иерархическая связь между отношениями в реляционной модели предполагает
Реляционная модель данных
Для того, чтобы изучение реляционной алгебры не превратилось в скучный перечень операций, мы их вводим порциями, достаточными для получения какого-нибудь интересного результата.
Сначала определим операцию декомпозиции — разбиения заполненного отношения на части. Удивительно, но не всегда воссоединение компонент дает исходное отношение. В этом случае декомпозиция называется неполной. На языке алгебры декомпозиция и воссоединение компонент определяются, соответственно, операциями проекции и естественного соединения.
Оказывается, функциональные зависимости, определенные на отношениях, дают естественный язык для задания идентификаторов кортежей отношений (ключей) и для формулирования теоремы Хиса, позволяющей выделить допустимые декомпозиции.
Выделим набор независимых операций. Рассмотрим самую необычную для алгебры операцию переименования атрибутов.
Разберёмся с отображением модели «сущность-связь» в реляционную модель.
В самом конце главы перейдём к реализациям и рассмотрим соотношения между реляционной и табличными моделями.
К 70-м годам направление баз данных представляло мощную индустрию, в которой доминировали иерархические и сетевые модели.
К 1973-му году был принят стандарт CODASYL, определивший общепринятые особенности сетевой модели. Он определил понятия простого и составного элементов данных — аналогов простого поля записи и агрегата. Запись —это именованный агрегат, не входящий ни в какой другой агрегат. В записях можно использовать неопределённое значение. Определялось два типа агрегатов — «вектор», состоящий из простых элементов данных, и «повторяющаяся группа элементов». При этом повторяющаяся группа может образовываться элементами данных, векторами, агрегатами и другими повторяющимися группами.
Наборы представляют связи между типами записей. Как упоминалось в разделе 3.3.1, термин «набор» в модели CODASYL не совпадает с употребляемым нами термином «набор записей». Можно определить любое количество типов наборов между двумя типами записей. Тип набора — это двучленная конструкция, объединяющая тип записи владельца набора и типы записей-членов набора.
В это же время в 1970 г. появилась основополагающая работа Э.Ф.Кодда, в которой он применил к описанию баз данных алгебру отношений — реляционную алгебру. Появилась реляционная модель данных, представляющая базу данных как набор отношений, может быть связанных. Началась эра реляционных баз данных.
Можно спросить, чего же не хватало в существовавших моделях данных? Что обеспечило победное шествие реляционной модели, которому не помешало низкое быстродействие первых её реализаций? Иерархической и сетевой модели не хватало математической убедительности, то есть отсутствовала простая и красивая математическая модель. Это бы ещё полбеды. Плохо то, что в старых моделях было много обременительно лишнего. Язык манипулирования данными и язык запросов носили навигационный характер и требовали знания деталей структуры базы.
Принятие реляционной модели широким кругом пользователей и вендоров обеспечило развитие математической теории, и создание стандартов для её реализаций. Вот с реализациями получилась весьма интересная история. С некоторой стадии их развития математические идеи иссякли и теперь развитие языков манипулирования данными и запросов направляют другие движущие силы. Но об этом мы поговорим в главах, начиная с 8-й. Изменения вызванные практическими потребностями, настолько велики, что в настоящее время реляционные модели практически заменены тем, что в дальнейшее мы будем называть табличными моделями или моделями реляционного типа. Поэтому, кроме отношений в конце этой главы будем рассматривать таблицы.
Давайте разберёмся с основами реляционной модели данных.
4.1 Отношения и их свойства. Схема и состояния отношения
Основные структуры данных в реляционной модели — отношения и атрибуты.
Схему отношения можно определить через задание предиката. Спецификациям отношений соответствуют предикаты. При этом типу записи соответствует предикатный символ, а полям соответствуют аргументные места предикатного символа.
Пример предиката, соответствующего спецификации отдела приведен на рисунке 4.1.

Каждой записи соответствует высказывание (на языке Пролог — факт), например, отдел(001, «Рога и копыта», «Нью-Москва»)?
Принадлежность кортежа к отношению определяется истинностью описывающего его предиката.
Однако, в реляционной модели принято говорить об отношениях, которые имеют имя и набор свойств, называемых атрибутами (рисунок 4.2).

Под сигнатурой отношения будем понимать набор, состоящий из имени отношения, имён и типов его атрибутов. Отношения без атрибутов не рассматриваются.
Свойство. Данные в реляционной модели хранятся только в отношениях с конечных числом атрибутов. Других источников данных не существует.
Будем рассматривать отношения как наборы однотипных строк-кортежей. Пример: Отношение «Студент» с атрибутами «Фамилия», «Имя», «Отчество», «Дата_рождения», «Студенческая_группа», «Телефон».
Студент(Фамилия, Имя, Отчество, Дата_рождения, Студенческая_груп-па, Телефон)
Каждый студент представляется строкой значений своих атрибутов — кортежем, например,
Обратите внимание, на то, что последний атрибут это всего лишь строка «111-0000, 222-0000», и нельзя будет определить, есть ли у Иванова телефон 111-0000. С подстроками модель не работает.
Основные свойства отношений:
Свойства отношений для удобства запоминания представлены на рисунке 4.3.

Обратите внимание на то, что простота типов данных вовсе не означает, что хранящиеся значения не имеют какой-нибудь структуры. Однако в рамках реляционной модели мы не можем эту структуру воспринять.
Замечание. В реализациях отсутствие упорядоченности может быть не удобным или не реализуемым, а метрические свойства всегда важны, поскольку они определяют быстродействие.
Замечание. Связей между отношениями, которые мы изучали в модели «сущность-связь», в реляционной модели нет. Связи определяются через ключевые атрибуты. В реализациях они задаются ограничениями целостности первичного ключа и внешнего ключа.
Состоянием отношения называется набор входящих в него кортежей.
Основные модели данных: иерархическая, сетевая, реляционная
 Для реализаций универсальных СУБД в течение многих лет и по настоящий момент доминирует реляционная модель. Несмотря на то, что вы, возможно, и не столкнётесь с СУБД иных типов, нелишним будет знать о существовании других миров. Например, чтобы понимать, соответствуют ли реалиям заявления продавцов о «новых подходах и концепциях».
Для реализаций универсальных СУБД в течение многих лет и по настоящий момент доминирует реляционная модель. Несмотря на то, что вы, возможно, и не столкнётесь с СУБД иных типов, нелишним будет знать о существовании других миров. Например, чтобы понимать, соответствуют ли реалиям заявления продавцов о «новых подходах и концепциях».
Иерархическая модель
Исторически, первой моделью данных, то есть способом их организации, структурирования, доступа и манипуляции, была иерархическая модель. Сейчас уже трудно найти тому причину, вероятнее всего сыграла свою роль тесная связь традиционного программирования с метафорой деревьев — упрощённого типа графов. С другой стороны, человеческому мозгу, справляющемуся со сложностями окружающего мира путём выделения иерархий, работать с ними оказывается проще, чем с более абстрактными множествами.
Продукт IMS (Information Management System) фирмы IBM, считающийся первой промышленной СУБД, реализует именно иерархическую модель.
Разработанная в 1966 году, эта СУБД до сих пор эксплуатируется на новейших мэйнфреймах серии Z, обеспечивая высокую производительность обработки порядка сотни тысяч транзакций в секунду.
Современной массово доступной каждому программисту реализацией иерархической модели данных является XML, точнее, разнообразные
«движки» и API для манипуляции со структурами, созданными на основе этой технологии с обязательным применением схем определения данных.
Последний пункт важен: без использования XML-схемы (XML schema) или описания типов DTD (Data Type Definition) документ XML относится к неполно структурированным моделям данных, рассматриваемым в следующей главе.
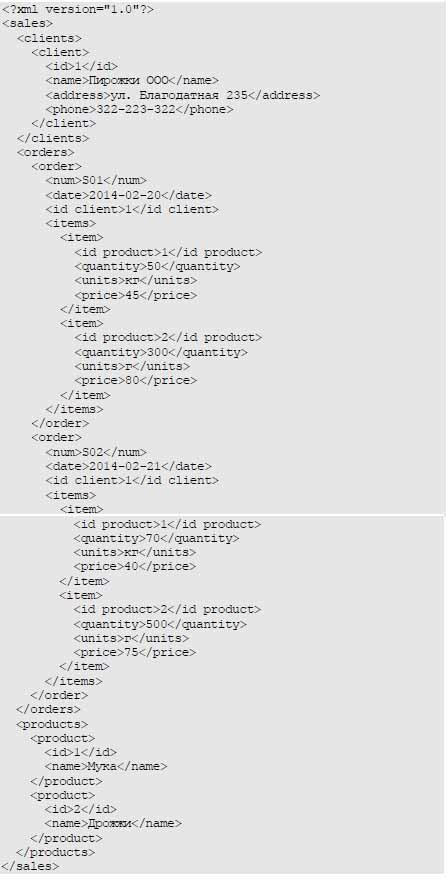
Если взглянуть на структуру XML-документа, то иерархия элементов данных становится видна, что называется, невооружённым глазом.
В приведённом примере БД описания продаж имеет иерархическую структуру. Все описываемые сущности являются вложенными в сущность более высокого уровня организации, что вызывает определённые неудобства хранения: приходится дублировать информацию.
Преимуществом такой структуры является возможность выполнения поисковых запросов без соединений. Например, чтобы выбрать все заказы клиента «Пирожки ООО», в которых он покупал муку в количестве более 50 кг, язык XPath [1] позволяет сделать в программе следующее:
Однако, с точки зрения расширяемости и поддержки целостности такая структура малопригодна. В рамках реляционной модели мы бы констатировали, что она денормализована, о чем будет сказано позже в разделе, посвящённом
проектированию. Например, при добавлении оплат потребуется создавать новый тег описаний
Частично, эта проблема решается введением ссылок на элементы XML- документа.
Структура становится гибче, мы исключаем дублирование. Но теперь наш первоначальный запрос значительно усложнится, так как приходится делать соединения между элементами.
На XML-документах небольшого размера с сотнями элементов подобные запросы выполняются быстро, но с ростом объёма данных неизбежно возникает необходимость их индексировать. В СУБД, поддерживающих XML хотя бы на уровне типа данных колонки таблицы, имеется возможность такой индексации. Например, в MS SQL Server вначале строится так называемый первичный XML-индекс, затем несколько вторичных, для которых нужно указывать их специализацию: PATH для запросов типа проверки
существования элементов, PROPERTY — для извлечения значений элементов и атрибутов или VALUE — для сквозного поиска элементов по значению. Без достаточного понимания таких особенностей физической организации данных хранилище XML начнёт испытывать проблемы с производительностью уже на небольших объёмах.

Кроме XML и поддерживающих его СУБД существуют и другие реализации. Наиболее известная отечественная разработка — СУБД ИНЕС, являвшаяся фактически стандартом на советских ЭВМ серии ЕС. К сожалению, эволюция системы прервалась вместе с прекращением выпуска своих ЭВМ, до наших дней этот продукт не дожил.
К иерархическим также можно отнести СУБД на базе подхода MUMPS [2] (в СССР назывался «ДИАМС»), лежащий в основе линейки продуктов InterSystems: от выпущенной в 1970-х годах СУБД ISM (InterSystem M), через OpenM периода 1980-х к СУБД Cache с конца 1990-х и по наше время, реализующей современные подходы к организации иерархий.
Так, например, в MUMPS можно обращаться к значениям полей:
Здесь сущность «Автомобиль» представлена в виде дерева, одним из верхних узлов которого является элемент «Корпус», в состав которого, в свою очередь, входит «Дверь», имеющая пока ещё листовой узел «Цвет».
Иерархию несложно динамически расширять как в ширину:
Общий принцип распознавания лежащей в основе СУБД иерархической модели можно сформулировать так.
Если при использовании входного языка и/или API наиболее низкого уровня из доступных программисту для доступа к данным (значениям узлов, переменных, полей и т д.) требуется указывать некоторый путь, то лежащая в основе СУБД модель базируется на иерархиях.
Иерархическая модель: плюсы и минусы
К преимуществам иерархической модели можно отнести относительную простоту восприятия логической структуры базы данных человеком. Система обеспечивает высокое быстродействие при транзакционной обработке, когда номенклатура типов запросов фиксирована.
При переходе к сложным многосвязным структурам и произвольным запросам начинают всплывать недостатки модели. Прежде всего, это медленный доступ к данным нижних уровней иерархии, что нетрудно заметить на примерах запросов с XML и в особенностях реализации индексов СУБД, поддерживающих XML в качестве встроенного типа. В тех же примерах видна и чёткая ориентация структур на определённые типы запросов, что исключает универсальность использования одной и той же БД разными типами приложений.
С теоретической точки зрения, используемая иерархическими СУБД модель графов ограничена деревьями, что сужает область её применения. Если структура связей сложна, то попытка втиснуть эту сложность в прокрустово ложе иерархий рождает на свет громоздкие описания, трудные для понимания специалистами и пользователями.
Сетевая модель
Сетевая модель, также относящаяся к теоретико-графовым, явилась развитием подходов, реализованных в модели иерархической. Прежде всего, развитие касается связей между записями, имеющих
двунаправленный характер. Сетевую модель можно представить в виде графа с узлами в виде записей, и рёбрами, отображающими наборы. Направление и характер связи в сетевых БД не являются очевидными, как в иерархических БД, поэтому характеристики и направление связей должны указываться явно при описании БД.
В 1975 году конференция CODASYL (Conference of Data System Languages) стандартизовала базовые понятия и формальный язык описания. Широко известной системой, основанной на сетевой модели данных, являлась СУБД IDMS (Integrated Database Management System), использовавшаяся на мэйнфреймах IBM. В настоящее время IDMS принадлежит компании Computer Associates, имеющей неформальный статус «лавки старьёвщика» в мире софтостроения: как правило, все купленные компанией продукты берутся на сопровождение, но не развиваются, доживая до своего естественного конца.
Несмотря на некоторые интересные особенности и преимущества, до наших дней дожило только небольшое число СУБД, реализующих сетевую модель, например американская Raima (бывшая dbVista) и отечественная КроносПро. На их примере также можно проследить эволюцию программных продуктов класса сетевых СУБД.
СУБД Raima изначально использовалась, как встроенная с достаточно низкоуровневым API для языка Си. Постепенно, в систему был добавлен интерфейс доступа на SQL, а сама СУБД получила возможность работы в режиме клиент-сервер. По-прежнему Raima используется для транзакционных приложений как лёгкое (lightweight) кросс-платформенное решение.
Напротив, развитие СУБД Кронос пошло в сторону аналитической обработки. Это та область, где преимущества сетевой модели могут быть использованы полнее, а недостатки обойдены более просто. Для объяснений нам все же придётся кратко познакомиться с основными понятиями сетевой модели.
Термин запись соответствует аналогичному понятию структурного типа в традиционных языках программирования: record в Паскаль-подобных или struct в наследниках Си.
Набор данных служит для связывания двух типов записей отношением «один-ко-многим».
Связи на основе наборов являются по сути физическими ссылками. Это означает, что можно установить связи между двумя любыми экземплярами записей, если у нас имеются их указатели. Не требуется, как в реляционной модели, думать о первичных и внешних ключах уже на стадии логического проектирования. С помощью двух взаимно-обратных наборов реализуется связь «многие-ко-многим».
В СУБД Кронос также реализовано объединение наборов, позволяющее одной записи ссылаться на записи двух и более типов. Такая возможность очень удобна при моделировании. Например, если имеется тип записи «Адрес», который используется записями «Лица» и «Организации», то объединённый набор «Относится к лицу или организации» отобразит все возможные связи.
Реализация связей между записями на базе физических ссылок является более низкоуровневым механизмом, чем ссылочная целостность на основе ключей в реляционной модели, поскольку связи между конкретными экземплярами необходимо задавать явным образом. Но по этой же причине операции соединения имеют более высокое быстродействие.
Поясню на упрощённом примере. Связь между двумя таблицами в реляционной модели осуществляется по значениям, соответственно, первичного и внешних ключей. Для выбранной строки подчинённой таблицы берётся значение внешнего ключа, которое затем ищется среди значений первичного ключа главной таблицы. Если таблица отсортирована в физическом порядке следования значений первичного ключа (так называемый кластерный ключ, подробнее см. «Физическая организация памяти»), то строка данных находится в той же области памяти, что и найденное значение. Если нет, то происходит дополнительный поиск связанной со значением первичного ключа строки по её идентификатору (row id).

Рис. 1. Организация связей между типами записей в сетевой модели
В случае сетевой модели запись одного типа имеет одну или несколько ссылок на записи другого типа; по этой ссылке непосредственно извлекается связанная запись.
Однако, если связи между записями меняются часто, то возрастают накладные расходы на удаление прежних и создание новых ссылок в наборе, что может явиться недостатком на пути достижения требуемого быстродействия.
Действительно, в реляционной модели для модификации связи достаточно изменить значение внешнего ключа или просто обнулить его для удаления связи. Последующая проверка ссылочной целостности
сводится лишь к поиску соответствующего значения первичного ключа, но и её можно принудительно отключать, например, в случае массированной загрузки данных.
Другим недостатком сетевой СУБД является жёсткость задаваемых структур, и, соответственно, более высокая трудоёмкость при реструктурировании схемы БД. Добавление новых типов записей и полей не представляет собой большой проблемы, но изменение связей и разукрупнение записей требуют множества низкоуровневых операций, связанных с физической реорганизацией хранилища.
Было отмечено, что одной из особенностей аналитической обработки является нахождение базы данных в режиме чтения, изменения связей между записями редки и происходят, как правило, только в моменты обновления информации. Поэтому использование сетевой модели в аналитических приложениях может нивелировать влияние указанных недостатков.
Сетевая модель: плюсы и минусы
К преимуществам сетевой модели можно отнести следующие особенности:
О недостатках уже было упомянуто:
Реляционная модель
Теоретические основы реляционной модели многократно и полно изложены в различных монографиях, книгах и статьях, поэтому в рамках данной статьи ограничимся лишь минимальными описаниями. В дальнейшем мы будем расширять их, опираясь на практическую нужду.
Как и положено доминирующей на протяжении десятков лет массово внедрённой парадигме, реляционная модель имеет свой основополагающий миф. Речь, конечно, идёт об известной работе Эдгара Кодда «Реляционная модель данных для больших совместно используемых банков данных», опубликованной в CACM [3] в 1970 году. «Да будет свет!» — сказал Кодд, и появился свет, и начали рождаться реляционные СУБД.
На самом деле, Кодд опирался на существовавшую и проработанную в рамках математической логики ещё в 19 веке теорию отношений. В рамках этой теории было показано, что множество отношений замкнуто относительно некоторых специальных операций, то есть образует вместе с этими операциями абстрактную алгебру. В упрощённой формулировке это означает, что все возможные результаты операций над элементами множества отношений также являются отношениями.
Кроме того, Кодд начал свои публикации раньше, в 1969 году, исследовательским отчётом «Derivability, Redundency, and Consistency of Relations Stored in Large Data Banks» в среде ограниченного круга подписчиков. В дальнейшем концепция эволюционировала, известный эксперт в области СУБД Майкл Стоунбрейкер отмечал, что «можно видеть четыре разных версии» модели:
версия 2, определена в статье по поводу Тьюринговской премии в 1981 г.;
Из сказанного Стоунбрейкером становится понятным, что Кодд, как и положено учёному, в течение десятилетий продолжал исследования, пересматривая свои подходы и концепции. И полнота реализации теории в промышленных СУБД волновала её автора в меньшей степени, потому что «дюжина Кодда» до сих пор является актуальной для оценки соответствия, а последние стандарты SQL полностью не реализованы ни в одном продукте.
Таким образом, начиная изучать предмет данной главы, необходимо принять к сведению, что существуют два мира с условными названиями «реляционная модель» и «промышленные РСУБД», и эти два мира пересекаются, но не полностью, создавая, в частности, проблемы переносимости приложений между СУБД разных производителей.
Реляционная модель, как и другая, более известная программистам — объектная, относится к логическим. Определённые в рамках модели структуры, операции над ними и задаваемые ограничения не зависят от способов реализации физической организации данных и управления ими. Тем не менее, каждая СУБД имеет свои особенности физической организации, поэтому одна и та же схема данных в рамках реляционной модели может иметь специфические параметры и опции, оптимизирующие работу с данными. Например, соответствующая понятию «отношение» таблица может быть организована в виде кластера, сегмента памяти (кучи), материализованной проекции, секционированной таблицы. К такого рода неоднозначности мы вернёмся в разделе, посвящённом проектированию.
Что же представляет собой отношение с более формальной точки зрения? Обратимся к первоисточнику.
является отношением на этих n множествах, если представляет собой множество кортежей степени n, у каждого из которых первый элемент взят из множества S1, второй — из множества S2 и т.д. Мы будем называть Sj j- тым доменом R. Говорят, что такое отношение R имеет степень n. Отношения степени 1 часто называют унарными, степени 2 — бинарными, степени 3 — тернарными и степени n — n-арными.
Для лучшего понимания столь лаконичного определения воспользуемся его графической интерпретацией.

Рис. 2. Отношение, как множество кортежей, заданных на доменах
Геометрический смысл данного выше определения больше всего напоминает таблицу с зафиксированным типом данных для каждой колонки. По этой причине реляционные СУБД предлагают своим пользователям оперировать не определениями реляционной алгебры, а их адаптированными аналогами (таблицы, строки, столбцы и т. п.). Хотя эти аналоги имеют более низкий уровень абстракции, они легче представляются в головах среднестатистических специалистов, занятых в основном насущными производственными проблемами, а не задачами из курса теории множеств.
Реляционная модель: плюсы и минусы
К преимуществам реляционной модели можно отнести следующие особенности:
Недостатки:
[1] XPath (от англ. XML Path Language) — язык запросов к элементам XML-документа.
[2] MUMPS — Massachusetts General Hospital Utility Multi-Programming System, позднее Multi-User Multi-Programming System, разработка датирована 1966 годом.
Модели организации баз данных
2. Сетевая модель данных. В сетевых БД наряду с вертикальными реализованы и горизонтальные связи. Однако унаследованы многие недостатки иерархической и главный из них, необходимость четко определять на физическом уровне связи данных и столь же четко следовать этой структуре связей при запросах к базе.
3. Реляционная модель. Реляционная модель появилась вследствие стремления сделать базу данных как можно более гибкой. Данная модель предоставила простой и эффективный механизм поддержания связей данных.
Рассмотрим более подробно эти модели данных далее.
Иерархическая модель базы данных

Корневая запись каждого дерева обязательно должна содержать ключ с уникальным значением. Ключи некорневых записей должны иметь уникальное значение только в рамках группового отношения. Каждая запись идентифицируется полным сцепленным ключом, под которым понимается совокупность ключей всех записей от корневой, по иерархическому пути.
Пример
Рассмотрим следующую модель данных предприятия (см. рис. 4.2): предприятие состоит из отделов, в которых работают сотрудники. В каждом отделе может работать несколько сотрудников, но сотрудник не может работать более чем в одном отделе.
Поэтому, для информационной системы управления персоналом необходимо создать групповое отношение, состоящее из родительской записи ОТДЕЛ (НАИМЕНОВАНИЕ_ОТДЕЛА, ЧИСЛО_РАБОТНИКОВ) и дочерней записи СОТРУДНИК (ФАМИЛИЯ, ДОЛЖНОСТЬ, ОКЛАД). Это отношение показано на рис. 4.2 (а) (Для простоты полагается, что имеются только две дочерние записи).

Из этого примера видны недостатки иерархических БД :
Частично дублируется информация между записями СОТРУДНИК и ИСПОЛНИТЕЛЬ (такие записи называют парными), причем в иерархической модели данных не предусмотрена поддержка соответствия между парными записями.
Иерархическая модель реализует отношение между исходной и дочерней записью по схеме 1:N, то есть одной родительской записи может соответствовать любое число дочерних.
Операции над данными, определенные в иерархической модели :
В операции ИЗВЛЕЧЬ допускается задание условий выборки (например, извлечь сотрудников с окладом более 10 тысяч руб.)
Как видим, все операции изменения применяются только к одной «текущей» записи (которая предварительно извлечена из базы данных ). Такой подход к манипулированию данных получил название «навигационного».
Ограничения целостности
Поддерживается только целостность связей между владельцами и членами группового отношения (никакой потомок не может существовать без предка). Как уже отмечалось, не обеспечивается автоматическое поддержание соответствия парных записей, входящих в разные иерархии.