваться компьютерными системами. Перед сохранением для дальнейшего использования обработанные тексты необходимо проверить на содержание ошибок, на правильность сложных макетов.
Варианты использования
Заключение
До того, как появилась технология OCR, единственным методом оцифровки бумажных носителей была ручная повторная печать текста. Этот процесс занимал много времени, а также часто приводил к ошибкам при печати. Использование OCR экономит время, помогает исключить ошибки, минимизировать усилия. Кроме этого, технология позволяет выполнять действия, которые недоступны для физических копий, например, может использовать сжатие в ZIP-файлы, выделять ключевые слова, размещать документы на веб-сайте, прикреплять их к электронной почте.
Что такое OCR в антиплагиате?
Несмотря на то, что оптическое распознавание текста активно используется уже достаточно долгое время, Антиплагиат внедрил в свой механизм проверки модуль OCR сравнительно недавно.
Что такое OCR в антиплагиате?
Давайте теперь поподробнее разберем, что такое OCR в антиплагиате. На самом деле, сам механизм распознавания текста остался неизменным, но приобрел новое значение. С помощью OCR система Антиплагиат уже не просто сканирует исходный машинописный текст, а сначала трансформирует его в изображение, делая своего рода фотографию, а уже потом производит оптическое распознавание. Распознанный текст в конечном итоге и подвергается проверке на уникальность. Звучит достаточно сложно, так зачем же такие трудности?
Дело в том, что система OCR в антиплагиате позволяет исключить все устаревшие способы искусственного завышения уникальности. Теперь программа будет работать именно с изображением текста, а не с текстом как таковым.
Еще одной фишкой модуля OCR является то, что теперь распознаваться будут изображения и таблицы, включенные в документ. Если раньше таблицы и изображения системой не распознавались и воспринимались антиплагиатом как уникальный текст, то теперь дела обстоят иначе – проверке будут подвергаться все элементы курсовой или дипломной работы.
Конечно, как и любые другие поисковые модули, модуль OCR не бесплатный. Доступен он только в системе Антиплагиат.ВУЗ или же его можно подключить на одну проверку в Антиплагиат.ру, минимальная цена которой 270 рублей.
Для использования OCR во время проверки работы необходимо поставить галочку напротив «Использовать распознавание текста (OCR)».

Разработчики антиплагиата предупреждают, что при проверке документа с помощью распознавания текста, скорость обработки файла может значительно увеличится.
Текст извлечен с помощью OCR – что это значит?
Нередко студенты сталкиваются с фразой, представленной в полных отчетах системы Антиплагиат.ВУЗ, «Текст извлечен с помощью OCR». Это значит, что перед проверкой работы преподаватель подключил модуль OCR – поставил галочку напротив «Использовать распознавание текста (OCR)». С помощью этого модуля в файле будут подвергаться проверке только видимые элементы, а это значит, что искусственное завышение уникальности с помощью скрытых символов в 90% случаев не сработает. Поскольку для того, чтобы использовать распознавание текста при проверке документа его сначала нужно подключить, многие преподаватели просто забывают о такой возможности, однако если же этот модуль действительно включен, информация об этом обязательно отобразиться в полном отчете о проверке.
После того как мы разобрали принципы распознавания текста OCR и что это в антиплагиате, стоит подробней остановиться на способах повышения уровня оригинальности текста и на том, как можно обойти модуль OCR.
Как обойти OCR в антиплагиате?
Использование преподавателями при проверке студенческих работ функции OCR действительно осложнило ситуацию, особенно если она используется в совокупности с множеством дополнительных модулей поиска.
Старые методы искусственного завышения с появлением модуля OCR уже не действуют. Благодаря тому, что функция распознавания позволяет работать не с текстом как таковым, а с его видимым изображением, то замена букв и прочие устаревшие методы повышения уникальности никак не повлияют на процент в антиплагиате, а только обеспечат вам пометку «подозрительный документ», что наверняка не обрадует вашего научного руководителя. Однако обойти OCR все же возможно.
Самым действенным и честным способом остается самостоятельное написание работы. Так вы можете быть уверены, что успешно пройдете любые проверки на антиплагиате и получите отличную оценку. Конечно, далеко немногие студенты могут позволить себе самостоятельно писать курсовую или диплом вввиду своей загруженности, а написание качественного и оригинального материала требует много времени и сил.
Можно также заказать работу на профильном сайте, предлагающем услуги авторов по различным направлениям подготовки. Этот способ обойдется достаточно дорого, ведь на хорошие, качественные работы цены очень высокие. Кроме того, всегда есть шанс попасть на недобросовестного исполнителя, который срывает все сроки и предоставляет скопированный текст.
Глубокий, основательный рерайт – это еще один способ значительно повысить уровень оригинальности работы. Воспользовавшись данным методом, вы получите совершенно новый текст. Несмотря на очевидные плюсы, глубокий рерайт занимает очень много времени и совершенно не подходит для ситуаций, когда действовать приходится в сжатые сроки.
Что такое оптическое распознавание символов?
Что такое оптическое распознавание символов?
Оптическое распознавание символов (OCR) — это процесс преобразования изображения текста в машиночитаемый текстовый формат. Например, при сканировании бланка или квитанции, компьютер сохраняет скан в виде файла изображения. Текстовый редактор невозможно использовать для редактирования, поиска или подсчета слов в файле изображения. OCR помогает преобразовать изображение в текстовый документ, содержимое которого хранится в виде текстовых данных.
В чем заключается важность OCR?
Большинство рабочих процессов связано с получением информации из печатных изданий. Любой бизнес-процесс предусматривает бланки, счета, отсканированные юридические документы и контракты, напечатанные на бумажном носителе. Такие большие объемы бумажной работы требуют много времени и места для хранения и обработки. Хотя безбумажный документооборот — это путь вперед, сканирование документа в изображение создает определенные трудности. Этот процесс требует ручного вмешательства и может быть утомительным и медленным.
При оцифровке содержимого документа создаются файлы изображений со скрытым в них текстом. Программы обработки текста не могут обработать текст в изображениях. Технология OCR решает эту проблему путем преобразования изображения в текстовые данные, которые могут быть проанализированы офисным ПО. Затем такие данные можно использовать для аналитики, оптимизации операций, автоматизации процессов и повышения производительности.
Как работает OCR?
Технология OCR включает следующие этапы:
Получение изображения
Сканер считывает документы и преобразует их в двоичные данные. ПО OCR анализирует отсканированное изображение и классифицирует светлые области как фон, а темные — как текст.
Предварительная обработка
Чтобы подготовить текст к распознаванию, ПО OCR очищает изображение и удаляет ошибочные области. Применяются следующие методы очистки:
Распознавание текста
Существует два основных типа алгоритмов OCR или программных процессов, которые использует ПО OCR для распознавания текста: сопоставление шаблонов и выделение признаков.
Сопоставление шаблонов
Сопоставление шаблонов работает путем выделения изображения символа, называемого глифом, и сравнения его с аналогичным глифом, хранящимся в памяти. Распознавание образа произойдет только в том случае, если шрифт и масштаб хранящегося глифа совпадают со шрифтом и масштабом отсканированного глифа. Данный метод эффективен при работе со сканами документов, набранных известным шрифтом.
Выделение признаков
Выделение признаков разбивает или раскладывает глифы на такие признаки, как линии, замкнутые контуры, направление линий и пересечения линий. Затем признаки используются для поиска наилучшего или ближайшего подходящего соответствия среди различных хранящихся глифов.
Окончательная обработка
После анализа система преобразует извлеченные текстовые данные в компьютерный файл. Некоторые системы OCR могут создавать аннотированные PDF-файлы, включающие как предыдущую, так и последующую версии отсканированного документа.
Какие виды OCR существуют?
Специалисты по анализу данных классифицируют различные виды технологий OCR на основе их использования и применения. Ниже представлены лишь некоторые примеры:
Программы простого оптического распознавания символов
Простой механизм OCR применяет множество различных хранимых шаблонов шрифтов и изображений текста в качестве шаблонов. Программное обеспечение OCR использует алгоритмы сопоставления шаблонов для посимвольного сравнения изображений текста с внутренней базой данных. Подход, при котором система сопоставляет текст слово за словом, называется оптическим распознаванием слов. Он имеет свои ограничения, поскольку существует практически неограниченное количество шрифтов и стилей почерка, и каждый отдельный тип не может быть учтен и сохранен в базе данных.
Программы интеллектуального распознавания символов
Современные системы OCR используют технологию интеллектуального распознавания символов (ICR) для считывания текста так же, как это делает человек. Они используют передовые методы машинного обучения человеческим навыкам чтения. Система машинного обучения, называемая нейронной сетью, анализирует текст на многих уровнях, многократно обрабатывая изображение. Она ищет различные атрибуты изображения (кривые, линии, пересечения и петли) и объединяет результаты различных уровней анализа для получения окончательного результата. Несмотря на то, что ICR обрабатывает изображения по символам, процесс не занимает много времени, а результаты получаются за считанные секунды.
Интеллектуальное распознавание слов
Интеллектуальные системы распознавания слов работают по тому же принципу, что и ICR, но обрабатывают изображения целых слов без предварительного выделения символов в изображении.
Оптическое распознавание знаков
Оптическое распознавание знаков позволяет идентифицировать логотипы, водяные знаки и другие обозначения в документе.
В чем заключаются основные преимущества OCR?
Ниже приведены основные преимущества технологии OCR:
Текст с возможностью поиска
Предприятия могут преобразовывать имеющиеся и новые документы в базу знаний с возможностью полноценного поиска. ПО для автоматической обработки текстовой базы позволяет совершенствовать базу знаний предприятия.
Эффективность работы
Применение ПО OCR позволяет повысить эффективность работы путем автоматической интеграции документооборота и цифровых рабочих процессов. Вот несколько примеров того, что может сделать ПО OCR:
Решения искусственного интеллекта
OCR часто является составляющей других решений в области искусственного интеллекта, которые могут внедрять предприятия. К примеру, OCR может применяться для сканирования и распознавания номерных знаков и дорожных указателей в самоуправляемых автомобилях, выявления логотипов брендов в сообщениях в социальных сетях или идентификации упаковки продукта в рекламных изображениях. Такие технологии искусственного интеллекта помогают предприятиям принимать более эффективные маркетинговые и операционные решения, которые позволяют сократить расходы и улучшить качество обслуживания клиентов.
Для чего применяется OCR?
Банковская сфера
Банковская сфера использует OCR для обработки и проверки документов по кредитам, депозитных чеков и других финансовых операций. Такая проверка позволила повысить эффективность борьбы с мошенничеством и укрепить безопасность транзакций. Например, BlueVine, финансовая технологическая компания, предоставляющая финансирование малому и среднему бизнесу, использовала Amazon Textract, облачный сервис OCR, для разработки продукта, с помощью которого малые бизнесы в США могут быстро получить доступ к кредитам по Программе защиты заработной платы (PPP) в рамках пакета мер по стимулированию экономики в условиях COVID-19. Amazon Textract автоматически обрабатывал и анализировал десятки тысяч форм PPP в день, благодаря чему BlueVine смогла помочь нескольким тысячам предприятий получить средства и сохранить более 400 000 рабочих мест.
Здравоохранение
В системе здравоохранения OCR используется для обработки историй болезни пациентов, включая лечебные процедуры, анализы, больничные карты и страховые выплаты. OCR помогает оптимизировать рабочий процесс и сократить объем ручной работы в больницах, а также поддерживать актуальность записей. Например, компания nib Group обеспечивает медицинское страхование более 1 миллиона австралийцев и ежедневно получает тысячи заявок на выплату страхового возмещения за получение медицинских услуг. Клиенты компании могут сфотографировать свой медицинский счет и отправить его через мобильное приложение nib. Amazon Textract автоматически обрабатывает эти изображения, что позволяет компании гораздо быстрее рассматривать заявки.
Логистика
Логистические компании используют OCR для более эффективного отслеживания этикеток на упаковках, счетов, квитанций и других документов. Например, компания Foresight Group использует Amazon Textract для автоматизации обработки счетов в SAP. Ввод таких документов вручную отнимал много времени и приводил к ошибкам, поскольку сотрудникам Foresight приходилось вводить данные в несколько систем бухгалтерского учета. Благодаря Amazon Textract программное обеспечение компании Foresight стало более точно считывать символы на различных носителях и повысило эффективность ведения бизнеса компании.
Как AWS может помочь с OCR?
AWS предлагает две услуги, которые могут помочь внедрить OCR в бизнесе:
Amazon Textract – это сервис машинного обучения (ML), который с помощью OCR автоматически извлекает печатный и рукописный текст и данные из отсканированных документов (например, PDF-файлов). Сервис позволяет быстро считывать тысячи различных документов различных носителей и форматов. После извлечения информации из документов Amazon Textract присваивает уровень уверенности, позволяя принимать обоснованные решения о том, как использовать полученные результаты.
Amazon Rekognition может анализировать миллионы изображений и видеозаписей за считанные минуты и дополнять задачи визуальной проверки, выполняемые человеком, с помощью искусственного интеллекта. Для извлечения текста из изображений и видео можно использовать API Amazon Rekognition. В нем имеется возможность распознавать искаженный и деформированный текст из изображений и видеозаписей дорожных знаков, публикаций в социальных сетях и упаковок продуктов.
Создайте учетную запись AWS и начните работу с технологией OCR уже сегодня.
Как мы создавали технологию оптического распознавания текста. OCR в Яндексе
Привет! Сегодня я расскажу читателям Хабра о том, как мы создавали технологию распознавания текста, работающую на 45 языках и доступную пользователям Яндекс.Облака, какие задачи мы ставили и как их решали. Будет полезно, если вы работаете над схожими проектами или хотите узнать, как так получилось, что сегодня вам достаточно сфотографировать вывеску турецкого магазина, чтобы Алиса перевела её на русский.

Технология Optical character recognition (OCR) развивается в мире уже десятки лет. Мы в Яндексе начали разрабатывать собственную технологию OCR, чтобы улучшить свои сервисы и дать пользователям больше возможностей. Картинки — это огромная часть интернета, и без способности их понимать поиск по интернету будет неполным.
Решения для анализа изображений становятся все более востребованными. Это связано с распространением искусственных нейронных сетей и устройств с качественными сенсорами. Понятно, что в первую очередь речь идет о смартфонах, но не только о них.
Сложность задач в области распознавания текста постоянно растет — все начиналось с распознавания отсканированных документов. Потом добавилось распознавание Born-Digital-картинок с текстом из интернета. Затем, с ростом популярности мобильных камер, — распознавание хороших снимков с камеры (Focused scene text). И чем дальше, тем больше параметры усложнялись: текст может быть нечетким (Incidental scene text), написанным с любым изгибом или по спирали, самых разных категорий — от фотографий чеков до прилавков магазинов и вывесок.
Какой путь мы прошли
Распознавание текста — это отдельный класс задач компьютерного зрения. Как и многие алгоритмы компьютерного зрения, до популярности нейросетей оно во многом основывалось на ручных признаках и эвристиках. Однако за последнее время, с переходом на нейросетевые подходы, качество технологии существенно выросло. Посмотрите на пример на фото. Как это происходило, я расскажу дальше.
Сравните сегодняшние результаты распознавания с результатами в начале 2018 года:
Какие трудности нам встретились сначала
В начале своего пути мы делали технологию распознавания для русского и английского языков, а основными сценариями использования были сфотографированные страницы текста и картинки из интернета. Но в ходе работы мы поняли, что этого недостаточно: текст на изображениях встречался на любом языке, на любой поверхности, а картинки порой оказывались самого разного качества. Значит, распознавание должно работать в любой ситуации и на всех типах входящих данных.
И тут мы столкнулись с рядом сложностей. Вот только некоторые:
Выбор модели детекции
Первый шаг к распознаванию текста — определение его положения (детекция).
Детекцию текста можно рассматривать как задачу распознавания объектов, где в качестве объекта могут выступать отдельные символы, слова или строки.
Нам было важно, чтобы модель впоследствии масштабировалась на другие языки (сейчас мы поддерживаем 45 языков).
Во многих исследовательских статьях про детекцию текста используются модели, которые предсказывают положения отдельных слов. Но в случае универсальной модели такой подход имеет ряд ограничений — например, само понятие слова для китайского языка принципиально отличается от понятия слова, к примеру, в английском языке. Отдельные слова в китайском не отделены пробелом. В тайском языке пробелом отбиваются только отдельные предложения.
Вот примеры одного и того же текста на русском, китайском и тайском языках:
Сегодня отличная погода. Замечательный день для прогулки.
今天天气很好 这是一个美丽的一天散步。
สภาพอากาศสมบูรณ์แบบในวันนี้ มันเป็นวันที่สวยงามสำหรับเดินเล่นกันหน่อยแล้ว
Строки же в свою очередь бывают очень вариативными по соотношению сторон. Из-за этого возможности таких распространенных детекционных моделей (например, SSD или RCNN-based) для предсказания линий ограничены, так как эти модели основаны на регионах-кандидатах / анкорных боксах с множеством предопределенных соотношений сторон. Кроме того, линии могут иметь произвольную форму, например изогнутую, поэтому для качественного описания строк недостаточно исключительно описывающего четырехугольника, даже с углом поворота.
Несмотря на то, что положения отдельных символов локальные и описываемые, их недостаток состоит в том, что требуется отдельный этап постобработки — нужно подобрать эвристики для склеивания символов в слова и строки.
Поэтому за основу для детекции мы взяли модель SegLink, основная идея которой — декомпозировать строки/слова на две более локальные сущности: сегменты и связи между ними.
Архитектура детектора
Архитектура модели основывается на SSD, который предсказывает положения объектов сразу на нескольких масштабах признаков. Только помимо предсказания координат отдельных «сегментов» предсказываются также и «связи» между соседними сегментами, то есть принадлежат ли два сегмента одной и той же строке. «Связи» предсказываются как для соседних сегментов на одинаковом масштабе признаков, так и для сегментов, находящихся в смежных областях на соседних масштабах (сегменты c разных масштабов признаков могут незначительно отличаться по размерам и принадлежать одной линии).

Иллюстрация принципов работы детектора SegLink из статьи Detecting Oriented Text in Natural Images by Linking Segments
По таким предсказаниям, если взять в качестве вершин все сегменты, для которых вероятность того, что они являются текстом больше порога α, а в качестве ребер все связи, вероятность которых больше порога β, то сегменты образуют связные компоненты, каждый из которых описывает линию текста.
Полученная модель имеет высокую обобщающую способность: даже обученная в первых подходах на русских и английских данных, она качественно находила китайский и арабский текст.
Десять скриптов
Если для детекции нам удалось создать модель, которая работает сразу для всех языков, то для распознавания найденных линий такую модель получить заметно сложнее. Поэтому мы решили использовать отдельную модель для каждого скрипта (кириллический, латинский, арабский, иврит, греческий, армянский, грузинский, корейский, тайский). Отдельная общая модель используется для китайского и японского языков из-за большого пересечения по иероглифам.
Общая для всего скрипта модель отличается от отдельной модели для каждого языка менее чем на 1 п.п. качества. В то же время и создание, и внедрение одной модели проще, чем, к примеру, 25 моделей (количество латинских языков, поддерживаемых нашей моделью). Но из-за частого присутствия во всех языках вкраплений английского все наши модели умеют помимо основного скрипта предсказывать также символы латинского алфавита.
Чтобы понять, какую модель необходимо использовать для распознавания, мы вначале определяем принадлежность полученных линий одному из 10 доступных для распознавания скриптов.
Стоит отдельно отметить, что не всегда по линии можно однозначно определить её скрипт. К примеру, цифры или одиночные латинские символы содержатся во многих скриптах, поэтому один из выходных классов модели — «неопределенный» скрипт.
Определение скрипта
Для определения скрипта мы сделали отдельный классификатор. Задача определения скрипта существенно проще, чем задача распознавания, и на синтетических данных нейронная сеть легко переобучается. Поэтому в наших экспериментах существенное улучшение качества модели давало предобучение на задаче распознавания строк. Для этого мы вначале обучали сеть для задачи распознавания для всех имеющихся языков. После этого полученный backbone использовался для инициализации модели на задачу классификации скрипта.
В то время как скрипт у отдельной линии часто бывает достаточно шумным, картинка в целом чаще всего содержит текст на одном языке, либо помимо основного вкрапления английского (или в случае наших пользователей русского). Поэтому для увеличения стабильности мы агрегируем предсказания линий с картинки с целью получения более стабильного предсказания скрипта картинки. Линии с предсказанным классом «неопределённый» не учитываются при агрегации.
Распознавание строк
Следующим шагом, когда мы уже определили положение каждой линии и ее скрипт, нам необходимо распознать последовательность символов из заданного скрипта, которая на ней изображена, то есть из последовательности пикселей предсказать последовательность символов. После множества экспериментов мы пришли к следующей sequence2sequence attention based модели:
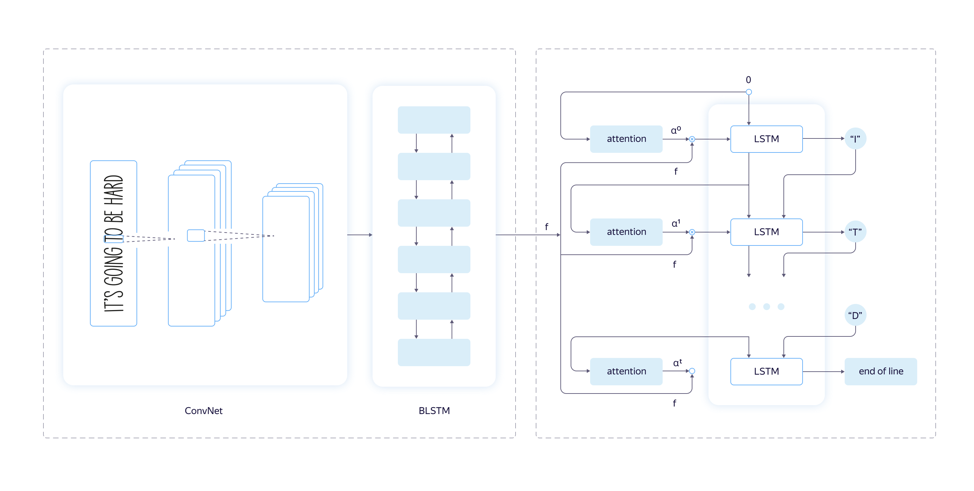
Использование CNN+BiLSTM в encoder позволяет получить признаки, улавливающие как локальный, так и глобальный контекст. Для текста это важно — зачастую он написан одним шрифтом (отличить схожие буквы, имея информацию о шрифте, гораздо проще). И чтобы отличить две буквы, написанные через пробел, от идущих подряд, тоже нужны глобальные для линии статистики.
Интересное наблюдение: в полученной модели выходы маски attention для конкретного символа можно использовать для предсказания его позиции на изображении.
Это вдохновило нас попробовать явно «фокусировать» внимание модели. Такие идеи встречались и в статьях — например, в статье Focusing Attention: Towards Accurate Text Recognition in Natural Images.
Так как механизм attention дает вероятностное распределение над пространством признаков, если взять в качестве дополнительного loss сумму выходов attention внутри маски, соответствующей предсказываемой на данном шаге букве, мы получим ту часть «внимания», которая фокусируется непосредственно на ней.
Для тех обучающих примеров, для которых местоположение отдельных символов неизвестно или неточно (не для всех обучающих данных имеется разметка на уровне отдельных символов, а не слов), — это слагаемое в финальном loss не учитывалось.
Еще одна приятная особенность: такая архитектура позволяет без дополнительных правок предсказывать распознавание линий right-to-left (что важно, к примеру, для таких языков как арабский, иврит). Модель сама начинает выдавать распознавание справа налево.
Быстрая и медленная модели
В процессе мы столкнулись проблемой: для «высоких» шрифтов, то есть шрифтов, вытянутых по вертикали, модель работала плохо. Вызвано это было тем, что размерность признаков на уровне attention в 8 раз меньше, чем размерность исходной картинки из-за страйдов и пулингов в архитектуре сверточной части сети. И местоположения нескольких соседних символов на исходной картинке могут соответствовать местоположению одного и того же вектора признаков, что может приводить к ошибкам на таких примерах. Использование архитектуры с меньшим сужением размерности признаков приводило к росту качества, но также к росту времени обработки.
Чтобы решить эту проблему и избежать увеличения времени обработки, мы сделали следующие доработки модели:

Мы обучили одновременно и быструю модель с большим количеством страйдов, и медленную с меньшим. На слое, где параметры модели начинали отличаться, мы добавили отдельный выход сети, который предсказывал, у какой модели будет меньше ошибка распознавания. Суммарный loss модели складывался из Lsmall + Lbig + Lquality. Таким образом, на промежуточном слое модель училась определять «сложность» данного примера. Далее на этапе применения общая часть и предсказание «сложности» примера считались для всех линий, а в зависимости от его выхода по значению порога в дальнейшем применялась либо быстрая, либо медленная модель. Это позволило нам получить качество, почти не отличающееся от качества долгой модели, при этом скорость увеличилась лишь на 5% процентов вместо предполагаемых 30%.
Данные для обучения
Важный этап создания качественной модели — подготовка большой и разнообразной обучающей выборки. «Синтетическая» природа текста дает возможность генерировать примеры в большом количестве и получать достойные результаты на реальных данных.
После первого подхода к генерации синтетических данных мы внимательно посмотрели на результаты полученной модели и выявили, что модель недостаточно хорошо распознает одиночные буквы ‘I’ из-за смещения в текстах, используемых для создания обучающей выборки. Поэтому мы явно сгенерировали набор «проблемных» примеров, и когда добавили его к исходным данным модели, качество ощутимо выросло. Этот процесс мы повторяли многократно, добавляя все больше сложных срезов, на которых хотели повысить качество распознавания.
Важный момент состоит в том, что сгенерированные данные должны быть разнообразными и похожими на реальные. И если вы хотите от модели, чтобы она работала на фотографиях текста на листках бумаги, а весь синтетический датасет содержит текст, написанный поверх пейзажей, то это может не сработать.
Еще одним важным шагом является использование для обучения тех примеров, на которых текущее распознавание ошибается. При наличии большого количества картинок, для которых нет разметки, можно взять те выходы текущей системы распознавания, в которых она не уверена, и разметить только их, тем самым сократив затраты на разметку.
Для получения сложных примеров мы просили пользователей сервиса Яндекс.Толока за вознаграждение сфотографировать и отправить нам изображения определенной «сложной» группы — например, фотографии упаковок товаров:


Качество работы на «сложных» данных
Мы хотим дать нашим пользователям возможность работать с фотографиями любой сложности, ведь распознать или перевести текст может понадобиться не только на странице книги или отсканированном документе, но и на уличной вывеске, объявлении или упаковке продукта. Поэтому, сохраняя высокое качество работы на потоке книг и документов (этой теме посвятим отдельный рассказ), мы уделяем особое внимание «сложным наборам изображений».
Описанным выше способом мы собрали набор изображений, содержащих текст in the wild, который может быть полезен нашим пользователям: фотографии вывесок, объявлений, табличек, обложек книг, тексты на бытовых приборах, одежде и предметах. На этом наборе данных (ссылка на который ниже) мы оценили качество работы нашего алгоритма.
В качество метрики для сравнения мы использовали стандартную метрику точности и полноты распознавания слов в датасете, а также F-меру. Распознанное слово считается правильно найденным, если его координаты соответствуют координатам размеченного слова (IoU > 0.3) и распознавание совпадает с размеченным с точностью до регистра. Цифры на получившемся датасете:
| Система распознавания | Полнота | Точность | F-мера |
| Yandex Vision | 73.99 | 86.57 | 79.79 |
Датасет, метрики и скрипты для воспроизведения результатов доступны по ссылке.
Upd. Друзья, сравнение нашей технологии с аналогичным решением от Abbyy вызвало много споров. Мы с уважением относимся ко мнению сообщества и коллег по индустрии. Но при этом уверены в своих результатах, поэтому решили так: мы уберем из сравнения результаты других продуктов, обсудим еще раз вместе с ними методику тестирования и вернемся с результатами, в которых придем к общему согласию.
Следующие шаги
На стыке отдельных шагов, таких как детекция и распознавание, всегда возникают проблемы: малейшие изменения в модели детекции влекут за собой необходимость изменений модели распознавания, поэтому мы активно экспериментируем над созданием end-to-end решения.
Помимо уже описанных путей усовершенствования технологии мы будем развивать направление анализа структуры документа, которая принципиально важна при извлечении информации и востребована у пользователей.
Заключение
Пользователи уже привыкли к удобным технологиям и не задумываясь включают камеру, наводят на вывеску магазина, меню в ресторане или страницу в книжке на иностранном языке и быстро получают перевод. Мы распознаем текст на 45 языках с подтвержденной точностью, и возможности будут только расширяться. Набор инструментов внутри Яндекс.Облака дает возможность любому желающему использовать те наработки, которые в Яндексе долгое время делали для себя.
Сегодня можно просто взять готовую технологию, интегрировать в собственное приложение и использовать для того, чтобы создавать новые продукты и автоматизировать собственные процессы. Документация по нашему OCR доступна по ссылке.