Soc что это
Soc что это
Что такое SOC и для чего он нужен компаниям
Определение и задачи SOC
SOC (Security Operations Center, или Центр обеспечения безопасности) – то, что объединяет людей, процессы и технологии в достижении глобальной цели: снижение рисков через повышение киберзащиты в организации. Но прежде всего SOC – это команда экспертов по безопасности, которые вооружены технологиями обнаружения, анализа, подготовки отчетов и предотвращения киберугроз.
SOC можно сравнить с работой команды пожарных или медиков на скорой помощи. Киберспециалисты в SOC, как и сотрудники экстренных служб, помогают в чрезвычайной ситуации: оперативно появляются в нужном месте, анализируют угрозы и принимают соответствующие меры. Еще их объединяет стремление не допустить подобные инциденты.

SOC – это непрерывные потоки информации, которые обрабатывают и компьютерные системы, и эксперты
Задачи SOC
Самое трудоемкое в работе SOC – постоянно анализировать большие объемы данных. Центр обеспечения безопасности собирает, хранит и анализирует от десятков до сотен миллионов событий безопасности ежедневно. Не забываем, что все это контролируют эксперты: они включаются в работу, когда нужно решить, что делать с найденной угрозой.
Зачем SOC нужен компаниям?
Непрерывный контроль за безопасностью организации. У киберугроз и киберпреступников, которые за ними стоят, нет рабочего времени, выходных и обеденных перерывов. Оперативно выявлять инциденты безопасности помогут только постоянный мониторинг и сканирование сетевой активности. Чем быстрее организация реагирует на кибератаки, тем меньше она рискует безопасностью.
Как внедрить SOC в организации
Создание современного Центра обеспечения безопасности требует намного большего, чем просто поиск подходящего оборудования и специалистов. Работа над SOC превратится в непрерывный процесс, он поможет организации оперативно реагировать на постоянно возникающие угрозы безопасности, идти в ногу с технологиями и создавать комфортную среду, в которой легко поддерживать безопасность и производительность. С чего начать?
Оцените потенциал организации
Перед тем, как строить собственный Центр обеспечения безопасности, оцените потенциал организации и составьте подробный план по рискам. Приготовьтесь к тому, что столкнетесь с непрерывным потоком предупреждений о безопасности, в том числе ложных. А команда экспертов будет перегружена данными об угрозах и не всегда сможет эффективно их нейтрализовать и предупреждать.
Чтобы оценить потенциальные угрозы, ответьте на три ключевых вопроса:
Какие угрозы опасны для бизнеса?
Как выглядит каждая из этих угроз?
Как SOC будет их обнаруживать и блокировать?
Организация должна быть заинтересована в том, чтобы определить источники данных, которые помогут оперативно обнаруживать, блокировать и в будущем предупреждать угрозы. Основная информация поступает через события безопасности и сетевую активность, средства анализа угроз, инструменты авторизации. Дальше они попадают на платформу разведки безопасности, которая консолидирует сведения об угрозах, сопоставляет, идентифицирует и предупреждает о них экспертов SOC. И на последнем этапе в работу включается система управления и регистрации тикетов.
Помните о том, что нет организаций с неограниченными ресурсами для постоянной поддержки SOC. Рабочая нагрузка на Центр будет расти, и вам придется разрабатывать свои инструменты, которые позволят как минимум различать реальные и ложные инциденты безопасности.

Приготовьтесь к тому, что информационная нагрузка на экспертов увеличится
Соберите команду экспертов
Работа команды экспертов по безопасности зависит от организации, ее целей и потребностей. Это может быть служба безопасности, постоянная команда внутри организации, внешняя команда ИТ-специалистов и специалистов по кибербезопасности или комбинированный вариант.
В Центр обеспечения безопасности следует нанимать квалифицированный и сертифицированный персонал. Так как проблемы и угрозы постоянно меняются, вам нужны люди, которые быстро учатся, легко адаптируются и могут мыслить нестандартно там, где нужно оперативно принимать решения. Лучше всего привлекать в SOC действующих сотрудников из IT-подразделения.
Будьте в курсе новых угроз
Следите за тенденциями в среде компьютерной безопасности и держите руку на пульсе актуальных отраслевых практик. Старайтесь в числе первых узнавать о новых угрозах и обеспечьте необходимыми знаниями и навыками команду Центра. Методы обнаружения и защиты, которые были эффективными два-три года назад, вероятно, потеряли актуальность и не соответствуют текущим угрозам.
Разработайте модель работы SOC
SOC может работать централизованно или децентрализованно. В первом случае в Глобальный центр обеспечения безопасности (GSOC) компании из отдельных офисов поступают оповещения, видео с камер наблюдения и другая разведывательная информация. В децентрализованной модели региональные SOC функционируют обособленно и передают в главный офис только важную информацию. В любом случае вам нужно установить тесные связи между командами экспертов по безопасности, сотрудниками IT и других подразделений.
Обеспечьте инфраструктуру для поддержки SOC
Оборудование для SOC включает системы контроля доступа, системы обнаружения вторжений, консоли и другое оборудование, а связующим звеном выступает специализированное программное обеспечение. Полностью укомплектованный Центр обеспечения безопасности должен работать в режиме 24/7, иначе в нем нет смысла.
Из инструментов для реализации SOC потребуются:
Удобно использовать их не по отдельности, а комплексно, предварительно интегрировав в бизнес-процессы организации.
Если вы серьезно настроены на внедрение SOC, рекомендуем ознакомиться с электронной книгой Ten Strategies of a World-Class Cybersecurity Operations Center Карсона Циммермана. Обратите внимание на Приложение В с тестом «Нужен ли вам SOC?». Уделите ему 20 минут, и вы поймете, чего стоит ожидать от Центра обеспечения безопасности и насколько вы готовы к его внедрению.
«ИТ Гильдия» предлагает внедрение услуги « Управление обеспечением безопасности » — приложение от ServiceNow поможет выявлять и оперативно реагировать на инциденты безопасности и уязвимости. Оформите заявку на сайте компании, и наши эксперты ответят на интересующие вопросы.
Как быстро запустить свой Security Operation Center (SOC)


Security Operation Center (SOC) становятся все более популярными среди представителей различных секторов экономики. Атаки постоянно совершенствуются, а потому необходим эффективный инструмент, чтобы им противодействовать. Правильно расставленные приоритеты при построении SOC помогают достичь конкретных результатов в короткие сроки. Об этом подробно рассказано в данной статье.
Введение
Сегодня вопросами построения Security Operation Center (SOC) интересуются практически все представители отечественной экономики: от страховых компаний и банков до крупных промышленных предприятий. Такой интерес вызван прежде всего постоянно совершенствующимися атаками и потребностью в современном инструменте противодействия им. Действительно, SOC является одним из ключевых компонентов подразделения информационной безопасности любой организации. В первую очередь он нацелен на мониторинг, детектирование и оперативную реакцию на инциденты, и, как следствие, на сокращение ущерба и финансовых потерь, к которым тот или иной инцидент может привести.
Как расставить приоритеты, с чего стоит начать построение SOC для достижения конкретных результатов в короткие сроки? На эти вопросы мы дадим ответы в этой статье.
Что такое SOC и чем он не является
При построении SOC важно помнить несколько моментов. Security Operation Center — это не только технические средства. Это команда, задача которой обнаруживать, анализировать, реагировать, уведомлять о возникновении и предотвращать инциденты информационной безопасности. Еще один немаловажный компонент SOC — это процессы, поскольку подразумевается взаимодействие между сотрудниками подразделения, отвечающего за мониторинг и реагирование на инциденты, а также между различными подразделениями (например, ИБ и ИТ). От того, насколько качественно выстроены эти процессы, будет зависеть эффективность работы SOC. Технические средства являются лишь инструментами, позволяющими автоматизировать часть процессов, которые функционируют в SOC. Ярким доказательством этому может послужить SOC одной из региональных энергетических компаний, в котором разбор инцидентов осуществляется сотрудниками подразделения без использования средств автоматизации. Но здесь нельзя забывать о том, что конкретно в этом примере поток событий от компонентов инфраструктуры невелик. Если же поток событий довольно большой, без SIEM-системы не обойтись, поскольку скорость реакции на инциденты будет низкой. Таким образом, формула идеального SOC выглядит так: SOC = Персонал + Процессы + Технические инструменты.
Рисунок 1. Функции SOC на основе классификации MITRE

Более того, нельзя ни в коем случае забывать о том, что SOC не является коробочным решением. Это организм, все время эволюционирующий и адаптирующийся к постоянно меняющимся условиям окружающей среды. Для создания такого организма требуется взвешенный подход и множество усилий со стороны его владельца. Мы все прекрасно понимаем, что создание SOC — длительный процесс, который может затянуться на несколько лет. При этом внедрение только средств защиты может занять полгода.
Мы все чаще слышим от своих заказчиков, что SOC у них еще не построен, но задача детектирования инцидентов и реакции на них стоит здесь и сейчас. И возникают вполне закономерные вопросы: с чего стоит начать, чтобы реализовать часть функций в короткие сроки, какие есть подводные камни и как их обойти, какие процессы стоит внедрить в первую очередь?
SOC с нуля: основные шаги
Формулирование целей, задач и ключевых параметров SOC
Хочется отметить, что зачастую при построении SOC первым делом покупается SIEM-система. Этот класс продуктов ИБ прочно ассоциируется с SOC, а зачастую между SIEM и SOC и вовсе ставится знак равенства. И уже только после этого приобретения создатели SOC в организации приступают к конкретной проработке целей и задач системы. Несмотря на туманные результаты такого подхода, он фактически является наиболее распространенным на практике.
Мы бы рекомендовали чуть отложить радостный момент распаковки коробки с новенькой SIEM и начать именно с проработки ключевых параметров создаваемой системы: ее функций, архитектуры, задач. Сформулировать это необходимо письменно, что поможет архитектору SOC лучше разобраться в вопросе и донести «миссию» и ключевые параметры системы до коллег, руководства и подрядчиков. Хорошо, если данный программный документ получит под собой подпись высшего руководства компании.
Итак, изначально лучше сосредоточиться на основных задачах SOC: проактивное предотвращение инцидентов ИБ, обнаружение и анализ нарушений ИБ в режиме реального времени, реагирование на инциденты, а также снабжение всех заинтересованных сторон в компании информацией о текущем уровне ИБ. Остальные задачи SOC можно считать вспомогательными.
К ключевым параметрам SOC можно отнести:
Отдельно стоит рассматривать такие SOC, которые обслуживают внешние организации. Например, отраслевой, внутри группы компаний, предоставляющий услуги аутсорсинга и т. п. Вопреки ожиданиям, основные подходы при построении таких SOC те же.
Определение основных процессов и процедур в SOC
Мы выделяем более 40 основных функций, которые может выполнять SOC: от сбора данных об инцидентах до взаимодействия с правоохранительными органами, от анализа вредоносного кода до повышения осведомленности сотрудников. Справедливости ради стоит отметить, что мы не встречали в своей практике SOC, успешно исполняющий все эти функции одновременно. Вероятно, таких систем и вовсе не существует.
Как было отмечено выше, в начале строительства SOC справедливо правило «меньше, но лучше». Стоит сконцентрироваться на ключевых задачах, стоящих перед создаваемой системой, и описать процессы, обеспечивающие их выполнение. Нам необходимо как минимум собирать, хранить и обрабатывать данные от ИБ- и ИТ-систем, дать возможность пользователям сообщить о подозрительной активности, расследовать и реагировать на инциденты. Команде SOC нужно иметь актуальную информацию об инфраструктуре, которую она защищает, и эффективно взаимодействовать с коллегами из других подразделений: ИТ- и ИБ-службы, HR, юристы, владельцы систем и пр. Без этого работу SOC представить сложно, поэтому именно с этого и стоит начать.
Процессы и процедуры лучше фиксировать на бумаге. Во всех организациях принят разный уровень документирования, но хотя бы в минимальном виде на этом этапе оно должно быть, чтобы все участники процесса (а их немало) строили одно и то же.
Только теперь, имея представление, что именно вам необходимо автоматизировать, можно переходить к выбору технических средств. Вы увидите, что помимо традиционной SIEM-системы вам понадобится множество дополнительных инструментов, зачастую недорогих или бесплатных, но требующих от персонала SOC определенных знаний. Станут вырисовываться и сами требования к «качеству и количеству» сотрудников.
Обследование инфраструктуры и выбор технических средств
Итак, в компании появилось понимание того, какие процессы необходимо автоматизировать, чтобы подразделение SOC не погрязло в рутинной работе, разбирая все инциденты вручную. Какие же инструменты SOC необходимо использовать для повышения эффективности самого SOC? Мы отмечали ранее, что SOC прочно ассоциируется с SIEM. И это не случайно. Хотя теоретически возможно построение SOC и вовсе без SIEM, на практике такое сегодня встречается крайне редко. Для того чтобы внедрить SIEM и качественно настроить источники информации, необходимо собственно определиться с этими источниками и понять, какие правила корреляции потребуются. Для этого проводится инвентаризация ИТ- и ИБ-активов организации. Как показывает многолетний опыт, в вопросе инвентаризации очень помогают решения класса Vulnerability Management или, как принято их называть, сканеры уязвимостей. Эти решения позволяют в короткие сроки собрать информацию об имеющихся компонентах инфраструктуры и об их уязвимостях, а также в будущем предоставляют возможность отслеживать появление новых компонентов в инфраструктуре организации.
Собрав информацию обо всех имеющихся компонентах, нужно приоритезировать их по степени критичности. Самые критичные источники и должны подключаться к SIEM в первую очередь. Исходя из набора критичных источников, следует определиться с теми правилами корреляции, которые они позволят настроить. Подключение остальных источников и настройку правил корреляции для них можно отложить на второй этап.
При подключении источников к SIEM важно понимать, что не все они смогут предоставить необходимые данные для SIEM. Во многом это зависит от уровня аудита, который настроен на источнике. Например, хорошо известна проблема с подключением баз данных к SIEM, связанная с деградацией производительности. Мы рекомендуем использовать наложенные средства защиты (Database Activity Monitoring / DAM). Данные решения позволяют получать более детальную информацию о каждой транзакции базы данных без ущерба для ее производительности. Аналогичная ситуация может быть и с другими источниками.
Еще одним неотъемлемым инструментом SOC является система Service Desk. У ряда производителей SIEM данный функционал предусмотрен, либо поддерживается интеграция со сторонними производителями. Этот инструмент позволит соблюдать сроки реакции на тот или иной инцидент и оценить эффективность работы подразделения в целом. Если сроки реакции не соблюдаются, то это повод задуматься над корректировкой процессов либо изменением схемы взаимодействия внутри подразделения.
Подбор персонала и определение режимов работы
Как мы уже отмечали, SOC — прежде всего команда, а технические средства — лишь инструмент, который будет работать только в умелых руках. В деле подбора персонала для строящегося SOC стоит исходить из принципа «качество важнее количества». Главная задача заключается в том, чтобы на ключевых позициях были профессионалы высочайшего уровня. Это тот случай, когда лучше нанять одну «звезду», чем двух рядовых аналитиков (особенно в начале создания SOC).
Костяк команды должен быть сформирован как можно раньше, чтобы они поучаствовали во внедрении систем и отладке процессов. Если есть такая возможность, стоит привлечь к работе в SOC часть работающих в компании сотрудников, знающих особенности ее ИТ-инфраструктуры и бизнес-процессов.
Помимо информационных сообщений от ИТ- и ИБ-систем, SOC должен оперативно обрабатывать заявки и звонки пользователей, сообщения от различных подразделений компании, информацию из внешних источников и т. д.
Для обработки входящей информации рекомендуется создать группу первой линии. Она обеспечит разбор входящих данных и выделение в общем потоке в соответствии с принятыми политиками данных, свидетельствующих об инциденте ИБ. Специалисты первой линии не осуществляют глубокого анализа инцидента, их основная задача — оперативно обрабатывать входящую информацию. Если обработка инцидента занимает более нескольких минут, инцидент должен быть эскалирован на вторую линию SOC. Эскалации также подлежат все инциденты с высоким уровнем критичности. Задержка между получением данных первой линией и эскалацией не должна превышать строго определенного времени (например, 20 минут). Специалисты второй линии могут расследовать инцидент от нескольких минут до нескольких недель, собирая детальные данные, привлекая экспертов, восстанавливая последовательность действий и готовя рекомендации по ликвидации последствий инцидента, внедрению контрмер и повышению осведомленности.
Сотрудники второй линии должны обладать более глубокими экспертными компетенциями, чем сотрудники первой. Рекомендуется осуществлять временную ротацию сотрудников внутри SOC: специалисты второй линии должны часть времени работать в первой, а специалисты первой линии, в свою очередь, привлекаться к расследованию части инцидентов. Эти меры направлены на улучшение качества работы SOC, рост профессионального уровня сотрудников и повышение их мотивации. В рамках таких ротаций или в отдельно выделенное время специалисты второй линии (или отдельная команда экспертов) должны совершенствовать метрики, которые используются специалистами первой линии при анализе и эскалации инцидентов, а также анализировать нетипичную и аномальную активность.
Важный вопрос, который часто вызывает много споров, — это режим работы SOC. Ясно, что идеальным вариантом является работа 24/7 в полную мощность. Многие, особенно направленные атаки осуществляются ночью. Это приводит к тому, что при работе в режиме 8/5 полноценная реакция последует только к обеду следующего рабочего дня, когда аналитики разгребут завал данных за ночь (или выходные) и разберутся в ситуации.
Однако наш опыт говорит о том, что затраты на режим 24/7 могут оказаться неподъемными. В сменах работают живые люди, которым необходимы выходные и отпуск. Работа более 8 часов в SOC не желательна, так как требуется внимание и быстрая реакция. Таким образом, мы получаем, что только на первую линию нам необходимо минимум 5 человек на полную ставку (а ведь хорошо бы, чтоб аналитики еще и страховали и перепроверяли друг друга, а также передавали дела между сменами — тут уже получим все 8 человек). Поэтому зачастую формируют промежуточные варианты. Например, 12/5 с двумя пересекающимися сменами по 8 часов в будни и 8 часов в выходные. Аналитики второй линии могут работать при этом в режиме 8/5. На ночь консоль SIEM можно выводить дежурной ИТ-смене, чтобы они отслеживали хотя бы самые критичные ситуации.
Понимая расходы на тот или иной режим работы SOC, а также оценивая актуальные ИБ-риски организации, можно выбрать наиболее оптимальную конфигурацию для каждого конкретного случая.
Обучение сотрудников
Отправить сотрудников на обучение, посвященное техническим средствам, используемым в SOC, — неплохая идея. Такое обучение не сделает из них экспертов, однако позволит быстро сориентироваться в сложных продуктах, таких как SIEM или сканер безопасности. Обучение может провести интегратор или консультанты, участвующие во внедрении системы. Такое обучение включает в себя не только технические моменты, но и процедуры, индивидуальные для конкретного SOC. Все новые сотрудники SOC должны обязательно проходить тренинги, знакомящие их с обязанностями, регламентами и техникой. В противном случае существует риск однажды обнаружить, что, к примеру, первая линия уже 6 месяцев пропускает критичные инциденты. Сбор и распространение внутри команды информации о новых угрозах и трендах в ИБ должны быть не эпизодическими событиями, а отлаженным непрерывным процессом. Важным компонентом обучения является и обмен опытом внутри команды, в том числе в рамках внутренних ротаций.
Использование аутсорсинга
Еще одним способом быстрого старта SOC может стать привлечение сервис-провайдера. Данный метод на российском рынке только набирает популярность, в то время как в Европе и США это явление уже вполне обыденное. Специалисты сервис-провайдера в короткие сроки подключают системы компании-клиента к ядру коммерческого SOC и осуществляют дальнейшее взаимодействие: информируют компанию-клиента о выявленном инциденте, выдают рекомендации по его устранению, а также предоставляют отчет о причинах его появления.
Казалось бы, удобно. Однако здесь все же есть небольшое «но». Сервис-провайдер при предоставлении подобной услуги получает доступ к информации об инфраструктуре своего клиента, записям аудита, логам систем. Иногда даже к учетным записям от используемых им средств защиты информации (в случае подключения также услуги по эксплуатации средств защиты). Такие данные являются лакомым кусочком для потенциальных злоумышленников, и, в случае реализации атаки на сервис-провайдера, они могут получить их. Именно поэтому стоит отдельно озаботиться вопросом проверки соответствия сервис-провайдера принятым нормам обеспечения информационной безопасности (к примеру, группе стандартов ISO 27000).
Еще одним камнем преткновения в случае подключения к аутсорсинговому SOC может послужить набор правил корреляции, используемых сервис-провайдером для выявления тех или иных инцидентов в инфраструктуре. Поскольку эти правила настраиваются на оборудовании и программном обеспечении сервис-провайдера, по сути своей они являются его «интеллектуальной собственностью». Поэтому, когда компания-клиент поймет, что ее собственный SOC построен и готов к работе и решит отказаться от услуг провайдера, ей стоит быть готовой к тому, что провайдер предложит оплатить ту «интеллектуальную собственность», которую он использовал в работе. В ином случае потребуется настраивать все правила корреляции заново на своей SIEM-системе.
Контроль результатов
SOC — сложный организм, качество работы которого оценить не так-то просто. Подходить к оценке в лоб неэффективно: при повышении качества обнаружения критических инцидентов ИБ становится больше, поскольку раньше часть из них просто не детектировались. Аналитики получают новые инструменты, и среднее время расследования сложного инцидента возрастает. Но вместе с тем возрастает и качество.
Однако ввести KPI работы компонентов и целого SOC возможно и даже необходимо. Оценка эффективности требуется не только для системы в целом, но и для каждой подсистемы и сотрудника. Иначе ночная смена будет смотреть YouTube, а не пресекать атаки на сетевую инфраструктуру. KPI делают ясной работу SOC для членов команды и руководства компании. При этом показатели должны быть конкретные, понятные, измеримые, достижимые, но амбициозные и рассчитываться за строго определенный период времени или к определенному сроку.
Так, к примеру, параметр типа «хакеры никогда не должны к нам пролезть» — это не KPI. Как это измерить и что это значит? Примерами KPI могут быть, например, «число просроченных критичных инцидентов не более N за месяц» или «суммарное время простоя ключевой системы по вине инцидентов ИБ не более M минут в квартал» и т. п.
Использование KPI позволит быстро выявлять слабые места созданного «штаба компьютерной обороны» и вносить корректировки в его работу.
Заключение
«Как съесть слона? — По кусочкам!» — эта шутка очень точно отражает процесс строительства SOC. Делать это с наскока не стоит, вас гарантированно ждет провал. Определите цели, доступные ресурсы, составьте план и двигайтесь последовательно, решая задачу за задачей. И в результате вы сможете создать для своей организации мощнейший инструмент по борьбе с инцидентами ИБ, живой и уникальный организм под названием SOC.
Системы на кристалле: от наручных часов до больших боевых роботов
Давным давно, ещё в 1958 году, некто Джон Маккарти написал язык обработки списков под названием LISP. Написал он его потому, что увлекался созданием искусственного интеллекта, и ему нужен был подходящий язык.
С тех пор прогресс, конечно, есть, а вот искусственного интеллекта по-прежнему нет. Я вообще не понимаю, как можно спроектировать и создать такую сложную систему, как мозг и моё самомнение успокаивает только то, что не я один такой: пока никто не придумал, как сделать этот величайший куайн в истории человечества. Но ведь сделают и создадут уже, наконец-то, киборгов.

При создании исккуственного интеллекта одним лиспом не обойдёшься: нужно его на чём-то запускать и железо тоже не стоит на месте. Причём, именно тут, на мой взгляд, прогресс куда более заметен. Оно всегда так, когда пытаешься сравнить прогресс в практической и теоретической части.
С железом люди придумали умную штуку под названием система на кристалле (System On a Chip, SoC). Казалось бы, процессор себе и процессор, ну на кристалле и на кристалле, а ведь по принципу работы — это почти мозг. Он (мозг) — это биологическая система на кристалле: в нашем мозге находится и центральный процессор, и графический процессор, и модуль управления памятью, и сама память как кратковременная, так и долгосрочная, и система ввода-вывода.
Как всем нам известно, прорыв в схемотехнике случился благодаря транзистору, но новый этап наступил в 1978 году, когда Intel выпустила в свет процессор 8086, прародителя нашего счастливого настоящего (изначально, кстати, считалось, что он способен на управление светофором, но никак не компьютером). Но гораздо интереснее, что за два года до этого в Intel создали первую систему на кристалле. Это были «всего лишь» электронные часы Microma LCD watch (ссылка с фотографиями). И внутри у них была система на кристалле под названием Intel 5810 CMOS chip.

Прогресс на часах не остановился, техпроцессы всё улучшались и улучшались, а транзисторы становились меньше и меньше. На место больших вакуумных ламп пришли транзисторы, изготовленные по 1.5-1 микрометровой технологии (если положить в ряд штук 200, то они как раз займут миллиметр на линейке). По этой технологи в Intel в 1985 году сделали процессор третьего поколения 80386 (кстати, а вы знали, что 80386 выпускала не только Intel, но и AMD? :)). Примечательна также и модель 386SL 1990 года, объединяющая на одном кристалле процессор, контроллер шины, контроллер оперативной и внешней кеш-памяти. А в 1995 появился 386EX, в кристалл которого поместили ещё контроллер прерываний, таймеры, счётчики и логику тестирования JTAG, которая используется и по сей день для прошивки и контроля качества микросхем. Несмотря на свои незначительные, по сегодняшним меркам, 25Мгц, процессор 386EX встраивали в спутники. Такая вот система на кристалле на орбите получилась.

В 2007 году Intel анонсировала своё следущее SoC решение Intel EP80579 с кодовым названием Tolapai. На одном кристалле объединили процессор с частотой от 600 Мгц до 1200 Мгц, контроллер памяти и I/O контроллеры, а в качестве killer feature в некоторых вариациях на чипе был расположен QuickAssist для аппаратного шифрования, и его использовали, например, в vpn-решениях. На сайте Intel есть отличная презентация, которая мне очень понравилась (ну, насколько вообще нормальному человеку может понравиться презентация).

Самая современная система на кристалле от Intel выполнена по 32нм технологии и называется Atom Z2460 с кодовым именем Medfield. Уже сегодня на Medfield есть прототип смартфона про который недавно был написан хороший пост и совсем скоро он должен поступить в продажу.

Современность
Системы на кристалле — это совсем непросто, да и видов их уже больше одного. Например, бывают мультипроцессорные системы на кристалле. Есть частный случай SoC под названием сеть на кристалле — с текущим техпроцессом уже совсем не обязательно делать сетевую PCI-карту, достаточно небольшого чипа на материнской плате. И радио на кристалле, которое объединяет на одном чипе и приёмник, и передатчик и занимает совсем немного места, по сравнению с предыдущими решениями.
С точки зрения пользователя, ничего особенного в SoC нет. Подумаешь, раньше была большая плата с кучей разноцветных штук, а теперь этих разноцветных штук мало. Велика разница. Но выгода налицо: из-за того, что все распологается внутри одного кристалла значительно уменьшается энергопотребление (это особенно важно для мобильных и автономных решений) и тепловыделение, а значит, можно обойтись либо пассивным охлаждением, либо слабеньким куллером. Ну и цена будет со временем всё ниже и ниже, что тоже всегда приятно.
У производителя всё обстоит не так просто. Чем сложнее устроено нечто, тем сложнее это нечто делать. Если это нечто ещё и маленькое, то делать это совсем непросто. SoC объединяет в себе много совершенно разных вещей, которые традиционно принято разносить по всей материнской плате, и поэтому нужен оригинальный подход к проектированию, позволяющий располагать большое колличество разнотипных компонентов в маленьком корпусе, причем, так, чтобы при работе они не мешали друг другу.
К сложностям проектирования добавляется и увеличивающийся процент брака, неизбежно возникающий при переходе на более высокий уровень техпроцесса. Впрочем, компания Intel уже строит завод Fab42, который будет изготавливать процессоры не по «допотопному» 32нм техроцессу, а по 14нм! Тогда в SoC можно будет разместить ещё больше транзисторов и тем самым увеличить их производительность. Что тогда произойдёт с обычными микропроцессорами, подумать страшно. Берегись, закон Мура!
Конечно же, Intel не единственный производитель систем на кристалле: их достаточно большое колличество, и среди них такие известные бренды как Atheros, ARM Holdings, Broadcom, Marvell Technology Group, Nokia, NVIDIA, Qualcomm, Sharp и другие.
Ближайшее будущее
Системы на кристалле заменят современные микропроцессоры так же, как микропроцессоры заменили вакуумные лампы — это просто вопрос времени. А там, глядишь, и Терминатора соберут.
Уже сейчас SoC можно встретить везде, например, в наручных часах. Хотя, кто сейчас носит наручные часы? Посмотрите, лучше, на свой смартфон. Если он работает на Android, Meego или iOS, там внутри система на кристалле. Посмотрите на свой роутер или adsl-модем — и там внутри SoC. Плеер? И в нём тоже. Да любой микроконтроллер (и даже всеми нами любимая ардуинка) — это система на кристалле.
SoC уже везде. Пока они занимают нишу устройств, не требующих высокой производительности, но это всего лишь вопрос времени. С нетерпением жду того дня, когда мне больше не нужно будет носить с собой тяжеленный ноутбук (нет, я не хочу компьютер в облаке), а будет хватать телефона, клавиатуру к которому я буду подключать по блутузу, а монитор через WiDi, и производительности этого телефона мне будет хватать для всего.

Руслан Рахметов, Security Vision
Оглавление
Друзья, в предыдущей статье (https://www.securityvision.ru/blog/informatsionnaya-bezopasnost-chto-eto/) мы обсудили основные понятия информационной безопасности и дали определение некоторым терминам. Разумеется, сфера защиты информации не ограничивается описанными определениями, и по мере появления новых статей мы будем всё больше погружаться в данную область и объяснять специфические термины.
Сейчас же давайте представим, как выглядит практическая работа тех, кто профессионально занимается информационной безопасностью, т.е. специалистов по защите информации. Мы часто слышим, что многие значимые расследования хакерских атак ведутся в Ситуационных центрах информационной безопасности, или Центрах SOC (от англ. Security Operations Center). Что такое SOC? Кто там работает и что делает? Какие обязанности выполняют сотрудники SOC, с какими системами и средствами они работают? Правда ли, что без знаний языков программирования не удастся достичь высот в работе в составе команды SOC-Центра, а навыки администрирования информационных систем нужны специалисту по защите информации как воздух? Поговорим об этом ниже.
Пока же нам следует уяснить, из каких специалистов должен состоять Центр SOC? Какие компетенции важны для успешной и плодотворной работы в Ситуационных центрах информационной безопасности? Для начала мы подробнее расскажем, какие именно задачи решаются в SOC-Центрах, поговорим о классификации SOC и о моделях работы и предоставления сервисных услуг заказчикам Ситуационных центров информационной безопасности.
На практике подключение и использование услуг SOC-Центра выглядит следующим образом:
1. Заказчик услуг SOC-Центра, который видит необходимость в аутсорсинге оперативного реагирования на свои инциденты ИБ, обращается к менеджерам SOC с запросом о подключении к сервисам SOC.
2. Менеджеры Центра SOC согласовывают детали подключения информационных и защитных систем заказчика к инфраструктуре SOC-Центра для того, чтобы оперативно обрабатывать поступающие данные без выезда на площадку Заказчика.
4. На площадке Заказчика информационные системы и имеющиеся средства технической защиты настраиваются на пересылку всей значимой с точки зрения ИБ информации во внешний SOC.
5. Во внешнем SOC-Центре входящие данные непрерывно обрабатываются сотрудниками SOC (дежурной сменой), которая состоит, как правило, из следующих специалистов:
Специалист по настройке правил в системах SIEM, SOAR, IRP получает от Заказчика вводные данные о работе информационных систем и затем составляет правила выявления инцидентов и реагирования на них в используемых в SOC-Центре системах. Это могут быть правила корреляции в системах SIEM, которые отвечают за обработку входящих сообщений от систем безопасности заказчика и за выстраивание этих разнородных событий в логически целостную «историю» для поиска возможной атаки. Также настраиваются правила автоматического реагирования, локализации, восстановления информационных систем при помощи SOAR и IRP решений. В случае, если для защиты Заказчиков используются сигнатурные методы обнаружения угроз, например, антивирусы или системы обнаружения/предотвращения компьютерных вторжений, то данный специалист создает для них сигнатуры, т.е. описывает правила, по которым угроза должна быть обнаружена.
Центр мониторинга информационной безопасности (Security Operations Center, SOC)
Центр мониторинга информационной безопасности (Security Operations Center, SOC) — структурное подразделение организации, отвечающее за оперативный мониторинг IT-среды и предотвращение киберинцидентов. Специалисты SOC собирают и анализируют данные с различных объектов инфраструктуры организации и при обнаружении подозрительной активности принимают меры для предотвращения атаки.
Функции SOC
Функции центра мониторинга безопасности могут отличаться в зависимости от масштаба предприятия и его организационной структуры. Чаще всего в сферу ответственности SOC входит:
Способы организации SOC
Центр мониторинга информационной безопасности может существовать как в форме отдельного подразделения компании, так и в виде команды специалистов из разных отделов, совмещающих задачи SOC с другими обязанностями. Также функции SOC могут быть отданы на аутсорсинг специализированным компаниям, осуществляющим удаленный ИБ-мониторинг и реагирование.
Публикации на схожие темы
Пять шагов для предотвращения выгорания ИБ-специалистов
Тест на интеллект для Threat Intelligence
Защита под ключ как сервис
Managed detection and response — отчет за 2021 год
Выбираем подарок ребенку: в тренде «Игра в кальмара» и Huggy Wuggy
Как и зачем мы атакуем собственную антиспам-технологию?
Soc что это
Система на кристалле — в микроэлектронике — электронная схема, выполняющая функции целого устройства (например, компьютера) и размещенная на одной интегральной схеме.
В англоязычной литературе называется System-on-a-Chip, SoC.
В зависимости от назначения она может оперировать как цифровыми сигналами, так и аналоговыми, аналого-цифровыми, а также частотами радиодиапазона. Как правило, применяются в портативных и встраиваемых системах.
Если разместить все необходимые цепи на одном полупроводниковом кристалле не удается, применяется схема из нескольких кристаллов, помещенных в единый корпус (System in a package, SiP). SoC считается более выгодной конструкцией, так как позволяет увеличить процент годных устройств при изготовлении и упростить конструкцию корпуса.
Устройство
Типичная SoC содержит:
Блоки могут быть соединены с помощью шины собственной разработки или стандартной конструкции, например AMBA в чипах компании DMA), то с его помощью можно заносить данные с большой скоростью из внешних устройств напрямую в память чипа, минуя процессорное ядро.
Разработка систем-на-кристалле
Для функционирования системы программное обеспечение не менее важно, чем аппаратное. Разработка, как правило, ведётся параллельно. Аппаратная часть собирается из стандартных отлаженных блоков, для сборки программной части используются готовые драйверы. Применяются средства разработки CAD и интегрированные программные оболочки.
Для того, чтобы удостовериться в правильной работе созданной комбинации блоков, драйверы и программу загружают в эмулятор аппаратной части (микросхему с программируемыми цепями, FPGA). Также требуется задать расположение блоков и разработать межблочные связи.
Перед сдачей в производство аппаратная часть тестируется на корректность с использованием языков VHDL, а для более сложных схем — SystemVerilog, e и OpenVera. До 70 % общих усилий на разработку затрачивается именно на этом этапе.
Системы на кристалле потребляют меньше энергии, стоят дешевле и работают надёжнее, чем наборы микросхем с той же функциональностью. Меньшее количество корпусов упрощает монтаж. Тем не менее, создание одной слишком большой и сложной системы на кристалле может оказаться более дорогим процессом, чем серии из маленьких из-за сложности разработки и отладки и снижения процента годных изделий.
Национальная библиотека им. Н. Э. Баумана
Bauman National Library
Персональные инструменты
SoC (System-on-a-Chip)

Систе́ма на криста́лле (СнК), однокриста́льная систе́ма (англ. System-on-a-Chip, SoC (произносится как «эс-оу-си»)) — в микроэлектронике — электронная схема, выполняющая функции целого устройства (например, компьютера) и размещенная на одной интегральной схеме.
Содержание
История
В 1976 году в Intel создали первую систему на кристалле. Это были «всего лишь» электронные часы Microma LCD watch (ссылка с фотографиями). Начинкой была система на кристалле под названием Intel 5810 CMOS chip. Прогресс на часах не остановился, Со временем, прогрессирующие технологии позволили уменьшить микросхемы и изготовить транзисторы, изготовленные по 1.5-1 микрометровой технологии (если положить в ряд 200, то они как раз займут миллиметр на линейке). По этой технологи в Intel в 1985 году сделали процессор третьего поколения 80386. Примечательна также и модель 386SL 1990 года, объединяющая на одном кристалле процессор, контроллер шины, контроллер оперативной и внешней кеш-памяти. А в 1995 появился 386EX, в кристалл которого поместили ещё контроллер прерываний, таймеры, счётчики и логику тестирования JTAG, которая используется и по сей день для прошивки и контроля качества микросхем. Несмотря на свои незначительные, по сегодняшним меркам, 25Мгц, процессор 386EX встраивали в спутники.
В 2007 году Intel анонсировала своё следущее SoC решение Intel EP80579 с кодовым названием Tolapai. На одном кристалле объединили процессор с частотой от 600 Мгц до 1200 Мгц, контроллер памяти и I/O контроллеры, а в некоторых вариациях на чипе был расположен QuickAssist для аппаратного шифрования, и его использовали, например, в vpn-решениях.
Структура
Если разместить все необходимые цепи на одном полупроводниковом кристалле не удается, применяется схема из нескольких кристаллов, помещенных в единый корпус (англ. System in a package, SiP). SoC считается более выгодной конструкцией, так как позволяет увеличить процент годных устройств при изготовлении и упростить конструкцию корпуса.
Типичная SoC содержит:

В программируемые SOC часто входят также блоки программируемых логических матриц — ПЛМ; а в прогреннаммируемые аналого-цифровые SOC — еще и программируемые аналоговые блоки. Блоки могут быть соединены с помощью шины собственной разработки или стандартной конструкции, например, AMBA[1] в чипах компании ARM. Если в составе чипа есть контроллер прямого доступа к памяти (ПДП), то с его помощью можно заносить данные с большой скоростью из внешних устройств напрямую в память чипа, минуя процессорное ядро.
Особенности проектирования СнК
В большинстве случаев СнК представляет собой цифровую СБИС, которая может также содержать ряд аналоговых блоков. Поэтому для проектирования СнК используются те же методы и средства, что и для СБИС. Эти средства реализованы в виде систем автоматизированного проектирования (САПР), поставляемых компаниями Cadance, Synopsis, Mentor Graphics и др. В качестве элементной базы эти САПР используют библиотеки функциональных элементов, в состав которых входят как простые логические вентили и триггеры, так и макроэлементы, выполняющие более сложные функции: регистры, счетчики, сумматоры, умножители, арифметико-логические устройства и т.д.
При разработке микроконтроллеров в 90-х гг. прошлого века широкое распространение получила концепция создания микроконтроллерных семейств, имеющих одинаковое процессорное ядро и различающихся набором периферийных устройств и объемом внутренней памяти. Для реализации этой концепции при проектировании СБИС микроконтроллеров кроме функциональных библиотек стали использоваться сложно-функциональные блоки (СФ-блоки) — процессоры, таймеры, АЦП, различные интерфейсные блоки (UART, SPI, CAN, Ethernet и т.д). Эти СФ-блоки формировали верхний уровень функциональных библиотек, используемых разработчиками и производителями микроконтроллеров. Они были достаточно жестко ориентированы на конкретную технологию компании-производителя, являясь внутрифирменной материальной ценностью.
Проблемы при повышении сложности
Повышение сложности проектируемых СБИС, жесткие требования к срокам их проектирования (сокращение времени выхода изделия на рынок) поставили перед разработчиками новые проблемы. В сложившихся условиях самостоятельное проектирование разработчиком СнК всех СФ-блоков, входящих в ее состав, не всегда целесообразно. Поэтому в последние годы широкое распространение получила практика разработки отдельных СФ-блоков для их последующего представления на рынок средств проектирования СнК. СФ-блоки, предназначенные для использования в разнообразных проектах, стали называть IP (Intellectual Property) модулями, тем самым подчеркивается, что эта продукция является предметом интеллектуальной собственности. СФ-блоки, используемые при проектировании СнК, имеют две основные формы представления:
Таким образом, разработчик может либо непосредственно «вмонтировать» в структуру проектируемой СБИС топологически готовый СФ-блок, либо использовать имеющуюся модель СФ-блока и выполнить его схемотехническое и топологическое проектирование в составе реализуемой СБИС СнК.
Различные решения для разработки
В процессе проектирования СнК разработчик имеет возможность выбора следующих решений:
Каждый из этих вариантов имеет свои достоинства и недостатки. Как уже отмечалось, самостоятельная разработка всех СФ-блоков может привести к увеличению сроков проектирования и задержке выпуска конечного изделия. Покупка СФ-блоков сопряжена с определенными финансовыми затратами, повышающими стоимость разработки. Применение СФ-блоков, имеющихся в свободном доступе, возможно только после их тщательной верификации, что требует обычно значительных временных затрат. При выполнении каждого проекта разработчик должен провести оценку поставленных требований и имеющихся ресурсов, чтобы выбрать оптимальный вариант реализации СнК. Таким образом, основная особенность проектирования СнК — возможность использования достаточно широкой номенклатуры синтезируемых СФ-блоков, имеющихся на рынке и в свободном доступе, которые могут быть реализованы на базе различных функциональных библиотек и технологий и интегрированы в кристалл средствами современных САПР.
Возможности реализации систем на кристалле
Технологии реализации
СнК могут быть созданы с помощью нескольких технологий, включая так называемые

Проблемы связанные с первыми технологиями
Изготовление опытной партии специализированных СБИС (несколько тысяч образцов) по технологии 0,13 — 0,18 мкм стоит несколько сотен тысяч долларов, а по технологии 0,09 мкм — свыше миллиона долларов. При этом имеющийся опыт разработки СнК показывает, что только в 25% проектов первоначально полученные опытные образцы соответствуют заданным требованиям. В большинстве случаев для получения необходимого результата требуется несколько итераций, что значительно увеличивает стоимость проекта. Можно надеяться, что развитие средств САПР позволит снизить риски при выполнении таких проектов.
Преимущества реализации СнК на базе FPGA
Преимущества реализации СнК на базе FPGA:
Таким образом, СнК на базе FPGA имеют практически те же достоинства, что и системы на плате, но отличаются лучшими техническими характеристиками — более низким энергопотреблением, меньшими габаритами и массой. При этом по таким параметрам как производительность и энергопотребление СнК на базе FPGA уступают СнК, реализованным в виде ASIC. Исходя из сказанного, можно сделать вывод, что СнК на базе FPGA будут конкурировать и постепенно вытеснять системы на плате. При этом вместо микропроцессоров и микроконтроллеров в этих СнК будут использоваться различные варианты процессорных СФ-блоков. СнК схемы обычно потребляют меньше энергии, имеют меньшую стоимость и большую надежность, чем много кристальные системы, которые они заменяют. С меньшим количеством кристаллов, стоимости сборки также снижаются. Однако у многих схем, общая стоимость больше у одного большого кристалла с той же функциональностью, нежели у нескольких маленьких схем.
Система на кристалле (SoC)

Содержание:
История создания
Первая СнК в 1976 году была вставлена в корпус электронных часов Microma LCD watch компанией Intel в виде 5810 CMOS chip. Через 2 года был создан 16-разрядный микропроцессор Intel 8086, который считается прародителем современных интегральных микрочипов.
В 1990 году в корпус интегральной микросхемы помимо процессора удалось поместить контроллер шины и контроллер памяти. В 1995 туда же добавили контроллер прерываний, таймеры, счётчики. К 2007 году развитие технологий позволило создать SoC, один процессор которого состоял из 148 миллионов транзисторов. Плюс: пара USB, 36 портов общего назначения GPIO, кэш на 256 КБ, 2 интерфейса SATA и множество контроллеров, включая поддержку часов в режиме реального времени.
В настоящее время ведущие производители систем на кристалле, такие как Espressif Systems, NORDIC Semiconductor, Qualcomm, Samsung, работают не столько над размером, сколько над снижением энергопотребления высокоинтегрированных систем.

Устройство SoC, компоненты и архитектура
Ёмкое определение «система-на-кристалле» объединяет множество устройств с различным функционалом общего назначения или узкой специализации.
Типичная СнК состоит из следующих компонентов:

Особенности SoC – проектирование и реализация
Хотя между традиционной semiconductor СБИС и СнК часто проводят прямую аналогию, между ними есть принципиальная разница. Правильнее считать SoCs следующей «ступенью эволюционного развития» интегральных микросхем. Если СБИС – это аппаратное решение, то ПЛИС требует одновременно аппаратного наполнения и программного обеспечения. При этом в разы возрастает сложность верификации готового продукта, не говоря уже о затратах человеко-часов на его разработку и отладку.
Для создания конкурентоспособного SoC необходимо совместить разумную стоимость, быстрое обновление предлагаемого рыночного продукта и высокую производительность на возможно меньшей площади кристалла. При этом сложность системы и трудоёмкость проектирования постоянно возрастает, а возможности дизайнера остаются на одном уровне.
При традиционных способах создания принципиально новой СБИС типа ASIC на разработку один человек затратит порядка пяти лет работы, а команда из 5 сотрудников может справиться с задачей за год. Проблема усугубляется тем, что ввиду особенностей реализации проекта на кристалле, разработчик ПО не может исправить допущенную ошибку. Нельзя переделать SoC – только создать заново. С усложнением рыночного интеллектуального продукта поменялись и подходы к его созданию.
Каждый изготовитель накопил (и продолжает создавать) немало готовых Intellectual Property блоков (IP-блоков), которые были разработаны под определённую задачу в рамках работы над текущими проектами. Это могут быть как простые логические вентили, так и более сложные умножители, регистры, счётчики и другие макроэлементы. В русском сегменте рынка изделий IoT их принято называть сложно-функциональными (СФ-блок).
Особенностью проектирования структуры СнК стало повторное использование готовых IP блоков, которые делятся на две группы:
Поскольку сложно-функциональный блок является интеллектуальной собственностью создателя, то добыть необходимые конструкции можно несколькими законными путями:
Купить готовый типовой блок для СнК в 2-5 раз дешевле, чем создать собственный. При этом не уходит время на верификацию продукта, тестирование опытных образцов. Однако, перед отправкой на производство обычно тестируют корректность функционирования систем на чипе, применяя языки Verilog, VHDL, SystemVerilog, SystemC, OpenVera.
Современный уровень создания микрочипов первым реализовался на Тайване, где создана система Fabless. Здесь разработчики уникального продукта активно сотрудничают с коллегами, а производство делегируют сторонней фабрике. Те, кто непосредственно изготавливают чипы, контролируют и перепроверяют лицензионное оформление всех, попадающих к ним в работу, топологий, своевременно выявляя кражи. Также проводится тестирование Подобные экосистемы по производству SoC представляются наиболее эффективными для снижения их стоимости.

Реализация
Есть две принципиально разные технологии создания СнК:
Система ASIC эффективно используются для замены традиционных микросхем на платах, что позволяет уменьшить вес, габариты, энергопотребление и теплоотдачу электронных устройств. При этом их производство экономически целесообразно только в промышленных масштабах, а процент ошибок и брака может доходить до 75. Таким образом, ASIC остаётся дорогостоящей технологией, даже если система создаётся из готовых СФ-блоков.
Альтернативный вариант уступает по производительности и энергопотреблению, но имеет ряд существенных преимуществ. А именно:
Производители считают, что СкН на FPGA будут заменять собой блоки на плате, а для реализации высокобюджетных проектов лучше использовать СБИС ASIC.
Отличие SoC и CPU
CPU – это центральное обрабатывающее устройство, процессор, который выполняет самую важную функцию в компьютере. Выглядит он как небольшой плоский квадрат со сторонами в 5 см на ножках, которыми прикреплён к материнской плате.
Функционал CPU – обработка информации. Однако для работы электронного устройства его наличие обязательно, но недостаточно. SoC представляет собой систему, в составе которой находится один или несколько ядер CPU, окружённый необходимой инфраструктурой, чтобы функционировать как законченное, автономное устройство.
Таким образом, принципиальное отличие ЦПУ от СнК кроется в их возможностях – процессор один из компонентов системы на кристалле, которая сравнима с полноценным компьютером, заключённым в маленьком неразборном корпусе, но потребляющем меньше энергии.

Использование систем на кристалле
Полупроводниковые системы на кристалле сегодня можно найти в любом многофункциональном электронном устройстве начиная, например, с наручных часов и заканчивая медицинским оборудованием. Компактные и эффективные, они активно используются в электронике IoT (Internet of Things), обеспечение связи 4G и 5G.
Крупнейшими производителями SoC являются Qualcomm, Samsung Semiconductor, NORDIC Semiconductor, Huawei HiSilicon, Espressif Systems, ARM Holdings, NVIDIA и MediaTek. Смартфоны, планшеты, компьютеры, модемы – любое современное программируемое оборудование может иметь в своём корпусе компактный чип с большими возможностями.
Проверка эффективности работы SOC
Сегодня мы поговорим о Security Operations Center (SOC) со стороны людей, которые не создают и настраивают его, а проверяют, как это сделали другие. Под проверку попадает эффективность работы SOC, построенного для вашей компании самостоятельно или кем-то со стороны. Проверка дает ответ на вопрос “Выполняет ли SOC поставленные перед ним задачи или нет, и насколько он эффективен?”. Ведь наличие SOC не говорит о том, что он работает как надо и вы в курсе любых возможных инцидентов и других проблем безопасности. Мы расскажем о своем опыте проверки SOC в разных компаниях в рамках наших проектов.

Тем, кто уже знает что такое SOC и с чем его пьют, предлагаем сразу перейти ко второй части статьи. Остальным предлагаем прочитать статью целиком.
Часть 1. Немного о SOC для начинающих
Защита информационных систем выходит на первое место практически в любой индустрии. Любой несанкционированный доступ к информации может привести к серьезным проблемам для компании.
Информационная система любой, даже самой маленькой компании, сложносоставная, и все её части должны защищаться по одному и тому же принципу — сначала организационные, затем превентивные меры, потом средства наблюдения, детектирующие аномалии, и инструменты реагирования. На последнем по порядку, но не по значимости, этапе борьбы с угрозами стоят люди, хотя случается, что проблему безопасности можно решить не привлекая людей, например путем автоматической блокировки портов или отключения машины от общей сети. Инструменты, используемые для защиты каждого из компонентов системы, могут быть разными от компании к компании, но прослеживается общая тенденция — постепенно компании, независимо от их размера, приходят к идее внедрения SOC — Security Operation Center.
Для этого есть несколько причин:
Не бывает двух одинаковых SOC-ов потому, что его настройка индивидуальна для каждой организации. Основные этапы создания SOC следующие:
Так как SOC — сложная и многосоставная структура, важно понимать, что на каждом из перечисленных этапов его создания что-то может пойти не так. А это с большой вероятностью повлияет на общую защищенность системы и эффективность работы самого SOC-а.
Часть 2. Что же произойдет, если не проверять эффективность работы SOC-а, а оставить всё как есть?

Начнем с того, что что-то может пойти не так, даже при малейших изменениях в инфраструктуре организации. А они происходят достаточно часто — кто-то увольняется, приходят новые люди, что-то ломается, происходит обновление техники и программного обеспечения и многое другое. В таком случае настройки СЗИ и правила корреляции должны быть оперативно изменены, но часто об этом забывают, а когда вспоминают, оказывается слишком поздно.

Следующая часть SOC, где могут возникнуть ошибки — средства защиты, с которых информация попадает в SIEM, могут быть настроены неверно и пропускать действия, направленные на систему извне. А если действие атакующего не будет обнаружено ни одним из имеющихся СЗИ, то оно не попадет в логи и не окажется в SIEM, и скорее всего служба безопасности узнает о нем не скоро.

Проблема может оказаться в SIEM-е. Он может работать не так, как хотелось бы вам. События, попадающие в него, могут коррелироваться неверно из-за ошибок в правилах корреляции, что приведет к пропуску действий атакующего. Здесь стоит уточнить, что не всегда достаточно данных от одного источника. Бывают случаи, когда для определения инцидентов безопасности необходимо объединить данные сразу из нескольких источников, чтобы получить цельную картину происходящего в системе. Но может оказаться, что правило настроено так, что для определения случившегося инцидента может не хватить данных от одного источника, которые и указывают на факт его свершения. Т.е. не сложится паззл, состоящий из данных от нескольких источников. Также правила для каких-то событий безопасности могут отсутствовать вовсе.
На этапе корреляции событий в SIEM может возникнуть сразу несколько проблем. Одной из них может быть задержка передачи событий от некоторых источников, что может помешать успешной корреляции.
Правила отнесения событий к инцидентам в SIEM могут быть настроены неверно сами по себе или же они могут отсутствовать для каких-либо событий. Также обычно инциденты имеют уровень важности, неверное определение которого может привести к большим проблемам.

Люди, работающие с SIEM, чьей задачей является реагирование на инциденты безопасности, также могут быть причиной пропущенных атак и последующих проблем с информационной безопасностью. Они могут пропускать какие-то сигналы от SIEM-а или неправильно реагировать на действия атакующего в силу разных причин. Есть также проблема в том, что люди рано или поздно увольняются, а новым сотрудникам требуется время на обучение.
Учитывая вышеперечисленное, тестирование SOC для проверки эффективности работы чрезвычайно важно как на этапе внедрения SOC, так и по прошествии времени. Так как специалисты нашей компании уже имеют опыт в этом деле, мы решили описать основные моменты и нюансы.
Часть 3. Проверка эффективности SOC
Тестирование SOC в компании может быть проведено по нескольким сценариям. Расскажем о тех, которые нам кажутся наиболее эффективными.
К задачам тестирования SOC относится проверка защищенности путем воспроизведения типовых сценариев поведения, присущих злоумышленникам. К ним можно отнести:
Тестирование SOC может проводиться двумя путями:
В первую очередь следует проверить работу SOC в режиме blackbox-тестирования. Его суть в том, что сотрудники отдела SOC не знают о проводимых работах и реагируют на все события в боевом режиме. Аудиторам/пентестерам предоставляется доступ в корпоративную сеть, а также могут быть даны учетные записи от наиболее широко используемых в компании сервисов.
Такая модель предполагает, что не располагающий никакой дополнительной информацией злоумышленник неизвестным путем получил доступ к сети компании и какой-либо из имеющихся в ней учетной записи. Действия такого злоумышленника характеризуются высокой степенью хаотичности и “шумности”. Он активно сканирует сеть, перебирает директории, учётные записи, рассылает на все порты все известные ему эксплойты, забрасывает веб-приложения XSS, SQLi, RCE, SSTI, NoSQLi, etc векторами. В общем, ведёт себя крайне агрессивно в надежде взломать хоть что-то. Аудиторы во время проверки имитируют действия такого злоумышленника, поддерживая заданный градус безумия, но готовые остановиться в любой момент по просьбе службы SOC или при возникновении технических неполадок. Кстати, неожиданным и приятным результатом может стать обнаружение уязвимых сервисов и приложений в инфраструктуре компании.
Другая модель тестирования — whitebox. В этом случае отрабатывается сценарий недобросовестного сотрудника. Обычно к этому моменту аудиторы хорошо ориентируются в сети заказчика и могут играть такую роль. Поведение потенциального злоумышленника в данном случае можно характеризовать высокой избирательностью как средств, так и целей атаки. Тут уже можно провести некоторые параллели с APT-атаками. Аудиторы атакуют только наиболее слабые на их взгляд места и используют продуманные и узконаправленные вектора атак, а также пытаются получить доступ к чувствительной информации вне зоны компетенции роли их учётной записи с последующей попыткой выкачивания её за пределы защищенного периметра. Все действия они стараются совершать таким образом, чтобы остаться незамеченными службой безопасности компании.
После тестирования обычно начинается разбор и сопоставление результатов, полученных аудиторами, и инцидентов, обнаруженных сотрудниками SOC. Данный этап позволит получить общую картину эффективности текущей работы SOC и может служить отправной точкой для всех дальнейших планов по расширению имеющихся проверок и подходов.
Наконец, когда представление о защищенности тестируемой инфраструктуры составлено, аудиторы могут с помощью whitebox тестирования проанализировать имеющийся набор правил, а также события, на основе которых, эти правила сформированы. Такое взаимодействие между аудиторами и аналитиками SOC может оказаться очень продуктивным, и в ходе консультации поможет обнаружить логические ошибки и упущения в настройке компонентов SOC. Корнем их обычно является недостаточное понимание аналитиками SOC, как же может действовать реальный злоумышленник и какие трюки он может совершать на системах.
Заключение
Наиболее критичные сервисы, заслуживающие более пристального внимания, тестируются отдельно с использованием двух моделей нарушителей.
Подобный комплекс мероприятий позволяет:
Чек-лист: проверьте, все ли «умеет» ваш SOC?
Какие задачи должен решать SOC? С ответа на этот вопрос целесообразно начинать проект создания ситуационного центра управления информационной безопасностью (Security Operation Center, SOC). Ринат Сагиров, ведущий консультант Центра информационной безопасности компании «Инфосистемы Джет», помог разобраться, что должен «уметь» современный SOC, и составить список по этой теме для чек-листа – нового формата TAdviser, в котором эксперты делятся полезной прикладной информацией, советами и инструкциями по применению различных технологий.
Содержание
Что может делать ваш SOC
SOC решает не только задачи по мониторингу и реагированию на инциденты информационной безопасности, но и в принципе любые другие операционные задачи в области ИБ (secops).


Многие компании при организации SOC ошибочно фокусируются на его техническом оснащении и только потом приступают к выстраиванию процессов и определению необходимого персонала. Между тем, целесообразно начинать с ответа на вопросы: для чего компании нужен SOC, и какие задачи он должен решать. Это поможет сформировать целевую модель планируемого SOC, исходя из целевого набора его функций или сервисов (если в компании внедрена сервисно-ориентированная модель). Например, MITRE выделяет порядка 40 функций SOC.

«Персонал—процессы—технологии» — основные компоненты SOC
После выбора целевого набора функций SOC эксперты рекомендуют переходить к разработке целевой модели, определяющей его основные компоненты в разрезе классической триады «персонал—процессы—технологии».
Целевая модель SOC помогает решить: какие процессы нужны; какие технологии требуются для автоматизации процессов; какой персонал необходим для реализации процессов и поддержки технологий.
Правильной формулы состава SOC не существует. У каждой компании свой путь и свой «обязательный» набор SOC. Состав очень сильно зависит от целевого набора функций SOC и объема решаемых им задач.

Компаниям с небольшой областью покрытия мониторинга будет достаточно централизованно собирать, фильтровать и нормализовать события с инфраструктуры c помощью систем управления логами (Log Management System) и выстроить процесс управления инцидентами ИБ, чтобы команда из 2–3 человек могла эффективно решать поставленные задачи.
Компаниям с разнообразным стеком технологий, распределенной ИТ-инфраструктурой и большим парком ИТ-средств для решения задач мониторинга и реагирования требуется большая команда SOC, которая способна использовать процессы в связке с технологиями, осуществлять их поддержку и развитие.
Остановимся подробно на отдельных составляющих SOC, исходя из базовой функциональности, включающей обнаружение и анализ нарушений ИБ в режиме реального времени, реагирование на инциденты и информирование всех заинтересованных сторон в компании о текущем уровне защищенности.
«Персонал»: какая команда нужна для обеспечения работы SOC
Организационная структура SOC зависит от его функций, поэтому четких критериев, которые бы определили точную численность персонала, нет. Для реализации базового функционала в команду SOC нужно включать специалистов, которые будут решать следующие задачи: мониторинг событий ИБ; регистрация и классификация подозрений на инцидент ИБ; сбор необходимых данных для анализа подозрения на инцидент ИБ; анализ подозрений на инцидент ИБ с целью его идентификации; координация реагирования на инциденты ИБ; администрирование технических инструментов SOC; развитие инфраструктуры SOC.

Основной состав команды стоит сформировать как можно раньше, чтобы он участвовал во внедрении систем и отладке процессов. Хорошим бэкграундом для сотрудника SOC является опыт администрирования ИТ-систем и сетевой инфраструктуры, внедрения и администрирования СЗИ, а также навыки по проведению тестирования на проникновение.


«Процессы»: какие процессы нужны для эффективной реализации функций SOC
Распространенной ошибкой при создании SOC является неправильное выстраивание процессов: нередко регламентирующая их документация оказывается нежизнеспособной и «уходит в стол». В результате вооруженные техническими средствами специалисты остаются без четкого понимания стоящих перед ними задач и без детальных инструкций по их выполнению. В таких условиях организовать продуктивное взаимодействие внутри SOC и со смежными подразделениями крайне сложно.
Для эффективности SOC рекомендуется моделировать процессы уровня управления и операционного уровня. Первые помогут обеспечить его развитие и заданный уровень качества реализации основного функционала. Вторые подразумевают выстраивание основных (т.е. напрямую связанных с реализацией целевого функционала) и вспомогательных процессов. Последние служат для определения подходов к подключению источников событий, развитию корреляционной логики, решению задач траблшутинга и актуализации перечня информационных активов в области мониторинга и данных об этих активах.

Как избежать ошибок при выстраивании процессов SOC
Подключите все заинтересованные подразделения к моделированию процессов; Закрепите зоны ответственности специалистов и определите наиболее удобные каналы коммуникаций между ними; Проведите пилотное тестирование по итогам моделирования; Проведите обучение всех, кто будет задействован в реализации процессов, с разбором реальных кейсов; Разработайте набор метрик, чтобы оценить правильность функционирования процесса.
«Технологии»: с помощью каких решений автоматизировать процессы SOC
Крупный SOC желательно оснастить инструментами для автоматизации выстроенных процессов.
SIEM-система помогает автоматизировать выявление инцидентов ИБ за счет сбора, корреляции и анализа событий ИБ с элементов ИТ-инфраструктуры и средств защиты информации.
IRP/SOAR-системы (Incident Response Platform / Resilient Security Orchestration, Automation and Response) повышают скорость реакции на инциденты за счет автоматизации рутинных задач по их обработке. Например, с их помощью удастся сэкономить время на регистрации, классификации (определении категории и уровня критичности), заполнении карточки инцидента, обогащении событиями для анализа, проверке на вредоносность индикаторов компрометации и выполнении действий по реагированию. В решениях этого класса можно настроить сценарии реагирования под каждую категорию инцидентов, что поможет автоматизировать весь жизненный цикл управления ими.
SOC может применять системы IRP/SOAR не только для управления инцидентами ИБ, но и для решения дополнительных задач.
Инвентаризация и контроль ИТ-инфраструктуры
При наличии в системе модуля управления активами можно реализовать контроль актуальности состава ИТ-инфраструктуры и решить проблему теневых ИТ (Shadow IT). Все это осуществляется в тесном взаимодействии с другими инфраструктурными системами: CMDB, корпоративный домен, системы управления ИТ-инфраструктурой. Управление уязвимостями в инфраструктуре
С помощью системы можно не только выявлять и регистрировать, но и приоритизировать уязвимости по уровням критичности информационных активов, автоматически назначать ответственных и сроки устранения.
Threat Intelligence Platform помогают автоматизировать задачи, связанные с использованием данных киберразведки (Threat Intelligence). К таким задачам можно отнести сбор и обработку индикаторов компрометации с последующим ретроспективным анализом событий ИБ на наличие получаемых индикаторов компрометации.
Что должен выявлять SOC
При строительстве SOC часто возникают сложности с пониманием того, какие инциденты он должен выявлять. Эту задачу решает его технологическое ядро — SIEM-система — путем корреляции событий ИБ, собираемых с элементов ИТ-инфраструктуры и средств защиты. Вендоры поставляют SIEM с большим количеством разработанных правил корреляции, которые остается только адаптировать под реалии конкретной ИТ-инфраструктуры. Или же можно написать свои правила, ориентируясь на популярный фреймворк MITRE ATT&CK с практиками выявления известных техник атак.
Не стоит ожидать, что правило корреляции сможет обнаружить полный вектор реализации угрозы ИБ. Вероятность того, что из всего многообразия тактик и техник злоумышленник выберет именно поставленные на мониторинг, ничтожно мала. Поэтому лучше разрабатывать правила корреляции, направленные на выявление атомарных событий реализации конкретных техник актуальных угроз.
Как разработать сценарную базу Определите актуальные угрозы ИБ для подключаемой ИТ-инфраструктуры; Установите сценарии действий (тактики) для реализации каждой угрозы ИБ; Выявите уязвимости, которые могут быть использованы в рамках конкретной тактики; Обозначьте способы (техники) реализации уязвимостей; Определите способы выявления реализации техники — набор событий ИБ, который указывает на попытки исполнения или осуществление конкретной техники, таких как:
— события обнаружения индикаторов компрометации (IP-адрес, URL, хеши файлов и т.д.);
— события обнаружения ПО, позволяющих реализовать технику;
— события обнаружения действий, предпринимаемых в рамках реализации техник. Проведите тестирование на проникновение, чтобы убедиться, что выбранные техники реализации угроз ИБ действительно актуальны для компании.
Аналитика
Возникающие события ИБ в инфраструктуре В первую очередь SOC должен анализировать события ИБ в элементах ИТ-инфраструктуры и средствах защиты информации для выявления инцидентов ИБ. Это нужно делать не только в режиме реального времени, но и в ретроспективе за заданный промежуток времени. Так вы сможете обнаружить пропущенные инциденты ИБ.
Постинцидентный анализ Чтобы инцидент не повторялся, важно анализировать результаты реагирования. Нужно разобраться, почему инцидент произошел и насколько эффективными были принятые меры по его устранению. После этого можно приступать к разработке рекомендаций: скорректировать настройки средств защиты, внести изменения в правила выявления инцидентов, изменить планы по реагированию и т.д.
Контроль метрик SOC Отслеживание значений метрик позволяет вовремя выявить и устранить проблемы, которые можно обнаружить как в организации процесса, так и в реализующем его персонале. Для SOC могут быть полезны, например, следующие метрики: доля инцидентов с соблюдением сроков реагирования; среднее время идентификации инцидентов ИБ; среднее время реагирования на инцидент (по уровням критичности).
Визуализация отчетности Аналитика по деятельности SOC отображается на дашбордах в виде виджетов — всевозможных таблиц и диаграмм, сгруппированных по смыслу на одном экране. Системы, входящие в технологическое ядро SOC (SIEM, IRP/SOAR), способны формировать множество типов виджетов любого состава и конфигурации. Чаще всего разрабатываются дашборды операционного и тактического уровней. Первые демонстрируют срез по текущей картине состояния ИБ: новые и открытые инциденты, их приоритеты, загрузку персонала, соблюдение сроков и т.д. Вторые предоставляют статистику по деятельности за последний месяц: распределение по категориям инцидентов и объектам атак, среднее время выявления и реагирования на инцидент, метрики эффективности.
Другой способ визуализации отчетности — представление данных по инциденту ИБ в виде графов или интерактивных схем и карт сетей. Такой способ демонстрирует: источник инцидента ИБ; информационные активы в корпоративной сети, подверженные атаке; скомпрометированные учетные записи; возможную связность одних инцидентов ИБ с другими для выявления цепочки атаки.
Новые тенденции
Поиск предпосылок к проведению атак В последнее время фокус ИБ смещается с выявления уже совершенных негативных действий в инфраструктуре в сторону обнаружения предпосылок к проведению атак. Другими словами, специалисты стремятся выявлять атаки на более ранних стадиях в соответствии с цепочкой Kill Chain, описывающей универсальный сценарий действий злоумышленника.

Для реализации такой концепции SOC нужны инструменты, которые не только выявляют сигнатурную активность, но и фиксируют и анализируют аномальное поведение, тем самым позволяя детектировать целенаправленные атаки с использованием неизвестного вредоносного кода, скомпрометированных учетных записей, бесфайловых методов, легитимных приложений и действий, не несущих под собой ничего подозрительного. Компания Gartner позиционирует связку NTA (Network Traffic Analysis), EDR (Endpoint Detection and Response) и SIEM как набор необходимых технических средств для организации максимально полного мониторинга инфраструктуры и выявления угроз, нацеленных на обход традиционных средств защиты.
EDR Рабочие места остаются ключевой целью злоумышленников и самыми распространенными точками входа в инфраструктуру компании. Конечные точки подключают к SIEM в качестве событий для мониторинга инцидентов редко или частично — только самые критичные. Это обусловлено в первую очередь высокой стоимостью сбора и обработки журналов со всех конечных станций, а также генерацией огромного количества событий для разбора, что зачастую приводит к перегрузке персонала SOC. Для детектирования событий на конечных узлах в инфраструктуре можно использовать решение класса EDR, которое поможет выявлять аномальное поведение на конечных хостах.
NTA Сетевой трафик — один из важных источников событий для выявления инцидентов ИБ. Часто вместо его полноценного анализа ограничиваются сбором логов со стандартных сетевых средств защиты и сетевого оборудования. Автоматизировать сбор и анализ событий внутри трафика можно с помощью решений класса NTA. В отличие от стандартных инструментов выявления сетевых атак, они оперируют большими объемами трафика, что дает возможность выявлять цепочку атаки целиком, а не довольствоваться срабатыванием единичной сигнатуры. Система класса NTA может быть полезна в выявлении неизвестных угроз за счет поведенческого анализа трафика.
Deception Tool Исследователи Gartner называют Deception одной из наиболее важных новых технологий в ИБ. Решения этого класса выявляют в ИТ-инфраструктуре совершаемые при APT-атаке вредоносные действия, которые часто остаются незаметными для стандартных ИБ-средств. Системы Deception создают активные ловушки и фейковые ресурсы, в полной мере имитирующие постоянную работу реальных пользователей, программных и программно-технических комплексов, функционирующих в ИТ-инфраструктуре. Такие ловушки дают злоумышленнику возможность успешно их атаковать и добиваться мнимых результатов нападения, тем самым выигрывая для команды SOC время на реагирование.
Breach and Attack Simulation (BAS) Активно развиваются и системы класса BAS, которые позволяют частично автоматизировать функционал тестирования на проникновение. Также они могут быть полезны при проведении киберучений, когда нужно отработать практические навыки персонала SOC по оперативному выявлению и реагированию на атаки.
О чем еще важно не забыть
«Песочница» Вырвавшийся на свободу вредонос, который аналитик решил проанализировать на основной машине, может оказаться серьезной угрозой. Для анализа вредоносного кода следует не забыть заложить в проект SOC полностью изолированную «песочницу».
Киберполигон Для киберучений понадобится киберполигон — симулятор, с помощью которого специалисты смогут обучиться отражать атаки и расследовать инциденты в боевом режиме. Кроме того, он пригодится и для тестирования новых средств защиты. По сути, это тестовая инфраструктура, которая никак не взаимодействует с основным ИТ-ландшафтом компании. В ней нужно обеспечить возможность имитации различных сценариев кибератак (DDoS, атак на ОС, Web, телеком-оборудование и Wi-Fi) и развернуть систему защиты, позволяющую выявлять и противодействовать им.
Защита самого SOC Для SOC нужно разработать отдельные, более строгие, стандарты обеспечения ИБ, чем для всей остальной компании. Инфраструктура SOC должна быть максимально разделена с корпоративной, сетевой сегмент отделен межсетевыми экранами и построен на отдельном сетевом оборудовании. Проще говоря, стоит исходить из того, что вся ИТ-инфраструктура компании уже скомпрометирована. При построении SOC нужно помнить, что его глаза и уши — это сетевые сенсоры, различные средства защиты информации, раскиданные по всей компании. Безопасный доступ к ним и их защита должны быть тщательно проработаны.
Вместо заключения
Строительство SOC — это длительный и ресурсозатратный проект. Классический подход к таким проектам можно сформулировать так: «Ешьте слона по частям».
SOC for beginners. Задачи SOC: контроль защищенности
Продолжаем цикл наших статей о центрах мониторинга кибератак для начинающих. В прошлой статье мы говорили о Security Monitoring, инструментах SIEM и Use Case.
Термин Security Operations Center у многих ассоциируется исключительно с мониторингом инцидентов. Многим сервис-провайдерам это, в принципе, на руку, поэтому мало кто говорит о том, что мониторинг имеет ряд серьезных ограничения в плане защиты от кибератак.
В этой статье мы на примерах продемонстрируем слабые места мониторинга инцидентов ИБ, расскажем, что с этим делать, и в конце, как обычно, дадим несколько практических рекомендаций на тему того, как провести аудит защищенности инфраструктуры своими силами.

«Уязвимость» Security Monitoring
В чем и сильная, и слабая сторона Security Monitoring? В том, что в первую очередь он оперирует событиями безопасности. Это либо события и срабатывания правил средств защиты информации, либо логи и журнальные файлы: операционной системы, базы данных, прикладного ПО.
При этом есть большое количество ситуаций, при которых либо в логах активность явным образом не фиксируется, либо поток событий или возможности систем не позволяют эффективно организовать процесс мониторинга.
Давайте рассмотрим на примерах.
1. Эксплуатация уязвимостей систем
Рассмотрим достаточно типовую ситуацию: есть существенно защищенный периметр, отдельно выделенный сегмент DMZ и достаточно слабо сегментированная офисная сеть компьютеров. И вот, в этой сети у нас появляется «новый » хост. Принадлежит ли эта машина инсайдеру, или это ноутбук рядового сотрудника, зараженный при помощи социальной инженерии, не столь важно. Злоумышленник начинает точечно заниматься эксплуатацией уязвимости RCE на операционных системах серверов и рабочих станций, доступных ему в рамках сегмента.
Каким образом можно зафиксировать такую проблему? Отсутствие сегментации сети оставляет нас без надежд на детект от сетевых средств защиты, будь то IPS или другие системы. В логах самой операционной системы эксплуатация RCE уязвимости не несет никакого специального кода, и поэтому нет никакой возможности отличить её от обычной попытки аутентификации в ОС. Так или иначе, в логах будет запуск системного процесса svchost.exe от системного пользователя.
Единственной нашей надеждой остаются IDS-модули средств защиты хоста, но, как показывает наша практика, наличие работающего и регулярно обновляемого IDS на всех хостах инфраструктуры – большая редкость.
Вот как выглядит процесс эксплуатации «наболевшей» уязвимости EternalBlue SMB Remote Windows Kernel Pool Corruption (устраняемой обновлением безопасности MS17-010). Обратите внимание, что отсутствие любого из приведенных в примере трех источников не даст нам полной картины и возможности понять, была атака или нет.

В итоге можно надеяться на чудо, а можно начать строить процесс управления уязвимостями и попытаться локализовать проблему еще до ее проявления.
По этой проблеме есть достаточно большое количество специализированных материалов, поэтому заострять внимание на ней не будем. Обозначим лишь несколько тезисов.
«Выиграть гонку» с уязвимостями и построить инфраструктуру с актуальными обновлениями безопасности – задача, практически не реализуемая в крупном корпоративном клиенте. Количество уязвимостей из года в год растет, причем большинство из них среднего и высокого уровня критичности (согласно системе оценки CVSS v2).

Распределение количества уязвимостей по годам в разрезе их критичности (ссылка на источник).
При рассмотрении и составлении карты устранения уязвимостей необходимо не только придерживаться принципа Парето (т.е. выбирать только самую критичную часть для устранения), но и очень тщательно работать с компенсирующими мерами – с достижимостью уязвимости за счет настроек средств защиты, анализом возможных векторов реализации и т.д.
Но это не единственная задача, оставшаяся за скоупом возможностей мониторинга.
2. Профилирование прямого доступа в Интернет
Периодически в глазах службы безопасности SIEM превращается в могучий инструмент, который в состоянии оперировать любыми событиями или потоками данных. В таком случае может возникнуть, например, следующая задача: в рамках компании есть некоторое согласованное количество маршрутов разрешенного прямого доступа в Интернет в обход прокси-серверов. И в целях контроля работы сетевых специалистов перед SIEM ставится задача: контролировать все несогласованные ранее открытия прямых доступов путем анализа сессий из корпоративной сети.
Казалось бы, задача простая и логичная. Но есть несколько ограничений:


В итоге данный вопрос в первую очередь касается управления конфигурациями и контроля изменений. И, несмотря на теоретическую возможность решения этой задачи с помощью мониторинга, многократно эффективнее оперировать специализированными средствами и уже в SIEM мониторить работоспособность процесса.
Совокупно же эти примеры приводят нас к более глобальной задаче: SOC должен детально понимать инфраструктуру компании, ее уязвимости и процессы в «широком смысле» и принимать решение о том, как наиболее эффективно мониторить данную инфраструктуру и как максимально быстро узнавать о том, что в ней что-то изменилось – то есть в каждый момент времени объективно оценивать фактическую защищенность инфраструктуры от атаки.
Контроль защищенности – задачи и технологии
На наш взгляд, в тематику контроля защищенности попадают следующие задачи:
Для каждой из обозначенных задач есть свой инструментарий:
Мониторинг и контроль защищенности => Мониторинг + контроль защищенности
Одним из важных преимуществ параллельного запуска процессов мониторинга и контроля защищенности в SOC является возможность «переопылять» один процесс информацией из другого, тем самым повышая общую безопасность. Разберем на примере, как это работает.
Мониторинг как инструмент выявления новых хостов и активов
Если в компании не построен процесс инвентаризации активов или ИТ не делится его результатами, появление новой системы с критичным функционалом или критичными данными может пройти мимо информационной безопасности. Но ситуация существенно меняется, когда существует процесс мониторинга.
В 99% случаев вновь появившийся хост в обязательном порядке «проявит» себя:
Пример: события аутентификации в ОС Windows с фильтрами по известным именам хостов. Как правило, в компании есть критерии именования хостов, за которые можно зацепиться.
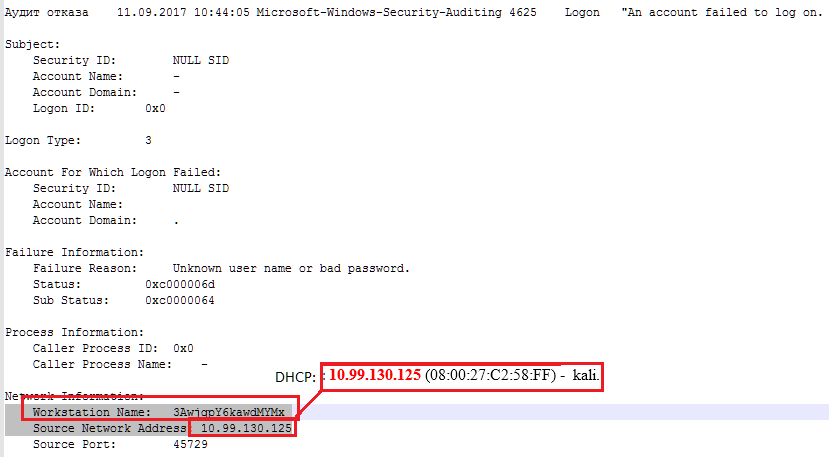
И, уже владея информацией о том, что появились новые сущности в сети компании, вполне можно разобраться в их задачах, легитимности или учесть их в общей модели угроз.
И наоборот, если невозможно закрыть какую-то процессную или технологическую уязвимость навсегда, в качестве компенсирующей меры можно разработать дополнительные сигнатуры и сценарии, контролирующие эксплуатацию данной уязвимости.
В качестве примера можно привести процесс наладки и обслуживания технологического оборудования на заводе (или, например, ГРЭС – другими словами, практически на любом производстве). Для работы с таким оборудованием, как правило, привлекаются инженеры от производителя, и зачастую это иностранные специалисты, для которых нужно каким-то образом организовать удаленный доступ до площадки. Довольно часто из-за ограничений существующей архитектуры сети и технологических сегментов удаленный доступ открывается напрямую из Интернета (по RDP, SSH) до терминальных серверов, с которых уже осуществляется наладка оборудования посредством специализированного ПО. И по-другому организовать этот доступ просто нет возможности. Да, можно открывать доступ по заявке и в строго определенное технологическое окно, ограничить адреса, с которых будут разрешены подключения к терминальному серверу, но все же остается риск перехвата RDP/SSH сессии, эксплуатации уязвимостей ОС из сети Интернет, проникновения в технологическую сеть через АРМ инженера-наладчика, заражения бэкдором данного терминального сервера и т.п.
Так как «закрыть» данную процессную уязвимость нет возможности, в качестве компенсирующей меры можно предложить усиленный мониторинг данных терминальных серверов и активности на них, а именно:
Контроль защищенности – с чего начать
Мы предлагаем начать подход к задачам контроля защищенности со следующих действий:
SOC for beginners. Задачи SOC: мониторинг
Мы продолжаем рассказывать о буднях Security Operations Center – о реагировании на массовые кибератаки, любопытных кейсах у заказчиков и правилах корреляции событий, позволяющих нам детектировать атаки на заказчиков и пр.
Сегодня мы хотим открыть новый цикл статей, задача которого – продемонстрировать, с какими задачами и трудностями сталкиваются все начинающие (и не очень) SOCостроители, и главное – поделиться нашим опытом по их решению.
В этих статьях мы будем касаться разных вопросов и технического, и методического характера, и максимально отделять коммерческое и маркетинговое позиционирование от реальных задач. В наших планах завершить первый цикл статей как раз к SOC-Форуму, чтобы площадка стала одним из мест для обсуждения данных вопросов.
Начнем с самой популярной задачи, без которого сложно представить SOC, – мониторинга инцидентов.
Security monitoring – реальная задача или новая маркетинговая реальность?
Любой опытный безопасник за свою карьеру пережил немало трендов на новые красивые аббревиатуры. Очередные NG-технологии, искусственные интеллектуальные системы, «золотые» и «серебряные» пули защиты от хакеров и таргетированных атак и т.д. Сейчас одним из таких популярных направлений стал мониторинг инцидентов информационной безопасности. При этом эксперты иногда высказываются, что безопасность не требует мониторинга, а требует только активного блокирования. Однако мы считаем иначе – по двум причинам.
Причина первая: динамика развития компаний
«Мир изменился, я чувствую это в воздухе, я чувствую это в воде».
Галадриэль, CSO Лотлориэна
Существуют два глобальных изменения, которые все агрессивнее входят в жизнь каждой компании, обладающих хоть какой-то ИТ-инфраструктурой:
Причина вторая: интеллектуальность атак и средств защиты
«Погоди, Гретель, вот скоро луна взойдет, и станут видны хлебные крошки».
Гензель, 1 level Security Analyst
Попытка взлома, отбитая или заблокированная средством защиты, сегодня уже не является поводом для успокоения, поскольку инструментарий злоумышленников, а следовательно, и сами атаки, непрерывно эволюционируют.
Приведем два простых примера.
1. В компании используется NGFW. Такие системы могут детектировать не только внешние атаки, но и потенциально вредоносную активность внутри сети (например, активность бота). И вот в один прекрасный день NGFW заблокировал попытку одного из хостов подключиться к центру управления бот-сетями вредоносного семейства / отправки информации на сервера, подконтрольные злоумышленникам.

Можно ли утверждать, что на этом инцидент исчерпан? На первый взгляд, да. Наша защита успешно заблокировала подключение, бот не связался с центром управления, и в итоге вредоносная активность в сети не началась. Но давайте копнем глубже: 90% процентов сотрудников компании уже давно пользуются ноутбуками. И если сотрудник решит поработать из дома или из кафе, бот успешно достучится до центра управления, ведь там, за пределами сети предприятия, нет ни NGFW, ни бдительного безопасника. К чему это приведет? На первом этапе – к компрометации всех данных этого ноутбука. На втором – к обновлению протоколов или адресов центра управления бота, что не позволит NGFW успешно блокировать атаку.
2. Уже достаточно давно антивирусные агенты научились выявлять и блокировать хакерские утилиты, например, печально известный mimikatz. И вот мы настроили соответствующую политику в нашей компании и зафиксировали блокировку. На одном из хостов ИТ-администраторов был запущен и заблокирован mimikatz.

Этот пример аналогичен предыдущему – с одной стороны, компрометации учетных записей не произошло, инцидент исчерпан. Но, даже если оставить в стороне ненормальность самой ситуации и желание в ней разобраться (сам ли ИТ-администратор запускал утилиту и для чего), ничто не помешает злоумышленнику еще раз попытаться получить доступ. Он попытается «прибить» процесс антивируса, использует версию, которая антивирусом не определяется, например, при применении powershell-аналогов. В конце концов, просто найдет хост без антивируса и получит интересующую его информацию там.

В итоге, проигнорировав анализ и разбор заблокированной атаки, мы оставляем действия злоумышленников без контроля. И вместо того, чтобы купировать их попытки захватить нашу инфраструктуру, мы оставляем их с развязанными руками, позволяя придумать новый способ атаки и вернуться к ней с ранее захваченных позиций.
Два этих примера доказывают, что оперативный мониторинг и тщательный анализ событий ИБ может не только помочь в выявлении и разборе инцидентов, но и усложнить жизнь злоумышленников.
Говорим мониторинг – подразумеваем SIEM?
Некоторое время назад между темой SOC и мониторинга ставился знак равенства, а дальше он же возникал между понятиями «мониторинг» и «SIEM». И, хотя вокруг этой темы сломано много копий, хочется вернуться к этому вопросу, чтобы он не смущал нас в дальнейшем.
В мировой практике и даже на территории России известны подходы к решению задач мониторинга и построения SOC вообще без применения SIEM. Один из крупнейших и самых успешных SOC прошлого десятилетия был целиком построен на оперативной регулярной работе сотрудников: на высокорегулярной основе дежурная смена анализировала журналы антивируса, прокси, IPS и других средств защиты – где руками, где базовыми скриптами, где умными отчетами. Этот подход позволял закрывать 80% задач baseline мониторинга (к примерам базовых задач и начального подхода я подойду детальнее в следующем разделе).
Так зачем же на самом деле нужна платформа SIEM/Log Management в плоскости задач мониторинга? Попробуем разобрать на примерах.
Use case 1. Собрать все инциденты «в одну кучу».
На первый взгляд эта задача может показаться бесполезной, но, на самом деле, трудно переоценить потребность заказчиков в ее решении. Особенно когда их цель –не обработка каждого детекта со средства защиты, а поиск определенных закономерностей. Например, выявление повторяющихся событий/инцидентов (когда проблема методически не устранена), фиксация странных активностей с одного хоста/на один хост (первые робкие шаги к модному слову kill chain), анализ частотности срабатываний.
Безусловно, для решения столь утилитарной задачи SIEM, по-честному, не нужен. Вполне приемлемым вариантом здесь может стать service desk с учетом заявок и правильная работа с отчетами из него (анализ закономерностей глазами).
Но, тем не менее, когда компания запускает у себя SIEM, ее, как правило мотивирует именно желание собрать все инциденты в едином окне, поэтому включаем этот use case в наш список.
Use case 2. Склеить однотипные инциденты.
Когда речь идет о развивающейся и длительной активности злоумышленника, при неправильной настройке сценария можно столкнуться с явлением под названием «incident storm». Например:
И в этом потоке событий очень легко пропустить инцидент, отличный от указанных активностей. Поэтому правильный SIEM всегда позволит склеить эти активности по ключевым полям, чтобы разбирать их как один общий инцидент.
Use Case 3. Обогатить расследование информацией из дополнительных систем.
После выявления инцидента аналитику обычно предстоит очень большой объем работы по поиску его причин и последствий. Рассмотрим следующий пример: одним из базовых правил мониторинга и контроля во многих международных стандартах является запрет на использование системных неперсонифированных учетных записей в инфраструктуре. И вот перед нами встала задача контролировать вход под учетной записью root на операционной системе Unix. Нужен ли для решения такой задачи SIEM? Безусловно, нет; любой администратор, владеющий основами написания скриптов, с легкостью создаст двухстрочный скрипт, который позволит выявлять такую активность.
Но теперь давайте посмотрим, что нам, как оператору SOC, нужно дальше сделать с этим событием.

Чем отличаются эти два события? Какое из подключений легитимно, а какое нет? Сейчас у нас есть только ip-адрес, с которого выполнялось подключение. Это, безусловно, не позволяет нам локализовать пользователя. Вот как действовали бы мы:

После этого необходимо оценить воздействие на систему, оказанное после входа под системной записью root. При правильно настроенном аудите нам, в принципе, будет достаточно журналов сервера, но есть одно «но»: сам злоумышленник с этими правами мог с легкостью их модифицировать. Что приводит нас к задаче хранения журналов в независимом источнике (одной из задач, которые часто ставят под SIEM). В итоге, анализ этих журналов позволяет оценить проблему и ее критичность.

Безусловно, большую часть этой работы можно выполнить и без SIEM, но тогда на нее уйдет гораздо больше времени, а аналитик столкнется с серьезными ограничениями. Поэтому хотя SIEM и не строго необходим, при проведении расследований он имеет серьезные преимущества.

Use Case 4. Простая и сложная корреляция.
На эту тему написаны уже сотни статей и презентаций, поэтому надолго останавливаться на данном примере не хочется. Скажу еще раз главное: сегодня, чтобы эффективно выявлять и отражать атаки, нужно уметь выявлять корреляции между событиями ИБ. Будет ли это создание и удаление учетной записи в Active Directory в течение подозрительно короткого интервала или выявление продолжительных vpn-сессий (длиннее 8 часов) на межсетевом экране – не важно. Так или иначе, базовыми скриптами или инструментами самого средства защиты эта задача не решается из-за огромного объема проходящих через него событий безопасности. Для решения таких задач и предназначены платформы SIEM.
Итого: подход к задачам мониторинга на первом этапе не обязательно требует SIEM-платформы, но она существенно упрощает жизнь SOC и его операторов. В долгосрочной перспективе, по мере углубления в задачи по выявлению инцидентов, наличие SIEM перестает быть рекомендацией и становится обязательным условием.
Мониторинг – с чего начать?
Отвечая на вопрос в заглавии этого раздела, большинство заказчиков впадает в одно из двух заблуждений.
Единственной задачей SOC и вообще информационной безопасности является борьба с APT или таргетированными атаками. Наша практика показывает, что до выстраивания базовых процессов мониторинга, наведения порядка в инфраструктуре и «причесывания» процессов реагирования ставить столь амбициозную задачу перед собой не стоит.
О мониторинге можно думать только после того, как вся инфраструктура будет накрыта плотным колпаком из средств защиты и самых современных систем ИБ. По нашим наблюдениям, хороший первый результат по повышению уровня ИБ можно получить, обладая минимальным набором средств защиты. Это подтверждает и статистика, которую мы собираем на регулярной основе: например, в первом полугодии 2017 около 67% событий у заказчиков были зафиксированы при помощи основных сервисов ИТ-инфраструктуры и средств обеспечения базовой безопасности – межсетевых экранов и сетевого оборудования, VPN-шлюзов, контроллеров доменов, почтовых серверов, антивирусов, прокси-серверов и систем обнаружения вторжений.
Итак, процесс мониторинга событий и инцидентов можно начать с достаточно базовых вещей: