Как сделать спектрограмму аудио
Рисуем звук
Пять лет назад на Хабре была опубликована статья «Печать и воспроизведение звука на бумаге» — о системе создания и проигрывания спектрограмм. Затем, полтора года назад Meklon опубликовал квест, в котором такая чёрно-белая логарифмическая спектрограмма стала одним из этапов. По авторскому замыслу, её надо было распечатать на принтере, отсканировать смартфоном с приложением-проигрывателем, и воспользоваться таким образом «надиктованным» паролем. 
У меня в тот момент не было в досягаемости ни принтера, ни смартфона, так что меня заинтересовали два аспекта задачи:
Готовых скриптов для воспроизведения спектрограмм я не нашёл, хотя для обратного преобразования — звука в спектрограмму — легко * находятся примеры, благодаря тому, что функциональность AnalyserNode.getByteFrequencyData() встроена в Web Audio API. А вот для преобразования массива частот в массив PCM для воспроизведения — не обойтись без реализации в скрипте обратного преобразования Фурье (DFT).
*В первом примере в качестве аудиозаписи для спектрального анализа предлагается фрагмент трека »
» от Aphex Twin: в качестве секретного послания музыкант встроил в этот трек селфи, проявляющееся на логарифмической спектрограмме. К сожалению, в этом примере спектрограмма отображается линейно, так что лицо получается растянутым вверху и сжатым внизу.
 » от Aphex Twin: в качестве секретного послания музыкант встроил в этот трек селфи, проявляющееся на логарифмической спектрограмме. К сожалению, в этом примере спектрограмма отображается линейно, так что лицо получается растянутым вверху и сжатым внизу.
» от Aphex Twin: в качестве секретного послания музыкант встроил в этот трек селфи, проявляющееся на логарифмической спектрограмме. К сожалению, в этом примере спектрограмма отображается линейно, так что лицо получается растянутым вверху и сжатым внизу.По поводу реализации DFT сразу ясно, что такая «числодробилка» на чистом JavaScript будет работать медленно и печально; к счастью, я обнаружил готовый порт библиотеки FFTW («Fastest Fourier Transform in the West») на asm.js — это форма представления низкоуровневого кода, обычно написанного на Си, которую современные браузеры обещают выполнять со скоростью почти как у скомпилированного в машинный код. Обвязку для FFTW, превращающую чёрно-белое изображение в WAV-файл, я взял из ARSS и собственноручно переписал на JavaScript. ARSS принимает изображения, инвертированные по сравнению с PhonoPaper, и я не стал это менять.
Результатом вы можете полюбоваться на tyomitch.github.io/#meklon.png
Внизу видны повторяющиеся горизонтальные полосы — форманты, по положению которых распознаются гласные. Вверху — вертикальные «всплески», соответствующие шумным согласным: более широкие — щелевым (фрикативным), более узкие — смычным. Сонорным же согласным ([р] и [л]) соответствуют «облака» в средних частотах.

Для того, чтобы можно было поиграть со спектрограммой, я приделал примитивную рисовалку, почти целиком скопированную из туториала по рисованию на canvas. Кнопка «Copy» позволяет перевести изображение в красный канал (он игнорируется синтезатором) и попытаться «обвести» звуки.
Википедия пишет: «Считается, что для характеристики звуков речи достаточно выделения четырёх формант». Обведём форманты F2-F4 (F1 почему-то игнорируется синтезатором), и убедимся, что гласные вполне распознаются:

Затем обведём шумные согласные: аффриката [ч] — это [т], плавно переходящее в [ш]; а звонкое [д] от глухого [т] отличается наличием среднечастотных формант. Теперь уже можно различить цифры «шесть» и «де’ить»:

Добавляем тёмно-серым сонорные согласные: заодно заметим, что [р] немного «приподнимает» гласные форманты, а [л] — наоборот, опускает.

Остались недорисованными только губные согласные [б] и [в], но и без них пароль более-менее ясен.
А можно ли нарисовать звук с чистого листа, не обводя спектрограмму аудиозаписи? Скажу честно, у меня не получилось. Может быть, хотите попробовать сами?
Как преобразовать аудиоданные в изображения
Относитесь к обработке звука, как к компьютерному зрению, и используйте аудиоданные в моделях глубокого обучения.
Закройте глаза и прислушайтесь к звукам вокруг вас. Независимо от того, находитесь ли вы в переполненном офисе, уютном доме или на открытом пространстве, на природе, вы можете понять, где находитесь, по звукам вокруг вас. Слух — одно из пяти основных чувств человека. Звук играет важную роль в нашей жизни. Это значит, что организация и использование значений аудиоданных с помощью глубокого обучения — важный для ИИ процесс в понимании нашего мира. Кроме того, ключевая задача обработки звука — дать компьютерам возможность отличать один звук от другого. Эта возможность позволит вычислительным машинам выполнять самые разные задачи: от обнаружения износа металла на электростанциях до мониторинга и оптимизации топливной экономии автомобилей.
Сегодня, специально к старту нового потока курса по машинному обучению делюсь с вами статьей, в которой авторы, в качестве примера определяют вид птиц по их пению. Они находят в записях, сделанных в естественных условиях, фрагменты с пением птиц, и классифицируют виды. Преобразовав аудиоданные в данные изображений и применив модели компьютерного зрения, авторы этой статьи получили серебряную медаль (как лучшие 2 %) на соревновании Kaggle Cornell Birdcall Identification.

Обработка аудио как изображений
Когда врач диагностирует болезни сердца, он либо напрямую слушает сердцебиение пациента, либо смотрит на ЭКГ — описывающую сердцебиение пациента схему. Первое обычно занимает больше времени — время нужно, чтобы прослушать сердце, а на запоминание услышанного тратится больше усилий. Напротив, визуальная ЭКГ позволяет врачу мгновенно усваивать пространственную информацию, она ускоряет выполнение задач.
Те же рассуждения применимы к задачам обнаружения звука. Есть спектрограммы четырёх видов птиц. Прослушать оригинальные отрезки звука можно здесь. Глазами человек тем более мгновенно увидит различия видов по цвету и форме.
Перемещение звуковых волн во времени требует больше вычислительных ресурсов, и мы можем получить больше информации из двумерных данных изображений, чем из одномерных волн. Кроме того, недавнее быстрое развитие компьютерного зрения, особенно с помощью свёрточных нейронной сетей, может значительно улучшить результаты, если рассматривать аудио как изображения, так мы (и почти все остальные участники) и поступили на соревнованиях.
Понимание спектрограммы
Используемое нами специфическое представление изображения называется спектрограммой — это изменяющееся во времени визуальное представление спектра частот сигнала. Звуки могут быть представлены в форме волн, и волны имеют два важных свойства: частоту и амплитуду, как показано на рисунке. Частота определяет высоту звука, амплитуда — его громкость.

Объяснение параметров звуковых волн
На спектрограмме аудиоклипа горизонтальное направление представляет время, а вертикальное направление представляет частоты. Наконец, амплитуда звуков определённой частоты, существующих в определённый момент, представлена цветом точки, который обозначается соответствующими координатами x-y.
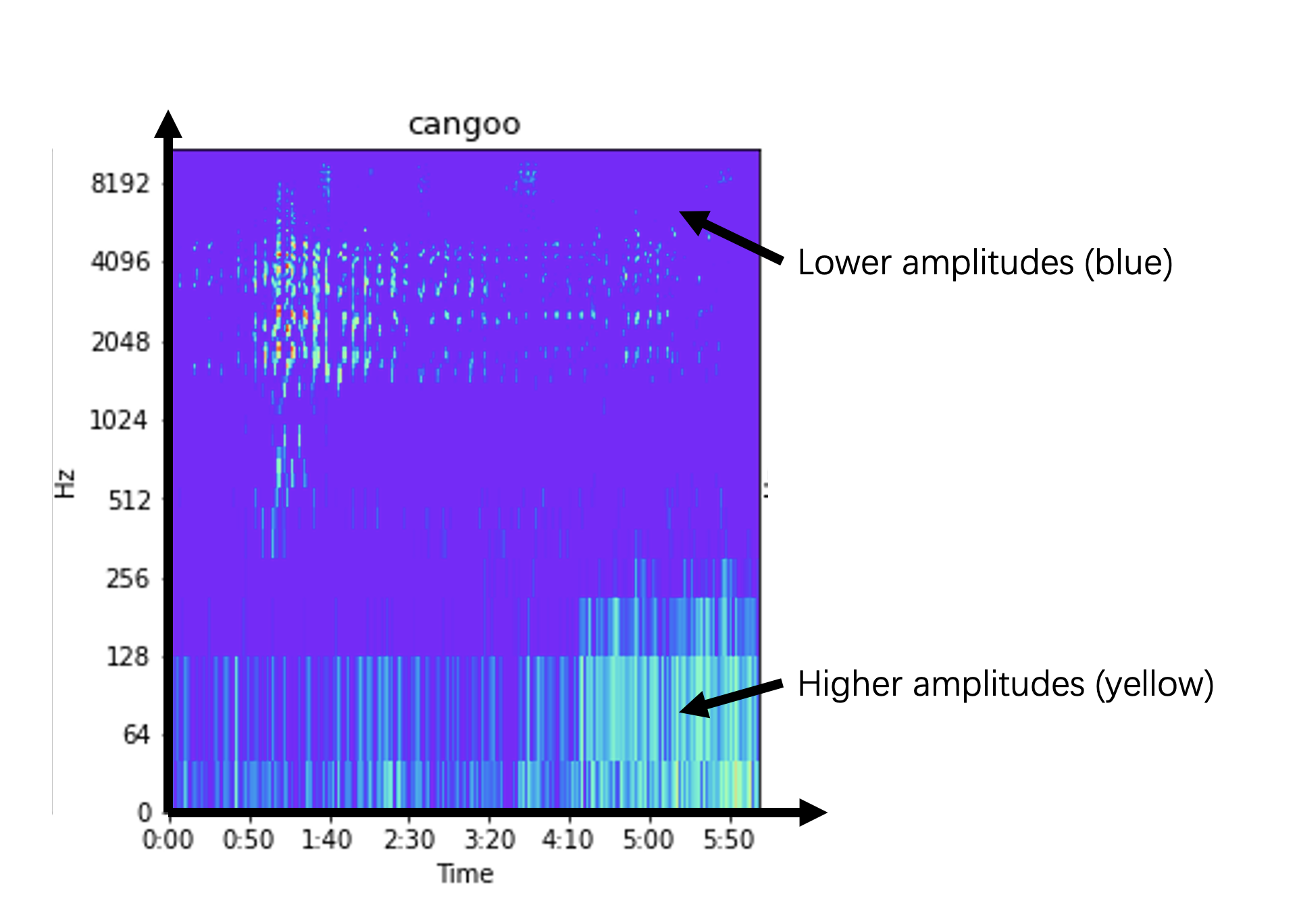
Чтобы понять, как частоты отражаются в спектрограммах, посмотрите на трёхмерную визуализацию, которая демонстрирует амплитуду с помощью дополнительного измерения. По оси X отложено время, а по оси Y — значения частот. Ось z — это амплитуда звуков частоты координаты y в момент координаты x. По мере увеличения значения z цвет меняется с синего на красный, получается цвет, который мы видели в предыдущем примере 2D-спектрограммы.
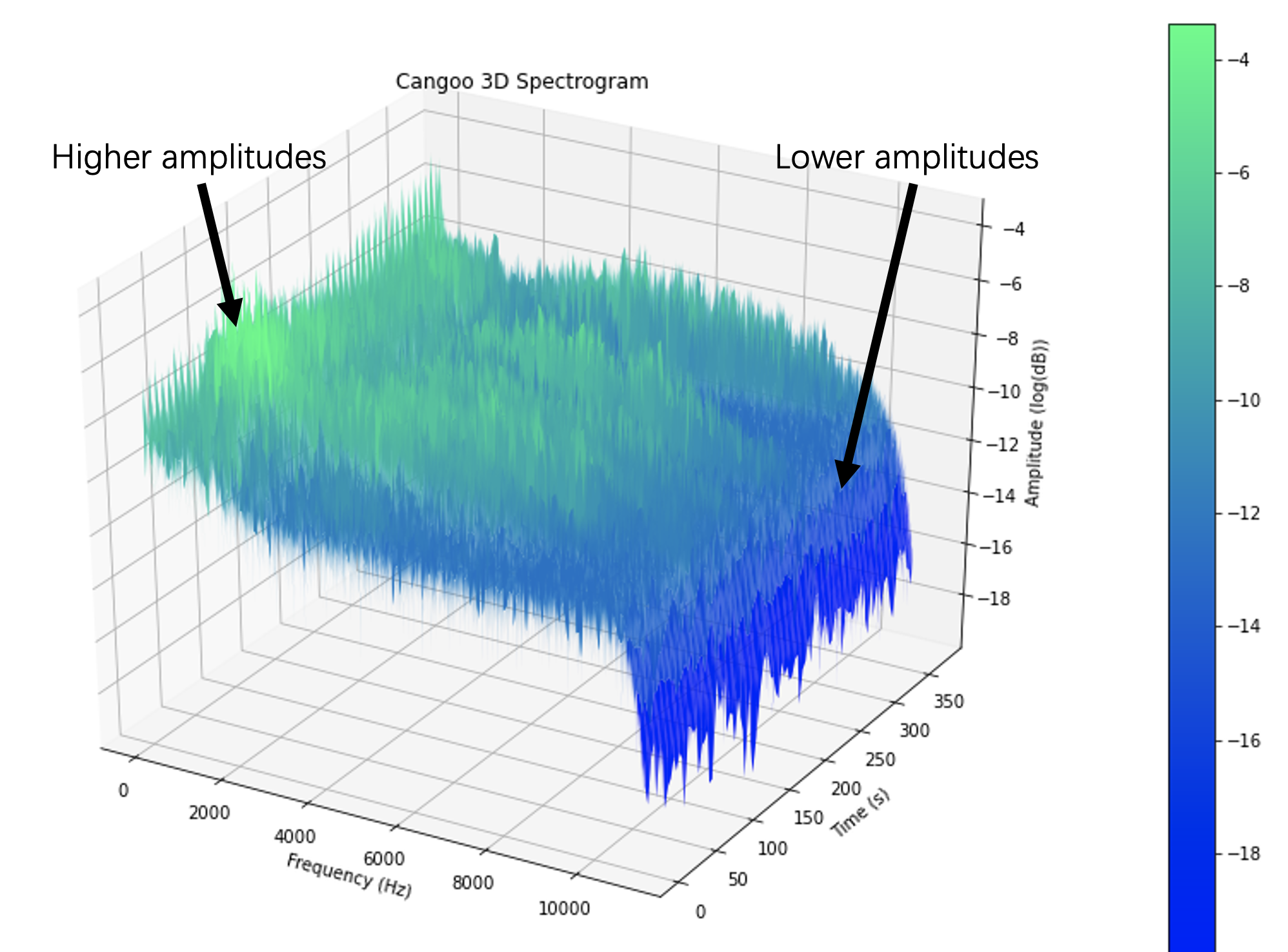
Визуализация трёхмерной спектрограммы
Спектрограммы полезны, потому что они показывают именно ту информацию, которая нам нужна: частоты, особенности, которые формируют форму слышимого нами звука. Разные виды птиц и все издающие звуки объекты имеют свой собственный уникальный частотный диапазон, поэтому звуки кажутся разными. Наша модель просто должна научиться различать частоты, чтобы достичь идеальных результатов классификации.
Шкала мел и её спектрограмма
Мел — психофизическая единица высоты звука, применяемая главным образом в музыкальной акустике. Название происходит от слова «мелодия». Количественная оценка звука по высоте основана на статистической обработке большого числа данных о субъективном восприятии высоты звуковых тонов.

Спектрограмма на мел-шкале — это просто спектрограмма с частотами, измеренными в мел.
Как мы используем спектрограмму?
Для создания мел-спектрограммы из звуковых волн мы воспользуемся библиотекой librosa.
Где y обозначает необработанные данные волны, sr обозначает частоту дискретизации аудио-сэмпла, а n_mels определяет количество полос мел в сгенерированной спектрограмме. При использовании метода melspectrogram вы также можете установить параметры метода f_min и f_max. Можно установить Then и преобразовать спектрограмму в спектрограмму мел, выражающую амплитуду на прямоугольной шкале, к децибелам с помощью метода power_to_db.
Чтобы визуализировать сгенерированную спектрограмму, запустите код:
В качестве альтернативы: если вы используете графический процессор, то можете ускорить процесс генерации спектрограммы с помощью библиотеки torchlibrosa.
Резюме
В заключение скажу, что мы можем воспользоваться преимуществами последних достижений компьютерного зрения в задачах, связанных со звуком, путём преобразования данных аудиоклипов в данные изображения. Мы достигаем этого с помощью спектрограмм, показывающих сведения о частоте, амплитуде и времени аудиоданных в изображении. Использование шкалы мел и спектрограммы шкалы мел помогает компьютерам имитировать человеческий слух, чтобы различать звуки разных частот. Для генерации спектрограмм мы могли бы воспользоваться библиотекой librosa или torchlibrosa для ускорения GPU на Python. Рассматривая таким образом задачи, связанные со звуком, мы можем создавать эффективные модели глубокого обучения для выявления и классификации звуков, так же, как, например, врачи диагностируют сердечные заболевания с помощью ЭКГ.
Как нейронная сеть SincNet выделяет значимые частоты в звуке через Back Propagation
Недавно вышла одна очень интересная статья «Speaker Recognition from raw waveform with SincNet», в которой была описана end-to-end архитектура нейронной сети для распознавания говорящего по голосу. Ключевая особенность этой архитектуры — специальные одномерные сверточные слои, которые имеют всего два параметра с четкой интерпретацией. Интерпретируемость параметров нейронной сети — дело довольно затруднительное, поэтому эта статья привлекла мой интерес.

Если заинтересовало описание идеи этой статьи, а также почему эта идея близка по смыслу к построению мел-спектрограмм, то милости прошу под кат.
Отмечу, что все изображения, используемые в этом посте либо взяты из исходной статьи, либо их можно получить с помощью Jupyter Notebook’а, хранящегося в этом репозитории.
Авторами описываемой статьи был выложен исходный код на гитхаб, с ним можно ознакомиться здесь.
Мел-спектрограммы
Чтобы понять суть этой статьи, давайте сначала вспомним, что такое мел-спектрограмма, как ее получить и в чем ее смысл. Если эта тема вам знакома, то эта часть будет не очень интересной. Ее вычисляют по обычной спектрограмме, построенной с помощью оконного преобразования Фурье:

Суть этой операции в последовательном применении преобразования Фурье к коротким кусочкам речевого сигнала, домноженным на некоторую оконную функцию. Результат применения оконного преобразования — это матрица, где каждый столбец является спектром короткого участка исходного сигнала. Посмотрите на пример ниже:

Эксперименты ученых показали, что человеческое ухо более чувствительно к изменениям звука на низких частотах, чем на высоких. То есть, если частота звука изменится со 100 Гц на 120 Гц, человек с очень высокой вероятностью заметит это изменение. А вот если частота изменится с 10000 Гц на 10020 Гц, это изменение мы вряд ли сможем уловить.
В связи с этим была введена новая единица измерения высоты звука — мел. Она основана на психо-физиологическом восприятии звука человеком, и логарифмически зависит от частоты:


Собственно, мел-спектрограмма — это обычная спектрограмма, где частота выражена не в Гц, а в мелах. Переход к мелам осуществляется с помощью применения мел-фильтров к исходной спектрограмме. Мел-фильтры представляют из себя треугольные функции, равномерно распределенные на мел-шкале. В качестве примера здесь изображены 10 мел-фильтров (на практике их берут больше, здесь их мало для наглядности):

При переводе в частотную шкалы, те же самые фильтры будут выглядеть так:

Каждый столбец исходной спектрограммы скалярно умножается на каждый мел-фильтр (размещенный на частотной шкале), после чего получается вектор чисел, по размеру равный количеству фильтров. На картинке ниже изображен один из столбцов спектрограммы (значения амплитуды переведены в логарифмический масштаб для наглядности, то, что на картинке кодировалось цветом, здесь отражено по оси ординат) и два мел-фильтра, с помощью которых строится мел-спектрограмма:

В результате таких преобразований значения из низких частот спектрограммы остаются практически неизменными на мел-спектре, а в высоких частотах происходит усреднение значений из более широкого диапазона. В качестве примера предлагаю посмотреть на мел-спектрограмму, построенную по предыдущей спектрограмме с использованием 64 мел-фильтров:

Резюмируя все вышесказанное: на мел-спектрограмме сохраняется больше информации, которая хорошо воспринимается и различается человеком, чем на обычной спектрограмме. Иными словами, такое представление звука больше сфокусировано на низких частотах, и меньше — на высоких.
При чем же здесь SincNet?
Вспомним, что мел-шкала была создана на основе человеческого психо-физического восприятия звука. Но что если мы хотим выбрать другие полосы частот, которые нас интересуют больше чем остальные в какой-либо конкретной задаче? Как выбрать самый лучший набор фильтров для решения какой-либо задачи?
Именно эту задачу и решает предложенная авторами архитектура.
Авторы рассматривают в качестве фильтра следующую функцию:

 в этой формуле — это прямоугольная функция. Такой фильтр задает диапазон частот от
в этой формуле — это прямоугольная функция. Такой фильтр задает диапазон частот от  до
до  . Вот ее график:
. Вот ее график:

С помощью обратного преобразования Фурье для этой функции можно получить ее аналог во временной области:



Функция  — это импульсная характеристика идеального полосового фильтра, который нельзя реализовать практически, поэтому авторы усекают эту функцию окном Хэмминга. В цифровой обработке сигналов такой подход называется синтезом фильтров методом окон.
— это импульсная характеристика идеального полосового фильтра, который нельзя реализовать практически, поэтому авторы усекают эту функцию окном Хэмминга. В цифровой обработке сигналов такой подход называется синтезом фильтров методом окон.
Усеченный окном вариант функции  авторы предлагают использовать в качестве шаблона для всех сверток, применяемых к сырым аудио данным. Эта функция дифференцируема по параметрам и , а значит ее можно использовать при оптимизации параметров сети методом обратного распространения ошибки.
авторы предлагают использовать в качестве шаблона для всех сверток, применяемых к сырым аудио данным. Эта функция дифференцируема по параметрам и , а значит ее можно использовать при оптимизации параметров сети методом обратного распространения ошибки.
По теореме о свертке, свертка исходного сигнала с функцией эквивалентна умножению спектра исходного сигнала на функцию  . Грубо говоря, выполняя свертку исходного сигнала с функцией , мы «обращаем внимание» нейронной сети на данный диапазон частот в рассматриваемом сигнале.
. Грубо говоря, выполняя свертку исходного сигнала с функцией , мы «обращаем внимание» нейронной сети на данный диапазон частот в рассматриваемом сигнале.
Конечно, здесь не применяется преобразование Фурье и явно нейросети не сообщаются конкретные значения спектра в диапазоне  . По всей видимости, задача извлечения спектральных характеристик возлагается на следующие блоки, расположенные в нейронной сети.
. По всей видимости, задача извлечения спектральных характеристик возлагается на следующие блоки, расположенные в нейронной сети.
Из достоинств такого подхода, авторы отмечают следующее:
Выводы
Фильтров, с помощью которых преобразуются спектрограммы, существуют много. Например, кроме описанных мел-фильтров, есть еще барк-фильтры (почитать можно здесь и здесь). По крайней мере барк — это тоже психофизическая величина, подобранная «под человека».
В своем исследовании авторы предложили метод, по которому можно заставить нейронную сеть самостоятельно выбрать наиболее подходящие диапазоны частот в процессе обучения в зависимости от набора данных. Как по мне, это очень похоже на процесс построения мел-спектрограммы, при котором больший приоритет отдается низким частотам. Вот только мел-спектрограммы придумали на основе человеческого восприятия звука, а в предложенном методе нейросеть сама решает, что важно, а что нет.