индексация базы данных sql server
Основы индексов в Microsoft SQL Server
В данном материале будут рассмотрены такие объекты базы данных Microsoft SQL Server как индексы, Вы узнаете, что такое индексы, какие типы индексов бывают, как их создавать, оптимизировать и удалять.
Что такое индексы в базе данных?

Индекс — это объект базы данных, который представляет собой структуру данных, состоящую из ключей, построенных на основе одного или нескольких столбцов таблицы или представления, и указателей, которые сопоставляются с местом хранения заданных данных. Индексы предназначены для более быстрого получения строк из таблицы, другими словами, индексы обеспечивают быстрый поиск данных в таблице, что значительно повышает производительность запросов и приложений. Индексы также могут быть использованы и для обеспечения уникальности строк таблицы, гарантируя тем самым целостность данных.
Типы индексов в Microsoft SQL Server
В Microsoft SQL Server существуют следующие типы индексов:
Создание и удаление индексов в Microsoft SQL Server
Перед тем как приступать к созданию индекса его необходимо хорошо спроектировать, для того чтобы эффективно использовать этот индекс, так как плохо спроектированные индексы могут не увеличить производительность, а наоборот снизить ее. Например, большое количество индексов в таблице снижает производительность инструкций INSERT, UPDATE, DELETE и MERGE, потому что при изменении данных в таблице все индексы должны быть изменены соответствующим образом. Общие рекомендации по проектированию индексов мы с Вами рассмотрим в отдельном материале, а сейчас давайте переходить непосредственно к рассмотрению процесса создания и удаления индексов.
Примечание! В качестве SQL сервера у меня выступает версия Microsoft SQL Server 2016 Express.
Создание индексов
Для создания индексов в Microsoft SQL Server существует два способа: первый – это с помощью графического интерфейса среды SQL Server Management Studio (SSMS), и второй – это с помощью языка Transact-SQL, мы с Вами разберем оба способа.
Исходные данные для примеров
Давайте представим, что у нас есть таблица с товарами под названием TestTable, в которой есть три столбца:
Пример создания кластеризованного индекса
Как я уже говорил, кластеризованный индекс создается автоматически, если мы, например, при создании таблицы указываем конкретный столбец в качестве первичного ключа (PRIMARY KEY), но так как мы этого не сделали, давайте рассмотрим пример самостоятельного создания кластеризованного индекса.
Для создания кластеризованного индекса мы можем у таблицы указать первичный ключ, и тем самым кластеризованный индекс будет создан автоматически или мы можем создать кластеризованный индекс отдельно.
Для примера давайте просто создадим кластеризованный индекс, без создания первичного ключа. Сначала сделаем это с помощью Management Studio.
Открываем SSMS и в обозревателе объектов находим нужную таблицу и щелкаем правой кнопкой мыши по пункту «Индексы», выбираем «Создать индекс» и тип индекса, в нашем случае «Кластеризованный».
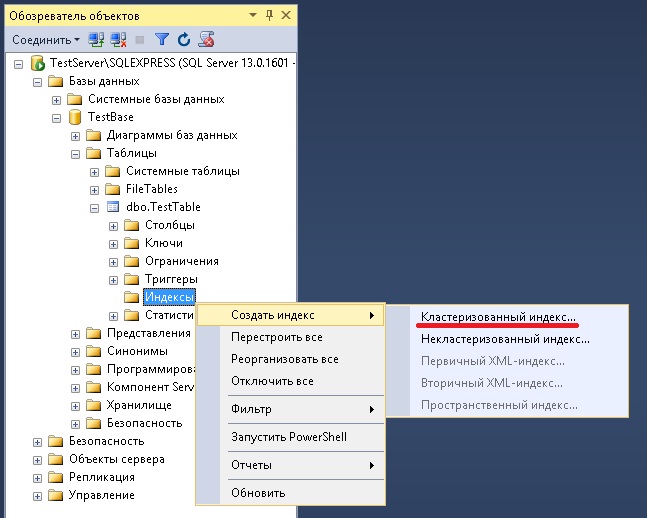
Откроется форма «Новый индекс», где нам необходимо указать имя нового индекса (оно должно быть уникальным в пределах таблицы), также указываем, будет ли этот индекс уникальным, если мы говорим об идентификаторе товара в таблице товаров, то, конечно же, он должен быть уникальным. Потом выбираем столбец (ключ индекса), на основе которого у нас будет создан кластеризованный индекс, т.е. будут отсортированы строки данных в таблице, с помощью кнопки «Добавить».
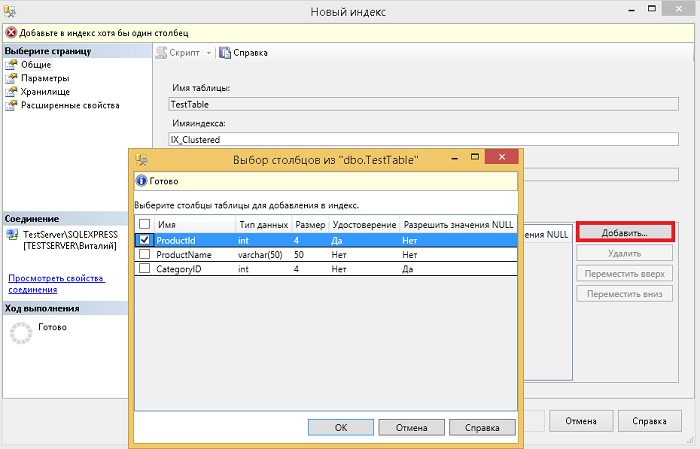
После ввода всех необходимых параметров жмем «ОК», в итоге будет создан кластеризованный индекс.
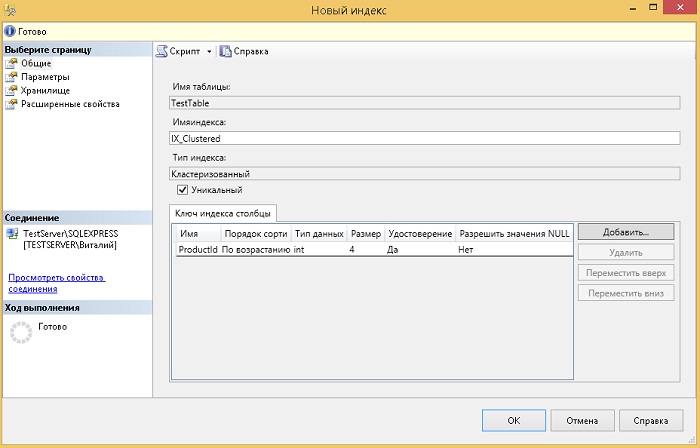
Точно также можно было бы создать кластеризованный индекс, используя инструкцию T-SQL CREATRE INDEX, например, вот так
Или, как мы уже говорили, можно было бы использовать и инструкцию создания первичного ключа, например
Пример создания некластеризованного индекса с включенными столбцами
Сейчас давайте рассмотрим пример создания некластеризованного индекса, при этом мы укажем столбцы, которые не будет являться ключевыми, но будут включаться в индекс. Это полезно в тех случаях, когда Вы создаете индекс для конкретного запроса, например, для того чтобы индекс полностью покрывал запрос, т.е. содержал все столбцы (это называется «Покрытием запроса»). Благодаря покрытию запроса повышается производительность, так как оптимизатор запросов может найти все значения столбцов в индексе, при этом не обращаясь к данным таблиц, что приводит к меньшему числу дисковых операций ввода-вывода. Но помните, что включение в индекс неключевых столбцов влечет за собой увеличение размера индекса, т.е. для хранения индекса потребуется больше места на диске, а также может повлечь и снижение производительности операций INSERT, UPDATE, DELETE и MERGE на базовой таблице.
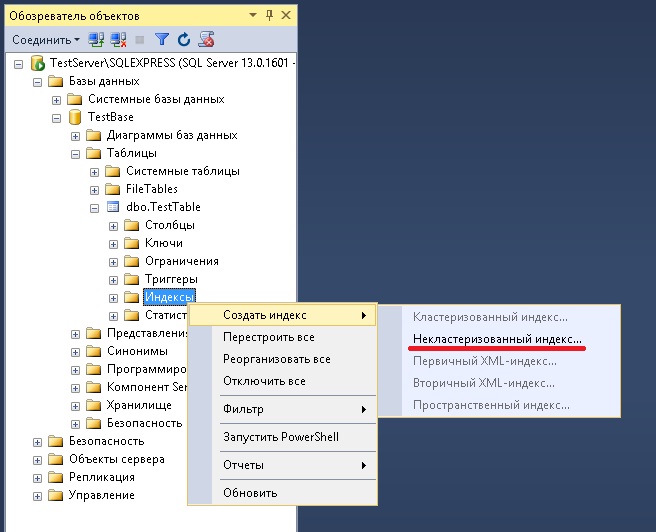
После открытия формы «Новый индекс» мы указываем название индекса, добавляем ключевой столбец или столбцы с помощью кнопки «Добавить», например, для нашего тестового случая давайте укажем CategoryID.
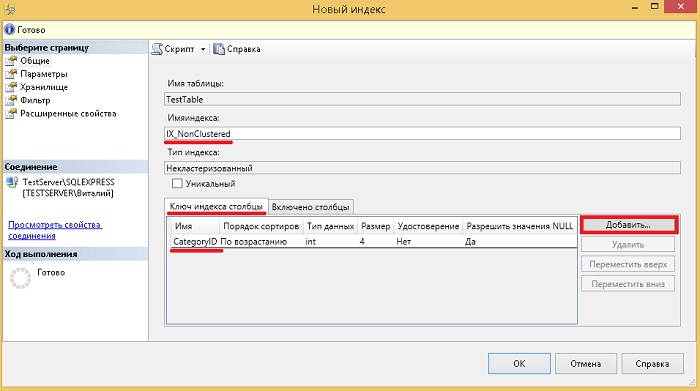
Далее переходим на вкладку «Включено столбцы» и с помощью кнопки «Добавить» добавляем столбцы, которые мы хотим включить в индекс, в нашем случае, например, ProductName.
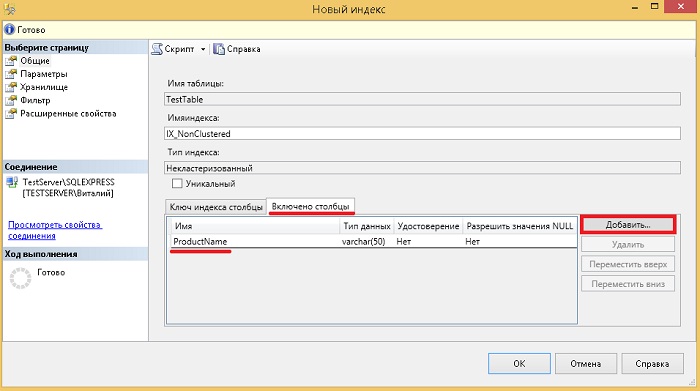
На Transact-SQL это будет выглядеть следующим образом.
Пример удаления индекса в Microsoft SQL Server
Для того чтобы удалить индекс можно щелкнуть правой кнопкой по нужному индексу и нажать «Удалить», затем подтвердить свое действия нажав «ОК».
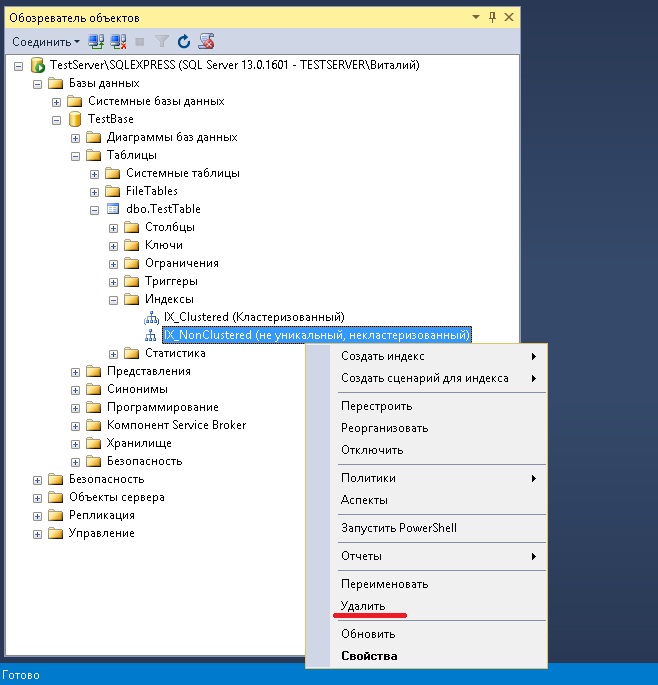
или также можно использовать инструкцию DROP INDEX, например
Следует отметить, что инструкция DROP INDEX неприменима к индексам, которые были созданы путем создания ограничений PRIMARY KEY и UNIQUE. В данном случае для удаления индекса нужно использовать инструкцию ALTER TABLE с предложением DROP CONSTRAINT.
Оптимизация индексов в Microsoft SQL Server
В результате выполнения операций обновления, добавления или удаления данных в таблицах SQL сервер автоматически вносит соответствующие изменения в индексы, но со временем все эти изменения могут вызвать фрагментацию данных в индексе, т.е. они окажутся разбросанными по базе данных. Фрагментация индексов влечет за собой снижение производительности запросов, поэтому периодически необходимо выполнять операции обслуживания индексов, а именно дефрагментацию, к таким можно отнести операции реорганизации и перестроения индексов.
В каких случаях использовать реорганизацию индекса, а в каких перестроение?
Чтобы ответить на этот вопрос сначала необходимо определить степень фрагментации индекса, так как в зависимости от фрагментации индекса тот или иной метод дефрагментации будет предпочтительней и эффективней. Для определения степени фрагментации индекса можно использовать системную табличную функцию sys.dm_db_index_physical_stats, которая возвращает подробные сведения о размере и фрагментации индексов. Например, используя следующий запрос, Вы можете узнать степень фрагментации индексов у всех таблиц в текущей базе данных.
В данном случае нас интересует столбец avg_fragmentation_in_percent, т.е. процентная доля логической фрагментации.
Так вот, Microsoft рекомендует:
Лично я могу добавить следующее, если у Вас небольшая компания и база данных не требует максимальной отдачи в режиме 24 часа в сутки, т.е. она не суперактивная БД, то Вы можете смело периодически выполнять операцию перестроения индексов, при этом даже не определяя степень фрагментации.
Реорганизация индексов
Реорганизация индекса – это процесс дефрагментации индекса, который дефрагментирует конечный уровень кластеризованных и некластеризованных индексов по таблицам и представлениям, физически переупорядочивая страницы концевого уровня в соответствии с логическим порядком (слева направо) конечных узлов.
Для реорганизации индекса можно использовать как графический инструмент SSMS, так и инструкцию Transact-SQL.
Реорганизация индекса с помощью Management Studio
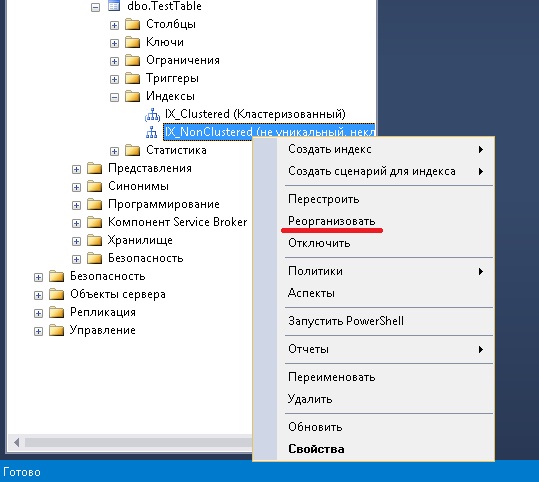
Реорганизация индекса с помощью Transact-SQL
Перестроение индексов
Перестроение индекса – это процесс, при котором происходит удаление старого индекса и создание нового, в результате чего фрагментация устраняется.
Для перестроения индексов можно использовать два способа.
Первый. Используя инструкцию ALTER INDEX с предложением REBUILD. Эта инструкция заменяет инструкцию DBCC DBREINDEX. Обычно для массового перестроения индексов используется именно этот способ.
И второй, используя инструкцию CREATE INDEX с предложением DROP_EXISTING. Можно использовать, например, для перестроения индекса с изменением его определения, т.е. добавления или удаления ключевых столбцов.
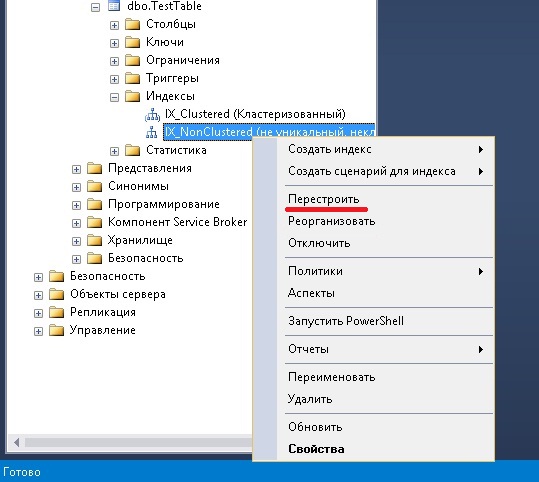
В Management Studio функционал для перестроения также доступен. Правой кнопкой по нужному индексу «Перестроить».
На этом материал по основам индексов в Microsoft SQL Server закончен, если Вас интересует SQL и T-SQL, рекомендую посмотреть мои видеокурсы по T-SQL, с помощью которых Вы «с нуля» научитесь работать с SQL и программировать с использованием языка T-SQL в Microsoft SQL Server, удачи!
Регламентные операции на уровне СУБД для MS SQL Server
Краткое содержание:
Инструкция по выполнению регламентных операций на уровне СУБД.
Информация применима к клиент-серверному варианту «1С:Предприятия 8» при использовании СУБД MS SQL Server.
Общие сведения
Одной из часто встречающихся причин неоптимальной работы системы является неправильное или несвоевременное выполнение регламентных операций на уровне СУБД. Особенно важно выполнять эти регламентные процедуры в крупных информационных системах, которые работают под значительной нагрузкой и обслуживают одновременно большое количество пользователей. Специфика таких систем в том, что обычных действий, выполняемых СУБД автоматически (на основании настроек) оказывает недостаточно для эффективной работы.
Если в работающей системе наблюдаются какие-либо симптомы проблем с производительностью, следует проверить, что в системе правильно настроены и регулярно выполняются все рекомендуемые регламентные операции на уровне СУБД.
Выполнение регламентных процедур должно быть автоматизировано. Для автоматизации этих операций рекомендуется использовать встроенное средства MS SQL Server: Maintenance Plan. Существуют так же другие способы автоматизации выполнения этих процедур. В настоящей статье для каждой регламентной процедуры дан пример ее настройки при помощи Maintenance Plan для MS SQL Server 2005.
Для MS SQL Server рекомендуется выполнять следующие регламентные операции:
Рекомендуется регулярно контролировать своевременность и правильность выполнения данных регламентных процедур.
Обновление статистик
MS SQL Server строит план запроса на основании статистической информации о распределении значений в индексах и таблицах. Статистическая информация собирается на основании части (образца) данных и автоматически обновляется при изменении этих данных. Иногда этого оказывается недостаточно для того, что MS SQL Server стабильно строил наиболее оптимальный план выполнения всех запросов.
В этом случае возможно проявление проблем с производительностью запросов. При этом в планах запросов наблюдаются характерные признаки неоптимальной работы (неоптимальные операции).
Для того, чтобы гарантировать максимально правильную работу оптимизатора MS SQL Server рекомендуется регулярно обновлять статистики базы данных MS SQL.
Для обновления статистик по всем таблицам базы данных необходимо выполнить следующий SQL запрос:
Обновление статистик не приводит к блокировке таблиц, и не будет мешать работе других пользователей. Статистика может обновляться настолько часто, насколько это необходимо. Следует учитывать, что нагрузка на сервер СУБД во время обновления статистик возрастет, что может негативно сказаться на общей производительности системы.
Приведенный выше запрос обновляет статистики для всех таблиц базы данных. В реально работающей системе разные таблицы требуют различной частоты обновления статистик. Путем анализа планов запроса можно установить, какие таблицы больше других нуждаются в частом обновлении статистик, и настроить две (или более) различных регламентных процедуры: для часто обновляемых таблиц и для всех остальных таблиц. Такой подход позволит существенно снизить время обновления статистик и влияние процесса обновления статистики на работу системы в целом.
Настройка автоматического обновления статистик (MS SQL 2005)
Запустите MS SQL Server Management Studio и подключитесь к серверу СУБД. Откройте папку Management и создайте новый план обслуживания:

Создайте субплан (Add Subplan) и назовите его «Обновление статистик». Добавьте в него задачу Update Statistics Task из панели задач:

Настройте расписание обновления статистик. Рекомендуется обновлять статистики не реже одного раза в день. При необходимости частота обновления статистик может быть увеличена.
Настройте параметры задачи. Для этого следует два раза кликнуть на задачу в правом нижнем углу окна. В появившейся форме укажите имя базу данных (или несколько баз данных) для которых будет выполняться обновление статистик. Кроме этого вы можете указать для каких таблиц обновлять статистики (если точно неизвестно, какие таблицы требуется указать, то устанавливайте значение All).
Обновление статистик необходимо проводить с включенной опцией Full Scan.

Сохраните созданный план. При наступлении указанного в расписании срока обновление статистик будет запущено автоматически.
Очистка процедурного КЭШа
Оптимизатор MS SQL Server кэширует планы запросов для их повторного выполнения. Это делается для того, чтобы экономить время, затрачиваемое на компиляцию запроса в том случае, если такой же запрос уже выполнялся и его план известен.
Возможна ситуация, при которой MS SQL Server, ориентируясь на устаревшую статистическую информацию, построит неоптимальный план запроса. Этот план будет сохранен в процедурном КЭШе и использован при повторном вызове такого же запроса. Если Вы обновили статистику, но не очистили процедурный кэш, то SQL Server может выбрать старый (неоптимальный) план запроса из КЭШа вместо того, чтобы построить новый (более оптимальный) план.
Таким образом, рекомендуется всегда после обновления статистик очищать содержимое процедурного КЭШа.
Для очистки процедурного КЭШа MS SQL Server необходимо выполнить следующий SQL запрос:
Этот запрос следует выполнять непосредственно после обновления статистики. Соответственно, частота его выполнения должна совпадать с частотой обновления статистики.
Настройка очистки процедурного КЭШа (MS SQL 2005)
Поскольку процедурный КЭШ необходимо очищать при каждом обновлении статистики, данную операцию рекомендуется добавить в уже созданный субплан «Обновление статистик». Для этого следует открыть субплан и добавить в его схему задачу Execute T-SQL Statement Task. Затем следует соединить задачу Update Statistics Task стрелочкой с новой задачей.

В тексте созданной задачи Execute T-SQL Statement Task следует указать запрос «DBCC FREEPROCCACHE»:

Дефрагментация индексов
При интенсивной работе с таблицами базы данных возникает эффект фрагментации индексов, который может привести к снижению эффективности работы запросов.
Рекомендуется регулярное выполнение дефрагментации индексов. Для дефрагментации всех индексов всех таблиц базы данных необходимо использовать следующий SQL запрос (предварительно подставив имя базы):
Дефрагментация индексов не блокирует таблицы, и не будет мешать работе других пользователей, однако создает дополнительную нагрузку на SQL Server. Оптимальная частота выполнения данной регламентной процедуры должна подбираться в соответствии с нагрузкой на систему и эффектом, получаемым от дефрагментации. Рекомендуется выполнять дефрагментацию индексов не реже одного раза в неделю.
Возможно выполнение дефрагментации для одной или нескольких таблиц, а не для всех таблиц базы данных.
Настройка дефрагментации индексов (MS SQL 2005)
В ранее созданном плане обслуживания создайте новый субплан с именем «Дефрагментация индексов».Добавьте в него задачу Reorganize Index Task:

Задайте расписание выполнения для задачи дефрагментации индексов. Рекомендуется выполнять задачу не реже одного раза в неделю, а при высокой изменчивости данных в базе еще чаще – до одного раза в день.
Настройте задачу, указав базу данных (или несколько баз данных) и выбрав необходимые таблицы. Если точно неизвестно, какие таблицы следует указать, то устанавливайте значение All.

Реиндексация таблиц базы данных
Реиндексация таблиц включает полное перестроение индексов таблиц базы данных, что приводит к существенной оптимизации их работы. Рекомендуется выполнять регулярную переиндексацию таблиц базы данных. Для реиндексации всех таблиц базы данных необходимо выполнить следующий SQL запрос:
sp_msforeachtable N’DBCC DBREINDEX (»?»)’
Реиндексация таблиц блокирует их на все время своей работы, что может существенно сказаться на работе пользователей. В связи с этим реиндексацию рекомендуется выполнять во время минимальной загрузки системы.
После выполнения реиндексации нет необходимости делать дефрагментацию индексов.
Настройка реиндексации таблиц (MS SQL 2005)
В ранее созданном плане обслуживания создайте новый субплан с именем «Реиндексация». Добавьте в него задачу Rebuild Index Task:

Задайте расписание выполнения для задачи реиндексирования таблиц. Рекомендуется выполнять задачу во время минимальной нагрузки на систему, не реже одного раза в неделю.
Настройте задачу, указав базу данных (или несколько баз данных) и выбрав необходимые таблицы. Если точно неизвестно, какие таблицы следует указать, то устанавливайте значение All.

Контроль выполнения регламентных процедур на уровне СУБД
Необходимо осуществлять регулярный контроль выполнения регламентных процедур на уровне СУБД. Ниже приведен пример контроля выполнения плана обслуживания для MS SQL Server 2005.
Откройте созданный вами план обслуживания и выберите из контекстного меню пункт «View History»:

Откроется окно с протоколом выполнения всех заданных регламентных процедур.

Успешно выполненные задачи и задачи, выполненные с ошибками, будут помечены соответствующими иконками. Для задач, выполненных с ошибками, доступна подробная информация об ошибке.
Все, что необходимо знать про индексы MS SQL

Предлагаем расширить знания об индексах в MS SQL Server. Получите полное представление о них, преимуществах использования, структуре. Узнаете, как создавать индексы, оптимизировать и удалять. Все самое полезное читайте в одной статье.
Что такое индексы в sql server
Разберемся в понятии индексов (indexes) – это особые таблицы, используемые поисковыми системами для поиска данных. Их активное использование играет важнейшую роль в повышении производительности sql серверов.
Словно указатель в грамотно составленной книге, индекс помогает быстро получить доступ к строкам требуемых данных в таблице, соответствующих запросу. Таким образом, их использование позволяет ускорить выполнение требуемого запроса.
К примеру, для получения всех страниц в книге, касающихся выбранной тематики, сначала нужно обратиться к перечню тем, а затем выбрать нужные страницы. Для этого следует создать индекс по выбранной теме. На ее основе и будут выбираться ссылки на страницы книги по затронутой теме. Используя значения, заданные первичным ключом, sql server найдет нужный индекс и с его помощью быстро выберет все строки с необходимыми данными. Если не использовать индекс, то для поиска информации будет произведено сканирование каждой строки таблицы. Это значительно понизит производительность и увеличит время поиска.
Благодаря индексу процесс поиска данных сокращается за счет их упорядочивания как физического, так и логического. Таким образом, он выглядит как набор ссылок на данные, которые упорядочены по выбранному столбцу таблицы. Такой столбец называется индексированным. Индексы находятся в таблице и по сути выступают полезными внутренними механизмами системы sql-сервера, которые помогают сделать доступ к данным наиболее оптимальным.
Создать стандартный индекс можно на всех столбцах данных, кроме:
Об индексах и кучах
Как только таблица создана и в ней еще нет индексов, она выглядит как куча данных (Heap). В ней все записи хранятся хаотично, без определенного порядка. Потому их и называют «кучами».
Если в таблице необходимо найти определенные данные, sql server просканирует ее (Table scan). Пока в таблице не заданы индексы, поддерживающие ограничения (UNIQUE CONSTRAINT, UNIQUE INDEX или PRIMARY KEY), сервер прочитает все табличные записи (с первой до последней) и выберет те, которые удовлетворяют условиям поиска.
Это демонстрирует базовые функции indexes:
Но не всегда индекс помогает ускорить поиск информации. Для таблиц небольших размеров обычный перебор данных может оказаться намного эффективнее выборки данных по индексам.
Indexes имеют и недостатки:
Но современные методы их создания позволяют не только снижать негативный эффект для вышеперечисленных операций, но и увеличивать скорость выполнения.
Структура
Все индексы имеют одинаковую структуру (structure). Они состоят из:
Все они хранятся в виде сбалансированных B-деревьев (B-tree). Начало такого дерева расположено в корневом узле (находящимся на вершине иерархии) и по сути является «входной дверью». Этот узел имеет одну страницу, в которой содержатся указатели на ключи последующих уровней.
В нижней части иерархии расположены листья дерева (являющиеся конечными узлами). Длины веток одинаковы.
В таком дереве сбалансирована каждая ветка. Благодаря внутреннему механизму при любых изменениях в таблице дерево снова становится сбалансированным.
При формировании запроса к индексированному столбцу подсистема начинает процесс поиска с верхнего узла к нижним, проходя промежуточные и обрабатывая их. На каждом уровне располагается все более развернутая информация о запрашиваемых данных. Как только достигается нижний уровень листьев (leaf level) поиск прекращается, т.к. подсистема запросов находит необходимое значение.
Типы индексов
В Microsoft SQL Server используются следующие индексы: кластерные и некластерные. Рассмотрим их подробнее.
Кластерный индекс
Основная его задача — сохранение табличных данных в виде, отсортированном по значению ключа. Таблице или представлению может быть присущ лишь единственный кластеризованный индекс (Clustered index), потому что табличные данные могут отсортировываться в едином возможном порядке – либо возрастания, либо убывания. По возможности, у каждой таблицы должен быть Clustered index.
Табличные данные будут храниться отсортированными лишь в том случае, когда таблица имеет кластеризованный индекс. Строки табличных данных Clustered index хранит в уровнях листьев.
Если у таблицы нет Clustered index, в момент формирования ограничений PRIMARY KEY и UNIQUE, он формируется автоматически. Когда для таблиц/ куч созданы Nonclustered indexes, то в процессе создания Clustered index все некластеризованные должны быть перестроены.
Содержание листьев зависит от того, индекс кластерный или некластерный. Они могут содержать как табличные данные, так и ссылки, указывающие на строки с ними.
Некластерный индекс
Некластеризованными (Nonclustered) называют такие индексы, которые содержат:
Чтобы обнаружить и получить запрашиваемые данные, для системы подзапросов потребуется совершение дополнительных операций. Содержимое указателей на запрашиваемые данные полностью зависит от того, как они хранятся.
Он может указывать на:
Nonclustered indexes могут быть расширены дополнительными столбцами (included column). А значит, листья будут сохранять значения индексированных и дополнительных неиндексированных столбцов. Это свойство дает возможность обойти определенные ограничения, возложенные на индекс. Данный подход позволяет включать неиндексируемые столбцы либо обходить ограничения на длину индекса.
Главные свойства Nonclustered indexes:
Nonclustered indexes могут создаваться на любых таблицах, в том числе и имеющих кластерный индекс.
Специальные типы индексов
Существует большое число специальных индексов, которые могут быть как кластерными, так и некластерными. Рассмотрим некоторые из них.
Фильтруемый
Фильтруемым (Filtered) индексом называют оптимизированный Nonclustered index, в котором задействован предикат фильтра для индексации части строк в таблице.
Тщательно спроектированный Filtered index способен:
Составной
Составным называют индекс, который:
Простые индексы, в отличие от составных, создаются лишь по единственному столбцу.
Создание составных индексов целесообразно, когда:
Отличным примером может служить телефонный справочник. Он сформирован по фамилии и имени, т.к. много людей имеют одинаковую фамилию. Следовательно, логично будет создать индекс одновременно и по фамилии, и по имени.
Отметим, что наивысший приоритет в процессе сортировки принадлежит первым колонкам, описываемым в CREATE INDEX. Потому, в числе первых должны указываться колонки уникальные. Чтобы индекс был задействован при выборке данных в таблице, сам запрос обязательно должен ссылаться именно на колонку, указанную первой.
Использование составных индексов поможет увеличить производительность за счет того, что для выполнения поиска данных сервер будет сканировать только его, что поможет снизить в таблице число индексов.
Query Optimizer использует их в зависимости от структуры запроса.
Уникальный
Уникальным (Unique) называют индекс, обеспечивающий уникальное значение всех строк по определенному ключу и гарантирующий, что в ключе индекса не будет значений одинаковых, повторяющихся. Для составного ключа понятие уникальности касается всех index columns, но не распространяется на каждый столбец в отдельности.
Если в таблице формируется Unique index одновременно по ряду столбцов, это означает, что абсолютно каждая вариация значений в ключе будет уникальной.
SQL сервером создается автоматически Unique index для ключевых столбцов при формировании ограничений UNIQUE либо PRIMARY KEY. Но он формируется лишь при выполнении условия отсутствия дублей в ключевых столбцах таблицы.
Уникальный индекс создается автоматом при определении ограничений столбца:
Колоночный
Колоночным (Columnstore) называют индекс, в котором данные хранятся в столбцах. Использование Columnstore indexes наиболее целесообразно применять для крупных хранилищ, т.к. они помогут:
Пространственный
Пространственным (Spatial) называют тип расширенного индекса, позволяющего индексировать столбцы с пространственными данными (представленные в типах Geography или Geometry). Spatial index позволяет наилучшим образом использовать определенные операции запросов относительно пространственных столбцов и может создаваться только для них.
Основное условие создания пространственного индекса – наличие PRIMARY KEY для таблиц.
Полнотекстовый
Полнотекстовые (Full-text) индексы применяются для повышения эффективности поиска определенных слов в строках, где данные представлены в символах.
Действия по созданию и обслуживанию Full-text indexes называются «заполнениями». Встречаются заполнения:
Покрывающий
Покрывающим (Covering) называют индекс, позволяющий на конкретный запрос получать запрашиваемую информацию в полном объеме с листьев индекса, не обращаясь к записям таблицы. А значит, в Covering index хранится достаточный объем данных для полноценного ответа на запрос. Потому нет необходимости обращаться к таблице.
Благодаря тому, что ответ можно получить без использования таблицы, покрывающие индексы быстрее остальных. Однако, они становятся достаточно большими, потому злоупотреблять ими не стоит.
XML-индекс
XML – специфический тип индекса, предназначенный для работы с данными в столбцах таблицы, представленными в соответствующем формате. Он делает более эффективной обработку поисковых запросов к ним.
Индексы, используемые в оптимизированных таблицах
Активно используются специальные индексы для таблиц данных:
Создание и проектирование индексов в ms sql server
Польза индексов очевидна, потому и проектироваться они должны крайне аккуратно. Созданные тщательным образом способны улучшить производительность, а непрофессионально – понизить.
Индексы занимают достаточно много дискового места, потому не имеет смысла создавать их больше, чем нужно. Более того, при каждом обновлении строк, автоматически обновляются и индексы. Это в свою очередь может потребовать увеличения ресурсов и грозить снижением производительности.
Очень важно при проектировании соблюдать ряд требований как к базам данных, так и к запросам направленным к ним.
Базы данных
Как сказано выше, производительность системы напрямую зависит от индексов. При поступлении запроса они могут увеличивать ее, обеспечивая быстрый поиск данных либо снижать, т.к. при каждой операции с данными будут изменяться и они, дабы отражать действия, производимые над данными. И не важно, что происходит с ними – добавление, удаление или обновление.
Потому, при разработке плана стратегии по индексированию, необходимо придерживаться советов специалистов:
Запросы к базе данных
При проектировании вторым важным пунктом является понимание и учет того, какие выполняются запросы к базе данных. Необходимо учитывать частоту изменения данных, а также требуется соблюдение определенных принципов:
Способы создания индексов
Предусмотрено создание индексов ms sql server с помощью двух инструментов. В этом помогут:
Как создать кластеризованный индекс
Как отмечалось выше, создание кластеризованного индекса sql сервером происходит автоматически, когда определенный столбец выбирается в качестве первичного ключа (PRIMARY KEY). Когда такого не происходит, следует создать кластерный индекс своими руками.
Чтобы создать Clustered index воспользуемся Management Studio. Для этого следует:
Результатом действий станет кластерный индекс.
Он может быть создан и с помощью инструкций Transact-SQL CREATRE INDEX.
Как создать некластеризованный индекс
Для создания Nonclustered index можно воспользоваться Management Studio либо инструкциями T-SQL.
Создание Nonclustered index с включенными столбцами
Коснемся вопроса, как создать Nonclustered index с условием, что в индекс включены столбцы, которые не являются ключевыми. Такой индекс принято использовать в тех случаях, когда индекс создается под конкретный запрос. К примеру, чтобы индексом покрывался запрос полностью, т.е. включал все столбцы. Вследствие того, что запрос покрыт, увеличивается производительность. Это становится возможным благодаря тому, что оптимизатор запросов может получить все значения столбцов в индексе без обращения к табличным данным. Это ведет к уменьшению числа операций ввода-вывода на диске.
Однако стоит учитывать, что с включением в индекс неключевых столбцов размер его увеличивается. А значит, для его хранения понадобится больше дискового пространства. Это также может снизить производительность операций INSERT, UPDATE, DELETE и MERGE в базовой таблице данных.
Для его создания также воспользуемся Management Studio:
При необходимости, можно легко создать фильтруемый Nonclustered index. Для этого следует воспользоваться T-SQL и в операторе CREATE NONCLUSTERED INDEX в WHERE указать условие фильтрации. Так можно отфильтровать практически любые данные, не важные в запросах.
Удаление индекса
Пришло время узнать о том, какими способами могут удаляться индексы. Для начала воспользуемся Management Studio. Для этого необходимо:
Удаление индексов выполняется и с помощью инструкций T-SQL DROP INDEX (DROP INDEX IX_NonClustered ON TestTable). Однако ею нельзя воспользоваться для удаления тех индексов, которые создавались через формирование ограничений PRIMARY KEY и UNIQUE. Чтобы удалить их, следует воспользоваться инструкцией ALTER TABLE с предложением DROP CONSTRAINT.
Как выполнить изменение значений коэффициента, который установлен по умолчанию
Чтобы внести изменения в значения коэффициента, которые установлены по умолчанию, следует воспользоваться:
Особенности индексов и условий предложения WHERE
Если предложение WHERE инструкции SELECT содержит условие поиска данных с одним столбцом, то необходимо для него создать индекс. Это условие очень важно при высокой селективности (selectivity) условия.
Но он будет абсолютно бесполезным при постоянном уровне селективности от 80% и выше. Простое сканирование табличных данных потребует меньше времени.
Если в часто применяемом запросе условие поиска включает оператор AND, то лучше всего – создать составной индекс, включив в него сразу все табличные столбцы, которые указывались в предложении WHERE инструкции SELECT.
Оптимизация индексов
После выполнения любых действий с табличными данными sql сервером в тот же момент производятся соответствующие правки в индексах. Спустя некоторое время все подобные исправления могут спровоцировать фрагментацию данных. В результате, их может разбросать по всей базе.
Подобная фрагментация данных может стать причиной понижения производительности. Потому крайне важно время от времени проводить дефрагментацию. К подобным операциям по обслуживанию индексов относят реорганизацию и перестроение индексов.
Чтобы понять, какую именно операцию требуется провести – реорганизацию или перестроение, следует выяснить степень фрагментации данных. Она поможет понять, какой способ дефрагментации будет наиболее эффективным и что выбрать.
Чтобы выяснить уровень фрагментации следует воспользоваться системной табличной функцией sys.dm_db_index_physical_stats. Для определения уровня фрагментации всего перечня таблиц для выбранной базы, можете воспользоваться следующим запросом:
SELECT OBJECT_NAME(T1.object_id) AS NameTable,
T1.index_id AS IndexId,
T2.name AS IndexName,
T1.avg_fragmentation_in_percent AS Fragmentation
FROM sys.dm_db_index_physical_stats (DB_ID(), NULL, NULL, NULL, NULL) AS T1
LEFT JOIN sys.indexes AS T2 ON T1.object_id = T2.object_id AND T1.index_id = T2.index_id
Согласно рекомендациям Microsoft, последующие действия будут зависеть от уровня фрагментации:
Реорганизация индекса
Реорганизацией называют процесс устранения фрагментации индекса. В его ходе происходит дефрагментация конечного уровня кластерных и некластерных индексов по таблицам и представлениям. Говоря простым языком – выполняется простое переупорядочивание страниц. В основе переупорядочивания лежит логический порядок конечных узлов (выполняете слева направо).
Если хотите провести реорганизацию – воспользуйтесь:
Перестроение индекса
Перестроением называется операция по устранению фрагментации индекса. Он заключается в устранении старого и формировании нового.
Перестроение индекс выполняется несколькими способами. В этом поможет:
Это вся полезная информация по индексам в Microsoft SQL Server. Изучайте их, а если возникнут вопросы – задавайте. Удачи в изучении и применении indexes ms sql.