Девопс что это
Девопс что это
Что такое DevOps и зачем он нужен?
Почему полезно работать с DevOps, где применять эту технологию и какие существуют инструменты. Объясняет Алексей Климин из компании «Атвинта».




Алексей Климин
Фронтенд, Бэкэнд, Админ, DevOps. Обожаю все оптимизировать и автоматизировать. Постоянно ищу новые технологии и способы их внедрения.

Что это за технология
Термин DevOps образован от английских слов development и operations. Это подход, методология и даже культура и философия процесса разработки, при котором программисты, тестировщики и системные администраторы могут работать над продуктом быстрее и эффективнее. Подход помогает снизить ошибки при передаче проекта от разработчиков к тестировщикам и сисадминам и наладить между ними взаимодействие. В основе лежит идея, что разработка, тестирование и эксплуатация цифровых продуктов — это единый, бесшовный и циклический процесс.

Сама по себе тема DevOps довольно объемная. Это автоматизация процессов подготовки инфраструктуры как для разработки, так и для тестирования приложения, а также для его эксплуатации. Сюда же входят автоматизация деплоя и мониторинг.
Рассмотрим на примере заказной разработки веб-приложений, с какими проблемами сталкиваются разработчики и как их устранить с DevOps-подходом.
Проблемы при работе без DevOps
Много действий при передаче на тестирование
Разработчик устанавливает у себя на машине все необходимое: язык программирования, на котором будет вестись разработка, например PHP 7.0, базу данных, MySQL 5.7 и веб-сервер, Apache. Какая операционная система и какие версии библиотек и зависимостей будут установлены на сервере, неизвестно.
После того как нужная функциональность приложения реализована, требуется ее протестировать.
Программист упаковывает в архив свой код, копию базы данных, информацию о требуемом ПО и инструкцию по установке всего необходимого для запуска и работы приложения. После этого он передает архив тестировщику.
QA-специалист устанавливает все необходимое на тестовый стенд, разворачивает приложение и принимается тестировать.
Если в процессе тестирования появляется новая версия разработки, то приходится повторять процедуру. Разработчику нужно снова создать архив, передать тестировщику; а тому, в свою очередь, снова развернуть приложение.
В результате таких многократно повторяющихся процедур ошибки наслаиваются, и QA- специалисту приходится дважды перепроверять одни и те же баги.
Несовместимость версий в тестовой среде и на сервере заказчика
Версия языка программирования может отличаться от той, на которой велась разработка. Могут различаться версии базы данных. И даже сама система управления базами данных может быть другой. И это не говоря о том, что пути до файлов и каталогов в коде самого приложения различаются, так как приложение на боевом сервере находится совершенно в другом месте, нежели на машине разработчика.
В итоге при использовании на продакшне другого веб-сервера приходится настраивать приложение заново. А это дополнительное время.
Как DevOps улучшает процесс разработки
У нас в digital-агентстве «Атвинта» я настроил процессы таким образом, что сборка проекта, запуск автотестов и деплой на тестовый сервер происходят автоматически, а на продакшн — полуавтоматически. Если какой-либо из этапов завершился неудачно, разработчик получит оповещение.
Эти технологии подходят при разработке веб-приложений, закрытых сервисов вроде корпоративных порталов и сервисов учета сделок для интернет-магазинов.
Для подготовки серверов используются инструменты наподобие Ansible. Они позволяют быстро настроить окружение, в котором приложение будет работать в автоматическом режиме. На это тратится несколько минут, а не несколько часов.
Для единообразия окружения используем инструмент Docker.
После того как разработчик сделал определенный функционал, он отправляет код в репозиторий. Там вступает в работу процесс, называемый Continuous Integration/Continuous Delivery — непрерывная интеграция и непрерывная доставка (далее CI/CD).
Если процесс сборки и автоматического тестирования прошел успешно, приложение разворачивается на тестовом сервере (staging server), где специалист по QA проводит ручное тестирование либо тестирование с применением инструментов вроде Selenium — для автоматизации действий веб-браузера в случае веб-приложения.
Даже если во время ручного тестирования возникли какие-либо ошибки, разработчик быстро вносит правки и выкатывает обновление. Даже если нужно повторять процедуру, это происходит быстро.
После успешного тестирования принимается решение о релизе, после чего достаточно нажать одну кнопку, чтобы выпустить новый релиз в продакшн.
DevOps-инженер также проводит работы по так называемому незаметному деплою, когда конечные пользователи даже не подозревают о том, что вышла новая версия.
Инструментарий для DevOps
Разнообразие инструментов DevOps невероятно велико, так что я перечислю лишь некоторые из них, которые применяю в своей работе.
Ansible

Cистема управления конфигурациями, написанная на Python с использованием декларативного языка разметки (yaml) для описания конфигураций.
Была выбрана за низкий порог вхождения. Уже через пару часов можно написать рабочую конфигурацию.
GitLab

Cистема контроля версий со встроенной CI/CD.
Выбрана, потому что можно развернуть на своем сервере и использовать бесплатно. Имеет большой функционал и интеграцию со множеством сторонних сервисов.
Для мониторинга нагрузки серверов используется довольно популярный стек: Grafana + InfluxDB + Telegraf.
Grafana

Это платформа с открытым исходным кодом для визуализации, мониторинга и анализа данных.
InfluxDB — база данных для хранения собранной статистики.
Telegraf — агент, который устанавливается на сервер и пересылает метрики, а также логи в базу InfluxDB.
Кому и для чего применять
Применение методологии DevOps поможет наладить бизнес-процессы и ускорить выход обновлений.
Кто такие DevOps?
На данный момент это чуть ли не самая дорогая позиция на рынке. Суета вокруг «DevOps» инженеров превосходит все мыслимые пределы, а тем хуже с Senior DevOps инженерами.
Я работаю руководителем отдела интеграции и автоматизации, угадайте английскую расшифровку — DevOps Manager. Отражает ли именно английская расшифровка нашу повседневную деятельность — вряд ли, а вот русский вариант в данном случае более точен. По роду моей деятельности, естественно, что мне, необходимо собеседовать будущих членов моей команды и, за прошедший год, через меня прошло человек 50, а еще столько же срезалось на прескрине с моими сотрудниками.
Мы все еще находимся в поиске коллег, потому как за лейблом DevOps прячется очень большая прослойка разного рода инженеров.
Все написанное ниже является моим личным мнением, вы не обязаны соглашаться с ним, однако допускаю, что внесет оттенок в ваше отношение к теме. Несмотря на риск попасть в немилость, я публикую свое мнение, поскольку считаю что ему есть место быть.
Компании по-разному понимают кто такие DevOps инженеры и ради быстрого найма ресурса вешают этот лейбл всем. Ситуация достаточно странная, поскольку компании готовы платить нереальные вознаграждения этим людям, получая за них, в большинстве случаев, админа-тулзиста.
Так кто же такие DevOps инженеры?
Давайте начнем с истории появления — Development Operations появился как еще один шаг к оптимизации взаимодействия в малых командах для повышения скорости производства продукта, как ожидаемое следствие. Идея заключалась в том, чтобы усилить команду разработки знаниями о процедурах и подходах в управлении продуктовой средой. Иными словами, разработчик должен понимать и знать как его продукт работает в тех или иных условиях, должен понимать как деплоить его продукт, какие характеристики среды подкрутить, чтобы повысить производительность. Так, в течение некоторого времени, появились разработчики с DevOps подходом. DevOps разработчики писали скрипты сборки и упаковки для упрощения своей деятельности и работоспособности продуктивной среды. Однако, сложность архитектуры решений и взаимное влияние компонентов инфраструктуры с течением времени начало ухудшать рабочие показатели сред, с каждой итерацией требовались все более глубокие понимания тех или иных компонентов, снижая продуктивность самого разработчика из-за дополнительных затрат на понимание компонентов и тюнинга систем под конкретную задачу. Собственная стоимость разработчика росла, стоимость продукта вместе с ним, резко подскочили требования к новым разработчикам в команде, ведь им необходимо было также покрывать обязанности «звезды» разработки и, естественно, «звезды» становились все менее доступны. Также стоит отметить, что, по моему опыту, мало кому из разработчиков интересна специфика обработки пакетов ядром операционной системы, правила маршрутизации пакетов, аспекты безопасности хоста. Логичным шагом было привлечь администратора, который именно с этим знаком и возложить подобного формата обязанности именно на него, что, благодаря его опыту, позволило достичь тех же показателей меньшей стоимостью в сравнении со стоимостью «звезды» разработки. Таких администраторов помещали в команду и основной его задачей было управление тестовыми и продуктивными средами, на правилах конкретно взятой команды, с ресурсами выделенными именно этой команде. Так, собственно, и появились DevOps в представлении большинства.
Частично или полностью, со временем, данные системные администраторы начали понимать потребности именно этой конкретной команды в области разработки, как упростить жизнь разработчикам и тестировщикам, как выкатить обновление и не остаться ночевать в пятницу в офисе, исправляя ошибки деплоя. Время шло, теперь «звездами» становились системные администраторы, понимающие чего хотят разработчики. С целью минимизации импакта начали подтягиваться утилиты управления, все вспомнили старые и надежные методы изоляции уровня ОС, которые позволяли минимизировать требования по безопасности, управлению сетевой части, да и конфигурации хоста в целом и, как следствие снизить требования к новым «звездам».
Появилась «замечательная» вещь — docker. Почему замечательная? Да только лишь потому, что создание изоляции в chroot или jail, равно как OpenVZ, требовало нетривиальных знаний ОС, в контру утилите позволяющей элементарно создать изолированную среду приложения на неком хосте со всем необходимым внутри и передать бразды правления разработке вновь, а системному администратору управлять только лишь одним хостом, обеспечивая его безопасность и высокую доступность — логичное упрощение. Но прогресс не стоит на месте и системы вновь становятся все сложнее и сложнее, компонентов все больше и больше, один хост уже не удовлетворяет потребностям системы и необходимо строить кластеры, мы вновь возвращаемся к системным администраторам, которые способны построить данные системы.
Цикл за циклом, появляются различные системы упрощающие разработку и/или администрирование, появляются системы оркестрации, которые, ровно до тех пор, пока не требуется отойти от стандартного процесса, просты в использовании. Микросервисная архитектура также появилась с целью упрощения всего описанного выше — меньше взаимосвязей, проще в управлении. В своем опыте я не застал полностью микросервисную архитектуру, я бы сказал 50 на 50 — 50 процентов микросервисов, черные коробки, пришло на вход, вышло обработанное, другие 50 — разодранный монолит, сервисы неспособные работать отдельно от других компонентов. Все это вновь наложило ограничения на уровень знаний как разработчиков, так администраторов.
Подобные «качели» уровня экспертных знаний того или иного ресурса продолжаются и по сей день. Но мы немного отвлеклись, есть немало моментов которые стоит осветить.
Build Engineer/Release Engineer
Весьма узкоспециализированные инженеры, появившиеся как средство стандартизации процессов сборки ПО и его релизов. В процессе введения повального Agile казалось бы они перестали быть востребованы, однако это далеко не так. Эта специализация появилась как средство стандартизации именно сборки и поставки ПО в промышленных масштабах, т.е. используя стандартные техники для всех продуктов компании. С появлением DevOps разработчиков частично утратили функции, поскольку именно разработчики стали подготавливать продукт к поставке, а учитывая изменяющуюся инфраструктуру и подход в максимально быстрой поставке без оглядки на качество со временем превратились именно в стопор изменений, поскольку следование стандартам качества неизбежно замедляет поставки. Так, постепенно, часть функционала Build/Release инженеров перекочевала на плечи системных администраторов.
Ops’ы такие разные
DevOps — (в теории) персона, не понаслышке понимающая все процессы цикла разработки — разработку, тестирование, понимающая архитектуру продукта, способная оценить риски безопасности, знакомая с подходами и средствами автоматизации, хотя бы на высоком уровне, помимо этого понимающая также пред и пост-релизную поддержку продукта. Персона способная выступать адвокатом как Operations, так Development, что позволяет выстроить благоприятное сотрудничество между этими двумя столпами. Понимающая процессы планирования работ командами и управления ожиданиями заказчика.
Для выполнения подобного рода работ и обязанностей данная персона должна иметь средства управления не только процессами разработки, тестирования, но и управления инфраструктурой продукта, а также планирования ресурсов. DevOps в данном понимании не может находится ни в IT, ни в R&D, ни даже в PMO, он должен иметь влияние во всех этих областях — технический директор компании, Chief Technical Officier.
Так ли это в вашей компании? — Сомневаюсь. В большинстве случаев это или IT, или R&D.
Недостаток средств и возможности влияния хотя бы на одно из этих трех направлений деятельности произведет смещение веса проблем в сторону где эти изменения проще применить, как например применение технических ограничений на релизы в связи с «грязным» кодом по данным систем статического анализатора. То есть когда PMO устанавливает жесткий срок на выпуск функционала, R&D не может выдать качественный результат в эти сроки и выдает его как может, оставив рефакторинг на потом, DevOps относящийся к IT, техническими средствами блокирует релиз. Недостаток полномочий на изменение ситуации, в случае с ответственными сотрудниками ведет к проявлению гиперответственности за то, на что они не могут повлиять, тем паче если эти сотрудники понимают и видят ошибки, и как их исправить — «Счастье в неведении», и как следствие к выгоранию и потери этих сотрудников.
Рынок DevOps ресурсов
Давайте рассмотрим несколько вакансий на позицию DevOps от разных компаний.
Резюмируя по данной вакансии можно сказать, что ребятам достаточно Middle/Senior System Administrator.
Кстати, не стоит сильно разделять админов на Linux/Windows. Я конечно понимаю, что сервисы и системы этих двух миров различаются, но основа у всех одна и любой уважающий себя админ знаком как с одним, так и с другим, и даже если не знаком, то для грамотного админа не составит труда ознакомится с этим.
Рассмотрим иную вакансию:
Резюмируя — Middle/Senior System Administrator
Хотелось бы также оставить ремарку относительно 3 пункта, дабы укрепить понимание, почему этот пункт покрывается сисадмином. Kubernetes всего лишь оркестрация, тулза которая оборачивает прямые команды драйверам сети и хостам виртуализации/изоляции в пару команд и позволяет сделать общение с ними абстрактным, вот и все. Для примера возьмем ‘build framework’ Make, коего фреймворком я, к слову, не считаю. Да, я знаю про моду пихать Make куда угодно, где нужно и не нужно — обернуть Maven в Make например, серьезно?
По сути Make просто обертка над shell, упрощающая именно команды компиляции, линковки, окружения компиляции, так же как и k8s.
Однажды, я собеседовал парня, который использовал k8s в своей работе поверх OpenStack, и он рассказывал как развертывал сервисы на нем, однако, когда я спросил именно про OpenStack, оказалось, что он администрируется, равно как и подымается системными администраторами. Вы правда думаете, что человек поднявший OpenStack вне зависимости от того какую платформу он использует позади него не способен использовать k8s?=)
Данный соискатель на самом деле не DevOps, а такой же Системный Администратор и, чтобы быть точнее, Kubernetes Administrator.
Резюмируем в очередной раз — Middle/Senior System Administrator им будет достаточно.
Сколько вешать в граммах
Разброс предлагаемых зарплат для указанных вакансий — 90к-200к
Теперь хотелось бы провести параллель между денежными вознаграждениями Системных Администраторов и DevOps Engineers.
В принципе, для упрощения можно грейды по опыту работы раскидать, хоть это и не будет точным, для целей статьи хватит.
Сайт поиска сотрудников предлагает:
System Adminsitrators:
По стажу «DevOps»’ов использовался стаж, хоть как то затрагивающий SDLC.
Из вышеозначенного следует, что на самом деле компаниям не нужны DevOps’ы, а также что они могли сэкономить не менее 50 процентов от изначально запланированных затрат, наняв именно Администратора, более того, они могли бы четче определить обязанности искомого человека и быстрее закрыть потребность. Не стоит также забывать, что четкое разделение ответственности позволяет снизить требования к персоналу, а также создать более благоприятную атмосферу в коллективе, ввиду отсутствия пересечений. В подавляющем большинстве вакансии пестрят утилитами и DevOps лейблами, однако не имеющие в основе действительно требования к DevOps Engineer, лишь запросы на тулзового администратора.
Процесс обучения DevOps инженеров также ограничен лишь набором специфичных работ, утилит, не дает общего понимания процессов и их зависимостей. Это конечно хорошо, когда человек может используя Terraform задеплоить AWS EKS, в связке с Fluentd сайд-каром в этом кластере и AWS ELK стеком для системы логирования за 10 минут, используя лишь одну команду в консоли, но если он не будет понимать сам принцип обработки логов и для чего они нужны, не знать как собирать метрики по ним и отслеживать деградацию сервиса, то это будет все тот же эникей, умеющий использовать некоторые утилиты.
Спрос, однако, порождает предложение, и мы видим крайне перегретый рынок позиции DevOps, где требования не соответствуют реальной роли, а лишь позволяют системным администраторам зарабатывать больше.
Так кто же они? DevOps’ы или жадные системные администраторы? =)
Как дальше жить?
Работодателям — точнее формулировать требования и искать именно тех кто нужен, а не разбрасываться лейблами. Вы не знаете чем занимаются DevOps — они вам не нужны в таком случае.
Работникам — Учиться. Постоянно совершенствовать свои знания, смотреть на общую картину процессов и отслеживать путь к поставленной цели. Можно стать кем захочешь, надо лишь постараться.
DevOps — что это, зачем, и насколько востребовано?

Несколько лет назад в IT появилась новая специальность DevOps-инженер. Она очень быстро стала одной из наиболее популярных и востребованных на рынке. Но вот парадокс — частично популярность DevOps объясняется тем, что компании, нанимающие таких специалистов, часто путают их с представителями других профессий.
Эта статья посвящена разбору нюансов профессии DevOps, текущем положении на рынке и перспективам. Мы разобрались в этом сложном вопросе при помощи декана факультета DevOps в GeekBrains в онлайн-университете GeekUniversity Дмитрия Бурковского.
Итак, что же такое DevOps?
Сам термин расшифровывается как Development Operations. Это не столько специальность, сколько подход к организации работы в средней или крупной компании при подготовке продукта или сервиса. Дело в том, что в процессе подготовки участвуют разные отделы одной компании, и действия их далеко не всегда хорошо скоординированы.
Так, разработчики, например, не всегда знают о том, какие проблемы возникают у пользователей, которые работают с выпущенной программой или сервисом. Техподдержка — знает все отлично, но она может быть не в курсе того, что «внутри» ПО. И тут приходит на помощь DevOps-инженер, который помогает координировать процесс разработки, способствует автоматизации процессов, улучшает их прозрачность.
Концепция DevOps объединяет людей, процессы и инструменты.
Что должен знать и уметь DevOps-инженер?
По мнению одного из наиболее известных адептов концепции DevOps Джо Санчеса, представитель профессии должен хорошо понимать нюансы самой концепции, иметь опыт администрирования как Windows, так и Linux-систем, понимать программный код, написанный на разных ЯП, работать Chef, Puppet, Ansible. Понятно, что для разбора кода нужно знать несколько языков программирования, и не просто знать, но и иметь опыт разработки. А еще очень желателен опыт тестирования готовых программных продуктов и сервисов.
Но это в идеале, такой уровень опыта и знаний найдется далеко не у каждого представителя IT-сферы. Вот набор минимально необходимых для хорошего DevOps знаний и опыта:

Кроме того, DevOps-cпециалист должен понимать потребности и требования бизнеса, видеть его роль в процессе разработки и уметь строить процесс с учетом интересом заказчика.
А что с порогом входа?
Список знаний и опыта не зря был подан выше. Теперь становится проще понять, кто же может стать DevOps-специалистом. Получается, что проще всего перейти в эту профессию для представителей других IT-специальностей, в особенности — системным администраторам и разработчикам. И тем, и другим можно быстро нарастить недостающий объем опыта и знаний. Половина необходимого набора у них уже есть, а нередко — и больше половины.
А еще отличные DevOps-инженеры получаются из тестировщиков. Они знают, что и как работает, в курсе недостатков и недоработок ПО и «железа». Можно сказать, что тестировщик, который знает языки программирования и умеет писать программы — без пяти минут DevOps.
А вот представителю нетехнической специальности, никогда не имевшему дело ни с разработкой, ни с системным администрированием, будет сложно. Конечно, ничего невозможного нет, но все же новичкам нужно адекватно оценивать свои силы. Времени на получение требуемого «багажа» потребуется немало.
Куда может устроиться DevOps?
В крупную компанию, работа которой напрямую либо косвенно связана с разработкой приложений и администрированием «железа». Максимальный дефицит в DevOps-инженерах — у компаний, предоставляющих большое количество сервисов конечным потребителям. Это банки, операторы связи, крупнейшие интернет-провайдеры и т.п. Среди компаний, которые активно нанимают на работу DevOps-инженеров — Google, Facebook, Amazon, Adobe.
Внедряют DevOps и стартапы с мелким бизнесом, но все же для многих из этих компаний приглашение DevOps-инженеров, скорее, дань моде, чем реальная необходимость. Конечно, бывают и исключения, но их не так много. Небольшим компаниям нужен, скорее «и швец, и жнец, и на дуде игрец», то есть человек, который в состоянии работать по ряду направлений. Хороший СТО способен справиться со всем этим. Дело в том, что малому бизнесу важна скорость работы, оптимизация рабочих процессов критична для среднего и крупного бизнеса.
Вот немного вакансий (следить за новыми можно на Хабр Карьере по этой ссылке):

Зарплата DevOps в России и мире
В России средняя зарплата DevOps-инженера составляет около 132 тысяч рублей в месяц. Это расчеты калькулятора зарплат сервиса Хабр Карьера, произведенные на основании 170 анкет на 2-е полугодие 2020 года. Да, выборка не такая уж и большая, но в качестве «средней температуры по больнице» вполне подходит.

Есть зарплаты в размере 250 тысяч рублей, есть — около 80 тысяч и чуть ниже. Все зависит от компании, квалификации и самого специалиста, конечно.

Что касается других стран, то статистика по зарплатам тоже известна. Хорошую работу провели специалисты Stack Overflow, проанализировав анкеты около 90 тысяч человек — не только DevOps, но и вообще представителей технических специальностей. Оказалось, что Engineering Manager и как раз DevOps получают больше всех.
В качестве заключения стоит сказать, что востребованность DevOps постепенно растет, спрос на специалистов любого уровня превышает предложение. Так что если есть желание — можно попробовать себя в этой сфере. Правда, нужно помнить, что одного желания — недостаточно. Нужно постоянно развиваться, учиться и работать.
Гайд по DevOps для начинающих
В чем важность DevOps, что он означает для ИТ-специалистов, описание методов, фреймворков и инструментов.

Многое произошло с тех пор, как термин DevOps закрепился в IT-мире. С учетом того, что большая часть экосистемы имеет открытый исходный код, важно пересмотреть, почему это началось и что это значит для карьеры в IT.
Что такое DevOps
Хотя нет единого определения, я считаю, что DevOps — это технологическая структура, которая обеспечивает взаимодействие между командами разработчиков и операционными командами для более быстрого развертывания кода в производственных средах с возможностью повторения действий и автоматизации. Остаток статьи мы потратим на распаковку этого утверждения.
Слово «DevOps» является объединением слов «разработка» (development) и «операции» (operations). DevOps помогает увеличить скорость доставки приложений и услуг. Это позволяет организациям эффективно обслуживать своих клиентов и становиться более конкурентоспособными на рынке. Проще говоря, DevOps — это согласованность между разработкой и ИТ-операциями с более эффективным взаимодействием и сотрудничеством.
DevOps предполагает такую культуру, при которой сотрудничество между командами разработчиков, операторами и бизнес-командами считается критически важным аспектом. Речь идет не только об инструментах, поскольку DevOps в организации постоянно приносит пользу и клиентам. Инструменты являются одним из его столпов, наряду с людьми и процессами. DevOps увеличивает возможности организаций по предоставлению высококачественных решений в кратчайшие сроки. Также DevOps автоматизирует все процессы, от сборки до развертывания, приложения или продукта.
Дискуссия о DevOps сосредоточена на взаимоотношениях между разработчиками, людьми, которые пишут программное обеспечение для жизни, и операторами, ответственными за поддержку этого программного обеспечения.
Вызовы для команды разработчиков
Разработчики, как правило, с энтузиазмом и желанием внедряют новые подходы и технологии для решения проблем организаций. Однако они также сталкиваются с определенными проблемами:
Проблемы, с которыми сталкивается операционная группа
Операционные группы исторически ориентированы на стабильность и надежность ИТ-сервисов. Именно поэтому операционные команды занимаются поиском стабильности с помощью внесения изменений в ресурсы, технологии или подходы. К их задачам относятся:
Как DevOps решает проблемы разработки и операций
Вместо того, чтобы выкатывать большое количество функций приложения одновременно, компании пытаются выяснить, смогут ли они развернуть небольшое количество функций для своих клиентов с помощью серии итераций релизов. Такой подход имеет ряд преимуществ, таких как лучшее качество программного обеспечения, более быстрая обратная связь с клиентами и т.д. Это, в свою очередь, обеспечивает высокую степень удовлетворенности клиентов. Для достижения этих целей от компаний требуется:
DevOps пытается решить различные проблемы, возникающие в результате применения методологий прошлого, в том числе:
Противостояние DevOps, Agile и традиционного IT
DevOps часто обсуждается в связи с другими ИТ-практиками, в частности, гибкой и водопадной ИТ-инфраструктурой.
Agile — это набор принципов, ценностей и методов производства программного обеспечения. Так, например, если у вас есть идея, которую вы хотите преобразовать в программное обеспечение, вы можете использовать принципы и ценности Agile. Но это программное обеспечение может работать только в среде разработки или тестирования. Вам нужен простой и безопасный способ быстро и с высокой повторяемостью переносить программное обеспечение в производственную среду, а путь лежит через инструменты и методы DevOps. Гибкая методология разработки программного обеспечения сосредоточена на процессах разработки, а DevOps отвечает за разработку и развертывание — самым безопасным и надежным способом.
Сравнение традиционной водопадной модели с DevOps – хороший способом понять преимущества, которые дает DevOps. В следующем примере предполагается, что приложение будет запущено через четыре недели, разработка завершена на 85%, приложение будет запущено, и процесс закупки серверов для отправки кода только что был начат.
| Традиционные процессы | Процессы в DevOps |
|---|---|
| После размещения заказа на новые серверы команда разработчиков работает над тестированием. Оперативная группа работает над обширной документацией, необходимой на предприятиях для развертывания инфраструктуры. | После размещения заказа на новые серверы, команды разработчиков и операторов совместно работают над процессами и документооборотом для установки новых серверов. Это позволяет лучше понять требования к инфраструктуре. |
| Искажена информация о восстановлении после отказа, избыточности, расположении центров обработки данных и требованиях к хранилищам, так как отсутствуют входные данные от команды разработчиков, которая обладает глубокими знаниями в области применения. | Подробная информация о преодолении отказа, избыточности, аварийном восстановлении, расположении центров данных и требованиях к хранилищам известна и корректна благодаря вкладу команды разработчиков. |
| Оперативная группа не имеет представления о прогрессе команды разработчиков. Также она разрабатывает план мониторинга на основе собственных представлений. | Оперативная группа полностью осведомлена о прогрессе, достигнутом командой разработчиков. Она также взаимодействует с командой разработчиков, и они совместно разрабатывают план мониторинга, который удовлетворяет IT и потребности бизнеса. Они также используют инструменты мониторинга производительности приложений (APM). |
| Нагрузочный тест, проводимый перед запуском приложения, приводит к сбою приложения, что задерживает его запуск. | Нагрузочный тест, проводимый перед запуском приложения, приводит к снижению производительности. Команда разработчиков быстро устраняет узкие места, и приложение запускается вовремя. |
Жизненный цикл DevOps
DevOps подразумевает принятие определенных общепринятых практик.
Непрерывное планирование
Непрерывное планирование опирается на принципы бережливости, для того чтобы начать с малого, определив ресурсы и результаты, необходимые для проверки ценности бизнеса или видения, постоянной адаптации, измерения прогресса, изучения потребностей клиентов, изменения направления по мере необходимости с учетом маневренности, а также для обновления бизнес-плана.
Совместное развитие
Процесс совместной разработки позволяет бизнесу, командам разработчиков и командам тестировщиков, распределенным по разным часовым поясам, непрерывно поставлять качественное программное обеспечение. Сюда входит многоплатформенная разработка, поддержка программирования на разных языках, создание пользовательских историй, разработка идей и управление жизненным циклом. Совместная разработка включает в себя процесс и практику непрерывной интеграции, что способствует частой интеграции кода и автоматической сборке. При частом внедрении кода в приложение, проблемы интеграции выявляются на ранних этапах жизненного цикла (когда их легче исправить), а общие усилия по интеграции сокращаются благодаря непрерывной обратной связи, поскольку проект демонстрирует непрерывный и наглядный прогресс.
Непрерывное тестирование
Непрерывное тестирование снижает стоимость тестирования, помогая командам разработчиков балансировать между скоростью и качеством. Оно также устраняет узкие места в тестировании благодаря виртуализации услуг и упрощает создание виртуализированных тестовых сред, которые можно легко совместно использовать, развертывать и обновлять по мере изменения систем. Эти возможности сокращают расходы на инициализацию и поддержку тестовых сред, а также сокращают время цикла тестирования, позволяя проводить интеграционное тестирование на ранних стадиях жизненного цикла.
Непрерывные выпуск и развертывание
Эти методики привносят за собой одну из основных практик: непрерывные выпуск и развертывание. Это обеспечивают непрерывный конвейер, который автоматизирует ключевые процессы. Он сокращает количество ручных операций, время ожидания ресурсов и объем переделок, позволяя осуществлять развертывание по нажатию кнопки, что обеспечивает большее количество релизов, снижение количества ошибок и полную прозрачность.
Автоматизация играет ключевую роль в обеспечении стабильного и надежного выпуска программного обеспечения. Одна из важнейших задач заключается в том, чтобы взять на вооружение ручные процессы, такие как сборка, регрессия, развертывание и создание инфраструктуры, и автоматизировать их. Для этого требуется контроль версии исходного кода; сценарии тестирования и развертывания; данные об инфраструктуре и конфигурации приложений; а также библиотеки и пакеты, от которых зависит приложение. Еще одним важным фактором является возможность запрашивать состояние всех сред.
Непрерывный мониторинг
Непрерывный мониторинг обеспечивает формирование отчетов корпоративного уровня, которые помогают командам разработчиков понять доступность и производительность приложений в производственном окружении еще до того, как они будут развернуты в производство. Ранняя обратная связь, обеспечиваемая непрерывным мониторингом, имеет решающее значение для снижения стоимости ошибок и управления проектами в правильном направлении. Эта практика часто включает в себя инструменты наблюдения, которые, как правило, раскрывают показатели, связанные с производительностью приложений.
Постоянная обратная связь и оптимизация
Непрерывная обратная связь и оптимизация обеспечивают визуальное представление потока клиентов и точное определения проблемных участков. Обратная связь может быть включена как на предпродажной, так и на постпроизводственной стадиях для максимизации ценности и обеспечения успешного завершения еще большего количества транзакций. Все это обеспечивает немедленную визуализацию первопричины проблем клиентов, которые влияют на их поведение и влияние на бизнес.

Преимущества DevOps
DevOps может способствовать созданию среды, в которой разработчики и операторы работают как одна команда для достижения общих целей. Важной вехой в этом процессе является внедрение непрерывной интеграции и непрерывной доставки (CI/CD). Эти методики позволят командам быстрее выводить программное обеспечение на рынок с меньшим количеством ошибок.
Важными преимуществами DevOps являются:
Принципы DevOps
Принятие DevOps породило несколько принципов, которые эволюционировали (и продолжают эволюционировать). Большинство поставщиков решений разработали свои собственные модификации различных методик. Все эти принципы основаны на целостном подходе к DevOps, и организации любого размера могут использовать их.
Разрабатывайте и тестируйте в среде, похожей на производственную
Суть заключается в том, чтобы позволить командам разработчиков и специалистов по контролю качества (QA) разрабатывать и тестировать системы, которые ведут себя как производственные системы, чтобы они могли видеть, как приложение ведет себя и работает задолго до того, как оно будет готово к развертыванию.
Приложение должно быть подключено к производственным системам как можно раньше в течение жизненного цикла для решения трех основных потенциальных проблем. Во-первых, это позволяет протестировать приложение в среде, близкой к реальному окружению. Во-вторых, это позволяет тестировать и проверять процессы доставки приложения заранее. В-третьих, это позволяет операционной команде проверить на ранней стадии жизненного цикла, как их среда будет вести себя, когда приложения будут развернуты, тем самым позволяя им создавать тонко настраиваемую, ориентированную на приложения среду.
Развертывание с воспроизводимыми, надежными процессами
Этот принцип позволяет командам разработчиков и операторов поддерживать гибкие процессы разработки программного обеспечения на протяжении всего жизненного цикла. Автоматизация имеет решающее значение для создания итеративных, надежных и воспроизводимых процессов. Следовательно, организация должна создать конвейер доставки, обеспечивающий непрерывное автоматизированное развертывание и тестирование. Частое развертывание также позволяет командам тестировать процессы развертывания, тем самым снижая риск сбоев развертывания во время реальных релизов.
Мониторинг и проверка качества работы
Организации хороши в мониторинге приложений на производстве, потому что у них есть инструменты, которые фиксируют показатели и ключевые показатели эффективности (KPI) в режиме реального времени. Этот принцип переносит мониторинг на ранние стадии жизненного цикла, гарантируя, что автоматизированное тестирование отслеживает функциональные и нефункциональные атрибуты приложения на ранних стадиях процесса. Всякий раз, когда приложение тестируется и развертывается, качественные показатели должны быть изучены и проанализированы. Инструменты мониторинга обеспечивают раннее оповещение о проблемах, связанных с эксплуатацией и качеством, которые могут возникнуть в процессе производства. Эти показатели должны быть собраны в формате, доступном и понятном всем заинтересованным сторонам.
Усовершенствование циклов обратной связи
Одна из целей процессов DevOps заключается в том, чтобы дать возможность организациям быстрее реагировать и вносить изменения. При поставке программного обеспечения эта цель требует, чтобы организация получала обратную связь на ранней стадии, а затем быстро училась на каждом предпринятом действии. Этот принцип требует от организаций создавать каналы коммуникации, которые позволяют заинтересованным сторонам получать доступ и взаимодействовать по принципу обратной связи. Разработка может осуществляться путем корректировки своих проектных планов или приоритетов. Производство может действовать путем улучшения производственной среды.
В заключение
DevOps — это все более популярная методология, целью которой является объединение разработчиков и операторов в единое целое. Она уникальна, отличается от традиционных IT-операций и дополняет Agile (но не является столь же гибкой).

Узнайте подробности, как получить востребованную профессию с нуля или Level Up по навыкам и зарплате, пройдя платные онлайн-курсы SkillFactory:
Зачем нужен DevOps и кто такие DevOps-специалисты
Когда приложение не работает, меньше всего хочется услышать от коллег фразу «проблема на вашей стороне». В итоге страдают пользователи – а им всё равно, какая часть команды несет ответственность за поломку. Культура DevOps появилась как раз затем, чтобы сплотить разработку и поддержку и объединить их вокруг общей ответственности за конечный продукт.
Какие практики входят в понятие DevOps и зачем они нужны? Чем занимаются DevOps-инженеры и что они должны уметь? На эти и другие вопросы отвечают эксперты из EPAM: Кирилл Сергеев, системный инженер и DevOps-евангелист, и Игорь Бойко, ведущий системный инженер и координатор одной из DevOps-команд компании.

Зачем нужен DevOps?
Раньше между разработчиками и поддержкой (т. н. operations) существовал барьер. Звучит парадоксально, но у них были разные цели и KPI, хотя они и делали общее дело. Целью разработки было как можно быстрее реализовать бизнес-требования и добавить их в работающий продукт. Поддержка отвечала за то, чтобы приложение стабильно работало – а любые изменения ставят стабильность под угрозу. Налицо конфликт интересов – DevOps появился, чтобы его решить.
Что такое DevOps?
Вопрос хороший – и спорный: окончательно в мире об этом пока не договорились. В ЕРАМ считают, что DevOps объединяет в себе технологии, процессы и культуру взаимодействия внутри команды. Это объединение нацелено на непрерывную доставку ценностей конечным пользователям.
Кирилл Сергеев: «Разработчики пишут код, тестировщики его проверяют, а администраторы устанавливают финальный продукт на производственное окружение. Долгое время эти части команды были несколько разрознены, а потом появилась идея объединить их общим процессом. Так появились DevOps-практики».
Настал тот день, когда разработчики и системные инженеры заинтересовались работой друг друга. Барьер между производством и поддержкой стал стираться. Так появился DevOps, в который входят практики, культура и порядок взаимодействия в команде.

В чем состоит суть DevOps-культуры?
В том, что ответственность за конечный результат лежит на каждом из участников команды. Самое интересное и сложное в философии DevOps – понять, что конкретный человек не просто отвечает за свой этап работы, а несет ответственность за то, как будет работать весь продукт. Проблема лежит не на чьей-то стороне – она общая, и каждый член команды помогает ее решить.
Важнейшее положение DevOps-культуры – именно решать проблему, а не просто применять DevOps-практики. Более того, эти практики внедряют не «на чьей-то стороне», а в весь продукт. Проекту нужен не сам по себе DevOps-инженер – ему нужно решение проблемы, а роль DevOps-инженера может быть распределена по нескольким членам команды с разной специализацией.
Какие бывают DevOps-практики?
DevOps-практики покрывают все этапы жизненного цикла ПО.
Игорь Бойко: «Идеальный случай – когда мы начинаем использовать DevOps-практики прямо при инициации проекта. Вместе с архитекторами мы планируем, какой у приложения будет архитектурный ландшафт, где оно будет располагаться и как масштабироваться, выбираем платформу. Сейчас в моде микросервисная архитектура – для нее мы выбираем систему оркестрации: нужно уметь управлять каждым элементом приложения по отдельности и обновлять его независимо от других. Еще одна практика – это “инфраструктура как код”. Так называют подход, при котором инфраструктура проекта создается и управляется при помощи кода, а не через прямое взаимодействие с серверами.
Дальше мы переходим на этап разработки. Здесь одна из крупнейших практик – построение CI/CD: нужно помочь разработчикам интегрировать изменения в продукт быстро, мелкими порциями, чаще и безболезненней. CI/CD покрывает и проверку кода, и заливку мастера в кодовую базу, и разворачивание приложения на тестовых и продуктивных средах.
На этапах CI/CD код проходит через quality gates. С их помощью проверяют, чтобы код, который вышел с рабочей станции разработчика, соответствовал заданным критериям качества. Здесь добавляется юнит- и UI-тестирование. Для быстрого, безболезненного и фокусированного разворачивания продукта можно выбрать подходящий тип деплоймента.
DevOps-практикам есть место и на стадии поддержки готового продукта. Их применяют для мониторинга, обратной связи, безопасности, внедрения изменений. На все эти задачи DevOps смотрит с точки зрения постоянных улучшений. Мы сводим к минимуму повторяющиеся операции, автоматизируем их. Сюда же относятся миграции, расширение приложения, поддержка работоспособности».
Чем полезны DevOps-практики?
Если бы мы писали учебник по современным практикам DevOps, на его первой странице значились бы три пункта: автоматизация, ускорение релиза и быстрая обратная связь от пользователей.
Кирилл Сергеев: «Первое – это автоматизация. Все взаимодействия в команде мы можем автоматизировать: написали код – выкатили – проверили – установили – собрали фидбэк – вернулись в начало. Всё это – автоматически.
Второе – ускорение выхода релиза и даже упрощение разработки. Заказчику всегда важно, чтобы продукт вышел на рынок как можно скорее и начал приносить пользу раньше, чем аналоги конкурентов. Процесс доставки продукта можно бесконечно улучшать: сокращать время, добавлять дополнительные контрольные метки, совершенствовать мониторинг.
Третье – это ускорение обратной связи от пользователя. Если у него есть замечания, мы можем сразу же вносить корректировки и тут же обновлять приложение».

Как соотносятся понятия «системный инженер», «билд-инженер» и «DevOps-инженер»?
Они пересекаются, но относятся к немного разным сферам.
Системный инженер в ЕРАМ – это должность. Они бывают разных уровней: от джуниора до chief-специалиста.
Билд-инженер – это скорее роль, которую можно выполнять на проекте. Сейчас так называют людей, ответственных за CI/CD.
DevOps-инженером называют специалиста, который внедряет на проекте DevOps-практики.
Если суммировать всё это, получается примерно следующее: человек в должности системного инженера исполняет на проекте роль билд-инженера и занимается там внедрением DevOps-практик.
Чем именно занимается DevOps-инженер?
DevOps-инженеры собирают воедино все части, из которых состоит проект. Они знают специфику работы программистов, тестировщиков, системных администраторов и помогают упростить их работу. Они понимают потребности и требования бизнеса, его роль в процессе разработки – и строят процесс с учетом интересов заказчика.
Мы много говорили про автоматизацию – ею DevOps-инженеры занимаются в первую очередь. Это очень большой пункт, в который, помимо прочего, входит подготовка окружения.
Кирилл Сергеев: «Прежде чем внедрять обновления в продукт, их нужно протестировать на стороннем окружении. Его готовят DevOps-инженеры. Они же насаждают на проекте DevOps-культуру в целом: внедряют DevOps-практики на всех слоях своих проектов. Эти три принципа: автоматизация, упрощение, ускорение – они привносят всюду, куда могут дотянуться».
Что должен знать DevOps-инженер?
По большому счету, у него должны быть знания из разных областей: программирование, работа с операционными системами, базами данных, системами сборки и конфигураций. К ним добавляется умение работать с облачной инфраструктурой, системами оркестрации, мониторинга.
1. Языки программирования
DevOps-инженеры знают несколько базовых языков для автоматизации и могут, например, сказать программисту: «Давай ты будешь делать установку кода не руками, а с помощью нашего скрипта, который всё автоматизирует? К нему мы подготовим config-файл, его будет удобно читать и тебе, и нам – и мы в любой момент сможем его изменить. А еще мы будем видеть, кто, когда и для чего вносит в него изменения».
DevOps-инженер может выучить один или несколько из этих языков: Python, Groovy, Bash, Powershell, Ruby, Go. Знать их на глубинном уровне не требуется – достаточно основ синтаксиса, принципов ООП, умения писать несложные скрипты для автоматизации.
2. Операционные системы
DevOps-инженер должен понимать, на каком сервере будет установлен продукт, в какой среде будет запускаться, с какими сервисами будет взаимодействовать. Можно выбрать специализацию на Windows или Linux-семействе.
3. Системы контроля версий
Без знаний системы контроля версий DevOps-инженеру никуда. Git – одна из самых популярных систем в настоящий момент.
4. Облачные провайдеры
AWS, Google, Azure – особенно если мы говорим про Windows-направление.
Кирилл Сергеев: «Облачные провайдеры предоставляют нам виртуальные сервера, которые прекрасно ложатся на рельсы CI/CD.
Установка десяти физических серверов требует порядка ста ручных операций. Каждый сервер нужно вручную запустить, установить и настроить нужную операционную систему, установить наше приложение на этих десяти серверах, а потом десять раз всё перепроверить. Облачные сервисы заменяют эту процедуру десятью строчками кода, и хороший DevOps-инженер должен уметь ими оперировать. Так он экономит время, силы и деньги – и для заказчика, и для компании».
5. Системы оркестрации: Docker и Kubernetes
Кирилл Сергеев: «Виртуальные сервера разделены на контейнеры, в каждый из которых мы можем установить наше приложение. Когда контейнеров много, надо ими управлять: один включить, другой выключить, где-то сделать бэкапы. Это становится довольно сложным делом, для которого нужна система оркестрации.
Раньше каждым приложением занимался отдельный сервер – любые изменения в его работе могли повлиять на исправность приложения. Благодаря контейнерам приложения становятся изолированными и запускаются по отдельности – каждое на своей виртуальной машине. Если происходит сбой, не нужно тратить время на поиск причины. Проще уничтожить старый контейнер и добавить новый».
6. Системы конфигураций: Chef, Ansible, Puppet
Когда необходимо обслуживать целый парк серверов, приходится делать много однотипных операций. Это долго и сложно, а еще ручная работа повышает шанс ошибки. Тут на помощь приходят системы конфигураций. С их помощью создают скрипт, который удобно читать и программистами, и DevOps-инженерами, и системными администраторами. Этот скрипт помогает проводить одинаковые операции на серверах автоматически. Так ручных операций (и, следовательно, ошибок) становится меньше.
Какую карьеру может построить DevOps-инженер?
Развиваться можно и горизонтально, и вертикально.
Игорь Бойко: «С точки зрения горизонтального развития, у DevOps-инженеров сейчас самые широкие перспективы. Всё постоянно меняется, и наращивать навыки можно по самым разным направлениям: от систем контроля версий до мониторинга, от управления конфигурациями до баз данных.
Можно стать системным архитектором, если сотруднику интересно разобраться, как работает приложение на всех этапах своего жизненного цикла – от разработки до поддержки».
Как стать DevOps-инженером?
А также можно посмотреть актуальные тренинги по DevOps на сайте Тренинг-центра EPAM.
Больше информации о DevOps-направлении на сайте.
Кто такой DevOps-инженер, что он делает, сколько зарабатывает и как им стать
DevOps-инженеры — это многопрофильные специалисты, которые умеют автоматизировать процессы и знают, как работают разработчики, QA и менеджеры. Они умеют программировать, быстро осваивают сложные инструменты и не теряются перед незнакомой задачей. DevOps-инженеров мало — им готовы платить по 200–300 тысяч рублей, но вакансий всё равно много.
Дмитрий Кузьмин рассказывает, чем конкретно занимается DevOps и что нужно изучить, чтобы претендовать на такую должность. Бонусом — важные ссылки на книги, видео, каналы и профессиональное сообщество.
Чем занимается DevOps-инженер
В ситуации с DevOps важно не путать термины. Дело в том, что DevOps — это не какое-то конкретное направление деятельности, а профессиональная философия. Это методология, которая помогает разработчикам, тестировщикам и системным администраторам работать быстрее и эффективнее за счёт автоматизации и бесшовности.
Соответственно, DevOps-инженер — это специалист, который внедряет эту методологию в процесс работы:
Всё, что написано выше, происходит в близких к идеальным проектах. В реальном же мире приходится стартовать в проекте, где планирование пропустили, с архитектурой ошиблись, а об автоматизации задумались, когда все проекты встали. И разобраться во всех этих проблемах, решить их и сделать так, чтобы всё работало — ключевой навык DevOps-специалиста.
На рынке кадров есть путаница. Иногда бизнес ищет DevOps-инженеров на позицию системного инженера, билд-инженера или кого-то ещё. Обязанности в зависимости от размера компании и направления тоже меняются — где-то ищут человека на консалтинг, где-то просят всё автоматизировать, а где-то требуют выполнять расширенные функции системного администратора, умеющего программировать.
Что нужно для старта в профессии
Вход в профессию требует предварительной подготовки. Просто прийти на курсы с нуля, ничего не понимая в IT, и выучиться до уровня junior не получится. Нужен технический бэкграунд:
Что должен знать DevOps
Хороший DevOps-инженер — это многопрофильный специалист с очень большим кругозором. Для успешной работы вам придётся разобраться сразу в нескольких IT-направлениях.
Разработка
DevOps напишет скрипт, который поможет разработчикам устанавливать код на сервер. Сделает программу, которая «на лету» тестирует отзывчивость баз данных. Напишет приложение для контроля за версионностью. Наконец, просто заметит потенциальную проблему в разработке, которая может появиться на сервере.
Сильный DevOps-специалист знает несколько языков, подходящих для автоматизации. Разбирается в них не досконально, но быстро напишет небольшую программу или прочитает чужой код. Если раньше с разработкой не сталкивались, начните с Python — у него простой синтаксис, на нём легко работать с облачными технологиями, есть много документации и библиотек.
Операционные системы
Знать все возможности каждой версии каждой системы невозможно — на такое обучение можно потратить тысячи часов и толку не будет. Вместо этого хороший DevOps понимает общие принципы работы на любой ОС. Хотя, судя по упоминаниям в вакансиях, большинство сейчас работают в Linux.
Хороший инженер понимает, в какой системе лучше разворачивать проект, какими инструментами пользоваться и какие потенциальные ошибки могут появиться в процессе внедрения или эксплуатации.
Облака
Рынок облачных технологий растёт в среднем на 20-25% в год — такая инфраструктура позволяет автоматизировать операции тестирования кода, сборки приложений из компонентов, доставки обновлений до пользователей. Хороший DevOps разбирается как в полностью облачных, так и в гибридных решениях.
В стандартных же требованиях к инженерам обычно значится GCP, AWS и Azure.
Сюда можно отнести и владение инструментами CI/CD. Обычно для непрерывной интеграции используется Jenkins, но стоит попробовать и аналоги. Их много, например, Buddy, TeamCity и Gitlab CI. Полезным будем изучить Terraform — это декларативный инструмент, помогающий удалённо поднимать и настраивать инфраструктуру в облаках. И Packer, который нужен для автоматического создания образов ОС.
Системы оркестрации и микросервисы
У микросервисной архитектуры есть много преимуществ — стабильность, возможность быстрого масштабирования, упрощение и повторные использования. DevOps понимает, как работают микросервисы, и может предупредить потенциальные проблемы.
Досконально знает Docker и Kubernetes. Понимает, как работают контейнеры, как строить систему так, чтобы можно было отключать часть из них без последствий для общей системы в целом. Например, умеет построить Kubernetes-кластер при помощи Ansible
Что ещё попробовать будущему DevOps
Перечислять инструменты, которые могут пригодиться в работе DevOps-инженеру, можно бесконечно. Кто-то работает над оркестрацией проектов, другие большую часть времени занимаются автоматизацией развёртывания и тестирования, третьи повышают эффективность в управлении конфигурациями. В процессе будет понятно, куда копать и какие проекты пригодятся.
Вот ещё небольшой минимум, который поможет на старте:
Почему стоит начать изучать DevOps сейчас
На рынке DevOps-инженеров — кадровый голод. Это условно подтверждается количеством и качеством вакансий:

Обратите внимание на зарплатные требования соискателей
Не меньше востребован DevOps и в мире — если вы собрались на релокацию в США или Европу, то только на портале Glassdoor таких специалистов ищут больше 34 тысяч компаний. Из частых требований — опыт 1–3 года, умение работать с «облаками» и не бояться консалтинговых функций.
На фрилансе предложений в разы меньше — DevOps-инженеров в основном ищут в штат и на полный день.

Найти подходящий проект на фрилансе сложно, но можно
Условный карьерный путь DevOps-инженера можно представить примерно так:
DevOps — это сложно. Нужно сочетать в себе навыки сразу нескольких профессий. Стать человеком, который готов предложить улучшение там, где другие IT-специалисты даже не думают о чем-то другом. За это много платят, но и объем знаний потребуется большой.
Сколько зарабатывают DevOps
Средняя медианная зарплата по данным за второй квартал 2019 года у девопсов находится в вилке между 90 и 160 тысячами рублей. Есть предложения дешевле — в основном 60–70 тысяч.
Постоянно есть предложения до 200 тысяч, встречаются вакансии с зарплатой до 330 тысяч рублей.
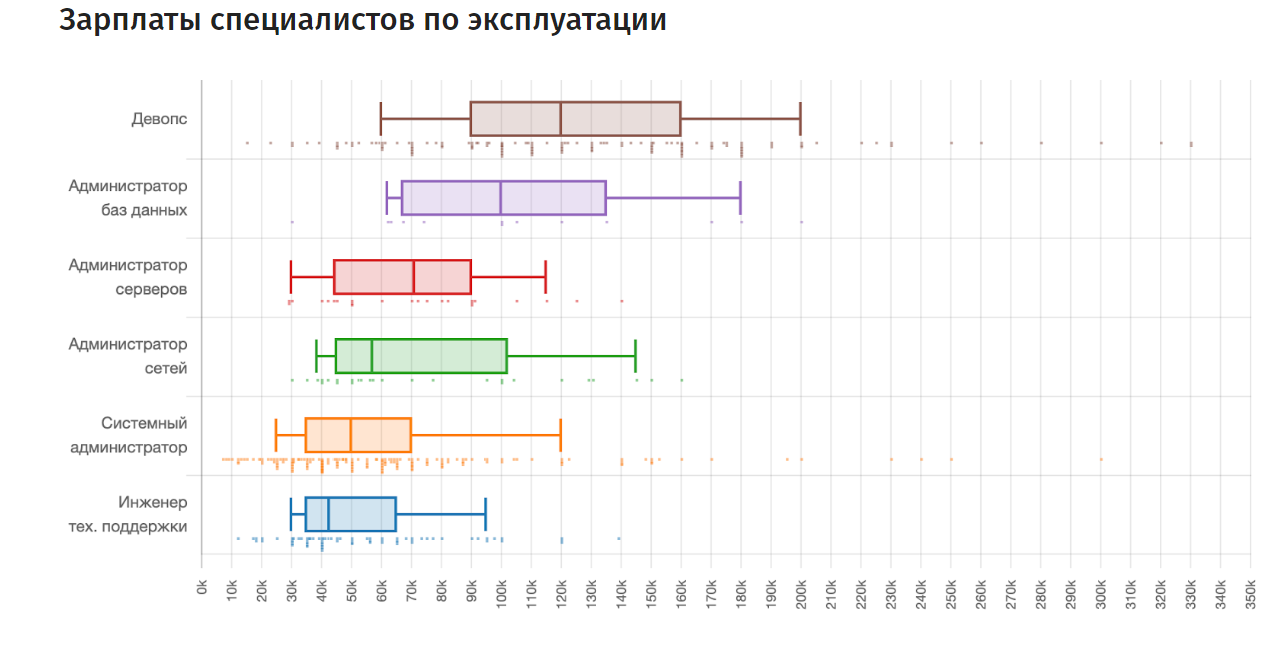
Среди специалистов по эксплуатации DevOps оплачивается выше остальных. Источник: Хабр.Карьера
DevOps-инженеры, в том числе начинающие, сейчас требуются в крупные банки, корпорации, облачные сервисы, торговые системы и другие организации, которые заботятся о поддержании своих IT-решений.
Отличным кандидатом на младшую вакансию с зарплатой в 60–90 тысяч станет начинающий системный администратор с опытом около года и профильным дипломом.

Такой статистики нет, но по ощущениям, людям, у которых есть опыт в Linux, платят больше
Что смотреть и читать для роста в профессии
Чтобы погрузиться в мир DevOps, попробуйте сразу несколько источников информации:
Где учиться на DevOps
Получить структурированные знания можно на курсе «DevOps-инженер» в Нетологии. Вы научитесь полному циклу методологии:
Чистый девопс: как возникло и развивалось понятие «DevOps»

В интернете есть уже тысячи споров о том, чем является DevOps. Мы решили подойти иначе: не навязывать вам точку зрения «понимайте это слово так-то», а оглянуться в прошлое и проследить историю его возникновения. Что привело к появлению DevOps? Какие люди первыми стали употреблять это слово и что они под ним подразумевали? Что изменилось за это время, а что осталось неизменным? И что там дальше?
А разобравшись со всем этим, в итоге можно обнаружить, что теперь и на вопрос «что такое DevOps» отвечаешь себе более четко.
Предыстория: как не утонуть в водопаде?
До разговора непосредственно о DevOps вспомним, что ему предшествовало.
Как известно, главная идея DevOps в эффективном сотрудничестве разработки («Dev») и эксплуатации («Ops»). Конечно, эффективное сотрудничество разных специалистов — это всегда хорошо, но почему именно в этом случае ему уделяют столько внимания? Потому что здесь оно помогает бизнесу добиваться многих важных для него целей: быстрее выводить решения на рынок, оперативнее восстанавливаться при сбоях и так далее.
А эти цели люди преследовали задолго до того, как слова «development» и «operations» сошлись вместе. Обратимся к истории.
Можно сказать, что разработчики в современном понимании (они сидели за терминалом и писали код) появились после 1957 года, когда изобрели первый высокоуровневый язык программирования FORTRAN. До этого как таковых менеджерских подходов к разработке не было — написание программ для тех самых компьютеров размером с дом было штучным продуктом. Но затем все стало меняться.
К концу 1970-х и 1980-х разработчики могли уже регулярно сидеть за рабочими станциями, писать код, компилировать его и тестировать на одном компьютере. Развертывание состояло из компиляции и копирования на десятки дискет. Компании начали открывать вакансии программистов для написания «исходного кода» — термина, который только недавно вошел в лексикон. Начал расти рынок коммерческого ПО и массовой разработки.
В 1970 году мир узнал о водопадной (или каскадной) модели разработки. Она была предложена американцем Уинстоном Ройсом — директором центра Lockheed Software Technology. Описанный подход напоминал конвейерное производство — вся работа распределялась по стадиям (анализ, проектирование, написание кода, тестирование, релиз), к следующей стадии можно было переходить только после завершения предыдущей. Никакие поздние изменения не допускались.
Это был прорыв — наконец-то появилась какая-то система, позволяющая контролировать разработку. Проблема была в том, что такой подход не годился для сложных проектов, где требовалась итеративная разработка (о чем и говорил сам Ройс).
Как писал Роберт Мартин в Clean Agile: Back to Basics («Чистый Agile», Питер, 2020): «Крупная работа не выполняется большими командами. На самом деле крупная работа выполняется большим количеством маленьких команд, которые в свою очередь выполняют много небольших задач. В 1950-х и 60-х годах программисты понимали это на уровне инстинкта. Но в 1970-е годы про это просто-напросто забыли».
 Водопадная модель: ожидание и реальность
Водопадная модель: ожидание и реальность
До 1990 года разработчики работали в основном по водопадной модели, пытаясь ее как-то модифицировать. Но даже она не спасала от проблем — дедлайны все равно срывались, бюджеты оценивались неадекватно, а конечный результат не всегда был предсказуем. По сути, до конца проекта заказчик не знал, что в итоге получит. К концу 80-х оформилась так называемая итеративно-инкрементальная разработка.
А к середине 90-x сообщество через боль и слезы наконец осознало, что принципы разработки необходимо перезагрузить.
В 2001 году в городке Сноуберд был составлен Agile Manifesto. Про сам манифест вы наверняка слышали, но обращали ли вы внимание на то, насколько тезисы «12 принципов Agile-разработки» близки DevOps? «Deliver frequently», «continuous delivery» — кажется, если заменить заголовок на «12 принципов хорошего DevOps» и запостить на Хабр, многие не заметят никакого подвоха.
Позже авторы манифеста развивали его идеи. В числе авторов Agile Manifesto, помимо того же Роберта Мартина и других известных людей вроде Мартина Фаулера, был Алистер Кокберн — и в 2004-м он описал методологию разработки ПО Crystal Clear. А дальше идеи подхватывали и развивали уже другие люди: например, в 2006-м системный администратор Марсель Вегерманн написал эссе на немецком языке, посвященное использованию принципов разработки ПО Crystal Clear, Scrum и Agile в области системного администрирования. Можете посмотреть его короткое выступление 2008-го по мотивам этой работы на Chaos Communication Congress.
Обращение Марселя не стало особо популярным, но оно показывает существование спроса на «Agile в эксплуатации»: не только в разработке хотели всё улучшить. В том же 2008-м системный администратор и Agile-практик Патрик Дебуа выступил на Agile Conference в Торонто с докладом «Agile infrastructure and operations», и сыграл куда большую роль. Но об этом чуть позже.
Дорога в облака
А что, кроме Agile, способствовало появлению DevOps? Изменение IT-ландшафта: появление новых технологий и реакция индустрии на них.
Например, в 90-е стали бурно развиваться интернет и облачные технологии. Это меняло многое — стал необходим новый способ разработки и доставки. В 1995 году появилась также СУБД MySQL, помогавшая создавать динамические веб-сайты и приложения.
Виртуализация программных и аппаратных сред возникла еще в 1964 году, с началом разработки ОС IBM CP-40, но стала массово востребованной позже. Виртуализация вводила дополнительный уровень абстракции между исполняемым кодом и системным ПО, разделяя разработку и эксплуатацию.
Развитие виртуализации, облачных технологий и интернета привело к появлению управления ИТ-инфраструктурой, как кодом, и позволило строить работу иначе, тестируя приложения в производственных средах на ранних этапах цикла разработки.
Со всем этим «быстрая доставка софта» превратилась в насущную потребность. Теперь бизнес требовал, чтобы софт создавался быстро, но при этом качественно и с минимальными издержками.
Для этого мало было просто писать код, нужно было качественно обслуживать его. Степень автоматизации росла, но эксплуатация явно не поспевала за разработкой. И в итоге, хотя Agile возник со стороны разработки, DevOps породили в первую очередь люди, которым были хорошо видны проблемы с operations.
Дебуа и другие
Одним из таких людей и был Патрик Дебуа. Он помогал министерству Бельгии с миграцией дата-центров и работал в связке с несколькими Agile-командами. Дебуа должен был координировать действия между командами разработки приложений и эксплуатационными командами (сервер, сеть баз данных).
Патрик столкнулся с тем, что между командами не было понимания и согласованности. При этом команда разработки работала по Agile и показывала высокую производительность. Тогда Дебуа решил провести эксперимент и внедрить Скрам в работу команды эксплуатации.
На конференции Agile 2008 в Торонто он выступил с докладом «Agile Operations and Infrastructure: How Infra-gile are You?», где рассказал о своем опыте изменения эксплуатационной работы. Он говорил о применении принципов Agile в инфраструктуре, а не при написании кода. Но в Agile-сообществе доклад широкого отклика не получил.
Большая часть его материала посвящена трем событиям: миграции дата-центра, улучшению процесса аварийного восстановления и обновлению сервера приложений. Наиболее успешной попыткой оказалась миграция дата-центра, но при этом команда не решила ключевую проблему в SLA. И неудача крылась в вопросах менеджмента и культурном взаимодействии (как между Agile-командами и традиционными «водопадными» командами, так и между отделами по эксплуатации, инфраструктуре и разработке).
 Выступление Патрика Дебуа на конференции DevOops 2020
Выступление Патрика Дебуа на конференции DevOops 2020
А дальнейшему развитию движение обязано курьезному случаю. Программист Эндрю Клэй Шафер, интересовавшийся проблемами в IT, предложил на той же конференции провести встречу-дискуссию по гибкой инфраструктуре (Agile Infrastructure). Однако тема настолько не привлекла внимание зрителей, что он даже сам не пошел на свое мероприятие, посчитав его никому не нужным. А вот Патрик Дебуа пришел. И для него эта «фан-встреча, куда никто не пришел» наоборот стала сигналом, что раз кто-то ее придумал, значит, кому-то все-таки это нужно! Он связался с Эндрю и продолжил обсуждение гибких методологий в инфраструктуре с ним напрямую.
Помимо Дебуа, DevOps связан с именем Джона Оллспоу, который работал тогда в компании Flickr. Компания начала внедрять новые процессы и делиться опытом с сообществом. Оллспоу был ведущим инженером по эксплуатации, которому поручили разобраться с масштабированием нового проекта и миграцией данных. В 2007 году к Flickr присоединился Пол Хэммонд и в 2008 году стал техническим директором, возглавив отдел разработки вместе с Оллспоу.
На конференции Velocity Santa Clara 2009 Хэммонд и Оллспоу вместе представили доклад 10+ Deploys per Day: Dev and Ops Cooperation at Flickr. Как можно видеть, хотя в названии еще не было слова «DevOps», до него осталось буквально полшага. Вот этот доклад:
В докладе они описали основной конфликт Dev и Ops: разработчики посвящают свою жизнь внесению изменений, а для эксплуатации любое изменение — возможная причина отказов и сбоев. Однако изменения жизненно необходимы бизнесу, а значит, вместо ведения войн задача Ops — дать бизнесу возможность развиваться.
Хэммонд и Оллспоу предлагали создавать инструменты, снижающие риск изменений и инструменты для быстрого восстановления после сбоев.
Также они предлагали следующее:
Общий контроль версий как для разработки, так и для эксплуатации.
Настройку одноэтапной системы сборки.
Развертывание за один шаг.
Журнал развертывания (Кто? Когда? Что?).
И самое главное: в компании важно создать культуру доверия, чтобы эксплуатация знала, чем занимается разработка, и наоборот. Оллспоу просил обратить пристальное внимание на этот момент, так как видел, что слушателей больше интересует техническая сторона доклада. Люди, процессы и ПО связаны между собой гораздо сильнее, чем принято считать.
Нельзя сказать, что этот доклад немедленно перевернул индустрию: слова про «10 деплоев в день» для многих звучали либо враньем, либо безумием, либо пустым бахвальством крупной компании («ну они там могут себе позволить такое, а нам-то с этого что»).
Но доклад вдохновил конкретного человека — Патрика Дебуа. Ему не нравилось, что тогда были конференции о разработке и конференции об инфраструктуре, но не было мероприятия, где две аудитории пересекались бы и общались. И совместный доклад Оллспоу и Хэммонда убеждает его, что такое мероприятие необходимо. Дебуа решает создать конференцию одновременно и для «dev», и для «ops».
Он называет её DevOpsDays («потому что Agile System Administration было слишком длинно») и впервые проводит в 2009-м в Бельгии. После завершения конференции ее участники продолжили обсуждать поднятые темы в Твиттере, где название мероприятия сократилось до хэштега #DevOps. А в итоге слово, стихийно возникшее как хэштег, прижилось настолько, что сегодня гугл находит его на миллионах страниц. Так что этим названием мы обязаны Патрику, хотя сам он совершенно не ожидал такого эффекта.
В 2010-м конференция DevOpsDays впервые прошла в США, и там это тоже дало плодотворную почву для дискуссий. Дэймон Эдвардс и Джон Уиллис тогда придумали аббревиатуру CAMS (Culture, Automation, Measurement, Sharing) — культура, автоматизация, измерение и совместное использование. Джез Хэмбл позже добавил L (Lean) — бережливый. Так были обозначены ключевые принципы DevOps и появился фреймворк для оценки готовности к переходу в DevOps.
Кстати, Джон Уиллис стал одним из ключевых людей для всего явления (например, как соавтор книги «Руководство DevOps»), много выступал в связи с ним, и одно из таких выступлений было на нашей конференции DevOops:
Служить и доставлять
Бывший технический директор компании Tripwire Джин Ким в работе The Three Ways: The Principles Underpinning DevOps (иллюстрации ниже взяты из оригинальной статьи) пишет про так называемые «Три пути» (или три принципа), которые позволяют добиться устранения отсутствующих связей между Dev и Ops.
Позже Ким стал соавтором бизнес-романов The Phoenix Project: A Novel about IT, DevOps, and Helping Your Business Win («Проект “Феникс”», Эксмо, 2015) и The Unicorn Project (IT Revolution Press, 2019), герои которых идут именно по этим трем путям. Первая книга стала основополагающей для погружения и понимания процесса внедрения DevOps в компании.
В итоге «три пути» в DevOps-контексте возникают регулярно: например, на нашей конференции DevOops 2020 Виталий Дмитриев из «Липтсофт» тоже попытался вернуться к основам и рассказал о своем опыте применения «Трех путей».
Итак, что же это за три пути?
Первый путь: системное мышление

Первый путь — рассматриваем производительности всей системы в целом и сосредотачиваемся на создании ценности. Формируем требования, которые проходят через разработку и передаются в эксплуатацию. Там клиенту предоставляется новая ценность в виде сервиса.
Второй путь: усиление обратной связи

Второй путь — создаем петлю обратной связи. По сути цель любой инициативы по улучшению процесса — сократить и усилить петли обратной связи, чтобы нужные исправления можно было вносить постоянно.
Третий путь: культура экспериментов и обучения

Третий путь — создаем культуру, способствующую двум вещам: постоянному экспериментированию и извлечению уроков из неудач. Люди должны понимать, что повторение и практика являются предпосылками к мастерству.
Герои книги «Проект “Феникс”» вот так справляются с этой задачей:
«Очень хорошо, — говорит он. — Ты объединил инструменты — визуальное управление работой и контроль работы через систему. Это важная часть первого пути, то есть ты создал быстрое течение работы между разработчиками и отделом IT-сопровождения. Карточки на доске — один из лучших способов сделать это, потому что все наглядно видят рабочий процесс. Теперь ты должен постоянно снижать объем незапланированной работы, это второй путь».
С ростом популярности идеи вокруг нее может вырасти целый карго-культ. И DevOps тоже не избежал этой участи, став жертвой своего успеха. В Сети много историй, как компании в погоне за эффективностью допускали ошибки и заканчивалось все плачевно.
Так что, дело в культуре?
По данным Gartner, к 2023 году 90% инициатив DevOps не оправдают ожиданий. Почему? Из-за неверного понимания сути концепции и неправильного подхода к внедрению. Раджеш Сетху, директор DevOps в Replicon сказал в 2018 году: «Основная причина того, что DevOps внедряется сложнее, чем другие методологии, заключается в том, что он объединяет культурные изменения с эксплуатацией и разработкой. Изменение бизнес-культуры — особенно в крупных компаниях с устоявшимися процессами — совсем не то, что можно мгновенно преобразовать на уровне людей, процессов и информации».
Всё это порождает неправильные ожидания, которые потом выливаются в разочарование. Реальная эффективность теряется за внешними атрибутами, так как на первое место ставятся инструменты, а не культура процесса.
К 2015 году идеи DevOps становятся популярней — они сулят успех в поставке ПО, но из-за отсутствия четкого зафиксированного определения разные компании начинают эти идеи понимать по-своему.
Это DevOps?
Представьте себе мир, в котором владельцы продуктов, разработка, контроль качества, ИТ-операции и Infosec работают вместе не только для того, чтобы помогать друг другу, но и для обеспечения успеха всей организации. Работая для достижения общей цели, они обеспечивают быстрое внедрение запланированных работ в производство, обеспечивая при этом стабильность, надежность, доступность и безопасность мирового уровня.
За время существования этого понятия оно по-разному интерпретировалось компаниями и людьми, все его примеряли на себя и проверяли на прочность. В этой части мы собрали распространенные убеждения про DevOps и расскажем про них. А насколько быть согласными с ними — решайте сами.
Инструменты
Твиттер-аккаунт «DevOps Борат» сообщает нам, что просто совершить ошибку — это в природе людей, а вот для автоматического распространения ошибки на все сервера без #devops не обойдешься.
Несмотря на шуточный посыл, здесь кроется стереотипное восприятие практик DevOps как набора инструментов. Часто, когда люди говорят, что используют DevOps, то подразумевают под этим, что используют Puppet для управления конфигурацией серверов, Ansible — для развертывания версий приложений, Cloudify — для оркестровки и так далее.
Но еще сам Патрик Дебуа в 2012 году говорил, что DevOps — это человеческая проблема. И согласно такому взгляду, важно не то, какой инструмент для чего используется. DevOps — это не инструмент, а ситуация, когда:
Разработка и эксплуатация работают в тесном сотрудничестве.
Всем понятна работа друг друга: разработчики знают систему, для которой пишут код (и приспосабливаются к ней), а администраторы знают код, который развертывают (и понимают, как это влияет на систему).
Всё разрабатывается в короткие итерации и может быстро развертываться (как инфраструктура, так и приложения), чтобы можно было сразу устранять ошибки.
Дэймон Эдвардс сетовал, что слов о важности культуры было сказано достаточно («Все начинается с культуры», «DevOps — это культурное и профессиональное движение», «Культура важнее инструментов» и т. д.). Но как только все соглашаются с тем, что культура превыше всего, разговор переходит к инструментами и… снова к инструментам.
В 2012 году, когда DevOps был уже достаточно популярен, один из основоположников фреймворка CAMS Джон Уиллис опубликовал мрачный твит с хештегом #devopsdead, где заявил, что убирает букву C (culture) из аббревиатуры CAMS. В ответ Патрик Дебуа посоветовал ему не отчаиваться.
Культура — это все-таки самая сложная часть DevOps.
Команды DevOps
В целях внедрения DevOps в компании могут начать создавать новые «DevOps-команды» вместо устранения разобщенности в имеющихся. Но если мы вернемся к основам, то поймем, что DevOps — это не человек или какая-то вещь, это процесс и культура. Если в компании есть команда DevOps, состоящая из инженеров DevOps, то теряется весь смысл, так как DevOps должен внедряться в кросс-функциональные команды.
Конечной целью должен стать уход от старого образа мышления, упрощение процесса разработки и концентрация на людях и процессах. Да и старина Фредерик Брукс еще заметил — простое добавление новых людей в систему не помогает ей работать быстрее или лучше.
DevOps и Agile
Например, об этом неоднократно говорил Михаэль Хюттерманн — Java-чемпион, инженер по доставке и эксперт по Agile и DevOps. В своей книге DevOps for Developers он пишет, что Agile обязательно должен внедряться в отдел эксплуатации и это позволит устранить конфликт между Dev и Ops.
DevOps-инженеры
Логично предположить, что если DevOps — это культура и процесс, а не инженерная специальность, то и DevOps-инженеров быть не должно, об этом мы уже писали. Сторонники такой позиции говорят, что это словосочетание появилось от желания менеджеров и HR-ов упростить себе жизнь: если появилась какая-то потребность (в данном случае в DevOps), то можно просто ввести роль, которая эту потребность закроет!
Другие возражают на это: существует много задач «на стыке», кто-то их должен выполнять, и если в компании выделили отдельную роль для таких людей, почему бы тогда не назвать их «девопс-инженерами»?
Вне зависимости от того, считаете ли вы это словосочетание осмысленным, бессмысленно спорить с тем, что люди его активно используют:
 Так росла популярность «DevOps-инженеров» (вне зависимости от того, существуют ли они)
Так росла популярность «DevOps-инженеров» (вне зависимости от того, существуют ли они)
Тогда вопрос в другом: что люди им обозначают в реальности? Похоже, что совершенно разные вещи в зависимости от ситуации. А если помониторить вакансии «DevOps-инженера», то список требований может оказаться колоссальным. Практически всё и сразу — и разработчик, и сисадмин, и специалист по безопасности!
А вот как в 2021 году говорит о своей роли один российский DevOps-инженер:
Программист пишет код, а девопс его внедряет. Естественно, в работе тех и других есть куча нюансов. Мало просто внедрить код, для этого нужны соответствующие инструменты, а их много, и настройкой этих инструментов тоже занимается девопс. Еще он немного админ, разработчик и тестировщик. Задачи могут сильно отличаться в зависимости от компании. Я бы сказал, что нет единого определения того, кто такой девопс и что он должен делать. Это не проблема конкретной профессии — просто ИТ-сфера стала усложняться и появилось много абстракций.
DevOps-инженерами становятся разработчики, которые интересуются развертыванием и сетевой эксплуатацией, либо системные администраторы, которые увлекаются написанием скриптов и кода и переходят в сторону разработки, где могут улучшить планирование тестирования и развертывания. В любом случае, это люди, которые вышли за рамки определенных сфер своей компетенции и имеют более целостное представление о своей технической среде.
Само по себе — это неплохо, но чтобы не расстраивать Дэймона Эдвардса и Джона Уиллиса, еще раз отметим, что по их мнению DevOps — это не что-то конкретное, выраженное в инструментах или конкретных ролях, а культура.
DevOps сейчас
Итак, что же такое DevOps в 2021 году? Инструменты, люди, процессы? Умение писать на Bash скрипты для кофемашины?
Как и многие фреймворки гибких методологий, DevOps не имеет четкого определения, и каждая компания будет объяснять его по-своему. Но его главная идея DevOps — это культура сотрудничества, и эта идея оставалась неизменной всегда. Об этом говорили Патрик Дебуа и Эндрю Клэй Шафер, Пол Хэммонд и Джон Оллспоу, а теперь об этом говорят люди вроде Баруха Садогурского.
А что тогда изменилось за 12 лет существования понятия? Во-первых, практики DevOps постепенно меняли общий подход к поставке ПО. Из новомодного слова все превращалось в общепринятую норму. Как в свое время Agile стал стандартом в разработке, так и DevOps становится стандартом в поставке.
А во-вторых, как и Agile в свое время, идея получает дальнейшее развитие. Например, в 2020 году Патрик Дебуа выступал на нашей конференции DevOops c докладом DevSecOps: More of the same — back to the roots, и в частности рассказывал про то, как важно вернуться к основам и посмотреть, что стоит за модным словом «Devops». А сейчас, уже практически из зрелой методологии вырастает новая — DevSecOps. Ее жизнеспособность покажет время и практика, а пока еще раз напомним, что самое важное в DevOps — это люди и культура.

А напоследок зададим такой вопрос: если с понятием «DevOps» всё так неоднозначно, то какой тогда должна быть DevOps-конференция? Как сделать, чтобы она не превратилась в набор технических фактов про Kubernetes и Terraform (мало связанный с исходным значением слова), но в то же время не превратилась в пустословие «наша культура культурнее вашей культуры», где можно сколько угодно лить воду?
Мы не первый год проводим DevOops и считаем так: на девопс-конференции нужен баланс между этими составляющими. Поэтому программа у нас делится на разные логические блоки: есть про процессы и культуру, есть про SRE (вот тут всякие кубернетесы-терраформы), есть про Cloud Native.
Если вы согласны с таким подходом, то вам наверняка будет интересно на следующем DevOops, который пройдет 8–11 ноября. А если захотелось повозражать, дополнить, поделиться своим взглядом — добро пожаловать в комментарии.
Что такое DevOps
Определение DevOps очень сложное, поэтому приходится каждый раз запускать дискуссию об этом заново. Только на Хабре тысяча публикаций на эту тему. Но если вы это читаете, то наверняка знаете, что такое DevOps. Потому что я — нет. Привет, меня зовут Александр Титов (@osminog), и мы просто поговорим о DevOps, и я поделюсь своим опытом.

Долго думал, как сделать мой рассказ полезным, поэтому здесь будет много вопросов — тех, которые я сам себе задаю, и тех, которые я задаю клиентам нашей компании. Отвечая на эти вопросы, понимание становится лучше. Я расскажу зачем нужен DevOps с моей точки зрения, что это такое, опять же, с моей позиции, и как понять, что вы движетесь к DevOps снова с моей точки зрения. Последний пункт будет через вопросы. Отвечая на них самому себе, вы сможете понять, движется ли ваша компания к DevOps или в чем-то есть проблемы.
Одно время я гулял по волнам слияний и поглощений. Сначала я поработал в маленьком стартапе Qik, потом его купила чуть большая компания Skype, которую потом купила еще чуть большая компания Microsoft. В этот момент мне стало доступно видение, как трансформируется представление о DevOps в разных по величине компаниях. После этого мне стало интересно уже с точки зрения рынка смотреть на DevOps, и мы с коллегами организовали компанию Экспресс 42. Уже 6 лет мы движемся на ней по волнам рынка.
Зачем DevOps
Первый вопрос, который преследует всех и всегда — зачем? Многие считают, что DevOps — это просто автоматизация или похожая штука, которая уже была в каждой компании.
— У нас был Continuous Integration — это значит, уже был DevOps, и зачем вся эта ботва нужна? Там за границей развлекаются, а нам работать мешают!
За 9 лет развития сообщества и методологии уже стало понятно, что это все-таки не маркетинговые блестки, но все равно не до конца понятно зачем он нужен. Как у любого инструмента и процесса, у DevOps есть конкретные цели, которые он в итоге решает.
Все это связано с тем, что мир меняется. Он уходит от подхода enterprise, когда компании движутся сразу к мечте, как пел наш питерский классик, из точки А в точку В по определенной стратегии, с построенной для этого определенной структурой.
В принципе в IT все и должно быть построено под этот подход. Здесь IT используется исключительно для автоматизации процессов.
Автоматизация не часто меняется, потому что когда компания катится по наезженной колее — что там менять? Работает — не трогай. Сейчас в мире подходы меняются, и тот, что называется словом Agile, говорит о том, что конечной точки В сразу не видно.
Когда компания идет по рынку, работает с клиентом — она постоянно исследует рынок и меняет конечную точку В. Причем чем чаще компания меняет свое направление, тем больше она в итоге успешна, потому что выбирает больше рыночных ниш.
Стратегию демонстрирует интересная компания, про которую я узнал недавно. One Box Shave — сервис по доставке бритв и бритвенных принадлежностей по подписке в коробке. Они умеют кастомизировать свою «коробочку» под разных клиентов. Этим занимается определенный софт, который потом отправляет заказ на корейскую фабрику, выпускающую товар.
Этот продукт купила компания Unilever за 1 млрд. долларов. Сейчас он конкурирует с Gillette и отъел у него значительную долю потребителей на американском рынке. One Box Shave говорят:
— 4 лезвия? Вы серьезно? Зачем вам это надо — это никак не улучшает качество бритья. Специально подобранный крем, отдушка и качественная бритва с двумя лезвиями решают гораздо больше вопросов, чем эти дурацкие 4 лезвия Gillette! Так скоро до 10 дойдем?
Так мир меняется. Unilever заявляют о том, что у них есть крутая IT-система, которая позволяет это делать. В итоге это выглядит как концепция Time-to-market, о которой уже кто только не говорил.
Смысл Time-to-market не в том, как часто мы деплоимся. Часто можно деплоить, но при этом релизные циклы будут длинными. Если трехмесячные релизные циклы накладывать друг на друга, сдвигая на недельку, получается, что компания как будто бы деплоится раз в неделю. А от идеи до конечной реализации проходит 3 месяца.
Time-to-market — это про минимизацию времени от идеи до конечной реализации.
В этом случае с рынком взаимодействует ПО. Так у One Box Shave с клиентом взаимодействует сайт. У них нет продавцов — просто сайт, где посетитель кликает и оставляет пожелания. Соответственно, на сайте надо постоянно размещать что-то новое, обновлять его в соответствии с пожеланиями. Например, в Южной Корее бреются не так, как в России, и им нравится в отдушке не запах сосны, а, например, морковки ванили.
Поскольку требуется быстро менять наполнение сайта, разработка ПО сильно меняется. Через ПО мы должны узнавать, что хочет клиент. Раньше мы это узнавали какими-то обходными путями, например, через бизнес-менеджмент. Потом проектировали, закладывали требования в IT-систему, и все было круто. Сейчас по-другому — ПО проектируется всеми, кто включен в процесс, в том числе и инженерами, потому что они узнают через технические характеристики, как работает рынок, и тоже делятся с бизнесом своими инсайтами.
Например, в компании Qik мы внезапно узнали, что людям очень нравится загружать контакт-листы на сервер, и они положили нам приложение. Изначально мы об этом не задумывались. В классической компании все бы решили, что это бага, так как в спеке не написано, что это должно классно работать и вообще было реализовано на коленке, выключили бы фичу и сказали: «Это никому не нужно, самое главное, что основная функциональность работает». А технологическая компания в этом видит возможность и начинает менять софт в согласии с этим.
В 1968 году прозорливый парень Мелвин Конвей сформулировал следующую идею.
Организация, которая создает систему, ограничена дизайном, который копирует структуру коммуникации в этой организации.
Если подробнее, — чтобы производить системы другого типа, надо еще вдобавок иметь коммуникационную структуру внутри компании другого типа. Если у вас коммуникационная структура верхне иерархическая, то это не позволит вам делать системы, которые могут обеспечивать очень высокий показатель Time-to-market.
Почитать про закон Конвея можно по ссылкам. Он важен для понимания культуры или философии DevOps, так как единственное, что базово меняется в DevOps — это именно структура коммуникации между командами.
С точки зрения процесса, до DevOps все стадии: аналитика, разработка, тестирование, эксплуатация, проходили линейно.
В случае DevOps все эти процессы идут одновременно.
Time-to-market только так и может выполняться. Для людей, которые работали в старом процессе, это выглядит несколько космически, и вообще так себе.
Так зачем нужен DevOps?
Для разработки цифровых продуктов. Если у вас в компании нет цифрового продукта, DevOps не нужен — это очень важно.
DevOps преодолевает скоростные ограничения последовательной схемы производства ПО. В нем все процессы происходят одновременно.
Увеличивается сложность. Когда DevOps-евангелисты рассказывают, что с ним вам станет проще выпускать ПО — это бредятина.
С DevOps все будет только сложнее.
На конференции на стенде Авито можно было посмотреть, что такое задеплоить Docker-контейнер — нереальная задача. Сложность становится запредельной, надо жонглировать многими шариками одновременно.
DevOps меняет полностью процесс и организацию в компании — точнее, меняет не DevOps, а цифровой продукт. Чтобы прийти к DevOps, надо все-таки этот процесс полностью поменять.
Вопросы для специалиста
А что у вас? Вопросы, которые вы можете себе задать, работая в компании и развиваясь, как специалист.
Есть ли у вас стратегия по созданию цифрового продукта? Если есть — уже хорошо. Это значит, что ваша компания движется в сторону DevOps.
Ваша компания уже создает цифровой продукт? Это значит, что вы можете подняться еще на ступень выше, заниматься делами интереснее — с точки зрения DevOps опять-таки. Я только с этой точки зрения говорю.
Ваша компания один из лидеров рынка в нише с цифровым продуктом? Spotify, Яндекс, Uber — компании, которые находятся на пике технологического прогресса сейчас.
Задайте себе эти вопросы, и если все ответы отрицательные, то, возможно, вам и не стоит заниматься DevOps в этой компании. Если же вам тема DevOps реально интересна, может быть,… вам стоит перейти в другую компанию? Если ваша компания хочет пойти в DevOps, но на все вопросы вы ответили «Нет», то она напоминает этого прекрасного носорожика, который никогда не изменится.
Организация
Как я уже сказал, по закону Конвея в компании меняется организация. Начну с того, что мешает DevOps проникать внутрь компании именно с точки зрения организации.
Проблема «колодцев»
Английское слово «Silo» переведено здесь на русский как «колодец». Смысл этой проблемы в том, что между командами нет обмена информацией. Каждая команда копает свою экспертизу вглубь, при этом не строя общую карту, в которой можно ориентироваться.
Чем-то это напоминает человека, который только приехал в Москву и еще не умеет ориентироваться по карте метро. Москвичи обычно прекрасно знают свой район, а по всей Москве ориентируются по карте метро. Когда ты приезжаешь в Москву в первый раз, нет этого навыка, и ты просто дезориентирован.
DevOps предлагает пройти этот момент дезориентации и всем подразделениям вместе построить общую карту взаимодействия.
Этому мешают два фактора.
Следствие корпоративной системы управления. Она построена отдельными иерархическими «колодцами». Например, есть определенные KPI в компаниях, которые эту систему поддерживают. С другой стороны, мешают мозги человека, которому сложно выйти за пределы своей экспертизы и ориентироваться во всей системе. Это просто некомфортно. Представьте себе, что вы попали в аэропорт Бангкока — там быстро не сориентируешься. В DevOps тоже сложно ориентироваться, и поэтому люди говорят, что надо найти проводника найти, чтобы туда попасть.
Но самое главное, что проблема «колодцев» для инженера, который проникся духом DevOps, начитался Фаулера и кучу других книжек, выражается в том, что «колодцы» не позволяют делать «очевидные» вещи. Мы часто собираемся после DevOps Moscow, разговариваем друг с другом, и люди жалуются:
— Мы хотели просто CI запустить, а получилось, что менеджменту это не надо.
Это происходит именно из-за того, что CI и Continuous Delivery process находятся на границе многих экспертиз. Просто не преодолев проблему «колодцев» на организационном уровне, не получится продвинуться дальше, что бы вы не делали и как бы это грустно не было.
Каждый участник процесса в компании: разработчики бэкенда и фронтенда, тестирование, DBA, эксплуатация, сеть, копает в свою сторону, а общей карты не имеет никто, кроме управленца, который как-то их обозревает и управляет методом «разделяй и властвуй».
Люди борются за какие-то звездочки или флажки, каждый копает свою экспертизу.
В итоге, когда появляется задача все это соединить вместе и построить общий пайплайн, и за звездочки и флажки уже бороться не надо, появляется вопрос — а что делать-то вообще? Надо как-то договариваться, а как это делать, нас в школе никто не учил. Мы еще со школы научены: восьмой класс — ого! — по сравнению с седьмым классом! Здесь то же самое.
В вашей компании так же?
Чтобы это проверить, можно задать себе следующие вопросы.
Пользуются ли команды общими инструментами, вносят ли вклад в изменения этих общих инструментов?
Насколько часто команды переформируются — одни специалисты из одной команды переходят в другую команду? Именно в DevOps-среде это становится нормальным, потому что иногда человек просто не может понять, чем занимается другая зона экспертизы. Он переходит в другой отдел, две недельки там работает, чтобы создать для себя карту ориентации и взаимодействия с этим отделом.
Можно ли создать комитет по изменению и что-то изменить? Или для этого нужна сильная рука самого высшего руководства и распоряжение? Недавно я написал в Facebook, как один малоизвестный банк через распоряжения внедряет инструменты: написали распоряжение, год внедряем, смотрим, что происходит. Это, конечно, долго и печально.
Насколько важно для менеджеров получать личные достижения без учета достижений компании?
Если вы для себя ответите на эти вопросы, станет понятнее, есть ли у вас такая проблема в компании.
Инфраструктура как код
После того, как эта проблема пройдена, первая важная практика, без которой сложно продвинуться в DevOps дальше — это инфраструктура как код.
Чаще всего инфраструктуру как код воспринимают так:
— Давайте все автоматизируем на bash, обмажемся скриптами, чтобы у админок было меньше ручной работы!
Инфраструктура как код подразумевает, что IT-систему, с которой работаете, вы описываете в виде кода, чтобы постоянно понимать ее состояние.
Совместно с другими командами вы создаете карту в виде кода, которая всем понятна, по которой можно ориентироваться, навигировать. Без разницы, на чем это сделано — Chef, Ansible, Salt, или используются YAML-файлы в Kubernetes — нет разницы.
На конференции коллега из 2ГИС рассказывал, как они сделали свою внутреннюю штуку для Kubernetes, которая описывает устройство отдельных систем. Чтобы описать 500 систем, им потребовался отдельный инструмент, который это описание генерирует. Когда есть это описание, каждый может сверяться друг с другом, мониторить изменения, как его поменять и улучшить, чего не хватает.
Согласитесь, отдельные bash-скрипты обычно не дают этого понимания. В одной из компаний, где я работал, было даже название «write only»-скрипт — когда скрипт написан, а прочитать его уже невозможно. Думаю, что это вам тоже знакомо.
Инфраструктура как код — это код, который описывает актуальное состояние инфраструктуры. Над этим кодом совместно работает множество продуктовых, инфраструктурных и сервисных команд, и, самое главное, все они должны понимать, как этот код вообще работает.
Код сопровождается согласно лучшим практикам работы с кодом: совместная разработка, код-ревью, XP-programming, тестирование, пулреквесты, CI для инфраструктур кода — это все годно и можно использовать.
Код становится общим языком для всех инженеров.
Изменение инфраструктуры в коде не занимает много времени. Да, в инфраструктурном коде тоже может быть технический долг. Обычно команды сталкиваются с ним года через полтора после того, как начали внедрять «инфраструктуру как код» в виде кучи скриптов или даже Ansible, который они пишут как спагетти-код, и еще bash-скрипты туда подкидывают в топочку!
Важно: если вы еще не попробовали эту дрянь, запомните, что Ansible — не bash! Внимательно читайте документацию, изучайте, что вообще про это пишут.
Инфраструктура как код — это разделение инфраструктурного кода на отдельные слои.
Мы у себя в компании выделяем 3 базовых слоя, которые очень понятны и просты, но их может быть больше. Вы можете посмотреть на ваш инфраструктурный код и сказать, есть ли у вас это условие или нет. Если никакие слои не выделяются, то надо выделить время и порефакторить немножко.
Базовый слой — это как настраивается ОС, бэкапы и другие низкоуровневые штуки, например, как разворачивается Kubernetes на базовом уровне.
Уровень сервисов — это те сервисы, которые вы даете разработчику: логирование как сервис, мониторинг как сервис, база данных как сервис, балансировщик как сервис, очередь как сервис, Continuous Delivery как сервис — куча сервисов, которые отдельные команды могут предоставлять разработке. Это все необходимо описывать отдельными модулями в вашей системе управления конфигурацией.
Слой, где делаются приложения и описывается, как они будут разворачиваться поверх двух предыдущих слоев.
Контрольные вопросы
Есть ли у вас в компании общий инфраструктурный репозиторий? Контролируете ли вы технический долг в инфраструктуре? Используете ли вы практики разработки в инфраструктурном репозитории? Нарезана ли ваша инфраструктура на слои? Можно свериться со схемой Base-service-APP. Насколько сложно внести изменение?
Если вы сталкивались с тем, что внесение изменений занимало полтора дня, это значит, что у вас появился технический долг и с ним надо поработать. Вы как раз наткнулись на грабли технического долга в инфраструктурном коде. Я помню много таких историй, когда чтобы поменять какой-нибудь CCTL, надо переписать половину инфраструктурного кода, потому что творчество и желание все автоматизировать привело к тому, что везде все закоркожено, все ручки убраны, и нужно рефакторить.
Непрерывная поставка
Подобьем дебит с кредитом. Сначала появляется описание инфраструктуры, которое может быть довольно базовым. Необязательно все описывать детально, но какое-то базовое описание требуется, чтобы вы могли с этим работать. Иначе непонятно, поверх чего дальше вообще делать непрерывную поставку. Все эти практики разворачиваются одновременно, когда вы приходите к DevOps, но начинать нужно с понимания того, что у вас есть, и как этим управлять. Это как раз практика инфраструктура как код.
После того, как стало понято, что у вас есть, как этим управлять, вы начинаете придумывать, как код разработчика максимально быстро отправить на продакшн. Я имею в виду вместе с разработчиком — помним про проблему «колодцев», то есть не отдельные люди это придумывают, а командой.
Когда мы с Ваней Евтуховичем увидели первую книжку Джеза Хамбла и группы авторов «Continuous Delivery», которая вышла в 2009 году, то долго думали, как перевести ее название на русский язык. Хотели перевести как «Постоянно доставлять», но, к сожалению, перевели как «Непрерывная поставка». Мне кажется, что в нашем названии есть что-то такое русское, с напором.
Постоянно доставлять — это значит
Код, который лежит в продуктовом репозитории, всегда может быть выкачен в продакшн. Он может быть и не выкачан, но всегда готов к этому. Соответственно, вы всегда пишите код с трудно объяснимым чувством некоторого беспокойства под копчиком. Оно часто появляется, когда выкатываешь инфраструктурный код. Это чувство некоторого беспокойства и должно присутствовать — оно вызывает мозговые процессы, которые позволяют писать код немного по-другому. Это должно быть зафиксировано в правилах внутри разработки.
Чтобы постоянно доставлять, нужен формат артефакта, который проходит по инфраструктурной платформе. Если вы кидаете по инфраструктурной платформе разного формата «отходы жизнедеятельности», то она у вас становится не унифицированной, ее сложно сопровождать, возникает проблема технического долга. Формат артефакта необходимо выровнять — это тоже коллективная задачка: надо всем вместе собраться, пошуршать мозгами и придумать этот формат.
Артефакт непрерывно улучшается и меняется под продакшн-среду во время прохождения по пайплайну поставки. Когда артефакт двигается по пайплайну, он все время сталкивается с какими-то неудобными для него вещами, которые похожи на то, с чем сталкивается артефакт, который вы выкладываете в продакшн. Если в классической разработке этим занимается сисадмин, который делает выкатку, то в DevOps-процессе это происходит постоянно: тут его какими-то тестами покрутили, тут — в Kubernetes-кластер закинули, который более-менее похож на продакшн, тут внезапно запустили нагрузочное тестирование.
Это чем-то напоминает игру Пакман — артефакт проходит какую-то историю. При этом важно контролировать, реально ли код проходит историю и она как-то связана с вашим продакшн. Истории с продакшен можно затаскивать внутрь Continuous Delivery процесса: было так, когда что-то упало, теперь давайте этот сценарий просто запрограммируем внутрь системы. Каждый раз код будет проходить этот сценарий тоже, и вы не столкнетесь следующий раз с этой проблемой. Вы узнаете о ней сильно раньше, чем она выйдет к вашему клиенту.
Разные стратегии деплоев. Например, вы используете AB-тестирование либо канареечные деплойменты, чтобы по-разному «щупать» код на разных клиентах, получать информацию о том, как код работает, и сильно раньше, чем когда он выкатится на 100 млн пользователей.
«Постоянно доставлять» выглядит так.
Процесс поставки Dev, CI, Test, PreProd, Prod — это не отдельное окружение, это стейджи или станции с несгораемыми суммами, по которым проходит ваш артефакт.
Если у вас есть инфраструктурный код, который описан как Base Service APP, то он помогает не забыть все сценарии, и записать их тоже в виде кода для этого артефакта, продвигать артефакт и менять его по ходу движения.
Вопросы для самопроверки
Время от описания фичи до выкатки в продакшен в 95 % случаев меньше недели? Повышается ли качество артефакта на каждом этапе пайплайна? Есть ли история, по которой он проходит? Используете ли вы различные стратегии деплоя?
Если все ответы да, то вы нереально круты! Напишите ответы в комментарии — я буду рад).
Обратная связь
Эта самая сложная практика из всех. На конференции DevOpsConf коллега из Infobip, рассказывая о ней, немного путался в словах, потому что это действительно очень сложная практика про то, что надо мониторить вообще все!
Например, давным-давно, когда я работал в Qik и мы поняли, что надо мониторить вообще все. Мы это сделали, и у нас в Zabbix появилось 150 000 items, которые мониторятся постоянно. Это было страшно, технический директор крутил пальцем у виска:
— Ребята, вы зачем сервак насилуете непонятно чем?
Но потом произошел случай, который показал, что это реально очень крутая стратегия.
Постоянно начал падать один из сервисов. Изначально он не падал, что интересно, туда код не дописывался, потому что это был базовый брокер, в котором практически не было бизнес-функциональности — он просто гонял сообщения между отдельными сервисами. Сервис не менялся 4 месяца, и вдруг стал падать с ошибкой «Segmentation fault».
Мы были в шоке, открыли наши графики в Zabbix, и выяснилось, что, оказывается, полторы недели назад сильно изменилось поведение запросов в API-сервисе, который использует этот брокер. Дальше мы посмотрели, что изменилась частота посылки определенного типа сообщений. После выяснили, что это android-клиенты. Мы спросили:
— Ребята, а что у вас случилось полторы недели назад?
В ответ услышали интересную историю о том, что они переделали UI. Вряд ли кто сразу скажет, что поменял HTTP-библиотеку. Для android-клиентов это как мыло сменить в ванной — они просто это не помнят. В итоге, после 40 минут разговора, мы выяснили, что они все-таки сменили HTTP-библиотеку, и у нее изменились дефолтные тайминги. Это привело к тому, что изменилось поведение трафика на API сервере, что и привело к ситуации, которая вызвала гонку внутри брокера, и он начал падать.
Собирайте всю информацию о том, что происходит с артефактом на каждой стадии процесса поставки — не в продакшн.
Мониторинг грузите на CI, и там уже будут видны какие-то базовые вещи. Дальше вы их увидите и в Test, и в PredProd, и в нагрузочном тестировании. Собирайте информацию на всех стадиях, причем не только метрики, статистику, но и логи: как выкатилось приложение, аномалии — собирайте все.
В противном случае будет сложно разобраться. Я уже говорил, что DevOps — это бОльшая сложность. Чтобы справиться с этой сложностью, нужно иметь нормальную аналитику.
Вопросы для самоконтроля
Ваш мониторинг и логирование — это средство разработки для вас? Ваши разработчики, и вы в том числе, когда пишут код, думают о том, как его замониторить?
Узнаете ли вы о проблемах от клиентов? Понимаете ли вы клиента лучше из мониторинга и логирования? Понимаете ли вы систему лучше из мониторинга и логирования? Меняете ли вы систему просто потому, что увидели, что тренд в системе растет и понимаете, что еще 3 недели и все загнется?
Когда у вас есть эти три компонента, вы можете подумать о том, какая у вас в компании инфраструктурная платформа.
Инфраструктурная платформа
Смысл не в том, что это набор разрозненных инструментов, который есть в каждой компании.
Смысл инфраструктурной платформы в том, что все команды пользуются этими инструментами и развивают их совместно.
Понятно, что есть отдельные команды, которые несут ответственность за развитие отдельных кусков инфраструктурной платформы. Но при этом ответственность за развитие, работоспособность, продвижение инфраструктурной платформы несет каждый инженер. На внутреннем уровне это становится общим инструментом.
Все команды развивают инфраструктурную платформу, относятся бережно к ней как к собственному IDE. В своем IDE вы ставите разные плагины, чтобы все было красиво и быстро, настраиваете горячие клавиши. Когда вы открываете Sublime, Atom или Visual Studio Code, у вас там сыпятся ошибки кода и вы понимаете, что вообще невозможно работать, вам сразу становится грустно и вы бежите чинить свой IDE.
Точно также относитесь к вашей инфраструктурной платформе. Если вы понимаете, что с ней что-то не то, оставляйте заявку, если не можете починить сами. Если же там что-то простое — правьте самостоятельно, отправляйте pull request — ребята рассматривают, добавляют. Это несколько другой подход к инженерному инструментарию в голове разработчика.
Инфраструктурная платформа обеспечивает перенос артефакта от разработки клиенту с постоянным повышением качества. В ИП запрограммирован набор историй, которые случаются с кодом в продакшн. За годы разработки этих историй становится очень много, часть из них уникальны и относятся только к вам — их невозможно нагуглить.
В этот момент инфраструктурная платформа становится вашим конкурентным преимуществом, потому что в нее зашито то, чего нет в инструменте конкурента. Чем глубже ваша ИП, тем больше ваше конкурентное преимущество в смысле Time-to-market. Здесь появляется проблема vendor lock: вы можете взять себе чужую платформу, но используя чужой опыт, вы не будете понимать, насколько он релевантен к вам. Да, не всякая компания может построить платформу типа Амазона. Это сложная грань, где опыт компании релевантен ее положению на рынке, и спускать туда vendor lock нельзя. Об этом тоже важно подумать.
Схема
Это базовая схема инфраструктурной платформы, которая поможет вам наладить все практики и процессы в DevOps-компании.
Рассмотрим, из чего она состоит.
Система оркестрации ресурсов, которая предоставляет CPU, память, диск приложениям и другим сервисам. Поверх этого — сервисы низкого уровня: мониторинг, логирование, CI/CD Engine, хранилище артефактов, инфраструктура как код системы.
Сервисы более высокого уровня: база данных, как сервис, очереди как сервис, Load Balance как сервис, resizing картинок как сервис, Big Data фабрика как сервис. Поверх этого — пайплайн, который поставляет постоянно модифицированный код вашему клиенту.
Вы получаете информацию о том, как ваше ПО работает у клиента, меняете, опять поставляете этот код, получаете информацию — и так постоянно развиваете и инфраструктурную платформу, и ваше ПО.
На схеме delivery pipeline состоит из множества стейджей. Но это принципиальная схема, которая приведена для примера — не надо повторять ее один в один. Стейджы взаимодействуют с сервисами, как с сервисами — каждый кирпичик платформы несет свою историю: как выделяются ресурсы, как приложение запускается, работает с ресурсами, мониторится, меняется.
Важно понимать, что каждая часть платформы несет историю, и спрашивать себя — какую историю несет этот кирпичик, может быть, его стоит выбросить и заменить сторонним сервисом. Например, можно ли вместо кирпичика поставить Okmeter? Возможно, парни уже прокачали эту экспертизу гораздо больше, чем мы. Но может и нет — возможно, у нас есть уникальная экспертиза, нам надо поставить Prometheus и развивать это дальше.
Создание платформы
Это сложный коммуникационный процесс. Когда у вас есть базовые практики, вы запускаете общение между разными инженерами и специалистами, которые вырабатывают требования и стандарты, и постоянно их изменяют к разным инструментам и подходам. Здесь важна культура, которая есть в DevOps.
С культурой все очень просто — это сотрудничество и коммуникация, то есть желание работать в общем поле друг с другом, желание владеть одним инструментом вместе. Тут нет никакого rocket science — все очень просто, банально. Например, мы все живем в подъезде и поддерживаем его чистоту — такой уровень культуры.
А что у вас?
Снова вопросы, которые вы можете себе задать.
Выделена ли инфраструктурная платформа? Кто отвечает за ее развитие? Понимаете ли вы конкурентные преимущества своей инфраструктурной платформы?
Эти вопросы надо постоянно себе задавать. Если что-то можно вынести на сторонние сервисы — нужно выносить, если сторонний сервис начинает блокировать ваше движение, то надо строить систему внутри себя.
Итак, DevOps.
… это сложная система, в нем должны быть:
Можно использовать эту схему, подкрасив в ней то, что уже у вас в компании есть в каком-то виде: это развилось или еще надо развить.
Уже через пару недель пройдет DevOpsConf 2019. в составе РИТ++. Приходите на конференцию, где вас ждет много крутых докладов про непрерывную поставку, инфраструктуру как код и DevOps-трансформацию. Бронируйте билеты, последний дедлайн цен 20 мая