Grafana что это
Grafana что это
Введение в мониторинг серверов с помощью Prometheus и Grafana

Мониторинг нужен всем: и серверам крупных технологических компаний и домашним Raspberry PI. Мониторинг позволяет узнать, когда сервер выходит из строя, когда заканчивается дисковое пространство и даже когда подходит время апгрейда.
В этой статье рассмотрим настройку базового мониторинга с помощью Prometheus, Node Exporter и Grafana.
Обзор решения
Основной компонент — Prometheus. Prometheus получает метрики из разных сервисов и собирает их в одном месте.
Node exporter — небольшое приложение, собирающее метрики операционной системы и предоставляющее к ним доступ по HTTP. Prometheus собирает данные с одного или нескольких экземпляров Node Exporter.
Grafana — это вишенка на торте. Grafana отображает данные из Prometheus в виде графиков и диаграмм, организованных в дашборды.
Примечание — в этом руководстве используется Ubuntu, но все эти инструменты поддерживаются и другими дистрибутивами Linux и даже Windows.
Приступаем к работе
Node Exporter
Первый шаг — установка Node Exporter. Его можно найти на github по ссылке ниже. На момент написания статьи последняя версия 0.18.1.
Node Exporter распространяется в виде одного бинарного файла, который можно запустить из любого места в системе. Так что установка довольно проста. После запуска переходим в браузере по адресу » :9100/metrics» и смотрим собираемые метрики.

Prometheus
Второй шаг — установка Prometheus и его настройка на сбор данных с установленного ранее Node Exporter. Ссылка на github ниже. На момент написания статьи последняя версия 2.13.1.
Установка Prometheus немного сложнее, но все же достаточно проста. Как и Node Exporter, это один бинарный файл, но дополнительно требуется файл конфигурации и папка для хранения данных.
Для настройки Prometheus на сбор метрик из ранее установленного экземпляра Node Exporter необходимо изменить файл конфигурации. Добавим в раздел static_configs еще один URL:
Здесь мы настроили Prometheus на сбор метрик из двух сервисов: самого себя (localhost:9090) и локального экземпляра Node Exporter (localhost:9100).
После запуска Prometheus можно открыть его пользовательский интерфейс в браузере » :9090″. На странице «/targets» отображается статус систем, с которых вы получаете метрики. Если все хорошо, то в колонке статуса (State) будет “UP”.

Уже используя только Prometheus, можно делать запросы к собранным данным, и строить графики с помощью инструментов на странице «/graph». Это хороший инструмент для изучения собираемых метрик и написания сложных запросов к данным. Но мы возложим эту работу на Grafana.
Grafana
Grafana — последний компонент нашего решения. Ее задача — подключиться к Prometheus и отобразить собранные метрики на графиках и дашбордах. Grafana взаимодействует только с Prometheus, так как все собираемые метрики хранятся там.
Grafana вы также можете найти на github:
Однако, установка Grafana еще несколько сложнее, чем Prometheus и Node Exporter, но, к счастью, на сайте Grafana есть отличная документация. Для Ubuntu все просто: скачайте deb-пакет и установите его:
После завершения установки перейдите в браузере по адресу » :3000″. Пользователь и пароль по умолчанию «admin»/»admin». При первом входе пароль необходимо будет изменить.
Настройка Grafana
После установки всех компонент можно приступить к настройке Grafana.
Источник данных (datasource)
Первый шаг — настройка источника данных (datasource). По сути, это источник метрик для Grafana. Мы будем получать метрики с нашего сервера Prometheus, поэтому в качестве источника данных выбираем Prometheus и указываем URL http://localhost:9090. Остальные параметры оставляем по умолчанию.

Стоит отметить, что помимо Prometheus, Grafana может запрашивать и обрабатывать данные из множества других систем.
Дашборд (dashboard)
После настройки Datasource, мы можем создать дашборд. Дашборд — это просто набор панелей, расположенных на одной странице. Панели бывают разные: от простого текста до круговых диаграмм. Каждую панель можно настроить для отображения различных метрик.
Создание своего дашборда с нуля может быть нелегкой задачей. К счастью, Grafana предоставляет простой способ импорта дашбордов, созданных другими пользователями. После импорта дашборд можно настроить в соответствии с вашими потребностями.
Для примера я буду использовать готовый дашборд, созданный «cordobatyc» и расположенный по следующей ссылке:

Чтобы установить дашборд, укажите его ID на странице Import.
После импорта откройте установленный дашборд с помощью выпадающего списка в левом верхнем углу. При первом открытии он выглядит следующим образом.

Плагины
Хотя плагины не являются обязательными, но наш дашборд содержит панель, которая использует сторонний плагин, отсутствующий по умолчанию. Эту панель можно удалить (возможно, заменив ее чем-то другим), либо установить недостающий плагин.
Необходимый нам плагин предназначен для отображения круговых диаграмм. Его можно найти по ссылке ниже.
Установка плагина описана на его странице. Откройте командную строку и выполните следующую команду:
Для завершения установки плагина перезапустите Grafana:
Далее можно обновить страницу — панель с круговой диаграммой должна отображаться правильно.
Заключение
После установки всех компонент и настройки Grafana у вас должно получиться что-то вроде этого:

Взглянув на эту страницу, вы можете получить информацию о состоянии сервера: начиная с того, как долго он работает, заканчивая загрузкой процессора и использованием памяти.
Это руководство лишь введение в мониторинг. С рассмотренными инструментами вы сможете сделать гораздо больше, включая настройку автоматических алертов при достижении метриками определенных пороговых значений. Теперь у вас есть основа для настройки и запуска базового мониторинга.
Для более глубокого изучения этой темы я рекомендую обратиться к документации Prometheus и Grafana.
Ресурсы
Всех желающих приглашаем на открытый урок «Системы логирования (ELK, EFK, Graylog2)» в OTUS, который состоится 21 февраля. На уроке сравним различные системы логирования, присутствующих на рынке: ELK, EFK — fluentd, Graylog2.
Grafana — удобный дашборд для метрик

Graphana — первый действительно хороший дашборд для отображения метрик.
Уважаемые коллеги, хочу поделиться с вами такой интересной находкой как open-source проект Graphana
Graphana предназначена для отображения всевозможных циклических метрик. Помимо предопределенных системных метрик (CPU, IO, etc..), можно сконфигурировать любой набор произвольных метрик — онлайн, профит и т.д. Graphana имеет две встроенных темы оформления — обе выглядят очень хорошо. Можно создать любое количество произвольных дашбордов.
Видео, которое кратко показывает возможности данного ПО: www.youtube.com/watch?v=OUvJamHeMpw
Данный проект разрабатывает шведский парень по имени Торкель.
Признаюсь честно, перепробовав все доступные дашборды и найдя Graphana, я тоже верю, что у него все получится.
Grafana — все, что вам нужно знать

Как компания по разработке программного обеспечения с богатой историей работы над коммерческим и бесплатным программным обеспечением, SCAND была активным сторонником и участником сообщества Open Source. Часть нашей работы была посвящена ядру инструмента визуализации данных Grafana.
Наша команда работала над проектом, который требовал создания списков сопоставлений, которые помогают преобразовывать идентификаторы в удобные для пользователя тексты и наоборот. Эта функция была очень востребована сообществом этого инструмента для создания графиков и таблиц, а также нашим клиентом. Коммит был разработан нашей командой и добавлен в систему 5 марта 2018 года.
Grafana — это многоплатформенная платформа для аналитики и интерактивной визуализации с открытым исходным кодом. Он предназначен для предоставления контекстно-насыщенной визуализации, в основном с помощью графиков, но он также поддерживает другие методы представления данных благодаря своей архитектуре подключаемых панелей. Каждая панель управления адаптируется и настраивается в соответствии с потребностями конкретного проекта разработки программного обеспечения. Одна из причин популярности Grafana среди разработчиков — ее элегантные дашборды. Визуализации называются панелями, и разработчики могут создавать собственные информационные панели с панелями для различных источников данных. Он поддерживает тепловые карты, графики, таблицы и типы панелей с произвольным текстом. Разработчики также могут получить доступ к хорошо зарекомендовавшей себя экосистеме пользовательских информационных панелей для различных типов информации и источников.

Что такое Grafana Tool: особенности и преимущества
Даже малые предприятия генерируют огромные объемы данных в 2021 году, что делает инструменты для отслеживания и анализа больших данных важной частью любого рабочего процесса. Grafana — эффективное решение, потому что оно простое в использовании, предоставляет красивые графики и может быть интегрировано с рядом баз данных, включая MySQL, Graphite, Influx DB, Logz.io, Influx DB, ElasticSearch и PostgreSQL. Тот факт, что это открытый исходный код, также означает, что разработчики могут создавать собственные плагины для удовлетворения своих конкретных потребностей.
Grafana — отличный инструмент для визуализации данных. Доступность и наблюдаемость для всех пользователей обеспечивается за счет упрощенной установки и настройки. Все пользователи могут найти приложение для отслеживания производительности удовлетворительным благодаря привлекательному и настраиваемому интерфейсу.

Панель управления хорошо оснащена для понимания сложных данных, таких как графики, тепловые карты, гистограммы и географические карты, и она постоянно обновляется. Инструмент предоставляет множество решений визуализации для понимания данных в соответствии с бизнес-потребностями конкретного проекта. Вот ключевые особенности Grafana, которые вам следует знать:

Преимущества Grafana включают:
Grafana Cloud — это открытая платформа метрик SaaS, которая является облачной, быстрой и высокодоступной. Это особенно полезно для тех, кто не хочет беспокоиться об управлении всей инфраструктурой развертывания и не хочет брать на себя бремя размещения решения локально. Он работает на кластерах Kubernetes. Серверная часть совместима с Prometheus и Graphite. В результате у вас есть выбор: использовать экземпляр облака Grafana или и то, и другое.
Grafana также предлагает Grafana Enterprise, разработанную для крупных предприятий со сложными потребностями в визуализации данных. Grafana Enterprise обеспечивает обслуживание клиентов и обучение под руководством своей команды разработчиков.
Почему компании используют Grafana?
Компании, использующие инструменты анализа баз данных и визуализации, такие как Grafana, намного эффективнее своих конкурентов. Grafana используется предприятиями для отслеживания своей инфраструктуры и ведения журналов аналитики, а также для улучшения операционных показателей. Панели управления Grafana упрощают мониторинг пользователей и событий за счет автоматизации сбора, управления и отображения данных. Эта информация может использоваться менеджерами по продуктам, аналитиками безопасности и разработчиками для принятия решений.
Он показывает командам и компаниям, что на самом деле делают их клиенты, а не только то, что они утверждают. Известно, что это открытое поведение, и оно чрезвычайно информативно. Пользователи не очень хорошо умеют предвидеть свое будущее, но наличие аналитики помогает техническим командам копать глубже, чем опросы и отслеживание, подверженные человеческим ошибкам.
Завершение
Grafana позволяет предприятиям полностью понять, почему и как пользователи или события связаны с их инфраструктурой или сетью. Это особенно полезно для групп аналитики безопасности, поскольку позволяет им шаг за шагом отслеживать события и цифровые следы пользователей, чтобы узнать, чем они занимаются в своей сети. Поскольку большинство приложений и веб-сайтов не созданы для предоставления исчерпывающих отчетов или визуализаций, аналитика является важной частью современных технологий SecOps и DevOps как услуги. Данные, которые они получают, часто неточны и плохо структурированы без адекватной визуализации. Grafana снова делает данные полезными, объединяя все источники данных в единое, хорошо организованное представление.
Мониторинг вашей инфраструктуры с помощью Grafana, InfluxDB и CollectD
У компаний, которым необходимо управлять данными и приложениями на более чем одном сервере, во главу угла поставлена инфраструктура.
Для каждой компании значимой частью рабочего процесса является мониторинг инфраструктурных узлов, особенно при отсутствии прямого доступа для решения возникающих проблем. Более того, интенсивное использование некоторых ресурсов может быть индикатором неисправностей и перегрузок инфраструктуры. Однако мониторинг может использоваться не только для профилактики, но и для оценки возможных последствий использования нового ПО в продакшне. Сейчас для отслеживания потребляемых ресурсов на рынке существует несколько готовых к использованию решений, но с ними, тем не менее, возникают две ключевые проблемы: дороговизна установки и настройки и связанные со сторонним ПО вопросы безопасности.
Первая проблема это вопрос цены: стоимость может варьироваться от десяти евро (потребительские расценки) до нескольких тысяч (корпоративные расценки) в месяц, в зависимости от числа подлежащих мониторингу хостов. Для примера, предположим что мне нужен мониторинг трех узлов в течение одного года. При цене в 10 евро в месяц я потрачу 120 евро, тогда как небольшая компания будет вынуждена раскошелиться на десять-двадцать тысяч, что окажется финансово несостоятельным решением и попросту подорвет весь бюджет.
Вторая проблема это стороннее ПО. Учитывая, что для анализа данные пользователя — будь то частное лицо или компания — должны обрабатываться третьей стороной, возникает вопрос: каким образом третья сторона собирает данные и представляет их пользователю? Обычно для этого на узел устанавливают специальное приложение, через которое и ведется мониторинг, но зачастую такие приложения успевают устареть или оказываются несовместимы с операционной системой клиента. Опыт исследователей в области информационной безопасности проливает свет на проблемы в работе с «проприетарным ПО». Стали бы вы доверять такому ПО? Я — нет.
У меня есть свои узлы как для Tor, так и для некоторых криптовалют, поэтому для мониторинга я предпочитаю бесплатные, легко настраиваемые альтернативы с открытыми исходниками. В этом посте мы рассмотрим три таких инструмента: Grafana, InfluxBD и CollectD.

Мониторинг
Для эффективного анализа каждой метрики нашей инфраструктуры нужно приложение, способное подхватывать статистику с интересующих нас устройств. В этом отношении нам на помощь приходит CollectD: этот демон группирует и собирает («collects», потому и такое имя) все параметры, которые можно хранить на диске или передать по сети.
Данные затем будут переданы инстансу InfluxDB: это база данных временных рядов (time series database, TSBD), которая связывает данные со временем (закодированным в UNIX временную метку) в которое их получил сервер. Таким образом, отправленные CollectD данные поступят уже как последовательность событий.
Наконец, мы воспользуемся Grafana: эта программа свяжется с InfluxDB и отобразит данные на удобных для пользователя цветастых приборных панелях. Благодаря всевозможным графикам и гистограммам мы сможем в реальном времени отслеживать данные CPU, оперативной памяти и так далее.

InfluxDB

Давайте начнем с InfluxDB, свободно распространяемой TSBD для хранения данных в виде последовательности событий. Эта разработанная на Go база данных станет сердцем нашей мониторинговой «системы».
Всякий раз при поступлении данных к ним по умолчанию привязывается UNIX метка. Гибкость такого подхода освобождает пользователя от необходимости хранить переменную «time», что в противном случае оказывается довольно сложным. Давайте представим, что у нас есть несколько расположенных на разных материках устройств. Каким образом мы будем обрабатывать переменную «time»? Станем ли мы привязывать все данные ко времени по Гринвичу, или мы зададим каждому узлу свой часовой пояс? Если данные сохраняются в разных часовых поясах, каким образом нам корректно отобразить их на графиках? Как можно видеть, проблемы возникают одна за другой.
Так как InfluxDB отслеживает время и автоматически проставляет метки на каждое поступление данных, она может синхронно записывать данные в конкретную базу данных. Именно поэтому InfluxDB часто представляют в виде таймлайна: запись данных не влияет на производительность базы данных (что порой случается у MySQL), поскольку запись это всего лишь добавление конкретного события в таймлайн. Поэтому название программы происходит от восприятия времени как бесконечного и неограниченного «потока».
Установка и настройка
Еще одно преимущество InfluxDB заключается в простоте установки и предоставляемой сообществом проекта, которое его широко поддерживает, объемной документации. У InfluxDB есть два типа интерфейса: командная строка (удобный инструмент для разработчиков, но плохо подготовлена к работе с большими объемами данных) и HTTP API для прямого взаимодействия с базой данных.
Скачать InfluxDB можно не только с официального сайта, но и через систему управления пакетами (мы продемонстрируем это через Debian). Кроме того, перед установкой рекомендуется проверить пакеты через GPG, поэтому ниже мы импортируем ключи пакета InfluxDB:
Наконец, мы обновим и установим InfluxDB:
Для запуска мы воспользуемся systemctl :
В том же CLI интерфейсе мы создадим базу данных «metrics», в которой и будем хранить наши метрики.
Затем мы настроим конфигурацию InfluxBD ( /etc/influxdb/influxdb.conf ) таким образом, чтобы интерфейс открывался через порт 24589 (UDP) с прямым соединением к базе данных «metrics» для поддержки CollectD. Также нам надо будет скачать файл types.db и поместить его по адресу /usr/share/collectd/ (или в любую другую папку) для корректного определения данных, которые CollectD передает в родном формате.
Больше про CollectD в конфигурации можно прочесть в документации.
CollectD

CollectD в нашей мониторинговой инфраструктуре будет исполнять роль агрегатора данных, который упрощает передау данных до InfluxDB. По определению CollectD собирает метрики с CPU, оперативной памяти, жестких дисков, сетевых интерфейсов, процессов… Потенциал этой программы безграничен, особенно если учесть широкий выбор как уже доступных плагинов, так и набор запланированных.
Как можно видеть, установка CollectD проста:
Давайте проиллюстрируем работу CollectD упрощенным примером. Допустим, я хочу знать число процессов на моем узле. Для проверки этого CollectD совершит вызов API чтобы узнать число процессов за единицу времени (по определению это 5000 миллисекунд) и ничего более. Как только агрегатор получит данные, он передаст их для настройки в InfluxDB через модуль (под названием «Network»), который нам надо будет настроить.
Я предлагаю изменить в файле конфигурации имя хоста, который пересылается InfluxDB (в нашей инфраструктуре это «централизованная» база данных, поскольку она расположена на одном узле). Таким образом, к нам не будут поступать лишние данные и исчезнет риск перезаписи данных другими узлами.

Grafana

Один график стоит тысячи изображений
Беря во внимание перефразированную цитату, наблюдение за метриками инфраструктуры в режиме реального времени через графики и таблицы дает нам действовать эффективно и своевременно. Для создания и настройки приборной панели наших графиков и таблиц мы воспользуемся Grafana.
Grafana это совместимый с широким набором баз данных (включая InfluxDB) свободно распространяемый инструмент по графическому отображению метрик, в котором пользователь может создавать оповещения об удовлетворении частью данных конкретного условия. Например, если ваш процессор достигает пиковых значений, оповещение может прийти вам в Slack, Mattermost, на почту и так далее. Более того, свои оповещения я настроил так, чтобы активно отслеживать каждый случай, когда кто-то «заходит» в мою инфраструктуру.
Grafana не требует каких-то особых настроек: как мы уже отметили ранее, InfluxDB «сканирует» переменную «time». Сама же интеграция очень проста: мы начнем с импорта публичного ключа чтобы добавить пакет с официального сайта Grafana (он зависит от вашей операционной системы):
Затем запустим его через systemctl:
Теперь, когда мы перейдем в браузере на страницу localhost:3000, мы должны будем увидеть интерфейс входа в Grafana. По определению, зайти можно через логин admin и пароль admin (после первого входа учетные данные рекомендуется сменить).

Давайте перейдем в раздел Sources (Источники) и добавим туда нашу базу данных Influx:


Теперь под надписью New Dashboard виднеется небольшой зеленый прямоугольник. Наведите на него свой курсор и выберите Add Panel (Добавить Панель), а затем Graph (График):

Теперь можно увидеть график с тестовыми данными. Нажмите на заголовок этой диаграммы и нажмите Edit(Изменить). С Grafana можно создавать умные запросы: вам не нужно знать каждое поле в базе, Grafana предложит их вам из списка подходящих для анализа параметров.
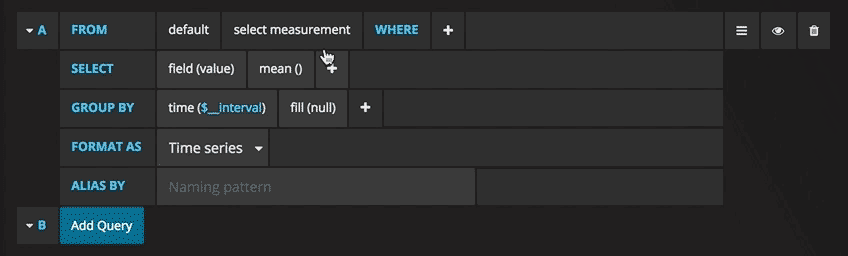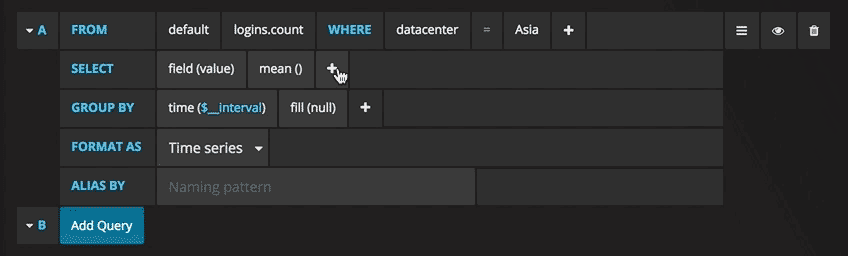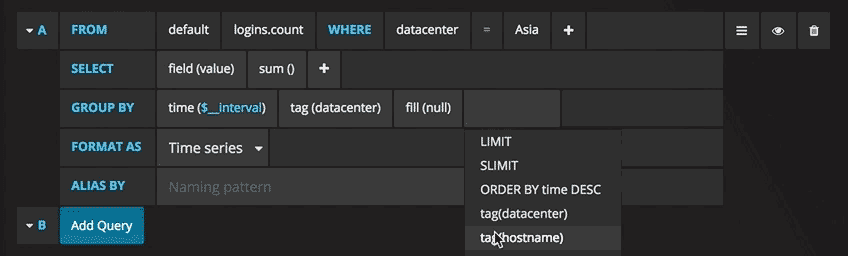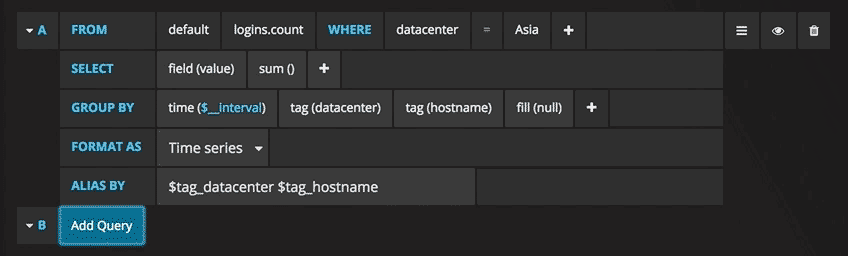
Писать запросы еще никогда не было так легко: просто выберите интересующую вас метрику и нажмите Refresh (Обновить). Еще я рекомендую разделить метрики по хостам, чтобы было проще изолировать проблемы. Если вам интересны другие идеи по созданию контрольных панелей, для вдохновения можно посетить сайт Grafana со всевозможными примерами.
Мы заметили, что Grafana это очень легко расширяемый инструмент, и он позволяет нам сравнивать очень разные по сравнению друг с другом данные. Нет ни одной метрики, которую нельзя было бы заполучить, так что вас ограничивает только ваша же изобретательность. Отслеживайте ваши устройства и получайте самый полный обзор вашей инфраструктуры в реальном времени!
Grafana и автотесты: учимся измерять работу тестов
Управление — трудоёмкая работа, которая усложняется при отсутствии подходящего инструмента. Легко упустить из виду постоянно меняющиеся компоненты и сложно быть в курсе событий: что-то обязательно проходит незамеченным.
На примерах наших тестов покажу, как Grafana помогает в анализе результатов автотестирования, чтобы точнее понимать, что происходит.

Наш контекст
Про сайт Ozon.ru
Сайт написан на TypeScript (Vue) и представляет собой монолитный репозиторий. Каждую страницу сайта делает отдельная команда (в нашей терминологии — «вертикаль»). Она отвечает за фронтенд, бэкенд, дизайн, аналитику и остальное необходимое для функционирования страницы.
Выпускаем до десяти релизов сайта в день, которые нужно быстро тестировать. В этом нам помогает WebdriverIO, а для запуска тестов используем Moon.
Автоматические тесты для сайта

Во время релиза мы прогоняем все критичные тесты, а также тесты той вертикали, чья страница релизится. Кроме того, мы регулярно прогоняем все тесты по расписанию, чтобы дополнительно отслеживать работу продакшен- и стейджинг-сред.
Кстати, подробнее про это я уже рассказывал в статье «Автоматическое тестирование аналитики в браузере».
Тестирование в продакшене
Здесь важно сделать отступление. На самом деле, тестирование в продакшене — это тема для отдельной статьи. Скажу, что мы не стесняемся использовать продакшен-среду для тестирования, — считаем, что чем ближе к пользователю, тем вернее, точнее, честнее проверки.
Мы используем blue-green деплой для проверки релизов: сервис выкладывается в прод, тестируется, и только потом пускается трафик пользователей. Никаких лишних действий после тестирования не происходит: протестировали — сразу пускается трафик.
Мы мониторим тестами продакшен: делаем это не ради перестраховки или дублирования мониторинга, а потому что, кроме релизов, вносятся изменения в конфигурации, в админки и в шаблоны страниц.
Проблемы при тестировании
Итак, возвращаемся к проблеме, которую я упомянул во вступлении.
Решение
Чтобы преодолеть эти трудности, нужно научиться измерять работу тестов. В этом помогает Grafana — инструмент, которым пользуются разработчики, девопсы, аналитики, продакт-менеджеры. Grafana отображает графики и результаты аналитики.
Как технически организовать сбор метрик
В Ozon уже создана инфраструктура для сбора всевозможных метрик: сейчас в эксплуатации больше 10 000 экземпляров сервисов, с которых мы каждую секунду собираем около миллиона уникальных метрик для бессрочного хранения. Тестировщики быстро втянулись и начали использовать эту инфраструктуру.
Всё, что нам нужно было сделать, — поднять пушгейтвей для Prometheus и подобрать библиотеку для отправки метрик. На официальном GitHub Prometheus можно подобрать библиотеку для любого языка.
После выполнения каждого теста добавляем хук, который отправляет метрики с его результатами:

Внутри каждой джобы с метрикой отображаются длительность теста, ошибка (если есть), результат и метки.

Из Grafana можно отправлять запросы в Prometheus. Для этого применяется специальный язык PromQL. Он оперирует векторами из меток, которые мы заполнили ранее:
В этом запросе возвращаем результаты критичных тестов, выполненных в Chrome.
Что мы измеряем
1. Результаты
В первую очередь хотим знать, успешно ли пройдены тесты. Изначально у нас было не много тестов и они были довольно простыми. Вот пример работы плагина-визуализатора Statusmap:

Здесь приведены названия тестов и шкала, на которой в режиме реального времени отображается их статус. На иллюстрации всё зелёное, потому что выбран ночной интервал, когда пользователей мало, сервисы никто не шатает, никто ничего не релизит.
Когда тестов стало больше, такая визуализация перестала нас устраивать. Мы начали группировать тесты по вертикалям и усреднять результаты. Графики получались уже не дискретные, а градиентные: чем больше красного цвета, тем больше тестов упало. А чтобы понять, какие именно тесты упали, можно перейти в Allure, данные которого хранятся у нас в отдельном сервисе.

Ещё можно строить полезные графики по разным срезам. Например, мы тестируем различные браузеры — IE, Safari, Edge, Firefox, Opera — и усреднённые результаты выглядят так:

Такую визуализацию можно получить и по иным признакам, например по платформам.
Так выглядит график результатов тестирования по вертикалям в период с 17 до 23 часов:

Каждый прямоугольник соответствует интервалу в пять минут. Вертикальные голубые линии — это отметки релизов. Как видите, у двух команд в течение часа что-то шло не так. Обычно мы действуем так: если после релиза тесты красные, то сразу откатываемся и ищем причину проблемы. Бывает и так, что на графиках долго сохраняется красный цвет. Это говорит о поломке либо тестов, либо среды, либо приложения.

В таких ситуациях можно настроить оповещения по PromQL-векторам. Например, у нас они рассылаются, если тест не работает на проде больше четырёх часов. В стейджинг-среде задан порог в 12 часов.
2. Ошибки
Иногда тесты краснеют — и нужно понять, в чём дело. Особенно руководству.


Ошибки в qaapi: Item говорят о падении на этапе подготовки тестовых данных, ошибки в wdio: Timeout — о проблеме с тайм-аутами (надо разбираться в Selenium).
3. Запуски
Мы запускаем тесты часто и плотно. Интервалы между запусками тестов из одного набора — от шести до 15 минут. Запусков много, и нужно уметь их контролировать.

Тестируем примерно с 7 утра до 12 ночи. На графике много всплесков, и если кликнуть по одному из значений, то можно увидеть подробную статистику запусков тестов для одной из страниц сайта. Зачем отслеживать этот вид метрик? Контролируя запуски, можно не только проверять расписание тестирования в командах, но и вылавливать возможные ошибки. Приведу пару примеров.
Здесь сразу видно, что одну страницу тестировали слишком часто (каждую минуту). Это пустая трата ресурсов.

А здесь видно, как у одной команды из-за ошибки в приложении часть тестов прогонялась однократно, а часть — повторялась.

4. Длительность
Время — самый ценный ресурс. Поскольку мы делаем релизы до десяти раз в день, тесты должны быть быстрыми: каждый — не дольше 30 секунд, а весь набор — не дольше пяти минут. Метрика test duration позволяет контролировать деградацию в приложении, в тестах или инфраструктуре. Делать это можно с помощью такого графика:

Здесь показана средняя продолжительность тестов по командам. Одна команда выделяется — видимо, есть какие-то проблемы в приложении, либо тесты написаны неоптимально.
Тесты могут выполняться слишком долго и из-за проблем с инфраструктурой. Когда мы разворачивали Moon, по этому графику мы отслеживали деградацию:

5. Нестабильные (flaky) тесты
Нестабильные тесты — боль и проблема тестировщика. Есть много способов борьбы с ними. Но для начала нужно их выявить. В этом помогает такой запрос:
Здесь вычисляется сумма изменений результатов тестов в течение шести часов. Если тест мигает один раз, то значение будет 2. Если мигает один раз в час, то за шесть часов будет 12.

Мигание раз в час для нас допустимо, но, если частота увеличивается, такой тест мы считаем нестабильным, помечаем красным и начинаем разбираться.
6. Покрытие
С сайта в наши аналитические системы постоянно идёт поток данных о действиях пользователей на разных страницах. Каждая страница состоит из нескольких десятков блоков — виджетов. Если пользователю показали виджет, отправляется событие view; если пользователь нажал на что-то — событие click.
Из аналитических систем можно запрашивать данные для Grafana и строить таблички.

Собираем всё вместе
Так выглядит дашборд со всеми описанными графиками по одной из вертикалей:

Здесь отображаются результаты тестов, ошибки, нестабильность, длительность, запуски и покрытие. Видно, что тесты прогоняются штатно, основные виджеты покрыты, длительность и количество запусков хорошие. Ошибок не много. В таблице нестабильных тестов нет красного цвета. Можно считать, что у этой команды всё работает как надо.

Есть пробелы в покрытии, много ошибок с тайм-аутами, пара совсем нестабильных тестов. Любой тестировщик и тимлид этой вертикали может сразу увидеть, чем необходимо заняться.
Grafana как еще один инструмент для технического мониторинга создаваемых нами программных продуктов
Очередная статья в серии «Инструменты мониторинга Logicify» рассказывает о Grafana. Это программное средство мы используем для визуализации и анализа данных как внутренних, так и внешних проектов. Статья может быть полезна техническим директорам, разработчикам, DevOps, системным администраторам, менеджерам проектов, а также всем заинтересованным лицам.

Что такое Grafana?
Grafana — это платформа с открытым исходным кодом для визуализации, мониторинга и анализа данных. Этот инструмент, в сочетании с Graylog, — часть нашей двухсторонней системы мониторинга поведения пользователей и производительности системы. Grafana позволяет пользователям создавать дашборды с панелями, каждая из которых отображает определенные показатели в течение установленного периода времени. Каждый дашборд универсален, поэтому его можно настроить для конкретного проекта или с учетом любых потребностей разработки и/или бизнеса.
Наша команда Logicify в основном использует Grafana в сочетании с Elasticsearch и InfluxDB, но это программное средство поддерживает множество других источников данных (Prometheus, MySQL, Postgres и т. д.). Для каждого источника данных в Grafana предусмотрен настраиваемый редактор запросов и специальный синтаксис.
Термины Grafana
Передовые методы использования инструмента Grafana командой Logicify
Использование Grafana во внутренних проектах
Для своего внутреннего проекта «Интернет вещей» (решение для мониторинга микроклимата в офисе) мы подключили Grafana к InfluxDB, базе данных временных рядов, чтобы визуализировать изменения параметров микроклимата в офисе и реагировать на них соответствующим образом. Набор датчиков измеряет температуру, влажность, атмосферное давление и уровень CO2 в каждой зоне нашего офиса в Херсоне; эти параметры собираются и визуализируются в виде графиков Grafana на большом кухонном мониторе и в режиме онлайн.

Дашборд Grafana с офисными зонами Logicify
Так мы постоянно отслеживаем параметры качества воздуха, и наш офис-менеджер реагирует на изменения: открывает окна, если уровень CO2 слишком высок, включает и выключает кондиционер и увлажнители воздуха.

Дашборд Grafana с параметрами микроклимата в офисах
Благодаря графикам и аннотациям временных рядов, отображаемым в Grafana, мы анализировали тенденции изменения микроклимата в офисах в течение несколько месяцев и времен года. Мы также использовали данный инструмент для визуализации некоторых полезных виджетов и сведений (прогноз погоды, курсы обмена валют, внутренние календари) на большом кухонном мониторе.
Как использовать Grafana в настраиваемых веб-приложениях
Grafana + Graylog
Мы используем инструмент Graylog для хранения журналов веб-приложений, управления ими и мониторинга их производительности как на этапе разработки, так и на этапе их эксплуатации. Grafana — это инструмент, который преобразует журналы, хранящиеся в Graylog, в визуальные формы для аналитического и системного мониторинга. Для одного из наших текущих проектов инструмент Grafana можно условно назвать пользовательским интерфейсом для загрузки и мониторинга производительности веб-приложений и потока клиентов. Инструменты Graylog и Grafana существуют независимо друг от друга, мы не создавали никаких специальных сложных средств интеграции для подключения их друг к другу. Поскольку Graylog хранит все данные журнала в Elasticsearch, одном из источников данных Grafana, мы просто используем определенный индекс Elasticsearch, где хранятся журналы, для подключения Grafana к Graylog.
Какие показатели можно визуализировать в Grafana для веб-приложения
Журналы с простым текстом или уведомления об ошибках не «интересны» инструменту Grafana, поскольку его основная цель — визуализировать данные в виде графиков, диаграмм и таблиц. Мы написали пользовательский модуль для Django для сбора данных, которые мы хотели бы отслеживать по каждому обработанному запросу и отклику сети/работника. Данные включали в себя не только статус «успех»/«неудача», но и набор структурированных полей (как общего характера, так и относящихся к проекту), как то:
Django помещает пользовательские структурированные аналитические записи в Graylog, который сохраняет их в отдельном потоке. Хотя эти данные можно визуализировать с помощью встроенных дашбордов Graylog, они не так хорошо выглядят, как дашборды Grafana. Поэтому мы заставляем Grafana считывать эти аналитические данные и визуализировать их. Таким образом, мы отслеживаем производительность приложения и загружаем данные как в режиме реального времени, так и в ретроспективе.

Grafana как инструмент отладки
Дашборды Grafana главным образом помогают нам в отладке приложений. Если конечный клиент сообщает о проблеме, Grafana дает нам возможность отличить ошибки на стороне клиента/сервера от реальных ошибок или брешей в логике приложения. Мы отслеживаем все веб-запросы, инициированные клиентом (используя адрес электронной почты), администраторами приложений и самим приложением в течение заданного периода времени и методом исключения находим причину.
Мы также проводим отладку и исправляем ошибки, если замечаем на дашборде аномалию в графиках загрузки и производительности приложения. Следующий пример графика Grafana показывает время отклика на веб-запросы в течение определенного периода времени. Для каждого веб-запроса мы отслеживаем максимальное, минимальное и среднее время отклика. Если видим запрос, на обработку которого у нас ушло слишком много времени, масштабируем определенную часть графика и исследуем проблему.

Пример графика Grafana, отображающего время отклика на веб-запросы
Другой график показывает загрузку системы в течение установленного периода времени и полезен для отслеживания трафика. Если мы видим необычный всплеск активности, например, в нерабочее время или в выходные дни, мы исследуем его. Такой всплеск может быть вызван, например, сканерами Google, индексирующими контент веб-сайта, или вредоносными ботами, сканирующими нашу систему на наличие уязвимостей. Опять-таки, каждый случай исследуется и рассматривается соответствующим образом.

Пример графика Grafana, отображающего загрузку приложения
Grafana имеет встроенный механизм оповещения (например, по электронной почте или с помощью уведомлений через Slack) согласно определенным правилам. Мы не используем эту возможность инструмента Grafana, поскольку у нас все уведомления настроены в Graylog. Однако некоторые проблемы с производительностью системы можно увидеть только после прогона программы, например, необычно долгое время отклика на веб-запрос. Мы не получим уведомления Graylog об этом, но аномалия будет четко видна на графике Grafana. Итак, оба инструмента дополняют друг друга, когда мы узнаем о какой-то проблеме: на высоком уровне мы проверяем Grafana, чтобы понять, что произошло и почему, а затем копаем глубже с помощью Graylog, используя конкретный идентификатор запроса.
В отличие от Graylog, используемого как для разрабатываемых, так и для используемых приложений, Grafana применяется только для используемых приложений. Единственным исключением, когда Grafana используется для приложения, которое все еще на этапе разработки, является тестирование производительности. Мы эмулируем загрузку системы с помощью JMeter, затем проверяем дашборды Grafana, чтобы увидеть, как она реагирует.
Grafana как инструмент бизнес-аналитики
Помимо целей отслеживания производительности и отладки, дашборды Grafana являются мощным инструментом для принятия обоснованных бизнес-решений. При правильной настройке (желательно в тандеме с сервисом Google Analytics) Grafana может визуализировать настраиваемую аналитику поведения пользователя в системе в виде круговых диаграмм, гистограмм времени и других графических элементов. На их основе стороны, заинтересованные в продукте, могут принимать решения о дальнейшем масштабировании приложения, добавлении или удалении некоторых функций и улучшении цикла взаимодействия с клиентами.

Пример дашборда Grafana, отображающего поведение пользователя в приложении для электронной коммерции
Поскольку вышеприведенный дашборд ориентирован в большей мере на бизнес, разработчики используют его для внутренних целей, скорее, как инструмент обеспечения, чтобы отслеживать поток клиентов в приложении для электронной коммерции: регистрации, авторизации, заказы, размещенные в течение заданного периода времени.
Вот 2 реальных проекта, где с помощью Grafana удалось повысить удобство использования веб-приложения.
Grafana является важным компонентом системы мониторинга команды Logicify как для внутренних, так и для внешних проектов. У этого программного средства открытый исходный код, плюс большое и активное сообщество разработчиков. Но больше всего нам нравится гибкость — оно поддерживает множество источников данных и позволяет легко настраивать дашборды и панели.
Grafana что это
Query, visualize, and alert on data

Monitor Kubernetes and cloud native

Multi-tenant log aggregation system
Scalable and performant metrics backend

High-scale distributed tracing backend

Scalable monitoring for timeseries data
Load testing for engineering teams

Instrument and collect telemetry data
Stay Up To Date
Our biggest community event of the year
News, releases, cool stories, and more
Upcoming in-person and virtual events
By use case, product, and industry
Webinars and videos
Demos, webinars, and feature tours
Hands-on, self-paced courses
Join The Community
Ask the community for help
Help build the future of open source observability software Open positions
Check out the open source projects we support Downloads
with Mimir, Prometheus,
and Graphite
Our biggest community event of the year
News, releases, cool stories, and more
Upcoming in-person and virtual events
By use case, product, and industry
Webinars and videos
Demos, webinars, and feature tours
Hands-on, self-paced courses
Ask the community for help
The Grafana Stack
with Mimir, Prometheus,
and Graphite
Other cool stuff
Free Forever plan:

Query, visualize, and alert on data
Monitor Kubernetes and cloud native
Multi-tenant log aggregation system
Scalable and performant metrics backend
High-scale distributed tracing backend
Scalable monitoring for timeseries data
Load testing for engineering teams
Instrument and collect telemetry data
Stay Up To Date
Our biggest community event of the year
News, releases, cool stories, and more
Upcoming in-person and virtual events
By use case, product, and industry
Webinars and videos
Demos, webinars, and feature tours
Hands-on, self-paced courses
Join The Community
Ask the community for help
Grafana 9.0 demo video
We’ll demo all the highlights of the major release: new and updated visualizations and themes, data source improvements, and Enterprise features.
Operational dashboards for your data here, there, or anywhere
Loki + Grafana + Tempo + Mimir + anything else (you know, Big Tent)

The (actually useful) free forever plan
Grafana, of course + 10K series Prometheus metrics + 50GB logs + 50GB traces









Millions of Users across 800K+ Global Instances
Compose and scale observability with one or all pieces of the stack
Your observability wherever you need it
Play around with the Grafana Stack
Experience Grafana for yourself, no registration or installation needed.
Upcoming and recent events
GrafanaLive: Chicago
Scaling your distributed tracing with Grafana Tempo
Learn about our open source tracing database, Tempo, a scalable way to store and query distributed traces generated by any open source tracing …
GrafanaLive: Seattle
Grafana Labs Blog
News, announcements, articles, metrics & monitoring love
Real users getting real value
It’s pretty awesome – with GitHub authentication I was up and running adding datasources and building dashboards in less time it takes to make a coffee.
Thanks @grafana (cloud) for providing a free + easy/simple way to set up a Grafana + Prometheus to monitor various metrics on Postgres/NodeJS/Linux
Loki is my goto log aggregator on my k8s clusters. Just so much nicer experience than others. Less moving parts, better integrated, familiar querying concepts.
@matteojoliveau
I’m amazed at @grafana Loki. So lightweight, yet so flexible and scalable. And the fact that 2.0 can run completely off a single S3 bucket is crazy I think I’m finally decommissioning ElasticSearch for log aggregation
After being stuck with @stackdriver for so long to monitor our clusters we’re finally moving to @grafana. Feels like going from an old unreliable car to a Ferrari.
Grafana dashboard #prometheus metrics behind the scenes at #wimbledon. Yep, they are running on #kubernetes in @ibm cloud
Grafana: инструмент для удобной визуализации метрик мониторинга
«Если результат от запуска IT-проекта нельзя измерить — то как понять, что вы запустили нужный проект?», — говорят грамотные управленцы и бизнесмены. И с ними не поспоришь. Сейчас мы разберемся с тем, что такое Grafana, как она помогает принимать решения и кому нужен этот инструмент.
Метрики мониторинга, которых тысячи
Любой мало-мальски вменяемый IT-проект — это разные метрики. Среднее число активных пользователей в сутки, количество регистраций в неделю, средний чек на клиента, количество активных юзеров, пользующихся новой фичей, — это примеры метрик, с которыми приходится каждый день иметь дело управленцам и владельцам бизнеса. Конечно, это далеко не полный список — крупная компания легко может собирать показатели по тысячам параметров.
Аналитики как раз те люди, которые извлекают из метрик пользу. Они смотрят на колонки цифр и формируют гипотезы и рекомендации по тому, куда и как бизнес должен двигаться дальше.
Эти ребята в основном занимаются математикой и статистикой. Некоторые из них в состоянии самостоятельно писать запросы в базы данных, но это не их основная специальность. А раньше дела обстояли еще хуже — почти никто из аналитиков не умел работать с СУБД.
Поэтому, чтобы обеспечить аналитический отдел топливом в виде метрик, приходилось отвлекать программистов от работы и просить их выгрузить нужные значения из таблиц СУБД. Конечно, это сильно затрудняло процесс.
Grafana — все метрики мониторинга в одном месте
Grafana — универсальная обертка для работы с аналитическими данными, которые хранятся в разных источниках. Она сама ничего не хранит и не собирает, а является лишь универсальным клиентом для систем хранения метрик. Например, с помощью нее можно ходить за цифрами как в традиционную базу PostgreSQL, так и в специализированные аналитические системы типа Prometheus или Influx.
Графану можно подключать к любому хранилищу статистических данных. Разные отделы компании могут использовать разные СУБД и системы сбора статистики. Так вот, Grafana умеет работать с любой популярной системой хранения данных. Конечно, делает она это не сама — первоначальную настройку и подключение к СУБД выполняют администраторы. Но на этом их работа заканчивается — дальше аналитики могут самостоятельно строить свои запросы.

Grafana может собирать метрики из различных источников
Системы хранения данных на рисунке выше — лишь малая часть того, куда Grafana может подключаться для отображения статистики. Если вам нужно что-то очень редкое — всегда можно найти и поставить дополнительные плагины. А их много — комьюнити вокруг инструмента очень активное и дружное.
Большой гайд. Пишем микросервисы на Java и Spring Boot, заворачиваем в Docker, запускаем на EKS, мониторим на Grafana
К какой из двух категорий относится эта статья — решать вам.
Вначале мы напишем пару простых микросервисов на Spring Boot, докеризуем их, зальём в AWS, настроим красивые доменные имена и HTTPS, прикрутим логирование и мониторинг, Prometheus и Grafana. Это небольшое путешествие по всем кругам ада, из которого вы не вернетесь прежним.
Текст написан на основе текстов и демо-проекта microservice-customer за авторством @kamaruzzaman. Если вы потеряли нить повествования, всегда можно зайти на GitHub и найти весь код в пригодном для запуска виде. Если захочется закопаться в тему, то бро Дима Чуйко (@Teapot) написал вам ещё две части статьи «Микросервисы: от CRUD до Native Image» (раз, два).
Часть 1. Пишем код микросервисов
Выбираем технологии
Какую выбрать Java? Многие всё ещё используют Oracle JDK и не осознали, что он имеет определенные лицензионные проблемы. К счастью, у нас есть множество альтернативных дистрибутивов OpenJDK, которые мы и будем использовать. Все они на 100% совместимы со стандартом, и всё такое прочее, т.е. годятся для серьезного продакшена. Версию Java не имеет смысла брать ниже 11 — новые версии куда лучше годятся для облачного использования.
Генерация проекта
Мы напишем микросервисы Customer и Order, и каждый из них будет делать одну свою маленькую задачу, как и положено в соответствии с канонами микросервисной архитектуры, да и хорошей архитектуры вообще (single responsibility principle).
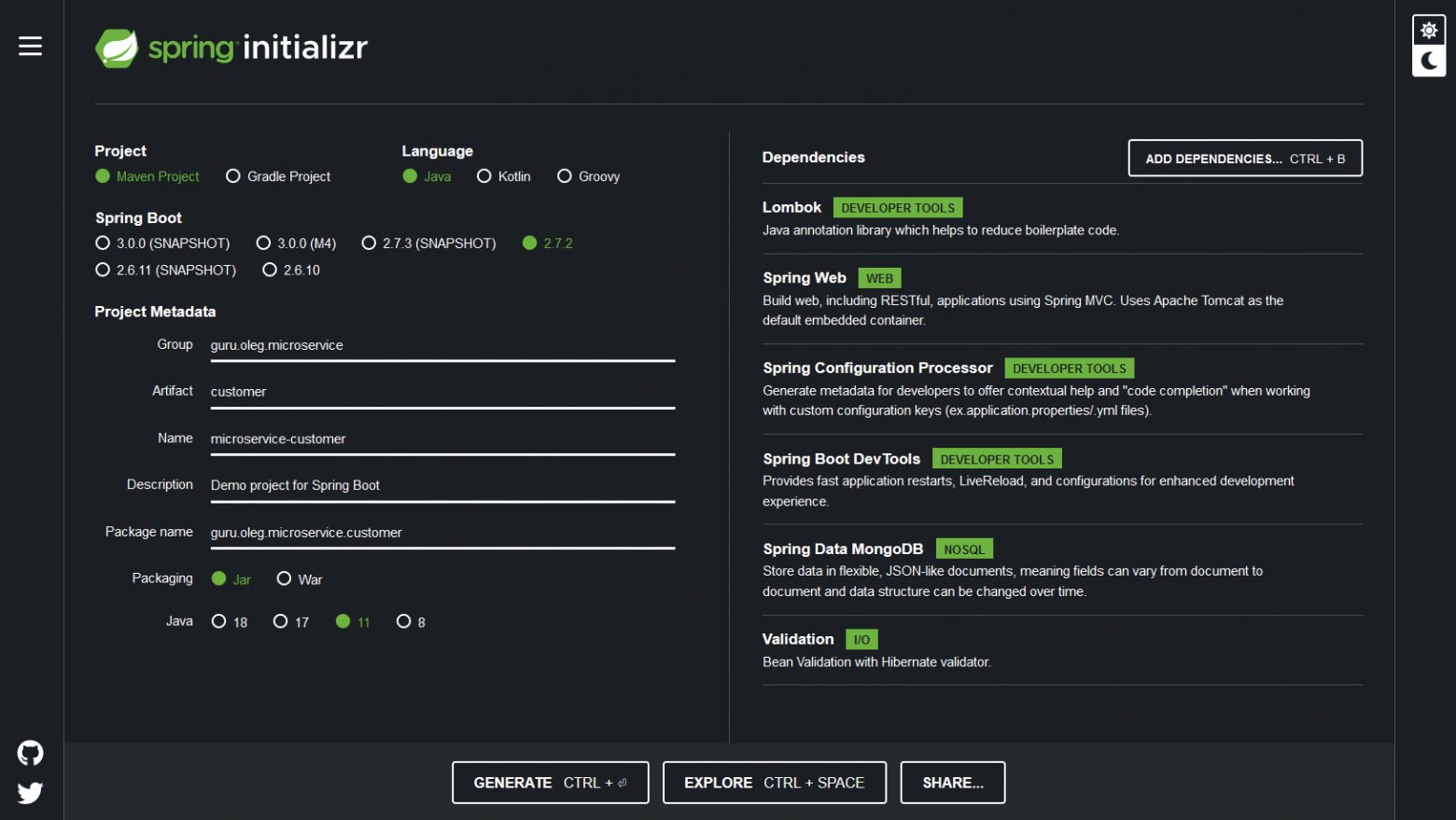
Во-первых, давайте создадим проект Spring Boot с нужными зависимостями. Для этого есть совершенно стандартная для Spring веб-утилита Spring Initializr.
Project: Gradle или Maven (лучше Gradle)
Spring Boot: 2.4.2 (ну или какая там будет доступна, они меняются)
Project Metadata: любые какие понравятся
Spring Configuration Processor
Spring Boot DevTools
Spring Data MongoDB
Микросервис Order
Сущность Order
Вот как выглядит POJO для микросервиса Order:
Микросервис Order у нас состоит всего из одной коллекции, и все ее сущности (продукты, адреса, итп) стоит встроить прямо в эту коллекцию, а не хранить отдельно.
Репозиторий
Чтобы работать с сохранением заказов в базу, нужно создать всего один интерфейс:
Контроллеры
Наша микросервисная архитектура выставляет наружу API, которое клиент или какой-то другой микросервис может использовать чтобы общаться с помощью REST. Spring MVC поддерживает паттерн написания контроллеров, которые выставляют наружу REST API, и делается это буквально в несколько строчек.
Для начала, создадим класс Health :
И дополняющий его класс HealthStatus :
application.yml в директории src/main/resources:
application.yml в директории src/main/local:
Микросервис Customer
А вот список сущностей мы будем использовать другой:
Дальше нужно сделать CustomerRepository по аналогии с OrderRepository :
Ну и традиционно, файлы конфигурации:
application.yml в src/main/local:
application.yml в src/main/resources:
Сервисы
В Spring принято хранить бизнес-логику внутри сервисного слоя. Логику синхронизации Customer и Order придется положить в микросервис Order в таком виде:
Промежуточные итоги первой части
Что мы сейчас имеем на руках? Мы примерно осознали, чем будем заниматься (делать микросервис на Spring Boot и Mongo), написали базовые сущности (Controller, Service, Repository, Entity). Код должен компилироваться без ошибок.
Часть 2. Контейнеризация микросервисов
Инфраструктура Cloud-Native
Прелесть микросервисной архитектуры в том, что микросервисы можно писать сразу на многих языках программирования и нескольких разношерстных технологиях, даже внутри одного проекта. Строго говоря, обсуждая облачную инфраструктуру, нужно всегда задаваться вопросом: а как мы будем писать в ней на нескольких языках сразу? Тем не менее, многоязычные проекты всё ещё не стали золотым стандартом индустрии (хотя и применяются активно в известных конторах типа Netflix). Поэтому, для простоты будем здесь и дальше считать, что пишем всё на Java.
Чтобы развернуть наше приложение в облаке, нужно построить инфраструктуру, в которой участвуют Docker и Kubernetes. Docker позволяет упаковать приложение и всю его уйму зависимостей в контейнер. Этот контейнер запускать в разных средах, поддерживая безопасную и изолированную среду внутри него.
Другие преимущества контейнеров:
Возможность частичного обновления отдельных участков кода, без необходимости останавливать всё приложение;
Многослойные образы, которые можно переиспользовать для создания новых контейнеров;
Возможность откатываться до предыдущей версии образа.
Минутка рекламы закончена. В этот момент вы должны понять, что Docker — это хорошо, а если не поняли — закрыть статью, отформатировать свой жесткий диск и пойти мести крыши.
Один из способов разворачивать приложения Spring Boot или отдельные микросервисы в AWS — создавать докерные контейнеры в формате OCI, использовать Amazon ECR в качестве облачного докерного реестра, Amazon EKS в качестве облачного Kubernetes.
Другой способ — использовать AWS Elastic Beanstalk, который предоставляет Platform as a Service (PaaS) для развертывания веб-приложений в облаке AWS, так что это легко масштабировать и настраивать. В этом гайде мы об этом говорить не станем.
К сожалению, в короткой демке не затронуть всех аспектов жизни в облаках, типа CI/CD, классического JavaEE подхода с помощью MicroProfile, построения распределенных систем, и тому подобного. В голове всё это нужно держать, но сейчас сконцентрируемся на контейнеризации.
Контейнеризация
Вначале нужно установить Docker на компьютер. Процесс этот сильно отличается на разных операционных системах и состоит из множества шагов, поэтому нужно последовать советам из официальной документации.
(Если вы на самом деле хотите разобраться с вопросом: нормально ли ничего не знать о Docker и генерить всё билдпаками, то обязательно ходите на конференции JUG Ru Group. Например, на JPoint был отличный доклад «Не клади все яйца в один buildpack» Дмитрия Чуйко, запись доступна на YouTube).
Чтобы собрать образ микросервиса Customer, достаточно пройти в его корневую директорию и выполнить команду:
Если вам больше нравится Gradle, то команда будет другая:
Эта команда собирает образ на основе файла конфигурации Spring. В нашей демке, образ микросервиса Customer будет называться как-то так: docker.io/library/microservice-customer:1.0.0
Точно такй же командой собирается и микросервис Order: docker.io/library/microservice-order:1.0.0
Запустить их можно, использовав это имя:
Посмотреть, что микросервис запустился, можно на стандартном адресе: http://localhost:8080.
Если контейнер успешно запустился, вы увидите идентификатор этого контейнера в консоли. В вашем случае он будет другой, все идентификаторы уникальны:
Посмотреть логи контейнера можно с помощью следующей команды:
И вы увидите там нечто вроде:
Теперь становится возможно проверить статус контейнера через GET запрос. Сделать запрос можно разными способами, для простоты пусть это будет curl в консоли:
Вот такой результат мы ожидаем:
Чтобы остановить контейнер, нужно выполнить docker stop с указанием идентификатора останавливаемого контейнера:
Промежуточные итоги второй части
Часть 3. Запускаем микросервисы в облаке
Развертывание на Amazon AWS
Для публикации контейнеров мы воспользуемся Amazon ECR. Это Docker Registry, который позволяет хранить, распространять и развертывать контейнеры в облаке AWS.
Вначале, нужно установить и настроить утилиты командной строки AWS CLI на вашем компьютере. Конкретные шаги описаны в официальной инструкции. Я не скопировал их в эту статью исключительно из гуманистических соображений: пара таких инструкций, и Хабр превратится в чертов инсталлятор.
Теперь, для каждого микросервиса нужно создать соответствующий репозиторий в ECR. Важно, чтобы имя репозитория в точности соответствовало названию имени контейнерного образа.
Эта команда создаст репозиторий для микросервиса Order, и должна распечатать вот такой выхлоп:
К нашему локально лежащему образу нужно привязать тэг, в котором описан реестр ECR и репозиторий. Вначале нужно взять идентификатор докерного образа для микросервиса Order, и посмотреть о нём полную информацию:
Теперь, создаем тэг, указывая ECR и репозиторий:
Для публикации образа в ECR, нужно залогиниться. Этот логин продержится 12 часов, после чего придётся перезайти заново.
Теперь можно запушить образ в AWS ECR:
Скорость загрузки зависит от того, насколько быстрый у вас интернет. Это может занять несколько минут, за которые можно вскипятить чаю и поесть.
После загрузки, неплохо сходить в веб-интерфейс и проверить, что всё получилось:

Но самая главная проверка, конечно же, делается не глазами. Давайте попробуем запуллить образ:
Если вся предыдущие шаги были выполнены правильно, мы увидим долгожданный ответ:
Развертывание на EKS
Теперь, нужно сгенерировать строчку для соединения с кластером, которую мы пропишем в микросервисы. Нажмите кнопку «Connect», выберите «Connect your application». Важно: строка для подключения зависит от вашего языка программирования и версии MongoDB. Там будут какие-то инструкции, их все нужно выполнить.
Развертывание Docker-контейнера
Kubernetes (или, для краткости, Куб) — стандарт индустрии для инфраструктурной оркестрации. Он изначально разработан в Google, выложен в опенсорс, и сейчас разрабатывается всем миром. Он помогает в разворачивании, масштабировании и управлении контейнеризованными приложениями.
Если вас это зачем-то интересует, то Kubernetes отлично работает на Docker Desktop, у него в поставке есть сервер и клиент. Не то чтобы это действительно нужно было делать.
К сожалению, Kubernetes требует кучу сисадминской работы. Если хочется только программировать и оставить админскую работу админам, лучше использовать облачные решения, т. е. Managed Kubernetes. Для cloud-native разработки, воспользуемся Amazon Elastic Kubernetes Service (EKS). Он позволяет запускать и масштабировать приложения как в облаке AWS Cloud, так и on-perm на локальном железе.
Установите утилиты для командной строки: eksctl для управления кластером EKS, и kubectl для Kubernetes.
Теперь можно создать кластер EKS, используя команду eksctl :
Эта команда создаёт два воркера типа «t2.small» в регионе «eu-central-1», с именем «microservice».
Где-то там глубоко в кишках, для создания кластера, eksctl использует CloudFormation. Это занимает минут 10-15, поэтому вы снова сможете вскипятить чаю и поесть. Используя облака, вы никогда не умрёте с голоду на рабочем месте. В любом, случае, вот такой в конце концов вас ждет выхлоп:
После того, как прошла целая вечность и кластер создался, можно проверить его статус командой:
Двигаемся дальше. Создадим конфиг развертывания:
Теперь, скормим его kubectl, чтобы развернуть приложение в Kubernetes:
Проверим, что всё запустилось:
Для пущей уверенности, можно проверить лог пода:
По логу видно, что микросервис не только запустился на порту 8080, но и подключился к MongoDB Atlas.
Несмотря на то, что микросервис корректно развернулся в EKS, снаружи до него достучаться невозможно. Нужно создать Kubernetes Service Controller, который выставит наружу IP-адрес, по которому к развернутым приложениям можно будет обратиться из внешнего мира. Вот как определить сервис:
Теперь можно развернуть сервис в AWS:
Сервис привязан к Elastic Load Balancer (ELB) в AWS. Теперь можно проверить, что лежит на внешнем IP-адресе:
Судя по выхлопу, балансировщик находится вот на этом внешнем адресе: aa62f80b9596a4fa6835d80a506227d6-1183908486.eu-central-1.elb.amazonaws.com
Конечно же, можно сходить и в веб-интерфейс:

Заметьте, что DNS имя в ELB — точно такое же, как у внешнего IP-адреса, который мы получили ранее.
Если открыть этот адрес в браузере, то мы увидим веб-страничку нашего микросервиса:

Аналогично, можно развернуть микросервис Order. Просто повторить шаги, перечисленные выше: создать докерный образ, опубликовать его в ECR, развернуть в EKS.
Конечно, вначале, нужно пописать эндпоинт микросервиса Customer в application.yml микросервиса Order:
Все остальные шаги совершенно те же самые.
Избавляемся от облачных ресурсов
Использовать Amazon ECS далеко не дешево. Там и сама инфраструктура EKS (мастер-узел), и воркеры, и балансировщики, и группа узлов. В продакшене они крутились бы круглосуточно, но если вы изучаете вопрос по туториалам, стоит вовремя избавляться от ненужного балласта.
К счастью, делается это предельно просто:
Промежуточные итоги третьей части
Миссия практически выполнена: мы развернули контейнеры в Kubernetes и EKS.
Но это ещё не предел мечтаний. У микросервисов уродливые DNS имена, трафик ходит без HTTPS, логирования никакого нет. Это не очень похоже на прод.
Часть 4. Безопасность, мониторинг и красивые имена
Доменные имена
Amazon Route 53 — это высокоустойчивый, масштабируемый облачный DNS. В дополнение к классическим возможностям DNS-роутинга, он позволяет регистрировать домены и проверять живость сервисов.
Конечно же, можно использовать какой-то другой провайдер DNS. В этом гайде мы воспользуемся именно Amazon Route 53, потому что это просто и удобно.
Вначале, откройте вкладку «Route 53″ и выберите “Register domain»:

Например, можно выбрать имя “microservicesdemo”. Сразу после этого отображаются другие домены с именем “microservicesdemo”. На момент регистрации, microservicesdemo.net было свободно и стоило около 11 американских USD в год.

Дальше вам предлагают вписать разные дополнительные сведения, необходимые для завершения регистрации. Сразу после этого, домен отправляется на регистрацию.

После регистрации имени, Route 53 автоматически настраивает DNS для зарегистрированного домена. Кроме того, создается «Hosted zone», с таким же именем, как и у зарегистрированного домена.
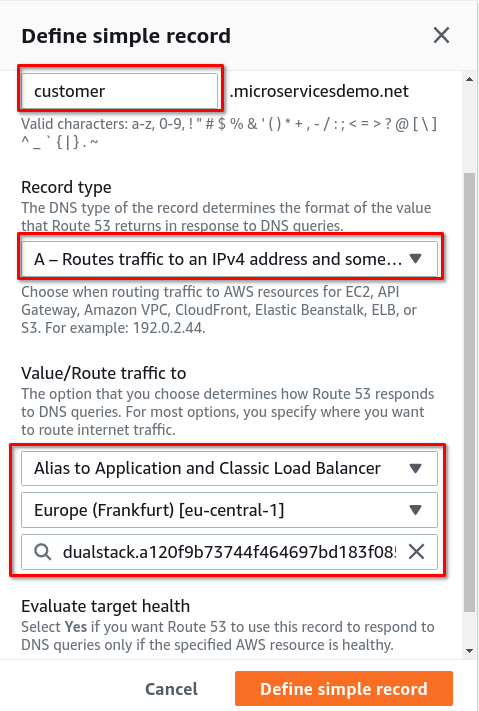
Нам нужно два субдомена для двух микросервисов, трафик с них нужно отправить на балансировщик. Для этого создадим рекорды внутри «Hosted zone»:

В поле ”Routing policy” нужно выбрать “Simple routing”.
В разделе “Configure record”, нужно создать “Simple record” для микросервиса Customer, сконфигурить его доменное имя, и отправить трафик на балансировщик:
В награду за старания, микросервис Customer теперь доступен по новому имени:
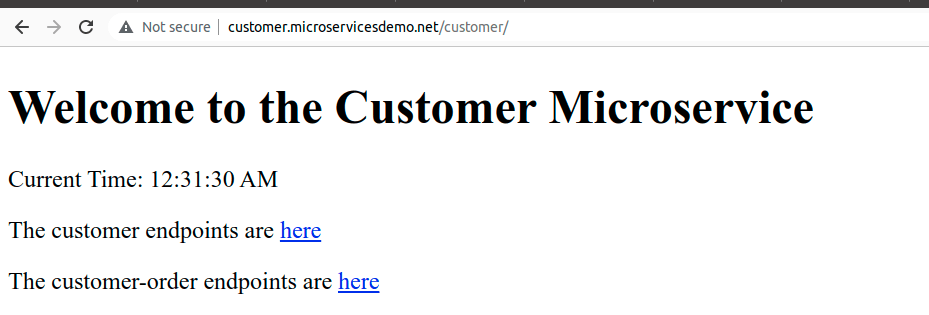
Route 53 DNS Service перенаправляет трафик с субдоменов на балансировщик.
Теперь, нужно повторить все те же самые шаги и сконфигурировать микросервис Order.
Безопасность (HTTPS)

Чтобы управлять сертификатами SSL/TLS у нас есть Amazon Certificate Manager, который мы и заиспользуем на балансировщике.
Откройте Amazon Certificate Manager и найдите раздел с публичными сертификатами:

Дальше нужно запросить сертификат:
На следующей странице указываем домен:

AWS хочет удостовериться, что домен принадлежит именно нам. Самое простое — выбрать вариант “DNS validation”, раз уж мы всё равно копаемся в админке DNS.
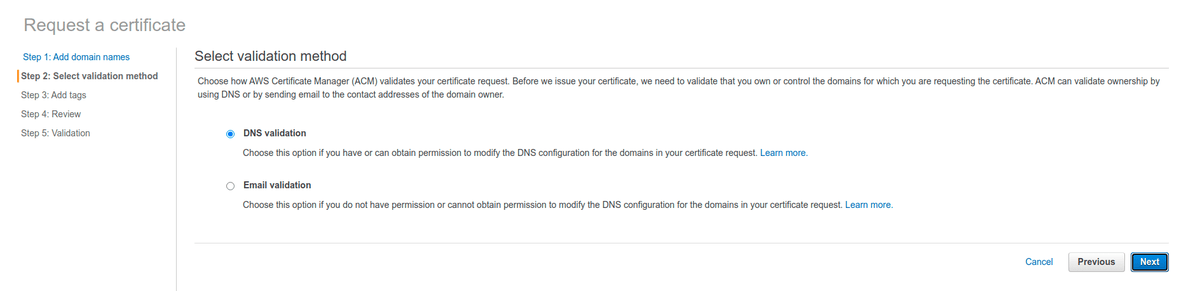
Теперь мы видим DNS-запись CNAME, которую нужно добавить в конфигурацию домена.
Можно сделать это автоматически, прожав кнопку “Create record in Route 53”. (Ценители могут мучиться с конфигом DNS самостоятельно).

Как только сертификат появится, мы увидим вот такой экран:

Что мы здесь видим? Статус сертификата — «issued», то есть он корректно выдан AWS. Интерфейс показывает «no» в поле «in use», потому что мы еще не настраивали использование сертификата.
Теперь, нужно терминировать SSL/TLS на балансировщике. Еще раз напомню, что соединение между балансером и подами зашифровано не будет.
Вначале нужно сделать Load Balancer Service “eks-service-tls.yaml” в директории “src/main/k8s”:
По сравнению с конфигом из предыдущей части, произошли некоторые изменения.
Аннотациями мы сконфигурировали сертификаты, только что выданные в ACM:
Ещё, мы явно определили, что протоколом на бэкенде будет http. Чтобы получить заголовок “X-Forwarded-Proto” мы установили “service.beta.kubernetes.io/aws-load-balancer-backend-protocol” в значение «http».
Ну и порт поменяли на “443”, потому что https.
Теперь можно пройти на страничку микросервиса Customer прямо из браузера: https://customer.microservicesdemo.net/customer

Все те же самые шаги нужно сделать для микросервиса Order.
Логирование через Fluent Bit
Логирование — неотъемлемая часть разработки и эксплуатации. Для продакшена же оно совершенно необходимо. В ходе логирования мы собираем как можно больше полезных данных о том, как работает приложение, и о всех важных событиях. Примеры, зачем это нужно:
Если приложение сломалось, мы можем проанализировать логи и найти корень проблемы;
Если в приложении закрался баг, по логам мы можем воспроизвести проблему;
Если необходимо понять, как работает приложение.
В нашем демо-проекте мы тоже пишем логи. Но как их собрать и проанализировать?
Есть много способов экспортировать логи наружу. Их можено писать в файлы, собирать с помощью специальных API, выливать в STDOUT на консоль, использовать какие-то коллекторы.
Согласно идеям twelve factor apps, которые являются золотым стандартом современной разработки, приложение не должно само писать в файлы или коллекторы. Вместо этого, приложение складывает логи в небуферизованный STDOUT, как в поток ивентов. В случае разработки на локальной машине, программисты имеют возможность видеть этот поток ивентов прямо в своей консоли.
На стейджинге или проде, логи собираются средой исполнения. Роутеры и коллекторы логов собирают и отправляют их в какое-то определенное место конечного хранения (например, базу данных или файл), где их можно складировать и анализировать.
В нашем демо-проекте из двух микросервисов, мы последуем путями “12 factor apps logging”: сгенерируем лог как поток событий, который поймают поды Kubernetes, отправим его в коллектор и анализатор, а в качестве места последнего упокоения заиспользуем Amazon Cloud Watch.
На рынке существует куча разных коллекторов логов. Чаще всего используют вендор-нейтральный Fluentd. Он заслужил определенную славу в последние годы, из-за своих лёгких, но довольно функцинальных фичей. Более того, Fluent Bit, в первую очередь, предназначен именно для работы с контейнерами.
Для нашего демо-проекта, мы заиспользуем Fluent Bit, чтобы собрать данные из подов. Для дальнейшего анализа пригодится Amazon CloudWatch Container Insights. Вот примерная схема используемых компонентов:
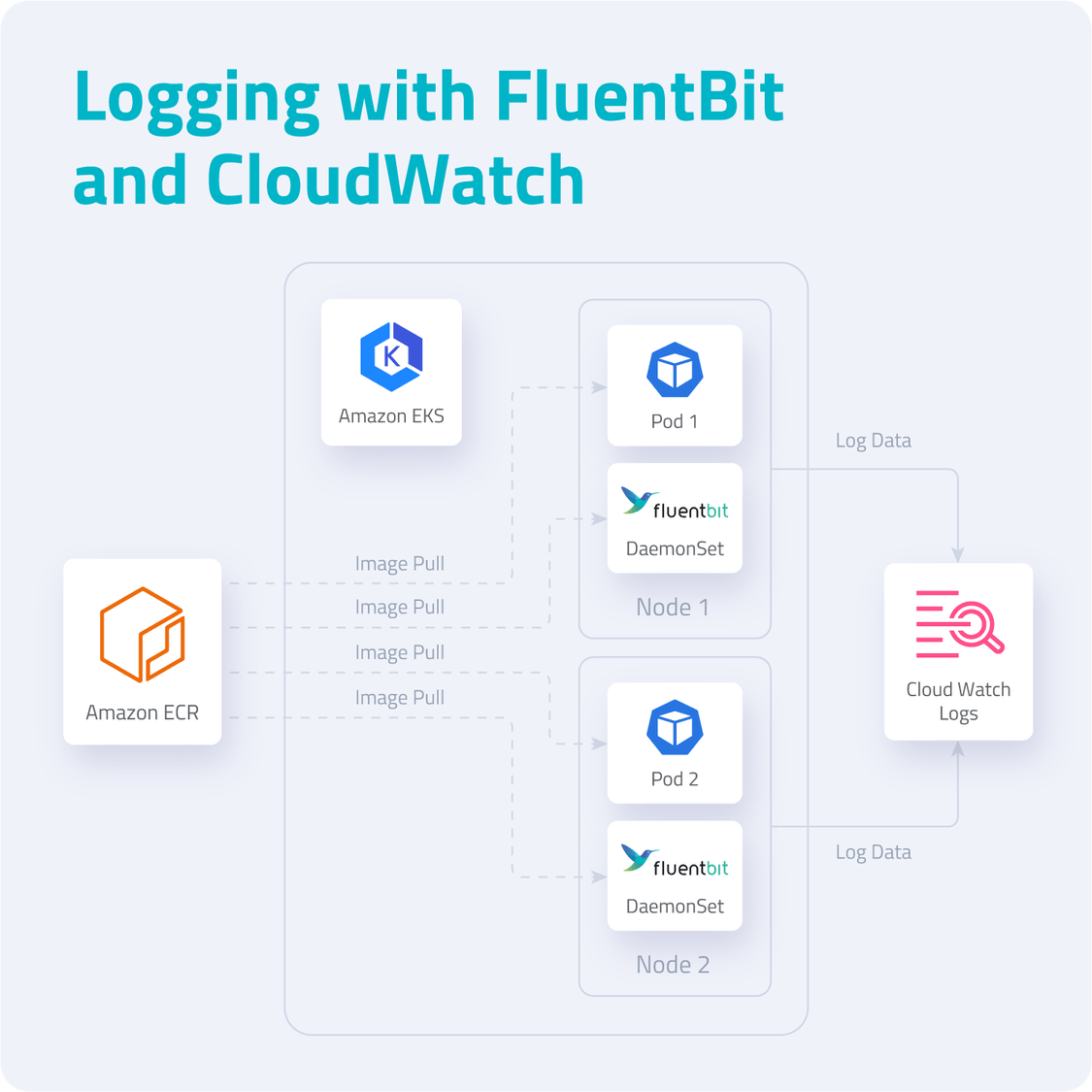
Fluent Bit — это опенсорсный процессор и форвардер логов, который позволяет собирать всевозможные данные (например, метрики и логи) из различных источников, фильтровать и отправлять их по нескольким направлениям, включая CloudWatch. Это очевидное решение для контейнерных технологий, в том числе, для Kubernetes. Архитектура Fluent Bit создана с расчетом на высокую производительность. Для этого она написана на Си и позволяет работать с высокой пропускной способностью, не тратя на это излишние ресурсы процессора и памяти.
В нашем кластере EKS есть следующие типы логов:
Application logs — создаются приложением и лежат в /var/log/containers/*.log
Host logs — системные логи, которые создаются хостовыми нодами EKS и хранятся в файлах /var/log/messages,/var/log/dmesg,/var/log/secure
Data Plane logs — создаются компонентами EKS Data Plane
В Kubernetes существует концепция DaemonSet: все ноды держат по копии пода. Это полезно для кластерных операций, таких как сбор логов и мониторинга узлов, при которых поды автоматически добавляются к новым узлам.
Кстати говоря, DaemonSet — отличный пример, когда стоит вспомнить о размере контейнерных образов. Постоянная загрузка образов жрёт трафик как не в себя. Но к счастью, образы, генерируемые в Spring Boot, собираются на основе Alpine Linux и специальных дистрибутивов OpenJDK, что позволяет им быть очень маленькими. Базовый образ весит на диске меньше 100 мегабайт.
Нам нужно настроить Fluent Bit как DaemonSet, чтобы посылать логи в AWS CloudWatch.
Вначале нужно предоставить IAM разрешения для Kubernetes-воркеров, чтобы метрики и логи улетали в CloudWatch. Это делается добавлением политики в IAM hоли воркеров. Заметьте, что это задача администрирования кластера, и делается ровно один раз при его создании. Заниматься этим каждый день, к счастью, не придется. Вначале, нужно выделить IAM роли воркеров (инстансов EC2):
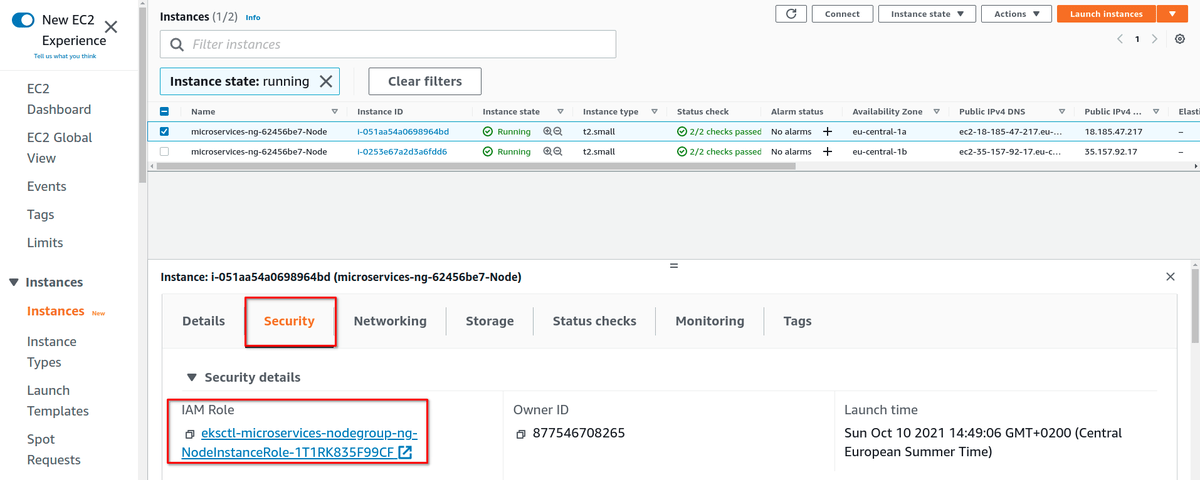
Далее, приаттачить политику “CloudWatchAgentServerPolicy” в IAM роли:

Далее, создать неймспейс “amazon-cloudwatch”:
Далее, создать ConfigMap с именем “fluent-bit-cluster-info”:
Здесь приведены дефолтные настройки FluentBitHttpServer. В дополнение, Fluent Bit читает логи из tail, и поэтому после развертывания захватывает только свежие логи.
Дальше, нужно скачать и развернуть Fluent Bit DaemonSet:
После этих шагов, в вашем кластере появятся следующие ресурсы:
Сервис-аккаунт с именем Fluent-Bit в неймспейсе amazon-cloudwatch. Он используется для запуска Fluent Bit daemonSet;
Кластерная роль с именем Fluent-Bit-role в неймспейсе amazon-cloudwatch. Она позволяет учетке Fluent-Bit смотреть и загружать логи подов;
ConfigMap с именем Fluent-Bit-config в неймспейсе amazon-cloudwatch. В нем хранится конфигурация Fluent Bit.
Дальше, нужно на практике проверить, что у нас запустилось:
В списке должны быть поды с именем, начинающимся на “fluent-bit-”, по штуке на узел. Ожидаемый выхлоп выглядит так:
Если зайти в веб-консоль AWS, наш DaemonSet выглядит как-то так:

Если пройти в консоль CloudWatch, то можно посмотреть, правильно ли мы настроили Fluent Bit. Важно проверить, что регион CloudWatch Console совпадает с регионом вашего кластера EKS (в этом гайде, чуть выше по тексту мы выбирали eu-central-1). В логе должны появиться три группы:

Лог можно фильтровать и смотреть в аггрегированном виде. В нашем демо-проекте, создание заказа с несуществующим customer ID возвращает “500 Internal Server Error”. Все такие события легко ловятся в логах:

Мониторинг через CloudWatch Container Insights
Мониторинг микросервисов на проде не менее важен, чем логирование. Для мониторинга Kubernetes создали кучу всевозможных инструментов. Amazon CloudWatch — это «родной» способ мониторить кластеры EC2. Amazon CloudWatch предоставляет сервис Container Insights, который позволяет мониторить, траблошутить и следить за AWS Elastic Kubernetes Service (EKS) и AWS Elastic Container Service (ECS).
Дашборда Container Insights показывает:
Утилизацию процессора и памяти
Количество задач и сервисов
Чтобы включить CloudWatch Container Insights, необходимо развернуть в кластере EKS агент CloudWatch для FluentBit:
Теперь можно зайти в дашборду CloudWatch Container Insights и понаблюдать за нагрузкой на наш кластер EKS:

Промежуточные итоги четвертой части
Что мы имеем на руках? Мы написали пару микросервисов, опакетили в контейнер, запустили на AWS, прикрутили красивые доменные имена и логи. Тем не менее, CloudWatch Container Insights — это не предел мечтаний, и наш рассказ был бы неполон без ещё одной, последней части.
Часть 5. Мониторинг в Prometheus
Когда вы запускаете Java-приложение (или даже, любое JVM-приложение) в контейнере, то на самом деле оно выполняется на JVM. (Капитан Очевидность отдает честь). Поэтому, если мы мониторим только контейнер, то всей картины получить никак не получится. Для лучшего обзервабилити, нужно мониторить и саму JVM. Одно из ограничений Amazon CloudWatch Container Insights заключается в том, что он может собрать метрики и процессить алерты только на уровне контейнера, а на уровне JVM он так не умеет.
Prometheus — популярная и широко используемая база данных для time series (временных рядов). Она входит в Cloud Native Computing Foundation (CNCF). На GitHub у нее больше 40 тысяч звезд, и по сути, это самое популярное опенсорсное решение для мониторинга.
Prometheus предоставляет очень эффективное хранилище на time series базе данных, кучу интеграций, крутой язык запросов PromQL, отличные визуализации и алерты.
В отличие от CloudWatch, Prometheus работает на основе мониторинга, который пуллит и собирает те данные из приложения, которые выставлены наружу через Metrics API. При разработке cloud-native микросервисов, pull может быть лучше, чем push, потому что это генерирует меньше трафика, создает меньше нагрузки на сеть.
Есть два способа, которым Prometheus вытягивает метрики. Первый заключается в том, что приложения выставляют Metrics API с помощью клиентских библиотек. Библиотека позволяет разработчикам выставить наружу важные им бизнесовые метрики, которые потом пойдут в дашборду Prometheus. Этот способ используется для тех приложений, которые вы сами разрабатываете. Второй способ — запускать рядом с приложением Exporter, который сам выставляет метрики через API. Этот метод больше подходит для сторонних приложений, например, для баз данных. Мы будем использовать клиентскую библиотеку.
Чтобы включить мониторинг Prometheus на AWS, придется немного доделать наши приложения, написанные на Spring Boot.
Включаем Prometheus в Spring Boot
В Java-приложениях есть несколько способов выставить наружу эндпоинты для мониторинга. Эти эндпоинты используются для сбора метрик приложения. Можно использовать данные Prometheus вместе с JMX бинами. В Spring, есть Spring Boot Actuator, который используется для создания хороших, готовых для продакшена эндпоинтов, совместимых с любым приложением на Spring MVC. Почитать про Spring Boot Actuator, можно в официальной документации.
Кроме того, в конфигурацию нужно доложить еще несколько свойств для корректной работы Prometheus Metrics API:
На следующем шаге, нужно заставить работать авто-дискавери, чтобы Prometheus смог сам нас найти и стянуть все данные. Для этого в “eks-deployment.yaml” нужно добавить еще парочку аннотаций:
Теперь, возвращаемся в EKS, и создаем неймспейс Prometheus в нашем кластере:
Теперь нужно создать докерный образ и развернуть его на неймспейсе “eks-prometheus-namespace”. Этот процесс мы уже описывали ранее в этом гайде. (Жестокая реальность в том, что я не буду копипастить сюда третью часть этого гайда, вам придется осознать это самостоятельно).
Как только приложение задеплоилось, нужно пройти в Actuator и проверить эндпоинт Prometheus:

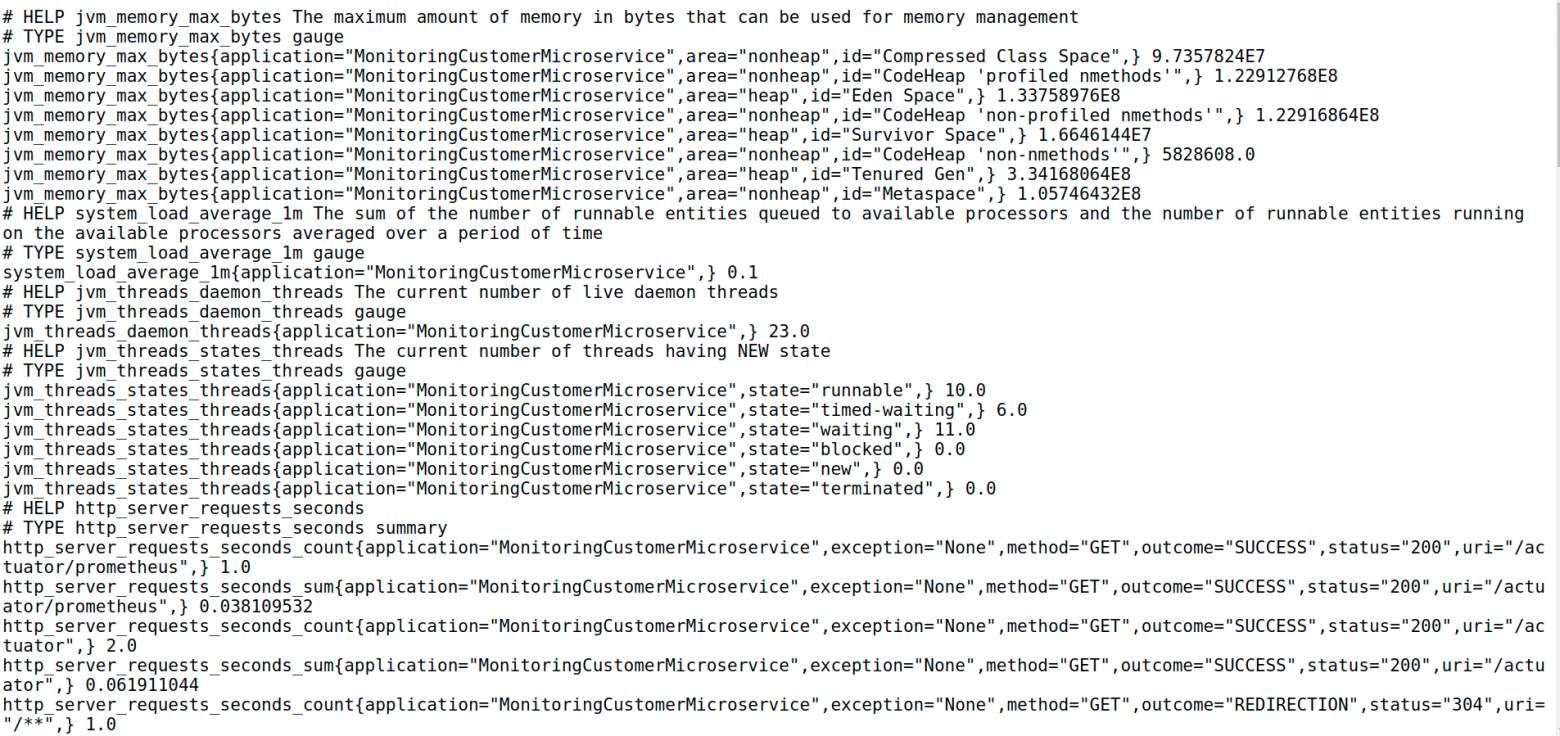
Как всегда, нужно повторить все эти процедуры для второго нашего микросервиса, Order.
Amazon Managed Service for Prometheus (AMP)
AMP Workspace — место для того, чтобы получать, хранить и анализировать метрики Prometheus. AMP Workspace помогает изолировать мониторинг различных проектов/приложений.
Создать AMP Workspace можно через AWS CLI или через AWS Console. Идём в Amazon Prometheus и создаем его примерно так:

Теперь в консоли AWS можно посмотреть подробности о созданном Prometheus Workspace :

Настройка Prometheus Metrics Collector
AMP не стягивает оперативные метрики автоматически. Для этого нужно сконфигурировать Prometheus Metrics Collector. Он стягивает их с контейнеризованных Java-микросервисов, запущенных в кластере, и посылает в AMP Workspace.

Есть несколько способов развернуть Prometheus Metrics Collector в AWS: либо сервер Prometheus, либо агент OpenTelemetry. В этом примере, мы будем использовать AWS-овский дистрибутив OpenTelemetry Collector/Prometheus server.
Установка сервера Prometheus
Устанавливать новый сервер Prometheus имеет смысл с помощью Helm. Helm — это популярный пакетный менеджер для Kubernetes. С помощью него легко и приятно искать, распространять и использовать софт, сделанный специально для Kubernetes.
Вначале, нужно установить Helm на наш локальный компьютер, как рассказано в официальной документацией.
Дальше, нужно добавить репозиторий чартов, где лежит Prometheus:
Настройка ролей IAM
Нужно настроить IAM роли сервис-аккаунтов для приема метрик из кластера EKS. Сервер Prometheus посылает данные с по HTTPS. Данные нужно подписать валидными креденшелами AWS и алгоритмом AWS Signature Version 4 для аутентификации и авторизации каждого клиентского запроса, предназначенного для управляемого сервиса. Запросы отправляются инстансу AWS signing proxy, который перенаправляет эти запросы на управляемый сервер.
AWS signing proxy может быть развернут на кластере EKS и может запускаться от имени сервис-аккаунта Kubernetes. С помощью IAM Roles for Service Account (IRSA), можно связать роль IAM с сервис-аккаунтом Kubernetes, и тем самым предоставить полномочия для каждого пода, который использует этот сервис-аккаунт. Это соответствует принципу минимальных привилегий: IRSA используется для безопасной настройки AWS signing proxy, чтобы переливать метрики Prometheus в AMP.
Подробное объяснение того, как для AMP настроить IAM роли сервис-аккаунтов можно прочитать в официальном гайде.
После создания двух ролей (одной для приема метрик, и второй для запросов), мы можем проверить правильность происходящего, поискав эти роли в консоли:
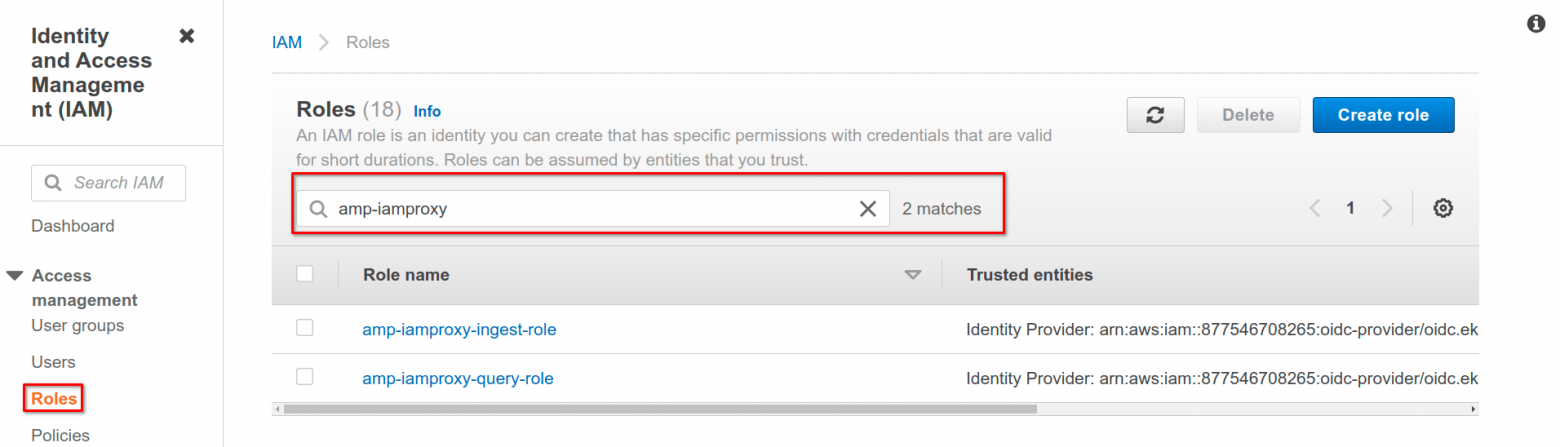
С помощью Helm можно переопределить конфигурацию Kubernetes. Нужно создать файл с именем “prometheus_eks_values.yaml” и содержимым типа такого:
В этом файле, мы просим использовать целевой Amazon Managed Service for Prometheus, а сервер Prometheus, запущенный на EKS Kubernetes, будет посылать данные с мониторинга.
Теперь, создадим сервер Prometheus следующей командой Helm:
Визуализация метрик в Amazon Managed Grafana
Grafana — это опенсорсная веб-консоль для аналитики и визуализации данных. Он предоставляет дашборд с графиками, таблицами, алертами (будучи подключена к источнику данных, который такое поддерживает). Grafana оказывается полезной для логирования, мониторинга, трейсинга, и так далее. Часто она используется в тандеме с Prometheus: можно показать дашборд с данными Prometheus на AWS.
Дальше я опишу шаги, которые позволяют настроить амазоновскую Grafana так, чтобы она начала визуализировать данные от Prometheus.
Для аутентификации в управляемой Grafana, мы будем использовать AWS SSO. Если у вас включена “AWS Organization”, то вы можете сделать пользователя AWS SSO как-то так:

Дальше, нужно создать воркспейс для Grafana. Grafana Workspace — это некий виртуальный сервер, который используется как общий дашборд для данных из различных источников.
Из раздела “Amazon Grafana” > Workspaces, новый воркспейс можно создать, выбрав опцию “Create workspace”:

Теперь нужно указать имя воркспейса, в нашем примере это “prometheus-metrics”:

Дальше, этот воркспейс нужно настроить. Мы будем использовать AWS SSO как метод аутентификации, и тогда ранее созданный аккаунт WEB SSO можно будет использовать чтобы залогиниться в Grafana. “Permission Type” установим в значение “Service managed”, тогда AWS автоматически будет предоставлять нужные разрешения.

На последней странице мастера, нужно установить “IAM permission access settings” в значение “Current Account”. В разделе “Data Sources” можно выбрать разные источники данных, и таким образом, у нас будет один дашборд Grafana, который можно использовать для разных целей и разных инструментов (Prometheus Monitoring, AWS CloudWatch Monitoring, AWS X-Ray Tracing, итп). Сейчас в качестве источника данных выберем “Amazon Managed Service for Prometheus”. Для нотификаций пусть будет “Amazon SNS”.
Как только воркспейс создан, становится возможным привязать нашего ранее созданного пользователя AWS SSO к этому воркспейсу:


Далее, логинимся в воркспейс Grafana, пройдя на URL воркспейса, через AWS SSO. Сразу после логина, мы можем добавить воркспейс Prometheus в качестве “Data Source”:



После успешного импорта, можно увидеть дашборд с данными мониторинга Kubernetes, включая JVM-специфичную информацию типа использования CPU или использования джавной кучи:

И конечно, какой же джавист не хочет посмотреть на подробности работы сборщика мусора?


Ещё, мы можем смотреть историю реплики с нужными критериями поиска:

Диаграмма выше показывает, что все наши реплики (4 для микросервисов и 4 для кластера Prometheus), отлично себе работают и не падают.
На проде очень важно установить правильный набор алертов, чтобы вовремя заметить некорректную работу приложения. Алерты позволяют техподдержке быстро отреагировать на ошибку на проде. Алерты просто необходимы, если вам нужно выполнять какие-то понятные SLA/SLO на приложение.
Вот пара примеров того, что можно использовать в алертах:
CPU используется более чем на 80%
RAM используется более чем на 80%
Поды перезагружаются каждые 10 минут
База данных заполнена на 90%
Когда у вас сработал какой-то алерт, активируется триггер, сообщающий об этом команде техподдержки или безопасникам. В зависимости от того, какой алерт сработал, можно использовать разные каналы оповещения: электронную почту, SMS, чаты.
Итоги
В этом гайде мы совершили небольшое путешествие по разработке микросервисов. Оно началось с написания кода в IDE и закончилось наблюдением графиков в Grafana.
Надеюсь, этот гайд окажется хорошей отправной точкой для людей, в первый раз погружающихся в страшный волшебный мир микросервисов на Java и всего того DevOps ада, который ждёт вас при встрече с облачными провайдерами.
Все сообщения об опечатках, отвратительных англицизмах, битых ссылках и прочих вопросах по форме, а не по сути — прошу пройти с ними в личку, чтобы не мусорить в комментариях.
Если хотите пообщаться со мной по существу, лучше использовать не личку Хабра (там миллионы каких-то сообщений, шансов разгрести которые нет), а писать на рабочую почту (по рабочим вопросам), либо в личный Facebook и личную почту (по приватным вопросам).
Отдельная просьба к сотрудникам облачных провайдеров. Если вы готовы предоставить помощь в написании подобной статьи не для Amazon, а для ваших облаков (SberCloud, MTS Cloud, Selectel, Yandex.Cloud, VK cloud solutions, итп), свяжитесь со мной любым способом. Помощь может выражаться, например, в экспертизе по использованию ваших аналогов зарубежных сервисов, помощи в вычитке статьи, либо предоставлении демо-доступа до ваших облаков.
Приятного Сезона Java на Хабре!
Как настроить мониторинг бизнес-процессов в БД Oracle и построение графиков, используя бесплатную версию Grafana
Вводные. Зачем мне это было нужно
Лично мне нужно было организовать мониторинг домашней солнечной электростанции.
Кратко о матчасти (хотя этот пост не про неё):
Инвертор МАП Энергия и 3 солнечных контроллера того же производителя.
Внутри инвертора установлен микрокомпьютер (производитель его называет «Малина»), который кое-что умеет в плане мониторинга, но не всё что мне нужно, и не очень удобно. Ценность микрокомпьютера в том, что он снимает данные с com-портов инвертора и контроллеров и публикует их насвоём http-сервере в виде Json. Данные веб-сервисов обновляются примерно каждую секунду. Также есть веб-сервисы для управления встроенными в контроллеры и инвертор реле
Парочка Ethernet-устройств SR-201 это такие платы с релюхами, используются для управления нагрузкой и кое-чем еще, управляются по протоколу tcp и udp.
Домашний сервер под управлением Centos-8, на нём установлен Oracle (разумеется Express Edition со всеми своими ограничениями, но для домашнего сервера достаточно)
В оракле крутятся 2 JOBa (на самом деле это persistent процессы, которые крутят бесконечный цикл и перезапускаются примерно раз в полчаса):
Постоянно пересчитывает статистику за некоторый промежуток времени, и на основе полученных результатов, управляет нагрузкой и еще кое-чем через SR-201 и встроенные реле инвертора и контроллеров.
Вопросы: Почему Oracle а не Postgres например? Ну просто лень, хотелось сделать из того что умею. 🙂
Собственно описание проекта
Данный пост ни разу не претендует на качественный пошаговый tutorial, я лишь хочу указать путь, по которому Вам будет легче идти.
Selinux у меня отключен, файрвол тоже, так что в эти нюансы вдаваться не буду
Далее одна проблемка: Grafana конечно с Oracle работать умеет, но данная опция (плагин) предоставляется только в Enterprise версии, которая начинается от 24к$ и это в мои планы не входит. Устанавливаем плагин grafana-simple-json-datasource
Вебсервис будем делать на apache + php
Для этого потребуется установить и настроить:
httpd, php и php-fpm (у меня php 7.2) установлен и сконфигрирован вместе с freepbx которая живёт на том же сервере 🙂
В общем путь такой:
Подключаем репозиторий remi, и оттуда:
Подключаем oci8 к php
В принципе достаточно раскомментировать 1 строку
Далее этот oci8 не очень хочет запускаться, тут помогут примерно такие строки в
Теперь при исполнении php-скрипта на вебсервере, oci8 прекрасно запускается
Выкладываем скрипт на вебсервер
В нашей БД есть пакет LGRAFANA, из которого наружу торчит только одна процедура
Теперь настройка в самой графане:

Дальше можно идти добавлять DashBoard и накидывать туда панели с нужными графиками
. Если у Вас уже есть реализация пакета LGRAFANA разумеется.
Да кстати про пакет.
Реализуем метод, который реагирует на pahinfo=/search и отдаёт массив имён метрик которые мы умеем считать
Реализуем метод /query который формирует массив данных по нужным метрикам
Установка и настройка Grafana
Если работаешь системным администратором или аналитиком, то часто приходится отображать данные о событиях или статистику в виде графиков и диаграмм, в зависимости от времени, когда они произошли. Для этого существует множество инструментов, и об одном из них мы поговорим в этой статье.
Установка Grafana в Ubuntu
В официальных репозиториях дистрибутива пакета для этой программы нет, но вы можете установить её из официального репозитория самой программы. Чтобы добавить репозиторий, выполните такие команды:
sudo add-apt-repository «deb https://packagecloud.io/grafana/stable/debian/ stretch main»
Затем нужно обновить список пакетов:
sudo apt-get update
Установка Grafana Ubuntu:
sudo apt-get install grafana
Затем запускаем сервис и добавляем его в автозагрузку:
sudo systemctl start grafana-server
sudo systemctl enable grafana-server

Теперь убедимся, что сервис действительно запущен и не произошло никаких ошибок:
sudo systemctl status grafana-server
Если всё прошло хорошо, то в выводе вы увидите сообщение active(running), выделенное зеленым цветом.

У Grafana своя система авторизации, поэтому закрывать её обратным прокси не обязательно, если вы, конечно, не собираетесь добавлять для интерфейса SSL-сертификат. Но по умолчанию интерфейс доступен на порте 3000. Нам нужно добавить его в исключения брандмауэра. Для этого выполните:
ufw allow 3000/tcp
Если на вашем сервере брандмауэр не настроен, то ничего делать не надо, порт будет доступен по умолчанию.
Установка Grafana в CentOS
В CentOS программа устанавливается похожим образом. Только добавление репозитория будет выглядеть совсем по-другому. Для добавления официального репозитория продукта создайте файл /etc/yum.repos.d/grafana.repo со следующим содержимым:
[grafana]
name=grafana
baseurl=https://packagecloud.io/grafana/stable/el/7/$basearch
repo_gpgcheck=1
enabled=1
gpgcheck=1
gpgkey=https://packagecloud.io/gpg.key https://grafanarel.s3.amazonaws.com/RPM-GPG-KEY-grafana
sslverify=1
sslcacert=/etc/pki/tls/certs/ca-bundle.crt
Сохраните изменения с помощью :w, и можно устанавливать Grafana:
Затем, таким же образом, запустите сервис и добавьте его в автозагрузку:
systemctl start grafana-server
systemctl enable grafana-server
Для управления брандмауэром в CentOS используется команда firewalld. Чтобы разрешить доступ к программе извне, выполните:
Grafana готова к использованию.
Настройка Grafana
1. Первый вход
Чтобы войти в интерфейс Grafana, нужно ввести в адресной стройке адрес http://localhost:3000 при условии, что вы устанавливали сервер на локальный компьютер. Если программа установлена на другой компьютер или сервер, то нужно ввести именно его адрес.


2. Источники данных
Дальше вы будете перенаправлены на домашнюю страницу:

Здесь нам система предлагает добавить источники, откуда будут загружаться данные. Для этого нажмите на зеленую кнопку Add Data Source:

В открывшемся окне введите названия ресурса и выберите его тип, движок, откуда будут браться данные. В этом примере я буду использовать InfluxDB:


Если база данных закрыта с помощью http-аутентификации, то ниже надо указать для неё данные. В самом низу нужно указать имя базы данных пользователя и его пароль для доступа к ней:

Затем нажмите кнопку Save. Если всё прошло успешно, то вы увидите сообщение, что источник успешно добавлен.

3. Создание Dashboards Grafana
Вернитесь на домашнюю страницу и нажмите кнопку New dashboard:

Доска создана. Теперь нам нужно заполнить её виджетами.

Сейчас доступно 9 разных виджетов:
Полезны нам для вывода информации только первые четыре, остальные используются для организации пространства или вывода меню программы. Давайте сначала создадим график.
4. Настройка графиков Grafana
Теперь разберём, как выполняется настройка графиков Grafana. Как вы догадались, для создания графика нужно нажать на кнопку Graph. После этого пустой график будет добавлен в рабочую область панели:

Нажмите на стрелочку около его заголовка и выберите в открывшемся меню Edit:


Рассмотрим содержимое интерфейса настройки более подробно:
Эти настройки можно разделить на несколько пунктов:
В нашем примере у меня есть база с климатическими данными за определённый период, температурой и влажностью. В ней есть таблица rpi-dht22, в которой есть поля: time, humidity, temperature и location. Структура документа influxdb:
<
«measurement»: rpidht22,
«tags»: <
«location»: indor/outdor,
>,
«time»: ГГГГ-ММ-ДДTчч:мм:ссZ,
«fields»: <
«temperature» : температура,
«humidity»: влажность
>
>

Если в базе есть данные, то они уже должны начать отображаться. Если не отображаются, попробуйте добавить больше данных или измените период или интервал времени:


Если всё ещё что-то не работает, вы можете нажать кнопку Query Inspector на панели вкладок и посмотреть запрос, который используется для получения данных, его можно потом выполнить отдельно в интерфейсе базы данных, поэкспериментировать и понять, что не работает.
Сейчас мы на вкладке Metrics. Переключившись на вкладку General мы можем настроить имя графика в поле Title:

Сохранив график, вы вернётесь к нашей панели и получите такой результат:

Вот такие графики Grafana можно получить. Если добавить несколько полей данных для графика с помощью кнопки Add Query:

То на одном полотне будет отображаться два графика:

5. Создание SingleStat
Виджет SingleStat позволяет отображать усреднённое значение показателя, а также шкалу и его текущую позицию на ней. Чтобы добавить новый элемент на панель, нажмите кнопку Add Panel:

Затем выберите пункт SingleStat:

Настройка источников данных выполняется точно также, как и для графика, только сюда можно добавить лишь один показатель.

Особенность этого виджета в том, что он берёт все данные и применяет к ним определённую функцию, а затем выводит результат. По умолчанию применяется функция average. Я хочу знать текущую температуру, для этого мне надо получить последнее значение из списка, а не среднее. Функцию обработки данных можно изменить на вкладке Options. Для последнего значения выберите в поле Stat значение Current:

Чтобы включить отображение шкалы, найдите на вкладке Options пункт Guage и поставьте напротив него галочку. Здесь же можно указать максимальное и минимальное значение:

Вот такая панель получится в результате:

6. Настройка панели
Имя панели вы можете задать, нажав на кнопку с шестерёнкой. Затем введите нужное имя в поле Name:


Таблица и тепловая карта выглядят вот так:

После внесения изменений не забывайте сохранить панель.
7. Импорт и экспорт
Готовую панель можно экспортировать и импортировать на другом сервере. Для этого есть кнопка Share:


В открывшемся окне нажмите кнопку Import, теперь осталось выбрать файл и выбрать источник, откуда будут браться данные.