Dall е как воспользоваться
Dall е как воспользоваться
Нейросеть DALL-E: что это, примеры изображений, перспективы технологии
Друзья, наверняка вы уже слышали о нейросети под название DALL-E (DALL·E, DALLE, Dall E) и даже видели картинки, созданные этим искусственным интеллектом. В этой статье хочу подробно рассказать о данной разработке, а также о том, почему некоторые разочаровываются в возможностях DALL-E после личного опыта. Мол, получается, что на тестовых картинках всё замечательно и красиво, а по факту выходит совсем иное.
Что такое DALL-E? Принцип работы нейросети
DALL-E – нейронная сеть, которая способна создавать уникальные изображения из текстового описания. Работает это так: вы пишете, к примеру «Кот катается на скейтборде в лесу», а нейросеть, анализируя эту информацию, выдает вот такую картинку:

Самое примечательное, что DALLE в своем творчестве (иначе назвать это даже невозможно) использует не только известные ей и нам предметы, но и способна создавать абсолютно новые комбинации, производя на свет несуществующие в природе объекты.

Как видим, не зря разработчики данной нейронки вложили в её алгоритм аж 12 миллиардов различных параметров (комбинаций слов и пикселей) на базе GPT-3 (третье поколение алгоритма обработки естественного языка), которые она способна комбинировать между собой. Кстати, насчет разработчиков…
Создателем DALL-E является американская компания OpenAI, одним из основателей которой является никто не иной как Илон Маск. Данная компания ставит своей задачей разработку революционных технологий в области искусственного интеллекта. Как видим, пока это удаётся ей вполне успешно 🙂 Подробнее работе нейросети можно узнать из блога OpenAI
Технология DALL·E очень сложна. Я прочитал с десяток различных статей на эту тему, и никто так и не смог доходчиво (лично для меня) объяснить как принцип работы этой нейросети. Все в один голос утверждают, что простыми словами объяснить это невозможно, а следовательно, не стоит и пытаться. Мол, это чудо, и воспринимайте его как есть 🙂

Более того, результаты, выдаваемые DALLE, оказались настолько фантастически качественными, что разработчики и сами не ожидали такого от своей нейронки! В какой-то момент времени они даже заметили, что нейросеть создала элементы своего собственного языка, которым пытается общаться с самими разработчиками!
Так, ни с того ни с сего, DALL-E начала выдавать вместе с генерируемыми ею картинками какую-то «тарабарщину» — комбинацию букв и слов, которая не встречается ни в одном языке. Но если разработчики вводили ей эти фразы в качестве исходных данных, то нейросеть их вполне понимала и выдавала логически связанные с ними картинки.

К примеру, словосочетание «Apoploe vesrreaitais» означает птиц, а фраза «Contarra ccetnxniams luryca tanniounons» подразумевает под собой жуков или насекомых-вредителей. При совмещении этих понятий одним предложением в запросе нейросеть выдавала птиц, поедающих насекомых 🙂
DALL-E 2 — эволюция искусственного интеллекта
В 2022 году разработчики из OpenAI анонсировали улучшенную нейросеть DALL-E 2, созданную на основе предшественницы. Эта нейронка способна создавать просто невероятные фотореалистичные изображения всего лишь по заданным фразам и целым предложениям. Только посмотрите на что она способна!

DALL·E 2 может работать в трех режимах:

Последний режим в буквально смысле ошарашивает! Только посмотрите как DALLE 2 «додумывает» недостающие фрагменты известных нам картин, создавая таким образом более целостный образ:



Если вы вдруг не поняли, то в приведенных парах сверху будет оригинал, а снизу — работа DALLE-2. Видео, где вы своими глазами увидите другие вариации приведенных выше картин, а также некоторых других:
Кстати фоновая музыка, звучащая в этом ролике, была создана мной буквально за пару минут при помощи сервиса Mubert.
Чем отличается нейросеть DALL-E 2 от DALLE?
Среди преимуществ DALL-E 2 над первой версией нейронки можно выделить следующие:
Как попробовать DALL-E 2?
Инженеры из OpenAI прекрасно осознают революционность своей разработки и к чему может привести её бесконтрольное применение в массах. Взять, к примеру, ту же технологию дипфейков.
Поэтому, несмотря на то что со временем OpenAI собирается выложить код DALL-E в открытый доступ, сейчас попробовать нейросеть можно только по приглашениям, записавшись в лист ожидания. По состоянию на май 2022 более 600 человек из «простых смертных» имеют доступ к нейросети.
Ну а пока доступа у вас нет, рекомендую подписаться на инстаграм openaidalle, где разработчики регулярно делятся классными шедеврами кисти искусственного интеллекта.

Dalle Mini (Dalle Mani) – ИИ с открытым исходным кодом
Dall-E mini — это программа искусственного интеллекта для преобразования текста в изображение, которая получила свое название от оригинального Dall-E. Команда энтузиастов-разработчиков этой мини-версии пытается воспроизвести результаты OpenAI с помощью модели с открытым исходным кодом.
Этот вариант нейросети может попробовать любой желающий по ссылке: https://huggingface.co/spaces/dalle-mini/dalle-mini
Помните, в начале статьи я упомянул, что некоторые ожидали от DALL-E 2 очень многого (судя по картинкам, выдаваемым разработчиками), а по факту немного разочаровались в нейросети? Так вот это благодаря тому, что оригинального DALL·E 2 нет в открытом доступе, а Dall-E mini выдаёт, честно говоря, весьма посредственные результаты.

Общий смысл нейросеть безусловно угадывает, но реализация… Впрочем, будем надеяться, что это всё поправимо в будущем.
Пользуясь Dall-E mini, почти все думают, что это и есть оригинальная разработка OpenAI, но это не так! Что Гугл, что Яндекс почему-то не выдают ссылки на официальный сайт Dall-E 2 по соответствующим запросам, а дают ссылки на Dalle Mini, Dalle Mani, ruDALL-E и прочие аналогичные разработки, которые просто на порядки хуже оригинала по выдаваемому результату.
Поэтому и вы не ждите от DALL-E mini чего-то сверхъестественного. Вот пример того, на что способен его искусственный интеллект:

Запрос для генерации картинки надо вводить на английском языке, время создания изображения может занимать до 5 минут.
ruDALL-E – DALL·E на русском?
ruDALL-E, как я упомянул ранее, является одной из альтернативных разработок, стремящихся воспроизвести результаты оригинальной нейросети от OpenAI. Прямое участие в ней принимали команды Sber AI, SberDevices, Самарского университета, AIRI и SberCloud.

В настоящее время в open source доступны четыре модели генератора:
Подробно о ruDALL-E можно прочитать на Хабре в блоге компании Сбер.
Применение нейросети DALL-E
Технология преобразование текста в изображения носит поистине революционный характер, который в прямом смысле перевернет многие области. Возьмем, к примеру, художников-иллюстраторов. Если раньше для создания иллюстраций в художественной книге надо было платить за это художнику, то сейчас это можно делать при помощи нейросети совершенно бесплатно. Просто введите отрывок текста в DALL·E, и нейросеть выдаст вам с десяток прекрасных иллюстраций.

Блогерам, веб-мастерам, периодическим изданиям, СМИ и пр. теперь незачем платить за уникальные картинки на фотостоках к своим статьям и публикациям. Буквально за несколько минут можно сгенерировать с десяток отличных картинок абсолютно на любую тему!
Известный журнал Cosmopolitan в одном из своих свежих номеров использовал для иллюстрации обложки картинку, созданную в DALL-E 2. Это прецедент, который несомненно войдет в тренд и послужит громадным стартом применения нейросетей в массмедиа.

Наконец, генератор текста в изображение DALL·E 2 – это отличный пример того, как искусственный интеллект продолжает развиваться в наше время.
Как пользоваться DALL-E 2? О художественной нейросети

Первая версия нейросети, способной рисовать картинки по описаниям, казалась забавным экспериментом, но чаще вызывала усмешку. Получалась абстрактная несуразица, в которой тяжело рассмотреть конкретные образы. Второе поколение – совсем другое дело. Но как пользоваться DALL-E 2 обычному пользователю? Сейчас получить доступ можно сугубо по заявке.
Переходим на официальный ресурс, где и вводим необходимую информацию. Указываем имя, фамилию, контактный E-mail и опциональные ссылки на соцсети. Указывать биографические сведения не потребуется, достаточно выбрать тип своей персоны: медийная личность, журналист или иной представитель прессы, учёный или научный сотрудник.
Понятно, что лучше не писать о своём желании воспользоваться мощнейшим инструментом сугубо для себя. Сейчас инструментарий ориентируется на узкий круг лиц, что обуславливается ограниченными мощностями серверной инфраструктуры. В дальнейшем постепенно сфера эксплуатации будет расширяться.

Как получить доступ к DALL-E 2 – как пользоваться нейросетью и в чём отличие от первой версии?
Глобальных изменений несколько. Первостепенное – увеличенное разрешение получаемых изображений. Главное – это гибкая обработка запросов на более чем 107 языках мира. Русский в списке присутствует, причём можно задавать комплексные описания. «Крыса едет на велосипеде и улыбается», «Слон сбил хоботом Луну», «Пчелы таранят танк» и т. д.
Точность распознавания также возросла. Можно задавать разнообразные настройки, подбирать цветовые фильтры и тщательно продумывать стиль изображения. Допустимо и дорисовывать загруженную картинку, в Сети полно результатов с Моной Лизой и другими известнейшими полотнами художников. Как именно работают алгоритмы?
Существуют миллионы факторов, влияющих на результат генерации. Очевидно, что активно используются поисковые системы. Поскольку нейросеть требует вычислительных ресурсов, время ожидания может варьироваться от пары минут до нескольких часов или более. Всё зависит от общего количества одновременно подключенных к ней пользователей. Когда ждать общедоступности? Неизвестно, ожидаем информации от разработчиков.
DALL·E от OpenAI: Генерация изображений из текста. Один из важнейших прорывов ИИ в начале 2021 года

Пару дней назад мы подводили ИИ итоги 2020-го года в мире машинного обучения. 2021-й год только начался, но мы определенно видим одну из важнейших работ в области ИИ текущего года.
Итак, исследователи в области искусственного интеллекта из OpenAI создали нейронную сеть под названием DALL·E, которая генерирует изображения из текстового описания на естественном языке.

Если тебе интересно машинное обучение, то приглашаю в «Мишин Лернинг» — мой субъективный телеграм-канал об искусстве глубокого обучения, нейронных сетях и новостях из мира искусственного интеллекта.
DALL·E представляет собой версию GPT-3 с 12 миллиардами параметров, обученную генерировать изображения из текстовых описаний на датасете из пар текст-изображение. Исследователи обнаружили, что DALL·E обладает огромным репертуаром генеративных возможностей, включая возможность создания антропоморфных животных и других необычных объектов, комбинирующих совершенно нетривиальные свойства, например «кресло в форме авокадо.»
 Изображения, сгенерированные DALL·E на основании текстового описания «кресло в форме авокадо»
Изображения, сгенерированные DALL·E на основании текстового описания «кресло в форме авокадо»
Можно сказать, что уже были все предпосылки к созданию DALL·E: прошлогодний триумф GPT-3 и успешное создание Image GPT сети, способной к генерации изображений на основе текста, использующей языковую модель трансформер GPT-2. Все уже подходило к тому, чтобы создать новую модель, взяв в этот раз за основу GPT-3. И теперь DALL·E показывает невиданные доселе чудеса манипулирования визуальными концепциями с помощью естественного языка!
Как и GPT-3, DALL·E — это языковая модель-трансформер, принимающая на вход текст и изображение, как последовательность размером до 1280 токенов. Модель обучена максимизировать правдоподобие при генерации токенов, следующих один за другим.
Также, сотрудники из openai выразили озадаченность тем, что уровень реалистичности и результаты работы современных генеративных моделей могут оказать сильное влияние на общество. И опасаются за возможные неоднозначные социальные и экономические последствия использования подобных технологий.
Давайте посмотрим на примеры, которые говорят сами за себя. Исследователи утверждают, что не использовали ручной «cherry picking». Примерами являются изображения, полученные при помощи DALL·E, в которых используются 32 лучших примера из 512-ти сгенерированных, отобранных нейросетью нейронного ранжирования CLIP, созданную теми же OpenAI.
Text: a collection of glasses sitting on the table
 Изображения, сгенерированные DALL·E
Изображения, сгенерированные DALL·E
Забавно, что алгоритм способен к мультимодальности, и справляется с неоднозначностью слова glasses в английском языке.
Text: an emoji of a baby penguin wearing a blue hat, red gloves, green shirt, and yellow pants
 Эмодзи пингвиненка, одетого в голубую шапку, красные перчатки, зеленую футболку и желтые штаны
Эмодзи пингвиненка, одетого в голубую шапку, красные перчатки, зеленую футболку и желтые штаны

DALL·E может не только генерировать изображение с нуля, но и регенерировать (достраивать) любую прямоугольную область существующего изображения, вплоть до нижнего правого угла изображения, в соответствии с текстовым описанием. В качестве примера за основу взяли верхнюю часть фотографии бюста Гомера. Модель принимает на вход это изображение и текст: a photograph of a bust of homer
Text: a photograph of a bust of homer
 Фотография бюста Гомера
Фотография бюста Гомера
Особенно поражает то, что DALL·E выучил исторический и географический контекст. Модель способна к обобщению тенденций в дизайне и технологиях. Вот пример того, как DALL·E генерирует телефонные аппараты разных десятилетий двадцатого века.
 Фотографии телефонов разных десятилетий XX века
Фотографии телефонов разных десятилетий XX века
DALL·E попросили сгенерировать изображение по следующему описанию: «гостиная с двумя белыми креслами и картиной Колизея, картина установлена над современным камином». Как оказалось DALL·E может создавать картины на самые разные темы, включая реальные локации, такие как «Колизей», и вымышленных персонажей, таких как «йода». Для каждого объекта DALL·E предлагает множество вариантов. В то время как картина почти всегда присутствует на изображении, DALL·E иногда не может нарисовать камин или правильное количество кресел.
Text: a living room with two white armchairs and painting of the colosseum. the painting is mounted above a modern fireplace
 Гостиная с двумя белыми креслами и картиной Колизея, висящей над современным камином
Гостиная с двумя белыми креслами и картиной Колизея, висящей над современным камином
Название модели DALL·E (DALL-E, DALL E) является словослиянием имени художника Сальвадора Дали и робота WALL·E от Pixar. Вышел такой своеобразный Вали-Дали. Вообще в мире ИИ «придумывание» таких оригинальных названий — это некий тренд. Что определенно радует, и делает эту область еще более оригинальной.
 Старый добрый перенос стиля WALL · E в Dalí
Старый добрый перенос стиля WALL · E в Dalí
Для пущего сюрреализма и оправдания своего названия DALL·E «попросили» сгенерировать животных, синтезированных из множества понятий, включая музыкальные инструменты, продукты питания и предметы домашнего обихода. Хотя это не всегда удавалось, исследователи обнаруживали, что DALL·E иногда принимает во внимание формы двух объектов при решении о том, как их объединить. Например, когда предлагается нарисовать «улитку-арфу».
Text: a snail made of harp
 Улитка-Арфа. Фантастические твари и где они обитают..
Улитка-Арфа. Фантастические твари и где они обитают..
Вывод
DALL·E — это декодер-трансформер, который принимает и текст, и изображение в виде единой последовательности токенов (1280 токенов = 256 для текста + 1024 для изображения) и далее генерирует изображения авторегрессивном режиме. По-видимому, авторегрессивный режим работы трансформера создает дискретную репрезентацию в разрешении 32х32, после чего VQVAE предобученный энкодер-декодер «завершает генерацию» до разрешения 256×256. Оговорюсь, что последнее предложение — это мое предположение, нужно подождать выхода самого пейпера.
Что можно сказать? Наступает эра «великого объединения» языковых моделей, компьютерного зрения и генеративных сетей. То что мы видим сейчас, уже поражает воображение своими результатами, не говоря уже о том, насколько подобные подходы могут изменить процесс генерации контента.
Как будет возможность, подготовлю уже технический разбор самой модели DALL·E, учитывая, что ребята из openai обещают предоставить более подробную информацию об архитектуре и обучении модели в ближайшее время.
Полезные ссылки
Чтобы сделать публикацию еще более полезной, я добавил образовательные материалы, которые могут быть интересны начинающим и продолжающим свой путь в мир машинного обучения:
Ну вот и все! Надеюсь, что материал оказался полезным. Спасибо за прочтение!
Что ты думаешь о DALL·E и подобных генеративных нейронных моделях, способных создавать визуальный контент по текстовому описанию? Где может быть полезна такая технология? Насколько тебя впечатлили результаты? Давай обсудим в комментариях.
DALL·E 2 — мои первые эксперименты с возможностями нейросети
Еще в прошлом году я в свое время подавался в лист ожидания для того чтобы опробовать нейросеть GPT3 для генерации текстов, и спустя достаточно длительное ожидание она попала ко мне в руки, и даже в рабочем проекте мы с ней поэкспериментировали.
И когда Open AI открыли возможность получить доступ к их новой нейросети DALL·E 2 я конечно же воспользовался возможностью и вот на прошлой неделе и она попала мне в руки.
Введение — а что это за DALL·E 2 такая?
Немного про саму нейросеть DALL·E 2 — она создана для генерации изображений на основе пользовательского описания.
https://openai.com/dall-e-2/ — на сайте проекта достаточно подробно и с примерами показывается что эта штука уже может, но я добавлю пару примеров в статью, чтобы у вас как у читателя сразу был некоторый контекст.
 Астронавт отдыхающий в тропическом отеле в космосе в фотореалистичном стиле
Астронавт отдыхающий в тропическом отеле в космосе в фотореалистичном стиле  Тарелка супа которая является порталом в другое измерение как «digital art» («цифровое искусство»)
Тарелка супа которая является порталом в другое измерение как «digital art» («цифровое искусство»)  Астронавт верхом на лошади как карандашный рисунок
Астронавт верхом на лошади как карандашный рисунок
Также кроме создания изображений с нуля, данная нейросеть способна модифицировать изображения дорисовывая что-то на них, так и создавать варианты исходного изображения.
 Пример создания вариантов из исходного изображения
Пример создания вариантов из исходного изображения  Пример модификации изображения — нейросеть попросили дорисовать диван
Пример модификации изображения — нейросеть попросили дорисовать диван
Итак, после того как все мы поняли что же эта штука умеет, настало время проверить это на практике.
Тесты нейросети
Этот вариант генерации вышел несколько абстрактным, но в целом неплохо

 Unreal engine 5 space station background inspired with space games and films
Unreal engine 5 space station background inspired with space games and films
Viewst team (developers, designers, managers and so on) making coding and sales of they wysiwyg software what helps create animated banners in Leonardo da Vinci styles
Как видно получается неплохо, задумка похожа на стоковые фотографии о командах которые делают свои дизайнерско\разработческие и прочие дела, но вот качество лиц конечно подкачало на «фотореалистичных вариантах»





Теперь перейдем к другим стилям
Realistic oil painting of Doggy in medieval armor with viewst chameleon logo on shield fighting with dragon of low sales
(Реалистичная масляная живопись изображающую Догги в средневековой броне с Viewst логотипом хамелеоном на щите сражающейся с драконом низких цен)
А вот это уже весьма круто выглядит и более чем соответствует запросу — не считая отсутствия дракона низких цен 🙂





Photo of cosplayers with costumes from games, films, anime before they go on stage to show whey work and performance
(Фото косплееров с костюмами по играм, фильмам и аниме перед тем как они выйдут на сцену показать свою работу и выступление)
Опять мы видим проблему с лицами людей (и любовь по всей видимости к аниме у нейросети 🙂 )





А теперь попробуем поменять стиль для такого запроса
Digital art of cosplayers with costumes from games, films, anime before they go on stage to show whey work and performance





И для картинки с девушкой с фиолетовыми волосами я решил посмотреть как сработает функция создания вариантов — и получилось более чем достойно




Pixel art of cosplayers with costumes from games, films, anime before they go on stage to show whey work and performance
И пиксель арт получается достаточно интересный





А теперь пришло время пейзажей. Как вариант я решил посмотреть что же может сделать нейросеть касательно моего родного города Рыбинска, и насколько это будет похоже на открыточные виды.
An impressionist watercolor painting of Rybinsk with view from water on bridge, museum and church at summer time
Этим результатом я был очень впечатлен, так как на многих фотографиях обычно как раз фигурирует собор, здание музея с красной крышей и мостом через волгу





И для примера фотография

Затем для того же запроса я попросил сделать еще вариантов, и вот что получилось





А затем я решил посмотреть на варианты пейзажей с осенью вместо лета и сменить стиль с акварели на масло
An impressionist oil painting painting of Rybinsk with view from water on bridge, museum and church at autumn time





Затем я решил попробовать режим работы с созданием вариантов по готовому изображению.
Я взял картинку медведя-пивовара из моего туристического пэт-проекта, и запросил нейросеть создать другие варианты эскиза. И получилось на удивление не плохо




Затем я опробовал вариант дорисовки\перерисовки изображения — взял картинку медведя, и запросил Bear in engineering helmet and blueprints in hands и разметив область головы и рук (вместо секиры)




Далее я решил посмотреть, что будет если разметить все изображение как возможное место для перерисовки с запросом Bear in watercolor type with Rybinsk museum background
Как видно, в таком случае сеть никак по большей части не отталкивается от предыдущего стиля изображения, а только от текстового описания.




И еще раз попробовал варианты, в этот раз вышло более коряво для медведя с секирой




Продолжим пробы с вариантами — тут я использовал свою фотографию с фестиваля в косплее на Иванушку из Морозко




Еще варианты косплейной фотографии, на этот раз с моим Айзеком из Dead Space 2





И еще немного перерисовки фотографии с запросом Phot if Russian summer forest (да, я опечатался)




А теперь продолжим с безумными запросами, часть из которых мне подсказали)
Wrestler in ball gown (рестлер в бальном платье)





Wrestler in ball gown from renesanse time in style of Yan van Eyk


DND dwarf monk character who likes cats and use as iron apples to fight for balance in a world (ДНД персонаж гном монах который любит котов и использует железные яблоки для того чтобы бороться за баланс в мире)




DND dwarf monk character who likes cats and use as iron apples to fight for balance in a world in unreal engine 5 style
И вот что будет если мы чуток поменяем запрос и попросим стиль Unreal Engine 5





Warhammer elf mage character riding a white Chinese dragon in unreal engine 5 style (Warhammer персонаж маг-эльф верхом на белом китайском драконе в стиле Unreal Engine 5)
Продолжим фэнтези тематику





Warhammer elf mage character riding a white Chinese dragon (Warhammer персонаж маг-эльф верхом на белом китайском драконе)





“Warhammer elf mage character riding a white Chinese dragon” by Yan van Eyk





Проба работы с вариантами логотипа

Medieval cockatiel tapestry
И еще один подсказанный запрос который вышел просто потрясающе















Medieval cockatiel tapestry as wallpapers in modern house
И вариант с попугаями выше в виде обоев




Красивый лес в стиле Шишкина с гигантскими мухоморами и охотниками за шишками
А теперь проверим как нейронка «понимает» другие языки, в частности русский — как мы видим в целом про лес и шишки и мухоморы понято, но уже не так хорошо.





Photorealistic 3d render of donut with blue glaze and small yellow hearts and pearls on glaze in purple room
Продолжим с вариантами генерации изображений. Данный запрос я составил, чтобы посмотреть получится ли что-то похожее на работу в 3d от @Troxx_cosplay

И вот что получилось





Oil painting of landscape with road going through field surrounded by forest. Road goes to giant grey concrete building, with few small windows on top. All landscape is foggy
Продолжаем тему пейзажей




Еще немного работы с вариантами картинки

Young woman not tall with short blue hair and many earrings with feathers and stones in light jacket, brown shirts, high socks and army shoes in watercolor style

Кокадутиэль
И тут отлично выглядящие пейзажи





“Front end and backend developers arguing to create ultimate developer”by Leonardo da Vinci

Front end and backend developers arguing to create ultimate developer in medival style

Disco elisium detective fighting his destiny in medival style

Что же можно сказать по итогу (после того как я потратил все доступные бесплатные лимиты).
Так что нас ждет очень интересное будущее 🙂
Мое первое знакомство с StableDiffusion, MidJourney и Dall-e 2
Вот я наконец-то и добрался до поста, который обещаю всем кому не лень =) А особенно в своей телеграм-группе, посвященной AI-ART.
В первую очередь хочу рассказать о StableDiffusion, доступ к которому получил сегодня. =) И пока эмоции свежи, начинаем.
Я не буду тратить много времени на рассказ о том, что это такое и зачем. В интернете уже полно информации об этом. А просто сразу перейду к своим арт-экспериментам.
Итак, так как я очень люблю породу «Golden Retriever», то первый запрос был таким.
a golden retriever in the grass field watching a distant view of a dramatic valley landscape, golden retriever, beautiful lighting, 8 k, high resolution detailed face, epic beauty, cinematic
multicolor drawing of cute creature sits in the dark forest by ray caesar created at modern world in 4 k ultra high resolution, with inspiring feeling
Кстати, с этим запросом мне помогло приложение Phraser
Вариаций можно получить миллион, но я пошел дальше, так как мое время ограничено и не мог сильно засиживаться за экспериментами.
Я очень люблю Simon Stalenhag и роботов.
fantastic robots fighting with each other in new zealand, dynamic scene, work in the style of simon stalenhag, 2 k
Далее я приступил к проверке генерации девушек с прическами. Так как MidJourney и Dalle-2 не совсем удовлетворили мои запросы.
young woman, big braids, slightly tanned, heroine, oil painting, portrait, intricate complexity, rule of thirds, in the style of artgerm, character concept
А тут сразу получилось то, что я хотел. Чуть позже покажу, что генерили MidJourney и Dalle.
Тот же запрос, но с другим стилем.
young woman, big braids, slightly tanned, heroine, oil painting, portrait, intricate complexity, rule of thirds, character concept by anderson, sophie
Кстати, SD обучен многим стилям и посмотреть их можно здесь
Идем дальше. Тот же запрос, но в еще одном стиле. Уж больно мне понравилось, как он генерит портреты.
young woman, big braids, slightly tanned, heroine, oil painting, portrait, intricate complexity, rule of thirds, character concept by bagshaw, tom
Ну и напоследок, с тем же запросом решил сгенерить фото в стиле Steve Mccurry
photo of beautifull europian woman with big braids by steve mccurry created at contemporary in 4 k ultra high resolution and with ultra wide angle, with inspiring feeling
Еще один запрос, с которым не справился MidJourney.
И опять же видим проблему SD в дубликации контента. Когда я спросил чат о том, как этого избежать, мне дали такой ответ:
Но, благодаря Dalle-2 Inpainting у меня получилось стереть лищних барышень и добиться того, что я хотел.
DALL·E: Creating Images from Text
We’ve trained a neural network called DALL·E that creates images from text captions for a wide range of concepts expressible in natural language.
DALL·E is a 12-billion parameter version of GPT-3 trained to generate images from text descriptions, using a dataset of text–image pairs. We’ve found that it has a diverse set of capabilities, including creating anthropomorphized versions of animals and objects, combining unrelated concepts in plausible ways, rendering text, and applying transformations to existing images.
See also: DALL·E 2, which generates more realistic and accurate images with 4x greater resolution.




















GPT-3 showed that language can be used to instruct a large neural network to perform a variety of text generation tasks. Image GPT showed that the same type of neural network can also be used to generate images with high fidelity. We extend these findings to show that manipulating visual concepts through language is now within reach.
Overview
Like GPT-3, DALL·E is a transformer language model. It receives both the text and the image as a single stream of data containing up to 1280 tokens, and is trained using maximum likelihood to generate all of the tokens, one after another. [1] This training procedure allows DALL·E to not only generate an image from scratch, but also to regenerate any rectangular region of an existing image that extends to the bottom-right corner, in a way that is consistent with the text prompt.
We recognize that work involving generative models has the potential for significant, broad societal impacts. In the future, we plan to analyze how models like DALL·E relate to societal issues like economic impact on certain work processes and professions, the potential for bias in the model outputs, and the longer term ethical challenges implied by this technology.
Capabilities
We find that DALL·E is able to create plausible images for a great variety of sentences that explore the compositional structure of language. We illustrate this using a series of interactive visuals in the next section. The samples shown for each caption in the visuals are obtained by taking the top 32 of 512 after reranking with CLIP, but we do not use any manual cherry-picking, aside from the thumbnails and standalone images that appear outside. [2]
Controlling Attributes
We test DALL·E’s ability to modify several of an object’s attributes, as well as the number of times that it appears.

We find that DALL·E can render familiar objects in polygonal shapes that are sometimes unlikely to occur in the real world. For some objects, such as “picture frame” and “plate,” DALL·E can reliably draw the object in any of the polygonal shapes except heptagon. For other objects, such as “manhole cover” and “stop sign,” DALL·E’s success rate for more unusual shapes, such as “pentagon,” is considerably lower.
For several of the visuals in this post, we find that repeating the caption, sometimes with alternative phrasings, improves the consistency of the results.


Drawing Multiple Objects
Simultaneously controlling multiple objects, their attributes, and their spatial relationships presents a new challenge. For example, consider the phrase “a hedgehog wearing a red hat, yellow gloves, blue shirt, and green pants.” To correctly interpret this sentence, DALL·E must not only correctly compose each piece of apparel with the animal, but also form the associations (hat, red), (gloves, yellow), (shirt, blue), and (pants, green) without mixing them up. [3] We test DALL·E’s ability to do this for relative positioning, stacking objects, and controlling multiple attributes.



While DALL·E does offer some level of controllability over the attributes and positions of a small number of objects, the success rate can depend on how the caption is phrased. As more objects are introduced, DALL·E is prone to confusing the associations between the objects and their colors, and the success rate decreases sharply. We also note that DALL·E is brittle with respect to rephrasing of the caption in these scenarios: alternative, semantically equivalent captions often yield no correct interpretations.
Visualizing Perspective and Three-Dimensionality
We find that DALL·E also allows for control over the viewpoint of a scene and the 3D style in which a scene is rendered.


To push this further, we test DALL·E’s ability to repeatedly draw the head of a well-known figure at each angle from a sequence of equally spaced angles, and find that we can recover a smooth animation of the rotating head.

DALL·E appears to be able to apply some types of optical distortions to scenes, as we see with the options “fisheye lens view” and “a spherical panorama.” This motivated us to explore its ability to generate reflections.

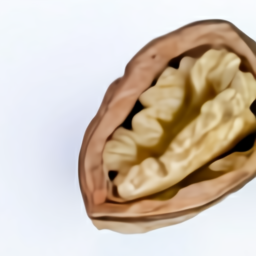
Visualizing Internal and External Structure
The samples from the “extreme close-up view” and “x-ray” style led us to further explore DALL·E’s ability to render internal structure with cross-sectional views, and external structure with macro photographs.

Inferring Contextual Details
The task of translating text to images is underspecified: a single caption generally corresponds to an infinitude of plausible images, so the image is not uniquely determined. For instance, consider the caption “a painting of a capybara sitting on a field at sunrise.” Depending on the orientation of the capybara, it may be necessary to draw a shadow, though this detail is never mentioned explicitly. We explore DALL·E’s ability to resolve underspecification in three cases: changing style, setting, and time; drawing the same object in a variety of different situations; and generating an image of an object with specific text written on it.


We find that DALL·E is sometimes able to render text and adapt the writing style to the context in which it appears. For example, “a bag of chips” and “a license plate” each requires different types of fonts, and “a neon sign” and “written in the sky” require the appearance of the letters to be changed.
Generally, the longer the string that DALL·E is prompted to write, the lower the success rate. We find that the success rate improves when parts of the caption are repeated. Additionally, the success rate sometimes improves as the sampling temperature for the image is decreased, although the samples become simpler and less realistic.
With varying degrees of reliability, DALL·E provides access to a subset of the capabilities of a 3D rendering engine via natural language. It can independently control the attributes of a small number of objects, and to a limited extent, how many there are, and how they are arranged with respect to one another. It can also control the location and angle from which a scene is rendered, and can generate known objects in compliance with precise specifications of angle and lighting conditions.
Unlike a 3D rendering engine, whose inputs must be specified unambiguously and in complete detail, DALL·E is often able to “fill in the blanks” when the caption implies that the image must contain a certain detail that is not explicitly stated.
Applications of Preceding Capabilities
Next, we explore the use of the preceding capabilities for fashion and interior design.


We explore DALL·E’s ability to render male mannequins in a variety of different outfits. When prompted with two colors, e.g., “an orange and white bomber jacket” and “an orange and black turtleneck sweater,” DALL·E often exhibits a range of possibilities for how both colors can be used for the same article of clothing.
DALL·E also seems to occasionally confuse less common colors with other neighboring shades. For example, when prompted to draw clothes in “navy,” DALL·E sometimes uses lighter shades of blue, or shades very close to black. Similarly, DALL·E sometimes confuses “olive” with shades of brown or brighter shades of green.






Combining Unrelated Concepts
The compositional nature of language allows us to put together concepts to describe both real and imaginary things. We find that DALL·E also has the ability to combine disparate ideas to synthesize objects, some of which are unlikely to exist in the real world. We explore this ability in two instances: transferring qualities from various concepts to animals, and designing products by taking inspiration from unrelated concepts.

We find that DALL·E can generate animals synthesized from a variety of concepts, including musical instruments, foods, and household items. While not always successful, we find that DALL·E sometimes takes the forms of the two objects into consideration when determining how to combine them. For example, when prompted to draw “a snail made of harp,” it sometimes relates the pillar of the harp to the spiral of the snail’s shell.
In a previous section, we saw that as more objects are introduced into the scene, DALL·E is liable to confuse the associations between the objects and their specified attributes. Here, we see a different sort of failure mode: sometimes, rather than binding some attribute of the specified concept (say, “a faucet”) to the animal (say, “a snail”), DALL·E just draws the two as separate items.
In the preceding visual, we explored DALL·E’s ability to generate fantastical objects by combining two unrelated ideas. Here, we explore its ability to take inspiration from an unrelated idea while respecting the form of the thing being designed, ideally producing an object that appears to be practically functional. We found that prompting DALL·E with the phrases “in the shape of,” “in the form of,” and “in the style of” gives it the ability to do this.
When generating some of these objects, such as “an armchair in the shape of an avocado”, DALL·E appears to relate the shape of a half avocado to the back of the chair, and the pit of the avocado to the cushion. We find that DALL·E is susceptible to the same kinds of mistakes mentioned in the previous visual.
Animal Illustrations
In the previous section, we explored DALL·E’s ability to combine unrelated concepts when generating images of real-world objects. Here, we explore this ability in the context of art, for three kinds of illustrations: anthropomorphized versions of animals and objects, animal chimeras, and emojis.
We find that DALL·E is sometimes able to transfer some human activities and articles of clothing to animals and inanimate objects, such as food items. We include “pikachu” and “wielding a blue lightsaber” to explore DALL·E’s ability to incorporate popular media.
We find it interesting how DALL·E adapts human body parts onto animals. For example, when asked to draw a daikon radish blowing its nose, sipping a latte, or riding a unicycle, DALL·E often draws the kerchief, hands, and feet in plausible locations.

We find that DALL·E is sometimes able to combine distinct animals in plausible ways. We include “pikachu” to explore DALL·E’s ability to incorporate knowledge of popular media, and “robot” to explore its ability to generate animal cyborgs. Generally, the features of the second animal mentioned in the caption tend to be dominant.
We also find that inserting the phrase “professional high quality” before “illustration” and “emoji” sometimes improves the quality and consistency of the results.

Zero-Shot Visual Reasoning
GPT-3 can be instructed to perform many kinds of tasks solely from a description and a cue to generate the answer supplied in its prompt, without any additional training. For example, when prompted with the phrase “here is the sentence ‘a person walking his dog in the park’ translated into French:”, GPT-3 answers “un homme qui promène son chien dans le parc.” This capability is called zero-shot reasoning. We find that DALL·E extends this capability to the visual domain, and is able to perform several kinds of image-to-image translation tasks when prompted in the right way.
We find that DALL·E is able to apply several kinds of image transformations to photos of animals, with varying degrees of reliability. The most straightforward ones, such as “photo colored pink” and “photo reflected upside-down,” also tend to be the most reliable, although the photo is often not copied or reflected exactly. The transformation “animal in extreme close-up view” requires DALL·E to recognize the breed of the animal in the photo, and render it up close with the appropriate details. This works less reliably, and for several of the photos, DALL·E only generates plausible completions in one or two instances.
Other transformations, such as “animal with sunglasses” and “animal wearing a bow tie,” require placing the accessory on the correct part of the animal’s body. Those that only change the color of the animal, such as “animal colored pink,” are less reliable, but show that DALL·E is sometimes capable of segmenting the animal from the background. Finally, the transformations “a sketch of the animal” and “a cell phone case with the animal” explore the use of this capability for illustrations and product design.

We did not anticipate that this capability would emerge, and made no modifications to the neural network or training procedure to encourage it. Motivated by these results, we measure DALL·E’s aptitude for analogical reasoning problems by testing it on Raven’s progressive matrices, a visual IQ test that saw widespread use in the 20th century.

Rather than treating the IQ test a multiple-choice problem as originally intended, we ask DALL·E to complete the bottom-right corner of each image using argmax sampling, and consider its completion to be correct if it is a close visual match to the original.
DALL·E is often able to solve matrices that involve continuing simple patterns or basic geometric reasoning, such as those in sets B and C. It is sometimes able to solve matrices that involve recognizing permutations and applying boolean operations, such as those in set D. The instances in set E tend to be the most difficult, and DALL·E gets almost none of them correct.
For each of the sets, we measure DALL·E’s performance on both the original images, and the images with the colors inverted. The inversion of colors should pose no additional difficulty for a human, yet does generally impair DALL·E’s performance, suggesting its capabilities may be brittle in unexpected ways.
Geographic Knowledge
We find that DALL·E has learned about geographic facts, landmarks, and neighborhoods. Its knowledge of these concepts is surprisingly precise in some ways and flawed in others.



Temporal Knowledge
In addition to exploring DALL·E’s knowledge of concepts that vary over space, we also explore its knowledge of concepts that vary over time.

Summary of Approach and Prior Work
DALL·E is a simple decoder-only transformer that receives both the text and the image as a single stream of 1280 tokens—256 for the text and 1024 for the image—and models all of them autoregressively. The attention mask at each of its 64 self-attention layers allows each image token to attend to all text tokens. DALL·E uses the standard causal mask for the text tokens, and sparse attention for the image tokens with either a row, column, or convolutional attention pattern, depending on the layer. We provide more details about the architecture and training procedure in our paper.
Text-to-image synthesis has been an active area of research since the pioneering work of Reed et. al, whose approach uses a GAN conditioned on text embeddings. The embeddings are produced by an encoder pretrained using a contrastive loss, not unlike CLIP. StackGAN and StackGAN++ use multi-scale GANs to scale up the image resolution and improve visual fidelity. AttnGAN incorporates attention between the text and image features, and proposes a contrastive text-image feature matching loss as an auxiliary objective. This is interesting to compare to our reranking with CLIP, which is done offline. Other work incorporates additional sources of supervision during training to improve image quality. Finally, work by Nguyen et. al and Cho et. al explores sampling-based strategies for image generation that leverage pretrained multimodal discriminative models.
DALL·E — революция в генерации изображений от OpenAI
DALL·E от новый алгоритм построенный на архитектуре GPT-3 обученный генерировать изображения по их текстовому описанию. Для этого использовался специальный датасет из пар «Текст»—«Изображение» и нейронная сеть величиной в 12 миллиардов параметров. В результате DALL·E способен генерировать иллюстрации, реалистичные фото, новые несуществующие комбинации объектов, а также: писать на изображении текст, проходить IQ тесты, генерировать изображение по заданной части, и многое, многое другое…
Объяснить лучше, на сколько это удивительно помогут только примеры. В каждом из них вверху задан текстовый запрос (или текст + часть изображения), а внизу: результаты генерации нейросети.
Как и GPT-3, DALL·E это языковая модель типа трансформер.
Исследователи начали изучать способности DALL·E понимать сложные абстрактные комбинации, изменять стиль и графику изображений, писать текст. Вот что из этого получилось:
С этим заданием нейросеть справилась впечатляюще, во многих случаях находя логически правильные решения:
Исследователи также попросили нейросеть сгенерировать конкретные географические места и достопримечательности. Ниже примеры результатов для Alamo Square и моста Золотые Ворота в Сан-Франциско. По словам авторов, сгенерированные картинки вызывают ощущение дежавю — показывают очень знакомые нам образы и места, которые на самом деле не существуют.
Еще больше примеров и результатов экспериментов вы можете найти в оригинальной статье.
Не вдаваясь в технические подробности, DALL·E — это трансформер состоящий из одного декодера, который принимает на вход последовательность из 1280 токенов, где 256 содержат текст, в 1024 оставшихся — части изображения. По сути, алгоритм обрабатывает регионы изображения так же как слова в тексте, и генерирует новые изображения таким же образом, как GPT-3 генерирует новый текст.
Начиная с прошлого года, использование языковых алгоритмов для зрительных задач стало новым трендом в машинном обучении, в котором исследователи видят большой потенциал.
Этот пост подготовлен Телеграм каналом эйай ньюз, где вы можете найти еще больше свежих новостей из мира AI.
Там я пишу про алгоритмы простым языком, но с профессиональной точки зрения, комментируя (а иногда и опровергая) то, что могут написать журналисты. Присоединяйтесь!
Встречайте новую модель ruDALL-E Kandinsky!
Недавно мы выпустили новую, большую модель ruDALL-E Kandinsky!🎉🎊🥳 Эта модель еще лучше справляется с генерацией красивых и сложных изображений! Попробовать ее уже можно в приложении Салют.
В приложении достаточно просто сказать «Запусти художника», а затем голосом попросить художника ruDALL-E что-нибудь нарисовать 🧑🎨
Также у нас есть бот в Discord, где можно не только сгенерить картинки, но и посмотреть генерации других пользователей! Однако в приложении Салют очередь на генерацию значительно меньше, чем в Discord
Попробуйте нашу старую модель ruDALL-E.
Напишите текстовый запрос — получите сгенерированную ИИ картинку

Светлая спальня с большой кроватью и большими зелеными пальмами по периметру
А еще мы научились генерировать эмодзи 😳😳😳 По текстовому описанию 🧚👩💻💁♂️ Попробуйте 🥺🥺🥺
Наша задача — создать «мультимодальную» нейронную сеть, которая изучает концепции в нескольких модальностях, в первую очередь в текстовой и визуальной областях, чтобы лучше понимать мир. Трансформер научен авторегрессивно моделировать токены текста и изображения как единый поток данных.
Применение
Генерация изображений решает две важные задачи, которые не может решить поиск: 1) позволяет учесть точное описание желаемого, 2) создаёт изображение, которое раньше не существовало. Генерацию изображений можно использовать, например, для фото-иллюстрации статей, в копирайтинге, в рекламе.
Самая большая вычислительная задача в истории России
На кластере Christofari модель обучалась 37 дней на 512 GPU TESLA V100, и затем еще 11 дней по 128 GPU — всего 20352 GPU-дней. Наша самая большая обученная модель XXL (12 миллиардов параметров) сравнима с английской DALL-E от OpenAI!
ruDALL-E Malevich (XL)
По короткому текстовому описанию ruDALL-E генерирует яркие и красочные изображения на самые разные темы и сюжеты. Модель понимает обширный набор понятий и генерирует совершенно новые изображения и объекты, которых не существовало в реальном мире.
Красивый горный пейзаж

Очень красивая собака

Красивая желтая птичка с красным клювом

ruDALL-E Kandinsky (XXL)
Русская text-to-image модель, генерирующая изображения по тексту. Архитектура такая же, как у ruDALL-E XL. Ещё больше параметров в новой версии!
Подсолнухи в вазе, Винсент Ван Гог

Сюрреализм, стиль

Картошка, стилизованная под аниме, с эффектами электрических разрядов, на фоне современного города в неоновом кибепанк стиле

Закат и город

ruDALL-E Emojich
По короткому текстовому описанию ruDALL-E генерирует смайлики, которые можно использовать для стикеров, клипартов и прототипов дизайна. Модель понимает обширный набор понятий и генерирует совершенно новые эмодзи, которых не существовало до этого.
Компьютер может сделать рисунок по любому описанию. Попробуйте сами
Вы уже наверняка видели в социальных сетях сюрреалистичные изображения вроде «скачущего на лошади астронавта» или «двух псов-химиков в защитных очках». Можно подумать, что это работы какого-то нового, талантливого художника со слишком развитой фантазией. Но нет — все эти изображения созданы нейросетью DALL-E 2, которую в апреле 2022 года представила компания OpenAI. При помощи нее любой человек может создавать реалистичные изображения с любым сюжетом, причем за очень короткое время — кажется, скоро художники будут не настолько нужны, как раньше. Технология перспективная, поэтому доступ к ней открыт только избранным людям. Однако, есть способ хотя бы немного оценить возможности удивительной нейросети — давайте узнаем о ней и попробуем создать свои уникальные картинки.

Изображения, созданные нейросетью DALL-E 2
Как нейросеть DALL-E 2 рисует по словам?
История нейросети, которая создает картинки на основе текстового описания, началась в 2021 году. Именно тогда компания OpenAI создала технологию DALL-E, которая создавала иллюстрации. Уже через год разработчики представили ее усовершенствованную версию DALL-E 2, которая лучше понимает ключевые слова для генерации изображений и выдает более фотореалистичные картинки в более высоком разрешении.

Результаты работы первой версии DALL-E
Чтобы описать принцип работы нейросети DALL-E 2 нужна огромная статья и знание машинного обучения, поэтому давайте обойдемся кратким описанием максимально простыми словами. Первым делом человек пишет описание того, какое изображение хочет получить — эти данные обрабатываются моделью CLIP, которая обучена на сотнях миллионов изображений и связанных с ними текстовых описаний. Модель CLIP «понимает» желание пользователя и передает его нейросети GLIDE, которая создает изображение методом обратной диффузии. Если коротко, в процессе она накладывает на исходные изображения шум, а потом из этого шума создает совершенно новую картинку.

Схема обучения DALL-E 2
Где найти нейросеть для создания картинок?
Несколько месяцев назад я уже писал статью про нейросети, которые умеют создавать картинки из текстового описания (обязательно попробуйте). Самой интересной из них является ruDALL-E — это почти то же самое, что у OpenAI, только разработанное специалистами из российского «Сбера». Он поддерживает запросы на русском языке и выдает результаты не хуже по качеству, чем у зарубежного проекта. Но доступного всем варианта нейросети DALL-E 2 нет — а хотелось бы, потому что ее художественные возможности многим кажутся безграничными.

Результаты работы ruDALL-E. Неплохо, не так ли?
Как пользоваться DALL-E mini?
На данный момент большой популярностью пользуется разве что нейросеть DALL-E mini, которая выдает результаты чуть лучше, чем у русского аналога. Но есть один минус — он не поддерживает запросы на русском, но использование переводчика еще никто не запрещал. Сайт рисующей по словам нейросети находится тут.

Пользоваться нейросетью DALL-E mini очень просто — нужно только ввести запрос и нажать на кнопку «Run». Создание изображения обычно занимает чуть более одной минуты, но при слишком большой нагрузке на сервер процесс может занять гораздо больше времени.
Что делать, если DALL-E mini не работает?
Иногда DALL-E mini не работает из-за ошибки, но в этом случае достаточно обновить страницу и ввести запрос заново. Если это не помогает, нужно попробовать позднее, потому что иногда сервер бывает перегружен.
Существует нейросеть, которая способна сделать вас персонажем Disney! Попробуйте сами.
Рисунки, созданные нейросетью
Чтобы протестировать нейронную сеть, я попробовал создать изображения, которые перекликаются с темами наших статей. Недавно космический телескоп Джеймса Уэбба столкнулся с небольшим камнем — почему бы не посмотреть на то, как бы выглядел телескоп на поверхности Марса? Получилось то, что вы видите ниже.

Телескоп Джеймса Уэбба на Марсе
Вот другой пример — примерно месяц назад ученые решили отправить в космос новые сигналы для инопланетян. В сообщение они хотят вложить информацию о местоположении Земли. Некоторые специалисты опасаются, что инопланетяне могут быть враждебными и уничтожить человечество. Почему бы не попробовать сделать инопланетян более дружелюбными? На запрос «UFO with flowers» нейросеть DALL-E mini выдала следующее.

Инопланетяне с цветами
Недавно у нас вышла статья про то, что сотни лет назад европейцы употребляли в пищу египетские мумии — это считалось полезным. Мы часто пишем про космос и археологию, поэтому DALL-E mini получил запрос про мумию в космосе. По-моему, вышло неплохо.

Египетская мумия в космосе
Еще одна интересная новость июня 2022 года — желание Илона Маска открыть собственную закусочную. Мы уже рассказывали о том, как он может выглядеть и даже показывали фотографии. А что по этому поводу думает нейросеть? Вопреки ожиданиям, ничего футуристического она не показала, обычная кафешка.

Закусочная Илона Маска
Под конец нейросеть получила максимально абстрактный запрос про «синюю утку, падающую в вулкан». По-моему, весьма забавно.

Синяя утка, падающая в вулкан
Нейросеть рисующий по словам от «Сбера»
После публикации статьи выяснилось, что разработчики от «Сбера» уже выпустили обновленную нейросеть, которая умеет рисовать картинки по текстовому описанию — новинка называется Kandinsky. Представители компании уверяют, что новая версия делает более реалистичные картинки, чем выпущенный в прошлом году ruDALL-E. В основном это стало возможным благодаря обучению на 179 миллионах изображений. Также был усовершенствован алгоритм: сначала нейросеть генерирует несколько картинок на основе запроса, потом другая модель выбирает самые удачные, а третья увеличивает разрешение самой лучшей. Запустить нейросеть Kandinsky можно в приложении «Салют» или в «умных» устройствах компании вроде дисплея Sber Portal.

Пример работы нейросети Kandinsky
Если вы этого еще не сделали, подпишитесь на нас в Дзене. Там вы найдете статьи, которые не вышли на сайте.
А вы уже поиграли с DALL-E mini или Kandinsky? Что интересного у вас получилось? Свои результаты отправляйте в наш Telegram-чат, а в комментариях пишите — как вы думаете, где такие нейросети могут быть максимально полезными?

Новости, статьи и анонсы публикаций
Свободное общение и обсуждение материалов

Искусственное мясо, которое должно остановить убийство животных, уже создано. А что насчет искусственной древесины? 🌳 Вырубая леса, люди лишают животных естественной среды обитания и тоже убивают их. Кажется, скоро этому тоже настанет конец.

Мы живем в таком мире, когда главным ресурсом является нефть. И тут бесполезно рассуждать на тему того, что появление электромобилей что-то изменит. Кроме пр…

Корабль American Courage оснащен автопилотом, поэтому не нуждается в капитане. 🚢 Он самостоятельно движется по узкой реке и ни разу не попал в аварию. Рассказываем, чем еще он так интересен, почему таких кораблей очень мало и что в будущем станет с моряками.
Внутри DALL-E 2: как устроена нейросеть, способная создать любую картинку на основе текстового описания
Краткий рассказ об «изнанке» модели, которая обучается на сотнях миллионов изображений и связанных с ними подписей.
В начале апреля OpenAI начала тестировать DALL-E 2 — обновлённую версию нейросети, впервые представленную в январе 2021 года. С помощью только короткой текстовой подсказки ИИ может генерировать совершенно новые изображения, редактировать фотографии, добавляя на них новые предметы и создавать новые рисунки на основе существующих и делать их в духе оригинала.
TJ уже рассказывал о результатах работы DALL-E 2: за постами о ней можно следить по одноимённому тегу. А быстрое представление о возможностях нейросети можно получить из клипа на песню «Feeling Good» от одного из тестировщиков.
А сейчас TJ публикует адаптацию статьи разработчика Райана О’Коннора, который подробно объяснил, как работает DALL-E 2.
На высшем уровне DALL-E 2 работает очень просто: текст вводится в кодировщик, обученный отображать подсказку. Затем «предшествующая» модель сопоставляет кодировку текста с кодировкой изображения. Наконец, модель декодирования изображения генерирует картинку-визуальное проявление этой семантической информации.
DALL-E 2 учится связывать текстовые и визуальные абстракции. Например, после ввода запроса «плюшевый мишка катается на скейтборде на Таймс-сквер» DALL-E 2 выводит следующее изображение. А ещё можно уточнить, как нейросети выполнить картинку, например, «рисунок краской», «3D-модель» или «наскальная живопись».
Откуда DALL-E 2 знает, как такое текстовое понятие, как «плюшевый мишка», проявляется в визуальном пространстве? Связь между текстовой семантикой и визуальным представлением изучается с помощью другой модели OpenAI — CLIP. Она обучается на сотнях миллионов изображений и связанных с ними подписей, выясняя, насколько конкретный фрагмент текста относится к изображению.
Вместо попыток предсказать подпись CLIP узнаёт, насколько она связана с изображением. Эта сравнительная, а не прогнозирующая цель позволяет CLIP изучать связь между текстовыми и визуальными представлениями одного и того же абстрактного объекта.
Основополагающие принципы тренировки CLIP:
CLIP важен для DALL-E 2, потому что это то, что в конечном итоге определяет, насколько семантически связан фрагмент естественного языка с визуальной концепцией. Это имеет решающее значение для создания изображений нейросетью.
Происходит это следующим образом. Возьмём «корги, играющего на трубе-огнемёте» (это реальный пример от одного из тестировщиков). Запрос проходит через кодировщик изображений CLIP. А затем GLIDE использует кодировку для создания нового изображения, сохраняющего основные черты оригинала.
GLIDE-обучение позволяет DALL-E 2 создавать фотореалистичные изображения
Для создания таких изображений GLIDE использует модель диффузии — такие модели учатся генерировать данные, обращая вспять процесс постепенного зашумления изображения.
Однако есть ряд нюансов. Так, если диффузионная модель обучена на наборе данных человеческого лица, она будет надежно генерировать фотореалистичные изображения человеческих лиц. Но что, если кто-то захочет создать лицо с определённой чертой, например, с карими глазами или светлыми волосами?
GLIDE расширяет основную концепцию диффузионных моделей, дополняя процесс обучения дополнительной текстовой информацией, что в конечном итоге приводит к созданию более точных изображений — в этом она превосходит первую версию DALL-E.
GLIDE важен для DALL-E 2, потому что он позволил авторам легко перенести возможности генерации фотореалистичных изображений с текстовым условием. Благодаря этому DALL-E 2 учится генерировать семантически согласованные изображения, обусловленные кодировкой изображения CLIP.
Как всё работает вместе
Таким образом, для генерации текстового изображения нужно собрать вместе следующее:
DALL·E: что мы знаем о молодой и многообещающей нейросети?
С момента релиза DALL·E не раз попадала в топы новостей: нейросеть освоила навыки редактуры изображений, научилась распознавать запросы на русском и даже «сделала» обложку для глянцевого журнала. А недавно разработчики анонсировали еще одно изменение — теперь созданные визуалы можно использовать для коммерческих целей.
Какой путь прошла DALL·E за полтора года — рассказываем и показываем в тексте. Ваши изображения, истории и размышления о будущем дизайна собираем в комментариях.
Ниже вы узнаете:
DALL·E — это нейросеть, которая умеет генерировать изображения по текстовому описанию. Первую версию разработчики из OpenAI представили в 2021 году. Тогда DALL·E создавала картинки, обрабатывая запрос пользователя на английском языке.
Для обучения использовали датасет из пар «текст+изображение» и нейронную сеть в 12 миллиардов параметров.
В ноябре того же года команда разработчиков, включая Лабораторию по искусственному интеллекту Сбербанка, выпустила генератор изображений по запросам на русском языке — ruDALL-E. Сейчас у нее уже несколько модификаций:
В апреле 2022 года OpenAI представила DALL·E 2: качество картинок улучшилось до разрешения 1024х1024 пикселей, сократилось количество искажений и смазанных элементов. Еще нейросеть научилась редактировать уже готовые изображения: изменять композицию, тени и структуру.
Конечно, нейросеть не совершенна. Так, например, пользователи обнаружили, что она не умеет считать. Если ввести запрос «семь красных яблок на стеклянном блюдце», то на картинке будет несколько яблок — но не факт, что именно семь. Также DALL·E 2 теряется, если запросить слишком много деталей.
Ниже попытки одного из пользователей получить изображение по сложному запросу: «маленький темноволосый мальчик, отдыхающий в постели, и седая пожилая женщина, сидящая в кресле рядом с кроватью у окна, сквозь которое льется солнце, диджитал-арт в стиле Pixar».
В официальном сообщении компании о выпуске DALL·E 2 в бету говорится, что пользователи, которые получили доступ к нейросети, теперь могут использовать сгенерированные изображения в коммерческих целях. Чтобы протестировать нейросеть самостоятельно, нужно встать в лист ожидания — и ждать, когда вам повезет. Это бесплатно.
«Начиная с сегодняшнего дня (20 июля 2022 года), пользователи получают полное право на коммерческое использование изображений, созданных ими с помощью DALL·E, включая право на перепечатку, продажу и создание мерча.
Пользователи сообщили нам, что с помощью DALL·E они хотят генерировать иллюстрации для детских книг, визуалы в SMM, игровой концепт-арт, мудборды и раскадровки для фильмов», — отметили разработчики.
К такому ходу уже прибегли в журнале Cosmopolitan. На обложке нового выпуска не было селебрити, заголовков про моду и успех, стильных нарядов. Только подпись: «Встречайте первую в мире обложку журнала, созданную искусственным интеллектом». И примечание ниже: «Это заняло всего 20 секунд».
На фоне новостей о DALL·E 2 пользователи спорят о том, какое будущее ждет дизайн. Да, нейросеть все еще генерирует неидеальные изображения по текстовому запросу, но ее быстрое развитие очевидно. А скорость, с которой готовится визуал, впечатляет.
Разработчики DALL·E 2 говорят, что не претендуют на лавры дизайнеров. На лендинге DALL·E 2 они написали: «Мы надеемся, что DALL·E 2 даст людям возможность творчески самовыражаться. Нейросеть также помогла нам понять, как системы искусственного интеллекта видят и понимают наш мир. Это критически важно для нашей цели по созданию искусственного интеллекта, приносящего пользу человечеству».
Кстати, DALL·E — не единственная нейросеть по генерации изображений.
Креативы, которые генерирует нейросеть Midjourney, впечатляют своей сложностью и оригинальностью. Они больше похожи на произведения искусства, чем на созданную искусственным интеллектом иллюстрацию.
Также есть ИИ This Person Does Not Exist на основе нейросети StyleGAN от Nvidia. Система обработала миллионы портретов и теперь генерирует фото человеческих лиц, основываясь на собирательных образах людей. Это подходящее решение для тех, кто, например, ищет фейковые фото для отзывов или боится нарушить авторские права при использовании реальных фото. Каждый раз, когда вы перезагружаете страницу, ИИ создает новый портрет.
У нейросети есть проблема с украшениями: она почти никогда не делает их одинаковыми и часто «срезает» на иллюстрации, оставляя только половину сережки. Но генерация нового портрета — дело пары секунд.
Еще одна интересная сеть — Colorize. Она раскрашивает черно-белые изображения в реалистичные цвета.
Сможет ли DALL·E и другие нейросети заменить живых дизайнеров, особенно после разрешения коммерциализировать иллюстрации? Давайте обсудим в комментариях.
Подпишитесь на блог Selectel, чтобы не пропустить новые обзоры, новости и кейсы из мира IT и технологий.
Это какие слова нарисованы?
Согласны абсолютно!
Вчера с коллегами смотрели на изображения, сгенерированные Midjourney, и это просто новый уровень дизайна.
Все самое интересное начнется когда нейросеть научится читать сценарии игрового кино
Ну вот вряд ли. Игровое кино сохранит своё место.
Хотелось бы посмотреть фильм, созданный нейросетью
«Зайдите через 5-6 лет»
Русский неофутуризм от midjourney

Подскажите пожалуйста, где можно скачать полноразмерные оригиналы этих картинок?
На мой неискушённый взгляд, весьма неплохо, особенно цвета.
Увы, midjourney генерирует в низком разрешении, так что это оригинал.
Там есть апскейл, но у меня закончились квоты.
Спасибо за подробный ответ мне и выше.
Досадно. Понимаю, что они могут иметь какие-то коммерческие интересы в связи с использованием результатов, но отдавать картинки 256х256 в 2022-м году — это, конечно, нечто.
Не исключаю, что те, кто начнут более-менее щедро делиться сгенерированными изображениями, имеют высокий шанс неплохо взлететь.
Я вам в личку отправил прямые ссылки на эти арты, там можно сделать улучшение разрешения, если нужно. Это бесплатно.
У нейросети бесплатно можно 30 картинок сгенерировать в месяц, дальше платно.
Результат до 3 мп. Это около 1650х1650. Либо 2300х1200 ну и тд.
Хотя вы тоже можете сделать апскейл, если квоты не закончились.
А как ей вообще пользоваться?
1. a) Зайти на сайт midjourney.com b) Join the beta c) Sign in with Discord
2. Зайти в дискорде на midjourney
3. Найти любую комнату, название которой начинается на newbie, нажать на неё
4. В комнате набрать на клавиатуре символ / и выбрать в выпадающем списке imagine, получится окошко в поле сообщения примерно так выглядящее /imagine[prompt ]
5. Написать на английском языке что-то, что вы хотите вообразить, нажать enter
Спасибо. Добавил в закладки
Теперь задача дизайнера будет научиться правильно составлять запрос и использовать полученный результат в дальнейшей работе.
Заказчики все-равно это делать сами не будут.
А зачем дизайнеру использовать этот результат? У дизайнера есть свое воображение, насмотренность, вдохновение, знание трендов и всякое такое.
А тут еще неясно, какая будет лицензия для коммерческого использования.