Парсить что это значит
Парсить что это значит
Что такое парсер и как он работает

Чтобы поддерживать информацию на своем ресурсе в актуальном состоянии, наполнять каталог товарами и структурировать контент, необходимо тратить кучу времени и сил. Но есть утилиты, которые позволяют заметно сократить затраты и автоматизировать все процедуры, связанные с поиском материалов и экспортом их в нужном формате. Эта процедура называется парсингом.
Давайте разберемся, что такое парсер и как он работает.
Что такое парсинг?
Начнем с определения. Парсинг – это метод индексирования информации с последующей конвертацией ее в иной формат или даже иной тип данных.

Парсинг позволяет взять файл в одном формате и преобразовать его данные в более удобоваримую форму, которую можно использовать в своих целях. К примеру, у вас может оказаться под рукой HTML-файл. С помощью парсинга информацию в нем можно трансформировать в «голый» текст и сделать понятной для человека. Или конвертировать в JSON и сделать понятной для приложения или скрипта.
Но в нашем случае парсингу подойдет более узкое и точное определение. Назовем этот процесс методом обработки данных на веб-страницах. Он подразумевает анализ текста, вычленение оттуда необходимых материалов и их преобразование в подходящий вид (тот, что можно использовать в соответствии с поставленными целями). Благодаря парсингу можно находить на страницах небольшие клочки полезной информации и в автоматическом режиме их оттуда извлекать, чтобы потом переиспользовать.
Ну а что такое парсер? Из названия понятно, что речь идет об инструменте, выполняющем парсинг. Кажется, этого определения достаточно.
Какие задачи помогает решить парсер?
При желании парсер можно сподобить к поиску и извлечению любой информации с сайта, но есть ряд направлений, в которых такого рода инструменты используются чаще всего:

Серый парсинг
Такой метод сбора информации не всегда допустим. Нет, «черных» и полностью запрещенных техник не существует, но для некоторых целей использование парсеров считается нечестным и неэтичным. Это касается копирования целых страниц и даже сайтов (когда вы парсите данные конкурентов и извлекаете сразу всю информацию с ресурса), а также агрессивного сбора контактов с площадок для размещения отзывов и картографических сервисов.
Но дело не в парсинге как таковом, а в том, как вебмастера распоряжаются добытым контентом. Если вы буквально «украдете» чужой сайт и автоматически сделаете его копию, то у хозяев оригинального ресурса могут возникнуть вопросы, ведь авторское право никто не отменял. За это можно понести реальное наказание.
Добытые с помощью парсинга номера и адреса используют для спам-рассылок и звонков, что попадает под закон о персональных данных.
Где найти парсер?
Добыть утилиту для поиска и преобразования информации с сайтов можно четырьмя путями.
При отсутствии разработчиков в штате я бы советовал именно десктопную программу. Это идеальный баланс между эффективностью и затратами. Но если задачи стоят не слишком сложные, то может хватить и облачного сервиса.
Плюсы парсинга
У автоматического сбора информации куча преимуществ (по сравнению с ручным методом):
Так что нет никакого смысла «парсить» руками, когда можно доверить эту операцию подходящему ПО.
Минусы парсинга
Главный недостаток парсеров заключается в том, что ими не всегда удается воспользоваться. В частности, когда владельцы чужих сайтов запрещают автоматический сбор информации со страниц. Есть сразу несколько методов блокировки доступа со стороны парсеров: и по IP-адресам, и с помощью настроек для поисковых ботов. Все они достаточно эффективно защищают от парсинга.
В минусы метода можно отнести и то, что конкуренты тоже могут использовать его. Чтобы защитить сайт от парсинга, придется прибегнуть к одной из техник:
Но все методы защиты легко обходятся, поэтому, скорее всего, придется с этим явлением мириться.
Алгоритм работы парсера
Парсер работает следующим образом: он анализирует страницу на наличие контента, соответствующего заранее заданным параметрам, а потом извлекает его, превратив в систематизированные данные.
Процесс работы с утилитой для поиска и извлечения найденной информации выглядит так:
Естественно, процедура парсинга через специализированное ПО описана лишь в общих чертах. Для каждой утилиты она будет выглядеть по-разному. Также на процесс работы с парсером влияют цели, преследуемые пользователем.
Как пользоваться парсером?
На начальных этапах парсинг пригодится для анализа конкурентов и подбора информации, необходимой для собственного проекта. В дальнейшей перспективе парсеры используются для актуализации материалов и аудита страниц.
При работе с парсером весь процесс строится вокруг вводимых параметров для поиска и извлечения контента. В зависимости от того, с какой целью планируется парсинг, будут возникать тонкости в определении вводных. Придется подгонять настройки поиска под конкретную задачу.
Иногда я буду упоминать названия облачных или десктопных парсеров, но использовать именно их необязательно. Краткие инструкции в этом параграфе подойдут практически под любой программный парсер.
Парсинг интернет-магазина
Это наиболее частый сценарий использования утилит для автоматического сбора данных. В этом направлении обычно решаются сразу две задачи:
В первом случае стоит воспользоваться утилитой Marketparser. Указать в ней код продукта и позволить самой собрать необходимую информацию с предложенных сайтов. Большая часть процесса будет протекать на автомате без вмешательства пользователя. Чтобы увеличить эффективность анализа информации, лучше сократить область поиска цен только страницами товаров (можно сузить поиск до определенной группы товаров).
Во втором случае нужно разыскать код товара и указать его в программе-парсере. Упростить задачу помогают специальные приложения. Например, Catalogloader – парсер, специально созданный для автоматического сбора данных о товарах в интернет-магазинах.
Парсинг других частей сайта
Принцип поиска других данных практически не отличается от парсинга цен или адресов. Для начала нужно открыть утилиту для сбора информации, ввести туда код нужных элементов и запустить парсинг.
Разница заключается в первичной настройке. При вводе параметров для поиска надо указать программе, что рендеринг осуществляется с использованием JavaScript. Это необходимо, к примеру, для анализа статей или комментариев, которые появляются на экране только при прокрутке страницы. Парсер попытается сымитировать эту деятельность при включении настройки.
Также парсинг используют для сбора данных о структуре сайта. Благодаря элементам breadcrumbs, можно выяснить, как устроены ресурсы конкурентов. Это помогает новичкам при организации информации на собственном проекте.
Обзор лучших парсеров
Далее рассмотрим наиболее популярные и востребованные приложения для сканирования сайтов и извлечения из них необходимых данных.
В виде облачных сервисов
Под облачными парсерами подразумеваются веб-сайты и приложения, в которых пользователь вводит инструкции для поиска определенной информации. Оттуда эти инструкции попадают на сервер к компаниям, предлагающим услуги парсинга. Затем на том же ресурсе отображается найденная информация.
Преимущество этого облака заключается в отсутствии необходимости устанавливать дополнительное программное обеспечение на компьютер. А еще у них зачастую есть API, позволяющее настроить поведение парсера под свои нужды. Но настроек все равно заметно меньше, чем при работе с полноценным приложением-парсером для ПК.
Наиболее популярные облачные парсеры
Похожих сервисов в сети много. Причем как платных, так и бесплатных. Но вышеперечисленные используются чаще остальных.
В виде компьютерных приложений
Есть и десктопные версии. Большая их часть работает только на Windows. То есть для запуска на macOS или Linux придется воспользоваться средствами виртуализации. Либо загрузить виртуальную машину с Windows (актуально в случае с операционной системой Apple), либо установить утилиту в духе Wine (актуально в случае с любым дистрибутивом Linux). Правда, из-за этого для сбора данных потребуется более мощный компьютер.
Наиболее популярные десктопные парсеры
Это наиболее востребованные утилиты для парсинга. У каждого из них есть демо-версия для проверки возможностей до приобретения. Бесплатные решения заметно хуже по качеству и часто уступают даже облачным сервисам.
В виде браузерных расширений
Это самый удобный вариант, но при этом наименее функциональный. Расширения хороши тем, что позволяют начать парсинг прямо из браузера, находясь на странице, откуда надо вытащить данные. Не приходится вводить часть параметров вручную.
Но дополнения к браузерам не имеют таких возможностей, как десктопные приложения. Ввиду отсутствия тех же ресурсов, что могут использовать программы для ПК, расширения не могут собирать такие огромные объемы данных.
Но для быстрого анализа данных и экспорта небольшого количества информации в XML такие дополнения подойдут.
Наиболее популярные расширения-парсеры
Вместо заключения
На этом и закончим статью про парсинг и способы его реализации. Этого должно быть достаточно, чтобы начать работу с парсерами и собрать информацию, необходимую для развития вашего проекта.
Парсинг — что это такое простыми словами. Как работает парсинг и парсеры, и какие типы парсеров бывают (подробный обзор +видео)
Парсинг – что это такое простыми словами? Если коротко, то это сбор информации по разным критериям из интернета, в автоматическом режиме. В процессе работы парсера сравнивается заданный образец и найденная информация, которая в дальнейшем будет структурирована.
В качестве примера можно привести англо-русский словарь. У нас есть исходное слово «parsing». Мы открываем словарь, находим его. И в качестве результата получаем перевод слова «разбор» или «анализ». Ну, а теперь давайте разберем эту тему поподробнее
Содержание статьи:
Парсинг: что это такое простыми словами
Парсинг — это процесс автоматического сбора информации по заданным нами критериям. Для лучшего понимания давайте разберем пример:
Пример того, что такое парсинг:
Представьте, что у нас есть интернет-магазин поставщика, который позволяет работать по схеме дропшиппинга и мы хотим скопировать информацию о товарах из этого магазина, а потом разместить ее на нашем сайте/интернет магазине (под информацией я подразумеваю: название товара, ссылку на товар, цену товара, изображение товара). Как мы можем собрать эту информацию?
Первый вариант сбора — делать все вручную:
То есть, мы вручную проходим по всем страницам сайта с которого хотим собрать информацию и вручную копируем всю эту информацию в таблицу для дальнейшего размещения на нашем сайте. Думаю понятно, что этот способ сбора информации может быть удобен, когда нужно собрать 10-50 товаров. Ну, а что делать, когда информацию нужно собрать о 500-1000 товаров? В этом случае лучше подойдет второй вариант.
Второй вариант — спарсить всю информацию разом:
Мы используем специальную программу или сервис (о них я буду говорить ниже) и в автоматическом режиме скачиваем всю информацию в готовую Excel таблицу. Такой способ подразумевает огромную экономию времени и позволяет не заниматься рутинной работой.
Причем, сбор информации из интернет-магазина я взял лишь для примера. С помощью парсеров можно собирать любую информацию к которой у нас есть доступ.
Грубо говоря парсинг позволяет автоматизировать сбор любой информации по заданным нами критериям. Думаю понятно, что использовать ручной способ сбора информации малоэффективно (особенно в наше время, когда информации слишком много).
Для наглядности хочу сразу показать главные преимущества парсинга:
Если говорить о наличие минусов, то это, разумеется, отсутствие у полученных данных уникальности. Прежде всего, это относится к контенту, мы ведь собираем все из открытых источников и парсер не уникализирует собранную информацию.
Думаю, что с понятием парсинга мы разобрались, теперь давайте разберемся со специальными программами и сервисами для парсинга.
Что такое парсер и как он работает

Парсер – это некое программное обеспечение или алгоритм с определенной последовательностью действий, цель работы которого получить заданную информацию.
Сбор информации происходит в 3 этапа:
Чаще всего парсер — это платная или бесплатная программа или сервис, созданный под ваши требования или выбранный вами для определенных целей. Подобных программ и сервисов очень много. Чаще всего языком написания является Python или PHP.
Но также есть и отдельные программы, которые позволяют писать парсеры. Например я пользуюсь программой ZennoPoster и пишу парсеры в ней — она позволяет собирать парсер как конструктор, но работать он будет по тому же принципу, что и платные/бесплатные сервисы парсинга.
Для примера можете посмотреть это видео в котором я показываю, как я создавал парсер для сбора информации с сервиса spravker.ru.
Чтобы было понятнее, давайте разберем каких типов и видов бывают парсеры:
Не следует забывать о том, что парсинг имеет определенные минусы. Недостатком использования считаются технические сложности, которые парсер может создать. Так, подключения к сайту создают нагрузку на сервер. Каждое подключение программы фиксируется. Если подключаться часто, то сайт может вас заблокировать по IP (но это легко можно обойти с помощью прокси).
Что такое парсинг и как правильно парсить
Современный маркетинг – это работа с огромными массивами данных. Нужно анализировать работу сайта, конкурентов, свою аудиторию и еще массу всего. Но откуда брать эти данные? Можно собрать что-то вручную, пойти в метрику, wordstat или дугой аналитический сервис и что-то увидеть. Однако часто ручного сбора информации недостаточно, тогда на помощь приходят парсеры.
Что такое парсинг
Простыми словами парсинг – это автоматический сбор данных по конкретным параметрам или под какие-то задачи. Соответственно, парсеры – специальные сервисы для автоматического сбора данных. Собирать информацию можно практически из любых источников. Там где вы можете вычленить данные вручную, там можно использовать и парсинг, главное подобрать правильный инструмент для этого.
В этой статье мы разберем парсеры, которые позволяют собирать данные, полезные для развития сайта.
Законно ли использовать парсинг
Применение парсинга в целом не запрещено законом. В конституции РФ закреплено право свободно искать, получать и распространять информацию любым законным способом. Таким образом, если информация не защищена авторским правом, находится в свободном доступе для каждого человека и нет никаких других запретов с точки зрения закона, значит, ее можно копировать и распространять, а способ копирования и распространения большого значения не имеет.
Однако, помните о том, что есть некоторые виды информации, которые защищены законом. Пример таких данных – персональные данные пользователей. Эта информация защищена Законом «О персональных данных» и с их парсингом нужно сохранять некоторую осторожность. Если собираете личные данные, уведомляйте пользователя об этом:

Таким образом, парсинг разрешен, но не путайте его с другими понятиями:
Такие действия – недобросовестная конкуренция, они запрещены и за них можно получить наказание: санкции со стороны закона, поисковиков, от социальных сетей и так далее.
Парсинг – это законно, если вы собираете информацию находящуюся в открытом доступе и это не вредит другим лицам
Алгоритм работы парсера
Парсер – это робот. Он воспринимает информацию на сайте не так как мы. Ему не интересны визуальные эффекты, он видит только код и текстовое содержимое страницы. Программа находит информацию по заданным параметрам, сравнивает ее, анализирует и сохраняет в нужном вам формате.
В качестве объекта парсинга может выступать практически все что угодно: обычный сайт, интернет-магазин, социальная сеть, какой-то каталог.
Для чего нужен парсинг
Объемы данных в интернете настолько большие, что обработать их вручную бывает просто невозможно. Представьте сайт с каталогом товаров на 3000 позиций. Как анализировать такой массив данных вручную? Никак. Какую-то часть информации, скажем, процентов 15-20 удастся держать под контролем вручную, но остальная доля будет оставаться без внимания. Парсинг данных позволяет контролировать всё.
Вот некоторые способы использования парсеров на благо своего сайта:
Это всего четыреи метода парсинга, которые относятся только к сайту, но даже они способны сэкономить десятки и сотни часов вашего времени.
Достоинства парсинга
Ограничения при парсинге
Парсинг может быть ограничен внутренними ресурсами на сайте:
Парсеры сайтов по способу доступа к интерфейсу
Облачные парсеры
Преимущество таких программ – не требуют установки на компьютер. Их можно использовать онлайн и вся собираемая информация хранится на серверах разработчика. Работают через веб-интерфейсы или по API. Пара примеров облачных сервисов с русскоязычным интерфейсом:
Программы-парсеры
Это приложения для установки на компьютер. Как правило, хорошо совместимы с Windows, на линуксе и MacOS возникают проблемы, запускаются через виртуальные машины.
Парсеры сайтов в зависимости от используемой технологии
Парсеры на основе Python и PHP
Python – самый популярный язык для создания парсеров. По функциональности такие приложения превосходят все аналоги. Однако, если у вас нет навыков программирования, создать такой парсер не получится. Парсер на Python или PHP можно написать абсолютно под любые задачи. Но прежде, чем идти со своим заказом к разработчику, поищите готовое решение. Скорее всего оно уже есть, нужно просто подобрать. За разработкой актуально обращаться только для решения узких специфических задач.
Парсеры-расширения для браузеров
Парсеры в виде расширений – очень удобные решения с той точки зрения, что не нужны никакие дополнительные приложения, кроме постоянно используемого браузера. По функциональности это чаще всего простые приложения, способные вытащить со страницы или сайта простые данные: цены, новости, товары, отзывы. Они делают выгрузку данных и компанют их в удобный для восприятия вид, обычно в Excel или Google Таблицы.
Вот пара полезных расширений в Chrome для владельцев интернет-магазинов: Scraper, Parsers.
Парсеры сайтов на основе Excel
Excel – настолько многофункциональное приложение, что на его основе разрабатывается масса надстроек, упрощающих жизнь вебмастеров и владельцев бизнеса в интернете. Парсинг в таком случае реализуется через макросы: специальные команды для Excel. Пример такой надстройки – ParserOK.
Парсинг при помощи Google Таблиц
В Google Таблицах есть встроенный функционал для автоматического сбора информации. Это две функции:
Чтобы использовать эти функции не обязательно знать язык запросов Xpath.
Парсеры сайтов в зависимости от решаемых задач
Спектр задач, которые решаются с помощью парсера – основной параметр выбора. Вот основные разновидности парсеров по сферам применения:
Парсеры для организаторов совместных покупок (СП)
Предназначены для сбора данных о магазинах в социальных сетях, продающих свои товары мелким оптом по сниженной цене. Это парсеры с узким функционалом:
Отличаются понятным интерфейсом, могут быть реализованы разными способами: браузерная версия, приложение на компьютер и смартфон. Настройки простые: какие страницы парсить, расписание проверок, группы для выгрузки.
Примеры приложений такого типа:
Сервисы мониторинга конкурентов
Полезные сервисы для аналитики предложений ваших конкурентов. Они помогают поддерживать ваши предложения в соответствии с рынком. Например, если конкурент повысит или понизит цену, вы узнаете об этом первым и скорректируете свое поведение в соотвествии с рынком. Пример приложения для этих целей – Marketparser.
Сбор данных и автонаполнение контентом
Когда на сайте тысячи страниц, наполнение и обновление контента превращается в непосильную задачу. Чтобы не мониторить сайты конкурентов и поставщиков в ручную и не собирать с них информацию, можно использовать специальные сервисы. Парсер соберет информацию, выгрузит в таблицу или сразу на ваш сайт. В настройках таких приложений можно указать размер наценки, собирать данные сразу с нескольких сайтов и задать систематические проверки и анализ сайтов с автообновлением контента. Сервис для автонаполнения сайта – Диггернаут.
Многофункциональные парсеры
Это сервисы с широким функционалом, способны собирать данные для наполнения сайта, проверять разные SEO-параметры, мониторить цены конкурентов.
SEO-парсеры
Эти сервисы нужны, чтобы проверить техническое состояние сайта и качество оптимизации. Вот основные задачи, которые решаются с их помощью:
Выводы
Парсеры – сервисы, которые экономят ваше время и отдают максимально точную информацию за считанные минуты. Чтобы получать нужные данные, важно подобрать правильный парсер. Вот вопросы, на которые нужно ответить:
После ответов на эти вопросы возьмите несколько подходящих приложений и изучите отзывы. Опыт прошлого использования подскажет, какой парсер ваш.
Правда про парсинг сайтов, или «все интернет-магазины делают это»
1. Что такое парсинг?
Раскрою вам тайну: парсингом занимаются все… По крайней мере, все крупные игроки на рынке. Пару лет назад в одной из статей в Ведомостях представители “М-видео”, “Связного” и “Ситилинка” даже в открытую говорили об этом в ответ на интерес ФАС (см. тут).
2. Для чего парсинг нужен?
В первую очередь, целью парсинга является ценовая «разведка», ассортиментный анализ, отслеживание товарных акций. “Кто, что, за сколько и в каких количествах продаёт?” – основные вопросы, на которые парсинг должен ответить. Если говорить более подробно, то парсинг ассортимента конкурентов или того же Яндекс.Маркет отвечает на первые три вопроса.
С оборотом товара несколько сложней. Однако, такие компании как “Wildberries”, “Lamoda“ и Леруа Мерлен, открыто предоставляют информацию об ежедневных объемах продаж (заказах) или остатках товара, на основе которой не сложно составить общее представлении о продажах (часто слышу мнение, мол эти данные могут искажаться намеренно — возможно, а возможно и нет). Смотрим, сколько было товара на складе сегодня, завтра, послезавтра и так в течении месяца и вот уже готов график и динамика изменения количества по позиции составлена (оборачиваемость товара фактически). Чем выше динамика, тем больше оборот.

Потенциально возможный способ узнать оборачиваемость товаров с помощью ежедневного анализа остатков сайта Леруа Мерлен.
Можно, конечно, сослаться на перемещение товаров между точками. Но суммарно, если брать, например, Москву — то число не сильно изменится, а в существенные передвижения товара по регионам верится с трудом.
С объемами продаж ситуация аналогична. Есть, конечно, компании, которые публикуют информацию в виде много/мало, но даже с этим можно работать, и самые продаваемые позиции легко отслеживаются. Особенно, если отсечь дешёвые позиции и сфокусироваться исключительно на тех, что представляют наибольшую ценность. По крайней мере, мы такой анализ делали – интересно получалось.
Во-вторых, парсинг используется для получения контента. Здесь уже могут иметь место истории в стиле “правовых оттенков серого”. Многие зацикливаются на том, что парсинг – это именно воровство контента, хотя это совершенно не так. Парсинг – это всего лишь автоматизированный сбор информации, не более того. Например, парсинг фотографий, особенно с “водяными знаками” – это чистой воды воровство контента и нарушение авторских прав. Потому таким обычно не занимаются (мы в своей работе ограничиваемся сбором ссылок на изображения, не более того… ну иногда просят посчитать количество фотографий, отследить наличие видео на товар и дать ссылку и т.п.).
Касательно сбора контента, интересней ситуация с описаниями товаров. Недавно нам поступил заказ на сбор данных по 50 сайтам крупных онлайн-аптек. Помимо информации об ассортименте и цене, нас попросили “спарсить” описание лекарственных аппаратов – то самое, что вложено в каждую пачку и является т.н. фактической информацией, т.е. маловероятно попадает под закон о защите авторских прав. В результате вместо набора инструкций вручную, заказчикам останется лишь внести небольшие корректировки в шаблоны инструкций, и всё – контент для сайта готов. Но да, могут быть и авторские описания лекарств, которые заверены у нотариуса и сделаны специально как своего рода ловушки для воришек контента :).
Рассмотрим также сбор описания книг, например, с ОЗОН.РУ или Лабиринт.ру. Здесь уже ситуация не так однозначна с правовой точки зрения. С одной стороны, использование такого описания может нарушать авторское право, особенно если описание каждой карточки с товаром было нотариально заверено (в чём я сильно сомневаюсь — ведь может и не быть заверено, исключение — небольшие ресурсы, которые хотят затаскать по судам воров контента). В любом случае, в данной ситуации придётся сильно «попотеть», чтобы доказать уникальность этого описания. Некоторые клиенты идут еще дальше — подключают синонимайзеры, которые «на лету» меняют (хорошо или плохо) слова в описании, сохраняя общий смысл.
Ещё одно из применений парсинга довольно оригинально – “самопарсинг”. Здесь преследуется несколько целей. Для начала – это отслеживание того, что происходит с наполнением сайта: где битые ссылки, где описания не хватает, дублирование товаров, отсутствие иллюстраций и т.д. Полчаса работы парсера — и вот у тебя готовая таблица со всеми категориями и данными. Удобно! “Самопарсинг” можно использовать и для того, чтобы сравнить остатки на сайте со своими складскими остатками (есть и такие заказчики, отслеживают сбои выгрузок на сайт). Ещё одно применение “самопарсинга”, с которым мы столкнулись в работе — это структурирование данных с сайта для выгрузки их на Яндекс Маркет. Ребятам так проще было сделать, чем вручную этим заниматься.
Также парсятся объявления, например, на ЦИАН-е, Авито и т.д. Цели тут могут быть как перепродажи баз риелторам или туроператорам, так и откровенный телефонный спам, ретаргетинг и т.п. В случае с Авито это особенно явно, т.к. сразу составляется таблица с телефонами пользователей (несмотря на то, что Авито подменяет телефоны пользователей для защиты и публикует их в виде изображения, от поступающих звонков все равно никуда не уйти).
3. “Что в резюме тебе моем?” или парсинг HH.RU
В последнее время стали актуальны запросы на парсинг Headhunter-а. Правда сначала люди просят продать им “базу Хедхантера”. Но, когда уже понимают, что никакой базы у нас нет и быть не может, мы переходим к разговору о парсинге в их профиле (“под паролем”). Это своеобразное направление парсинга и, честно говоря, нам оно не особо интересно, однако рассказать о нём стоит.
В чём тонкость? Клиент предоставляет доступ к своему аккаунту и ставит задачу по сбору данных под свои нужды. Т.е. он уже оплатил доступ к базе HH и, подписывая с нами договор, ставит нам задачу на автоматический сбор информации в его интересах и под его аккаунтом, что находится полностью под его ответственностью. В случае, если HH зафиксирует ненормальную активность, аккаунт будет заблокирован. Потому мы стараемся как можно лучше сымитировать человеческую деятельность при сборе данных.
Если бы HH (насколько знаю “успешно” проваливший свои эксперименты с API) сам предоставлял (продавал) данные в табличке по регионам, скажем, контакты всех работающих в данный момент директоров по маркетингу в Москве, к нам бы никто и не приходил. А пока это приходится делать человеку “ручками”, к нам идут. Ведь, когда у тебя есть такая таблица, заниматься рекламным спамом – холодными звонками намного удобнее.
Подчеркну ещё раз, у нас нет базы HH, мы просто собираем данные для каждого клиента под его нужды, его аккаунтом и его ответственностью. И нарушение договора оферты не связано с использованием сайта парсящей стороной. Подписывая с нами договор, клиент получает за прогон контакты порядка 450-ти ЛПР-ов, которые мы положим к нему на сервер, и дальше уже его отдел продаж сам решит, что с этим делать. Эх, мы бы тоже “спамили”, если б у нас была такая база. Шучу 🙂
Хотя, лично я считаю, что нет перспектив в парсинге под паролем. А вот парсинг открытых ресурсов – это другое дело. Ты один раз настроил всё и парсишь постоянно, потом перепродаешь доступ ко всем собранным данным. Это более перспективно.
4. Парсинг вообще законен?
В российском законодательстве нет статьи, запрещающей парсинг. Запрещен взлом, DDOS, воровство авторского контента, а парсинг – это ни то, ни другое, не третье и, соответственно, он не запрещен.
Некоторые люди воспринимают парсинг как DDOS-атаку и относятся к нему с сомнением. Однако, это совершенно разные вещи, и при парсинге мы, напротив, стараемся как можно меньше нагружать целевой сайт и не навредить бизнесу. Как в случае со здоровым паразитизмом – мы не хотим, чтобы бизнес «отбросил копыта», иначе нам не на чем будет “паразитировать”.
Обычно просят парсить крупные сайты, из топа 300-500 сайтов России. На таких сайтах посещаемость, как правило, несколько миллионов в месяц, может даже и больше. И на таком фоне парсинг одного товара в секунду или в две практически незаметен (нет смысла чаще парсить, 1-2 секунды на товар — это оптимальная скорость для крупных сайтов). Соответственно, и намека на DDOS-атаку в наших действиях нет. Очень редко люди просят чтобы мы обновляли, например, весь сайт БЕРУ.РУ за сутки — это, скажем прямо, перебор и слишком высокая нагрузка на сайт… обычно занимает 3-4 дня.
Напомню, что парсинг – это лишь сбор того, что мы можем своими глазами увидеть на сайте и скопировать к себе руками. Таким образом, под статью об авторском праве могут попасть лишь действия с уже собранной информацией, т.е. действия самого заказчика. Просто человек это делает долго медленно и с ошибками, а парсер – быстро и не ошибается. Что же делать, когда речь касается сбора данных с AliExpress или Wildberies? Человеку просто не под силу такая задача, и парсинг – единственный выход.
Правда, недавно попросили парсить сайт государственной организации – суда, если не ошибаюсь. Там в открытом доступе вся информация, но мы (на всякий случай) отказались. 🙂
5. “Вы чего нас парсите, мы же заказчик” или в чем разница между парсингом и мониторингом цен?
Мониторинг цен – одно из наиболее востребованных направлений применения парсинга. Но с ним не всё так просто – поработать в данном случае придётся не только нам, но и самому клиенту.
При заказе на мониторинг цен мы сразу предупреждаем, что будем парсить не только конкурентов, но и заказчика. Это необходимо для получения схожих таблиц с товарами и ценами, которые мы сможем обновлять автоматически. Однако, сами по себе такие данные не несут ценность, пока они не связаны между собой (так называемый матчинг товаров). Некоторые позиции с разных сайтов мы можем сопоставить автоматически, но, к сожалению, на данный момент “машины” еще не так хороши, чтобы сделать это гарантированно без ошибок, и лучше человека (например, работающего удаленно на полставки сотрудника из регионов) это никто не сделает.
Если бы все выводили штрих-код на сайте, то вообще было бы замечательно, и мы могли бы делать все “связки” автоматически. Но, к сожалению, так это не так, и даже названия продуктов разные компании пишут по-разному.
Хорошо, что такую работу необходимо провести единожды, а потом периодически перепроверять и вносить небольшие корректировки, если требуется. При наличии связок мы уже можем обновлять такие таблицы автоматически. К тому же, обычно людям не требуется мониторить цены на всё: есть условно 3-5 тысяч позиций, которые в топе, а мелочь не представляет интерес. И оператор из региона легко сможет выполнять такую работу за деньги порядка 10 000 рублей в месяц.
Самый удачный и правильный кейс в данном случае, на мой взгляд, загружать полученный прайс лист конкурентов сразу к себе в 1С-ку (или другую ERP систему) и там уже выполнять сопоставление. Так мониторинг цен легче всего внедрить в ежедневную деятельность своих аналитиков. А без анализа такой парсинг никому и не нужен.
6. Как защититься от парсинга?
Да никак. И стоит ли вообще защищаться от парсинга? Я бы не стал. Работающей 100% защиты всё равно нет (точнее, мы еще не встречали), так что особого смысла пытаться защититься я не вижу. Лучшая защита от парсинга – это просто выложить готовую таблицу на сайте и написать – берите отсюда, обновляем раз в пару дней. Если люди так будут делать, то у нас хлеба не будет.
К слову говоря, недавно созванивались с IT директором крупной сети – они хотели протестировать свою защиту от парсинга. Я его напрямую спросил, почему они так не делают. Как технический специалист он прекрасно понимает, что никакая защита от парсинга не спасёт, лишь отпугнет дилетантов; а вот компании, которые зарабатывают на парсинге, вполне могут позволить себе исследовательскую деятельность в этом направлении – долго и мучительно разбираться в новой защите, и в итоге ее обойти…
Как правило, все используют однотипные защиты, и такое исследование пригодится еще не раз. Так вот, оказалось, что отдел маркетинга не готов к такому: “Зачем нам упрощать жизнь конкурентам?” Казалось бы, логично, но… В результате компания будет тратить деньги на защиту, которая не поможет, а паразитная нагрузка на сайт – останется. Хотя, справедливости ради, стоит отметить, что от «студентов» изучающих python и парсящих все что «шевелится» вполне может помочь.
Кстати, и “Яндекс”, и “Google” занимаются парсингом: они заходят на сайт и индексируют его – собирают информацию. Только все хотят, чтобы “Яндекс” и “Google” индексировали их сайты по понятным причинам, и никто не хочет, чтобы их парсили 🙂
7. “Я тут бесплатно поискал. ” или история про авиабилеты
Однажды к нам обратились с интересным заказом на тестовый парсинг. Компания занимается авиабилетами и им были интересны цены конкурентов на пару самых популярных направлений. Задача оказалась нетривиальной, т.к. пришлось повозиться с подстановкой и сопоставлением рейсов. Занимательным оказалось то, что цены у “Onetwotrip”, “Aviasales” и “Skyscanner” на одни и те же рейсы немного отличаются (разброс около 5-7%).
Проект показался мне очень интересным, и я выложил пост об этом в соц.сетях. К моему удивлению дискуссия под постом оказалась довольно агрессивной, и я не сразу понял почему. Затем мне написал гендиректор одной из компаний лидера рынка продажи билетов в России, и ситуация прояснилась. Выяснилось, что запросы о ценах на билеты для таких компаний платные, т.к. они берут информацию с международных платных сервисов. И, помимо паразитной нагрузки, парсинг представляет для них еще и финансовую.
В любом случае, никто же с вас не требует оплаты, если вы подыскиваете себе лично билеты на этих сервисах, а запросов обычные люди тоже делают немало пока перебирают разные варианты… В общем тут такая бизнес-дилемма 🙂
8. “Рецепты шеф-парсера”. или как мы работаем?
Думаю, для большего понимания всех аспектов парсинга стоит приоткрыть завесу нашей “внутренней кухни”.
Всё начинается с заказа. Иногда клиенты связываются с нами сами, а иногда звоним мы. Особенно удачно получается с заказами на мониторинг цен. В этом случае нам приходится парсить не только конкурентов, но и самого заказчика. Поэтому мы порой звоним тем, кого так или иначе парсим, и в открытую об этом говорим, предлагая свои услуги – работа ведь нами уже и так выполняется. Сначала реакция очень негативная, но проходит пара дней, эмоции спадают, и заказчики сами перезванивают, говоря: “Чёрт с ним! Кого вы ещё парсите?”
Парсинг у ОЧЕНЬ многих владельцев посещаемых ресурсов вызывает эмоции. Сначала негативные, ведь он схож с подглядыванием в замочную скважину. Затем перерастает в интерес, а потом и в осознание необходимости. Бизнесмены – умные люди. Когда эмоции сходят на нет и остаётся холодный расчёт, всегда возникает вопрос: “А, может, мы где-то недоработали, и нам тоже это нужно?”
Благодаря этим эмоциям мы довольно активно растём и развиваемся. На данный момент мы парсим порядка 300 сайтов в день. Обычно у нас заказывают по 8-15 сайтов, а парсинг одного стоит от 5 до 9 тысяч рублей в месяц, в зависимости от сложности подключения, ведь каждый сайт приходится подключать индивидуально (уходит где-то 4-5 часов на ресурс). Сложность заключается в том, что некоторые защищаются. Борьба идёт не столько с парсингом, сколько с некой паразитной нагрузкой, которая не приносит им прибыль, но иногда приходится повозиться.
В любом случае ВСЁ ПАРСИТСЯ, даже если цена на товар публикуется на сайте как картинка 🙂 Желающим попробовать свои силы в парсинге, рекомендую потренироваться на сайте «Аптеки Столички» и спарсить цены.
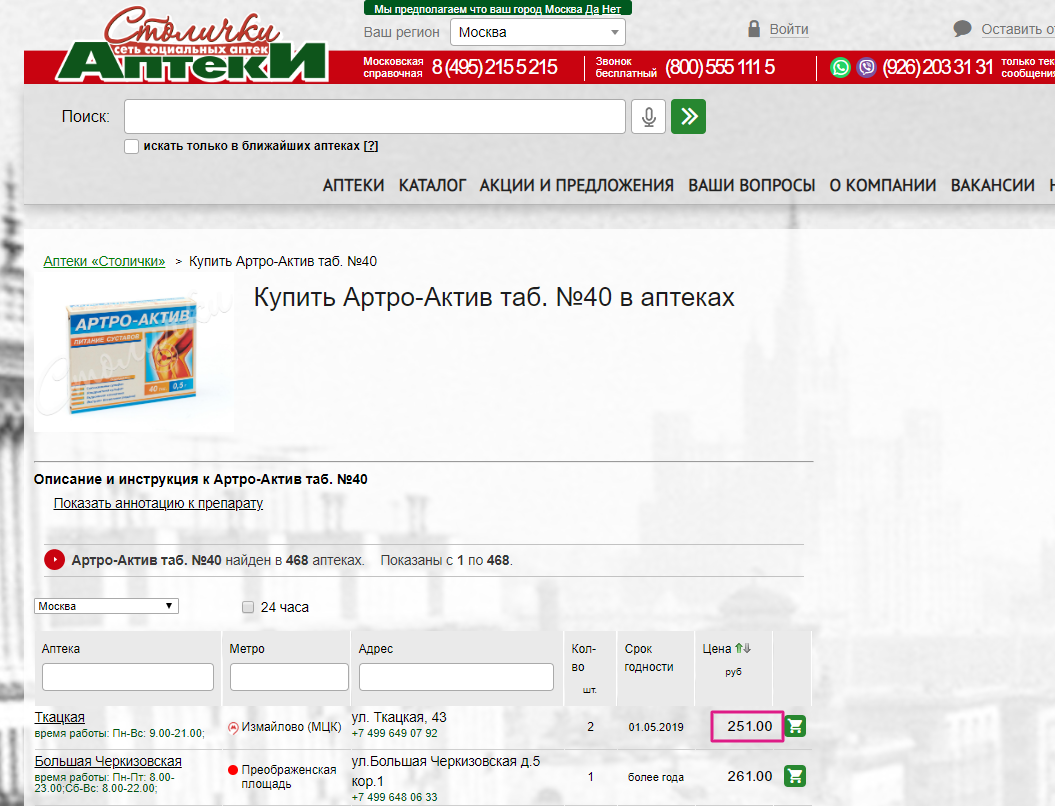
Интернет- магазин сети аптек «Столички» — цены пишутся внутренним шрифтом и чтобы их спарсить одним из решений будет формирование картинки и ее распознавание. Мы так делаем по крайне мере.
Собранные данные передаются клиенту. Обычно мы размещаем их на собственном облаке, постоянно обновляя, и предоставляем клиенту доступ к ним по API. Если с данными вдруг становится что-то не так (а это бывает редко – раз в 3-4 месяца), нам сразу звонят-пишут, и мы стараемся устранить проблему как можно быстрее. Такие сбои возникают при установки новой защиты или блокировки, а решаются с помощью исследований и прокси соответственно. В другом случае, когда на сайте что-то меняется, бот просто перестает понимать, где что находится, и нашему программисту приходится заново его настраивать. Но всё решаемо, и заказчики обычно относятся к таким проблемам с пониманием.
Отмечу, что в нашем деле личность заказчика никогда не разглашается – мы относимся к этому достаточно трепетно, да и пункты в договоре о неразглашении никто не отменял. Хоть в парсинге и нет ничего предосудительного, но многие стесняются.
Собственно, подводя итог- если вы растущий бизнес, торгуете широко распространенными товарами или работаете в быстро меняющейся среде (такой, как найм персонала или предложение специфических услуг для определенной категории авторов объявлений, резюме и содержимого других“досок объявлений” в Интернете), то рано или поздно столкнетесь с парсингом (как заказчик или как мишень).
Что такое парсинг и как правильно парсить


Что такое парсинг данных должен знать каждый владелец сайта, планирующий серьёзно развиваться в бизнесе. Это явление настолько распространено, что рано или поздно с парсингом может столкнуться любой. Либо как заказчик данной операции, либо как лицо, владеющее объектом для сбора информации, то есть ресурсом в Интернете.
К парсингу в российской бизнес-среде часто наблюдается негативное отношение. По принципу: если это не незаконно, то уж точно аморально. На самом деле из его грамотного и тактичного использования каждая компания может извлечь немало преимуществ.

Digital шагает семимильными шагами. Еще недавно компании и клиенты радовались первым сайтам, а сегодня загрузка страницы за 10 секунд вызывает дикое раздражение.
Пройдите тест и узнайте, какие невероятные технологии уже стали реальностью, а какие пока остаются мечтой.
Что такое парсинг
Глагол “to parse” в дословном переводе не означает ничего плохого. Делать грамматический разбор или структурировать — действия полезные и нужные. На языке всех, кто работает с данными на сайтах это слово имеет свой оттенок.
Парсить — собирать и систематизировать информацию, размещенную на определенных сайтах, с помощью специальных программ, автоматизирующих процесс.
Если вы когда-либо задавались вопросом, что такое парсер сайта, то вот он ответ. Это программные продукты, основной функцией которых является получение необходимых данных, соответствующих заданным параметрам.
Законно ли использовать парсинг
После выяснения что такое парсинг, может показаться, что это нечто, не соответствующее нормам действующего законодательства. На самом деле это не так. Законом не преследуется парсинг. Зато запрещены:
Парсинг законен, если он касается сбора информации, находящейся в открытом доступе. То есть всего, что можно и так собрать вручную.
Парсеры просто позволяют ускорить процесс и избежать ошибок из-за человеческого фактора. Поэтому «незаконности» в процесс они не добавляют.
Другое дело, как владелец свежесобранной базы распорядится подобной информацией. Ответственность может наступить именно за последующие действия.
Как запустить и настроить таргетированную рекламу ВКонтакте: пошаговая инструкция
Как запустить и настроить таргетированную рекламу ВКонтакте: пошаговая инструкция
Для чего нужен парсинг
Что такое парсить сайт разобрались. Переходим к тому, зачем же это может понадобиться. Здесь открывается широкий простор для действий.
Основная проблема современного Интернета — избыток информации, которую человек не в состоянии систематизировать вручную.
Парсинг используется для:
Сквозная аналитика — это тоже своеобразный парсинг, только рекламы и продаж. Система интегрируется с площадками и CRM, а потом автоматически соединяет данные о бюджетах, кликах, сделках и подсчитывает окупаемость каждой кампании. Используйте ее, чтобы не потеряться в большом количестве информации и видеть в отчетах то, что вам действительно нужно. Отчеты Calltouch легко кастомизировать под себя и задачи команды маркетологов.

Достоинства парсинга
Они многочисленны. По сравнению с человеком парсеры могут:
Ограничения при парсинге
Есть несколько вариантов ограничений, которые могут затруднить работу парсера:
Какую информацию можно парсить
Спарсить можно всё, что есть на сайте в открытом доступе. Чаще всего требуются:
Изображения с сайтов технически спарсить тоже можно, но, как уже упоминалось выше, если они защищены авторским правом, лучше не нужно. Нельзя собирать с чужих сайтов личные данные их пользователей, которые те вводили в личных кабинетах.
Парсинг часто используется в индустрии e-commerce. Оценить влияние парсинга и его результатов можно в сквозной аналитике для интернет-магазинов. Вам доступны отчеты по любым временным срезам, метрикам и товарам. С помощью этих данных вы узнаете, из каких источников вы получаете добавления в корзины и продажи, и сможете оптимизировать рекламу с опорой на эти данные.

Алгоритм работы парсинга
Принцип действия программы зависит от целей. Но схематично он выглядит так:
Способы применения
Основных способов применения парсинга существует два:
Обычно оба варианта работают в тесной связке друг с другом. Например, анализ ценовых позиций у конкурентов отталкивается от имеющегося диапазона на собственном сайте, а обнаруженные новинки сопоставляются с собственной товарной базой и т. п.
Парсить — что это значит, парсинг и парсер — что это такое простыми словами

Говоря о сборе семантического ядра для сайта, мы используем термины «парсинг», «парсить». Что это значит? Попробую объяснить простыми словами, что это такое.
Что такое парсинг (не путать с пирсингом)
Сначала небольшое отступление. Вспомнился интересный случай. Однажды, на уроке химии, я рассказывал про гомологический ряд метана (метан, этан, пропан, бутан, пентан, гексан и т. д.). Для лучшего понимания и запоминания предложил вспомнить слова с аналогичным корнем. Спросил, что такое пентагон. Один из ответов был – Это такое лекарство.
Парсинг – это один из способов автоматического сбора и обработки информации из Всемирной сети.
При парсинге проводится лексический анализ собранной информации путем сравнения найденных текстов с определенными образцами, то есть по некоторому шаблону или, как еще говорят, по маске.
Обработанная таким образом информация структурируется по заданным правилам. Аналогией парсинга можно считать работу со словарем. Мы парсим словарь, сравнивая его текст с нужным нам словом, а найдя его, узнаем перевод.
Для чего нужен парсинг
Использование этого процесса в информатике очень разнообразно. Перечислить все варианты его применения практически невозможно.
Рассмотрим наиболее важные примеры.
Активнее всего «парсят» всемирную паутину поисковые сервисы. Их программы парсеры, которые называют поисковыми роботами или пауками, непрерывно просматривают и анализируют сайты, пополняя и обновляя свои базы данных. Эта незаметная, но очень важная для нас работа позволяет практически мгновенно находить нужную нам информацию.
Парсинг используется для наполнения сайтов контентом. В некоторых случаях это оправданно, а в некоторых такое действие можно считать воровством интеллектуальной собственности.
Активно парсингом занимаются владельцы интернет-магазинов для заполнения описаний товаров, их характеристик, цен. Сделать все это вручную очень трудно.
Парсинг необходим для быстрого обновления новостных сайтов и других сайтов, содержащих информацию, которая быстро и постоянно изменяется, например, сводки погоды, курсы валюты, изменения на биржах и т. д.
Парсеры мгновенно отслеживают все изменения и отправляют их на сайты заказчиков. Все происходит без вмешательства человека. Мы открываем сайт и смотрим, какая сейчас погода, каков курс доллара на данный момент в разных банках, на каком участке дороги есть пробки и многое другое.
Как я уже упоминал, парсинг необходим для поиска ключевых слов при составлении семантического ядра.
Как работает парсер
Парсер – это программа, написанная на одном из языков программирования.
Принцип работы парсера довольно прост:
Достоинства парсинга
Парсинг, как и любая компьютерная технология, имеет определенные преимущества перед ручной обработкой информации.
На первое место я бы поставил скорость. Парсер быстро обрабатывает огромные массивы данных.
Как и любая, правильно настроенная программа, парсер точно выделяет и структурирует нужную информацию.
Результаты парсинга можно выгрузить в удобном для заказчика виде или сразу же автоматически встроить в нужное место сайта.
Виды парсинга
Парсить можно самые разные данные, и поэтому этот процесс можно разделить на несколько видов.
Анализ аудитории
Парсинг аудитории – это сбор различных сведений о посетителях сайтов, интернет-магазинов, соцсетей.
Собираются при этом самые разнообразные данные, начиная с простых, как ФИО, пол, возраст, образование, местоположение, и заканчивая такими, кажется, неочевидными, как интересы, наклонности в какой-то области и многое другое.
Это необходимо для формирования модели потенциального клиента и разработки более точной и целенаправленной рекламы, что экономит бюджет рекламной кампании.
Парсинг товаров
Этот вид парсинга наиболее важен для владельцев интернет-магазинов. С его помощью собирается информация о товарах, их характеристиках, ценах.
Парсинг сайтов
Парсить сайты можно для разных целей.
Чуть подробнее о сборе ключевых запросов для создания семантического ядра. Количество таких запросов исчисляется миллиардами и, конечно, без программной обработки здесь не обойтись. Для этих целей созданы как специальные программы, так и онлайн-сервисы.
К первым относится самая популярная среди сеошников программа Key Collector, с помощью которой можно парсить ключевые запросы, определять частотность, конкурентность, проводить кластеризацию запросов и т. д.
Среди онлайн-сервисов, которые используются для работы с ключевыми словами, я бы выделил Букварикс, о котором у меня уже есть статья, и сервис Мутаген, считающийся лучшим для определения конкурентности поисковых запросов.
Другое направление, где необходим парсинг сайтов – это их аудит. Например, я также писал о программе Smart Seo Auditor, с помощью которой можно выполнить SEO-аудит как своего, так и чужого сайта.
Утилита парсит сайт, находит заголовки страниц (title, h1-h6), описания (description), изображения с их характеристиками и многое другое, и результаты выдает в виде удобной таблицы.
С помощью парсинга наполняют контентом так называемые, автонаполняемые сайты. Например, для сайтов на WordPress разработаны специальные плагины-парсеры, которые регулярно обходят ресурсы из заданного списка и, в случае появления на них новых статей, сразу же копируют их к себе.
Технические и этические проблемы
Парсеры могут создавать определенные технические сложности. В первую очередь, это связано с трафиком. Хотя парсер – это программа, каждое его подключение фиксируется и представляет некоторую нагрузку на сервер. При слишком частых подключениях эта нагрузка может оказаться чрезмерной, и сайт будет заблокирован.
Другая проблема парсинга носит этический характер. Это связано с тем, что данный процесс во многих случаях можно считать воровством контента. Границы между допустимым и недопустимым довольно расплывчаты.
Я не раз встречал в Интернете сайты, на которых опубликованы статьи, полностью скопированные с моих веб-ресурсов. И хотя там присутствует ссылка на первоисточник, это не очень приятно.
Итак, парсинг – это важный и необходимый процесс, применяющийся для разных целей, который облегчает жизнь многим пользователям Интернета по поиску и обработке огромных массивов информации.
Надеюсь, теперь вам понятны термины «парсинг», «парсить», что это значит, и для чего делается.
Что такое парсинг сайта, программы и примеры их использования

В интернет маркетинге часто необходимо собрать большой объем информации с сайта, не только со своего, но и с сайтов конкурентов, после её проанализировать и применить для каких-либо целей.
В статье постараемся достаточно просто рассказать о термине «парсинг”, его основных нюансах и рассмотрим несколько примеров его полезного применения, как для маркетологов и владельцев бизнеса, так и для SEO специалистов.

Что такое парсинг сайта?
Простыми словами парсинг – это автоматизированный сбор информации с любого сайта, ее анализ, преобразование и выдача в структурированном виде, чаще всего в виде таблицы с набором данных.
Парсер сайта — это любая программа или сервис, которая осуществляет автоматический сбор информации с заданного ресурса.
В статье мы разберем самые популярные программы и сервисы для парсинга сайта.
Зачем парсинг нужен и когда его используют?
Вообще парсинг можно разделить на 2 типа:
На основе полученных данных специалист составляет технические задания для устранения выявленных проблем.
Выше перечислены основные примеры использования парсинга. На самом деле их куда больше и ограничивается только вашей фантазией и некоторыми техническими особенностями.
Как работает парсинг? Алгоритм работы парсера.
Процесс парсинга — это автоматическое извлечение большого массива данных с веб-ресурсов, которое выполняется с помощью специальных скриптов.
Если кратко, то парсер ходит по ссылкам указанного сайта и сканирует код каждой страницы, собирая информацию о ней в Excel-файл либо куда-то еще. Совокупность информации со всех страниц сайта и будет итогом парсинга сайта.
Парсинг работает на основе XPath-запросов, это язык, который обращается к определенному участку кода страницы и извлекает из него заданную критерием информацию.
Алгоритм стандартного парсинга сайта.
Чем парсинг лучше работы человека?
Парсинг сайта – это рутинная и трудоемкая работа. Если вручную извлекать информацию из сайта, в котором всего 10 страниц, не такая сложная задача, то анализ сайта, у которого 50 страниц и больше, уже не покажется такой легкой.
Кроме того нельзя исключать человеческий фактор. Человек может что-то не заметить или не придать значения. В случае с парсером это исключено, главное его правильно настроить.
Если кратко, то парсер позволяет быстро, качественно и структурировано получить необходимую информацию.
Какую информацию можно получить, используя парсер?
У разных парсеров могут быть свои ограничения на парсинг, но по своей сути вы можете спарсить и получить абсолютно любую информацию, которая есть в коде страниц сайта.
Законно ли парсить чужие сайты?
Парсинг данных с сайтов-конкурентов или с агрегаторов не противоречат закону, если:
Если вы сомневаетесь по одному из перечисленных пунктов, перед проведением анализа сайта лучше проконсультироваться с юристом.
Популярные программы для парсинга сайта
Мы выделяем 4 основных инструменты для парсинга сайтов:
Google таблицы (Google Spreadsheet)
Удобный способ для парсинга, если нет необходимости парсить большое количество данных, так как есть лимиты на количество xml запросов в день.
С помощью таблиц Google Spreadsheet можно парсить метаданные, заголовки, наименования товаров, цены, почту и многое другое.
Рассмотрим основные функции
Функция importHTML
Настраивает импорт таблиц и списков на страницах сайта. Прописывается следующим образом:
=IMPORTHTML(“ссылка на страницу”; запрос “table” или “list”; порядковый номер таблицы/списка)
Пример использования
Необходимо выгрузить данные из таблицы со страницы сайта.


Для этого в формулу помещаем URL страницы, добавляем тег «table» и порядковый номер — 1.
Вот что получается:
Вставляем формулу в таблицу и смотрим результат:

Для выгрузки второй таблицы в формуле заменяем 1 на 2.
Вставляем формулу в таблицу и смотрим результат:

Функция importXML
Импортирует данные из документов в форматах HTML, XML, CSV, CSV, TSV, RSS, ATOM XML.
Функция имеет более широкий спектр опций, чем предыдущая. С её помощью со страниц и документов можно собирать информацию практически любого вида.
Работа с этой функцией предусматривает использование языка запросов XPath.
Формула:
=IMPORTXML(“ссылка”; “//XPath запрос”)
Пример использования
Вытягиваем title, description и заголовок h1.
В первом случае в формуле просто прописываем //title:

В формулу можно также добавлять названия ячеек, в которых содержатся нужные данные.
Для заголовка h1 похожая формула

С парсингом description немного другая история, а именно прописать его XPath запросом. Он будет выглядеть так:

В случае с другими любыми данными XPath можно скопировать прямо из кода страницы. Делается это просто:

Вот как это будет выглядеть после всех манипуляций

Функция REGEXEXTRACT
С её помощью можно извлекать любую часть текста, которая соответствует регулярному выражению.
Конечно для использования данной функции необходимы знания построения регулярных выражений,
Пример использования
Нужно отделить домены от страниц. Это можно сделать с помощью выражения:

Подробнее о функциях таблиц можно почитать в справке Google.
NetPeak Spider

Десктопный инструмент для регулярного SEO-аудита, быстрого поиска ошибок, системного анализа и парсинга сайтов.
Бесплатный период 14 дней, есть варианты платных лицензий на месяц и более.
Данная программа подойдет как новичкам, так и опытным SEO-специалистам. У неё интуитивно понятный интерфейс, она самостоятельно находит и кластеризует ошибки, найденные на сайте, помечает их разными цветами в зависимости от степени критичности.
Возможности Netpeak Spider:

ComparseR

ComparseR – специализированная программа, предназначенная для глубокого изучения индексации сайта.
У демо-версии ComparseR есть 2 ограничения:
Данный парсер примечателен тем, что он заточен на сравнение того, что есть на вашем сайте и тем, что индексируется в поисковых системах.
То есть вы легко найдете страницы, которые не индексируются поисковыми системами, или наоборот, страницы-сироты (страницы, на которые нет ссылок на сайте), о которых вы даже не подозревали.
Стоит отметить, что данный парсер полностью на русском и не так требователен к мощностям компьютера, как другие аналоги.

Screaming Frog SEO Spider

Особенности программы:
В бесплатной версии доступна обработка до 500 запросов.
На первый взгляд интерфейс данной программы для парсинга сайтов может показаться сложным и непонятным, особенно из-за отсутствия русского языка.
Не смотря на это, сама программа является великолепным инструментом с множеством возможностей.
Всю необходимую информацию можно узнать из подробного мануала по адресу https://www.screamingfrog.co.uk/seo-spider/user-guide/.

Примеры глубокого парсинга сайта — парсинг с конкретной целью
Пример 1 — Поиск страниц по наличию/отсутствию определенного элемента в коде страниц
Задача: — Спарсить страницы, где не выводится столбец с ценой квартиры.
Как быстро найти такие страницы на сайте с помощью Screaming Frog SEO Spider?
Открываете страницу где есть блок, который вам нужен и с помощью просмотра кода ищите класс блока, который есть на всех искомых страницах.

Чтобы было более понятна задача из примера, мы ищем страницы, блок которых выглядит вот так:

Тут же ищите элемент, который отсутствует на искомых страницах, но присутствует на нормальных страницах.
В нашем случае это столбец цен, и мы просто ищем страницы, где отсутствует столбец с таким названием (предварительно проверив, нет ли где в коде закомменченного подобного столбца)

Выглядит это так

Выглядит это так

Выгружаем Custom 1 и Custom 2.

Далее в Excel ищем урлы которые совпадают между файлами Custom 1 и Custom 2. Для этого объединяем 2 файла в 1 таблицу Excel и с помощью «Повторяющихся значений» (предварительно нужно выделить проверяемый столбец).

Фильтруем по красному цвету и получаем список урлов, где есть блок с выводом квартир, но нет столбца с ценами)!
Таким способом на сайте можно быстро найти и выгрузить выборку необходимых страниц для различных задач.
Пример 2 — Парсим содержимое заданного элемента на странице с помощью CSSPath
Давайте разбираться, как такое сделать
Открываете страницу где есть блок, который вам нужен и с помощью просмотра кода ищите класс блока, текст которого нам нужно выгружать.

Выглядит это так

Для того, чтобы не парсить весь сайт целиком, вы можете ограничить область поиска с помощью указания конкретного раздела, который нужно парсить.
Указываем сюда разделы, в которых содержатся все нужные страницы.
Выглядит это вот так для обоих случаев.

Далее парсим сайт, вбив в строку свой урл. В нашем случае это https://www.ughotels.ru/kurorty/otdyh-v-sochi.

Теперь в Excel чистим файл от пустых данных, так как не на всех страницах есть подобные блоки, поэтому данных нет.

После фильтрации мы рекомендуем для удобства сделать транспонирование таблички на второй вкладке, так ее станет удобнее читать.
Для этого выделяем табличку, копируем и на новой вкладке нажимаем

Получаем итоговый файл: 
Пример 3 — Извлекаем содержимое нужных нам элементов сайта с помощью запросов XPath
Задача: Допустим, мы хотим спарсить нестандартные, необходимые только нам данные и получить на выходе таблицу с нужными нам столбцами — URL, Title, Description, h1, h2 и текст из конца страниц листингов товаров (например, https://www.funarena.ru/catalog/maty/). Таким образом, решаем сразу 2 задачи:
Сначала немного теории, знание которой позволит решить эту и многие другие задачи.
Технический парсинг сайта и сбор определенных данных со страницы с помощью запросов XPath
Как уже говорилось выше, SEO-специалисты используют технический парсинг сайта в основном для поиска “классических” тех. ошибок. У парсеров даже есть специальные алгоритмы, которые сразу помечают и классифицируют ошибки по типам, облегчая работу SEO специалиста.
Но бывают ситуации, когда с сайта необходимо извлечь содержимое конкретного класса или тега. Для этого на помощь приходит язык запросов XPath. С помощью него можно извлечь с сайта только нужную информацию, записать ее в удобный вид и затем работать с ней.
Ниже приведем примеры некоторых вариантов запросов XPath, которые могут быть вам полезны.
Данные взяты из официальной справки. Там вы сможете увидеть больше примеров.
По умолчанию парсер Screaming Frog SEO Spider собирает только h1 и h2, но если вы хотите собрать h3, то XPath запрос будет выглядеть так:
//h3

Если вы хотите спарсить только 1-й h3, то XPath запрос будет таким:
/descendant::h3[1]
Чтобы собрать первые 10 h3 на странице, XPath запрос будет:
/descendant::h3[position() >= 0 and position() Теперь вернемся к изначальной задаче
В предыдущем примере мы показали, как парсить с помощью CSSPath, принцип похож, но у него есть свои особенности.

При таком копировании мы получили /html/body/section/div[2]/ul[2]/li/div
Для элементарного понимания, таким образом в коде зашифрована вложенность того места, где расположен текст. И мы получается будем проверять на страницах, есть ли текст по этой вложенности.

На скрине мы оставили вариант парсинга того же текста, но уже с помощью CSSPath, чтобы показать, что практически все можно спарсить 2-мя способами, но у Xpath все же больше возможностей.
Получаем Excel с нужными нам данными.

После фильтрации удобно сделать транспонирование полученных данных.

Пример 4 — Как спарсить цены и названия товаров с Интернет магазина конкурента
Задача: Спарсить товары и взять со страницы название товара и цену.

Начнем с того, что ограничим область парсинга до каталога, так как ссылки на все товары ресурса лежат в папке /catalog/. Но нас интересуют именно карточки товаров, а они лежат в папке /product/ и поэтому их тоже нужно парсить, так как информацию мы будем собирать именно с них.
https://okumashop.ru/catalog/.* ← Это страницы на которых расположены ссылки на товары.
https://okumashop.ru/product/.* ← Это страницы товаров, с которых мы будем получать информацию.
Для реализации задуманного мы воспользуемся уже известными нам методами извлечения данных с помощью CSSPath и XPath запросов.
Заходим на любую страницу товара, нажимаем F12 и через кнопку исследования элемента смотрим какой класс у названия товара.

Иногда этого знания достаточно, чтобы получить нужные данные, но всегда стоит проверить, есть ли еще на сайте элементы, размеченные как

Цену можно получить, как с помощью CSSPath, так и с помощью Xpath.
Если хотим получить цену через XPath, то также через исследование элемента копируем путь XPath.

Получаем вот такой код //*[@id=»catalog-page»]/div/div/div/div[1]/div[2]/div[2]/div[1]
Идем в Configuration → Custom → Extraction и записываем все что мы выявили. Важно выбирать Extract Text, чтобы получать именно текст искомого элемента, а не сам код.

После парсим сайт. То, что мы хотели получить находится в разделе Custom Extraction. Подробнее на скрине.

Выгружаем полученные данные.

Получаем файл, где есть все необходимое, что мы искали — URL, Название и цена товара

Пример 5 — Поиск страниц-сирот на сайте (Orphan Pages)
Задача: — Поиск страниц, на которые нет ссылок на сайте, то есть им не передается внутренний вес.
Для решения задачи нам потребуется предварительно подключить к Screaming frog SEO spider Google Search Console. Для этого у вас должны быть подтверждены права на сайт через GSC.
Screaming frog SEO spider в итоге спарсит ваш сайт и сравнит найденные страницы с данными GSC. В отчете мы получим страницы, которые она не обнаружила на сайте, но нашла в Search Console.
Давайте разбираться, как такое сделать.
Подключаемся к Google Search Console. Просто нажимаете кнопку, откроется браузер, где нужно выбрать аккаунт и нажать кнопку “Разрешить”.

В окошках, указанных выше нужно найти свой сайт, который вы хотите спарсить. С GSC все просто там можно вбить домен. А вот с GA не всегда все просто, нужно знать название аккаунта клиента. Возможно потребуется вручную залезть в GA и посмотреть там, как он называется.
Выбрали, нажали ок. Все готово к чуду.
Теперь можно приступать к парсингу сайта.
Тут ничего нового. Если нужно спарсить конкретный поддомен, то в Include его добавляем и парсим как обычно.
Если по завершению парсинга у вас нет надписи “API 100%”



Открываем получившийся отчет. Получили список страниц, которые известны Гуглу, но Screaming frog SEO spider не обнаружил ссылок на них на самом сайте.

Возможно тут будет много лишних страниц (которые отдают 301 или 404 код ответа), поэтому рекомендуем прогнать весь этот список еще раз, используя метод List.

После парсинга всех найденных страниц, выгружаем список страниц, которые отдают 200 код. Таким образом вы получаете реальный список страниц-сирот с которыми нужно работать.
На такие страницы нужно разместить ссылки на сайте, если в них есть необходимость, либо удаляем страницы или настраиваем 301 редирект на существующие похожие страницы.
Вывод
Парсеры помогают очень быстро решить множество задач не только технического характера (поиска ошибок), но и массу бизнес задач, таких как, собрать структуру сайта конкурента, спарсить цены и названия товаров и и другие полезные данные.
Если у вас возникают вопросы по данной теме или вам нужны услуги в области продвижения сайтов, смело обращайтесь к нам!
Что такое парсер и как с ним работать
Статья обновлена 09.07.2022
Ответить на вопрос, что такое парсер, довольно легко, если вы владеете английским языком. В переводе «parsing» означает провести грамматический разбор слова или текста. Первоначальное значение произошло от латинского «pars orationis» — часть речи. Таким образом, парсинг — это метод, при котором строка или текст анализируются и разбиваются на синтаксические компоненты. Затем полученные данные преобразуются в пригодный формат для дальнейшей обработки и использования в прикладных исследованиях. Получается, что один формат данных превращается в другой, более читаемый. Допустим, вы получаете данные в необработанном коде HTML, а парсер принимает его и преобразует в формат, который можно легко проанализировать и понять.
В этом материале мы разберем, как парсить и что это значит, виды парсеров; узнаем, для чего он может понадобиться в программировании и маркетинге, а также запишем тонкости его применения и многое другое.
Парсинг: общие понятия и практика
Парсинг предлагает инструментарий, который помогает извлекать нужные значения из любых форматов данных. Извлеченные данные сохраняются в отдельном файле — либо на локальном компьютере, либо в облаке или на хостинге, либо напрямую в базе данных. Это процесс, который запускается автоматически.
Проанализировать собранную информацию помогает программное обеспечение. Что значит парсить в программировании? Работающий парсер посылает запрос типа GET на сайт-«донор», который должен взамен отдать данные. В результате этого запроса создается HTML-документ, который будет проанализирован программой. Затем парсер осуществляет в нем поиск необходимых данных и выполняет преобразование в нужный формат.
Существует 2 разных метода выполнения веб-парсинга:
Парсинг не является запрещенным методом сбора и анализа информации. Часто даже сайты государственных служб предоставляют данные для публичного использования, доступные через API. Поскольку сбор такой информации — это обработка огромных массивов данных, на помощь приходят парсеры.
Парсинг и краулинг: отличия
Парсинг иногда путают с краулингом. Это происходит потому, что данные процессы схожи. Оба имеют идентичные варианты использования. Разница — в целях.
Обе операции «заточены» на обработку данных с сайтов. Процессы автоматизированы, поскольку используют роботов-парсеров. Что это такое? Всего лишь боты для обработки информации или контента.
И парсинг, и краулинг проводят анализ веб-страниц и поиск данных с помощью программных средств. Они никак не изменяют информацию, представленную там, и работают с ней напрямую.
Парсинг собирает данные и сортирует их для выдачи по заданным критериям. И это необязательно происходит в Интернете, где делают парсинг веб-страниц. Речь идет о данных, а не о том, где они хранятся.
Например, вы хотите поработать над ценовой аналитикой. Для этого вы запускаете созданные парсеры товаров и цен на них, чтобы собрать информацию с Avito или с любого интернет-магазина. Таким же образом можно анализировать данные фондового рынка, объявления по недвижимости и так далее.
Краулинг или веб-сканирование — прерогатива поисковых ботов или пауков. Краулинг включает в себя просмотр страницы целиком в поисках информации и ее индексацию, включая последнюю букву и точку. Но никакие данные при этом не извлекаются. Интернет-бот, он же — парсер поисковой системы — тоже систематически просматривает всемирную паутину для того, чтобы найти сайты и описать их содержимое. Самое важное отличие от краулера — он собирает данные и систематизирует их.
То, что делают Google, Яндекс или Yahoo — простой пример веб-сканирования. Это тоже своего рода парсинг. Что это такое простыми словами? Когда поисковые машины сканируют сайты и используют полученную информацию для индексации. Подробно об этом процессе можно прочитать в нашем глоссарии.
Что такое программа парсер и как она работает
Некоторые не понимают разницы: парсер или парсинг? Парсер — программное решение, а парсинг — процесс.
То есть программа для парсинга — это парсер. Она предназначена для автоматической обработки и извлечения данных.
Для анализа заданного текста такое ПО обычно использует отдельный лексический анализатор. Он называется токенайзером или лексером. Токенайзер разбивает все входные данные на токены — отдельные символы, например, слова. Полученные таким образом токены служат входными символами для парсера.
Затем программа обрабатывает грамматику входных данных, анализирует их и создает синтаксическое древо. На этой основе идет дальнейшая работа парсера с информацией — генерация кода или выборка по определенным критериям.
Парсинг данных: методы
Существует два основных метода парсинга: нисходящий и восходящий. Обычно они различаются порядком, в котором создаются узлы синтаксического древа.
Но метод работы — не самое важное. Хорошо сделанный парсер — восходящий или нисходящий — будет различать, какая информация, например, в строке HTML необходима. И в соответствии с заранее написанным кодом и правилами синтаксического анализа выберет нужные данные и преобразует их, например, в формат JSON, CSV или даже в таблицу Excel.
Важно отметить, что сам парсер информации не привязан к определенному формату данных. Это просто инструмент, который преобразует один формат в другой. А вот как он преобразует его и во что, зависит от текущих задач.
Где применяется парсинг
Парсинг используется для преобразования текста в новую структуру в следующих случаях:
В цифровом маркетинге парсинг применяют, чтобы собрать и проанализировать определенную информацию из контента нужных сайтов.
Парсинг страницы: применение
Парсинг страниц, ведущий сбор информации из веб-контента сайтов, используется в различных сферах — для продаж, маркетинга, финансов, электронной коммерции, сбора информации по конкурентам и так далее. Активно его применяют в следующих областях.
В розничной торговле существует множество возможностей использования парсинга. Например, мониторинг цен конкурентов или аналитика рынка, где парсинг используют для обработки данных и извлечения из них ценной для маркетологов информации.
Так, для электронной коммерции может потребоваться бесчисленное количество изображений и описаний товаров. Их нельзя просто создать за пару-тройку дней, так как даже просто скопировать и вставить каждый займет определенное время. Гораздо проще и быстрее создать парсинг и быстро «выцепить» все нужное. Или взять аналитику рыночных цен — регулярный парсинг веб-страниц конкурентов поможет своевременно замечать и учитывать все изменения на рынке.

Как проанализировать контекстную рекламу конкурентов
Бизнес — своего рода постоянный спринт. Здесь важно обогнать как можно больше соперников за короткий промежуток времени. Поэтому анализ ключевых слов рекламной кампании конкурентов — …
Анализ рынка акций
Раньше анализ фондового рынка ограничивался изучением финансовой отчетности компаний и, соответственно, инвестированием в наиболее подходящие ценные бумаги. Сегодня каждая новость или изменения настроений в политике и в обществе важны для определения текущих трендов. Как получать такие альтернативные данные? Здесь помогает парсинг. Он позволяет получить всю совокупность информации, связанной с рынком, и увидеть общую картину. Не говоря уже о том, что извлекать годовые отчеты и все стандартные финансовые данные с любого сайта гораздо проще и быстрее с помощью парсинга.
По сути, каждый парсер проходит обучение. Это позволяет искусственному интеллекту обнаруживать закономерности. Однако для того, чтобы установить нужные связи, необходимо передать в компьютерный разум много данных и помочь связать одно с другим. Часто парсеры применяются в технологиях AI, чтобы обеспечить регулярный поток обучающей информации.
Что это такое? Парсинг электронной почты позволяет анализировать входящие и исходящие сообщения. Затем их содержимое можно интегрировать в различные приложения c помощью программного интерфейса API или собрать для дальнейшего анализа.
Электронная почта — одна из наиболее загруженных данными форм современного общения. Обычная отправка одного электронного письма собирает, передает и интерпретирует около 100 Кб данных. Умножьте на миллиарды, и вы поймете, почему компаниям может быть сложно управлять такими объемами информации. К счастью, решение проблемы сегодня берут на себя специальные парсеры.

5 шагов к эффективной email-рассылке
В этой статье мы расскажем о секретах создания эффективной email-рассылки и разберем ключевые вопросы: Цели и результаты email-рассылки. Целевая аудитория и база контактов. Время и …
Большинство компаний используют решения на основе API для 3 основных видов приложений.
Как проходит веб-парсинг
Принцип работы парсеров для веб-страниц одинаков, обычно он состоит из 3 этапов.
Первый шаг — запросить у целевого сайта содержимое определенного URL-адреса. Взамен парсер получает запрошенную информацию в формате HTML.
2. Разбор и извлечение
Синтаксический анализ обычно применяется к любому компьютерному языку. Это процесс распознавания кода в виде текста и создания структуры в памяти, которую компьютер может понять и с которой будет работать.
Проще говоря, парсер берет HTML-код и извлекает оттуда соответствующую информацию — такую, как заголовок страницы, абзацы, подзаголовки, ссылки, выделения жирным, нужные темы и так далее, проводя парсинг текста.
3. Загрузка данных
Полученные данные загружаются и сохраняются. Формат файла задается таким образом, чтобы его можно было открыть в другой нужной программе. Для Google Таблиц это, например, CSV, для парсинга базы данных — JSON и так далее.
Готовое решение или собственный парсер
Предположим, вам нужно проводить регулярный мониторинг, чтобы отслеживать ценовую политику других поставщиков. И каждый раз, когда конкурент снижает цены, должно приходить соответствующее уведомление.
Чтобы решить эту задачу, возможны два варианта — создать собственный парсер или купить готовое решение на аутсорсинге. Что же выбрать?
На этот вопрос непросто ответить, и при принятии решения стоит учитывать различные факторы. Давайте рассмотрим возможности и результаты обоих вариантов.
Создание собственного парсера данных
Допустим, вы решили создать собственный парсер и знаете, как написать код. Самостоятельно парсить — что это даст и нужно ли вам это? Принятие такого решения имеет несколько преимуществ.
Есть и обратная сторона медали.
Создание собственного парсера имеет свои преимущества, но потребует ресурсов. Особенно если вы понимаете, для чего вам нужен парсер такого масштаба. Например, разработать сложное решение для больших объемов информации и контролировать не одного, а несколько десятков крупных конкурентов.
Парсеры данных на аутсорсе
Как насчет покупки готового инструмента, который проанализирует нужные данные по конкурентам за вас? Начнем с преимуществ.
Конечно, у готового решения есть и недостатки.
Кажется, у обоих вариантов есть свои плюсы и минусы, и трудно сказать, как сделать лучше и как правильно парсить. На самом деле это — вопрос объема данных. Опытный разработчик может сделать для вас простой парсер сайтов за неделю или вы можете создать его сами, используя онлайн-сервисы. Но если перед вами стоит сложная задача, на это могут уйти месяцы.
Таким образом, если вы — крупная компания и анализируете большие массивы информации, потребуются значительные усилия и привлечение сторонних компаний для разработки и сопровождения парсера. Если же вы — малый предприниматель или представляете небольшой бизнес и вам нужен менее сложный парсер меньшего размера — вероятно, лучше создать свой собственный, например, с помощью специальных программ.
Программа для парсинга сайтов: ТОП-30 лучших сервисов
Какой же выбрать парсер? Для сбора информации без него не обойтись. Важно не просто создать соответствующее программное решение, но и предотвратить блокировку вашего IP-адреса в процессе. А также обеспечить обход капчи, построение синтаксического древа на основе заданных значений, удаление заголовков, выборку данных, представленных в нужном формате. Все это требует больших усилий.
Как со всем этим справиться, если вы не понимаете, что значит в программировании парсинг, и вообще не программист, а всего лишь уверенный пользователь? Конечно, с помощью специальных программ.
Мы подготовили для вас список из 30 популярных решений для парсинга, представленных сегодня на рынке. От простых онлайн-сервисов до браузерных плагинов и ПО для настольных ПК.
При выборе парсера следует учитывать форматы вывода, поддерживаемые сервисом, его способность работать с современными сайтами — например, поддержку элементов управления Ajax, а также возможности автоматизации и формы отчетности.
Инструмент для обширного парсинга по заданным URL-адресам. Возможна работа через API, которые настраиваются под любые задачи. Например, это могут быть общие шаблоны обработки HTML-страниц или сбор информации из интернет-магазинов. А также настройка API для обработки объявлений с нужных сайтов.
Программа представляет API-интерфейс для парсинга через браузер или через защищенный прокси-сервер. Она может выполнять JavaScript на сайтах и изменять прокси для каждого запроса, чтобы получать HTML-коды без блокировки. У ScrapingBee также есть специальный API для связки с поиском Google.
Это масштабируемая платформа для извлечения данных, которую можно настроить для парсинга файлов и структурирования различной информации с сайтов, а также документов в виде PDF и текста, исторических данных, электронной почты. Сервис даже способен работать как парсер сообщений в социальных сетях. Преобразовывает все данные в готовый к анализу формат.
Сервис дает обширные возможности обработки HTML-кода и работает как парсер по ключам. Он позволяет собирать данные через API и браузер, обходить блокировки и капчи. Результаты легко интегрировать в собственный проект. Достаточно настроить отправку запроса GET в конечную точку Сети с ключом API и URL-адресом. Эта функция позволяет использовать ScraperAPI как граббер сайтов.
Сервис работает как парсер веб-ресурсов: помогает сформировать массив данных путем импорта их из любых страниц сайта. Парсить файл можно с последующим экспортом данных в формат CSV. Полученную информацию через API и веб-перехватчики можно размещать сразу в базу данных собственного проекта и в различные приложения. Сервис работает и как граббер контента.
Сервис позволяет обрабатывать тысячи сайтов с информацией, причем берет как текущий контент, так и исторические данные более чем 10-летней давности.
Преимущества
Dexi Intelligent Parser
Сервис позиционирует себя как платформу для скоростного парсинга больших объемов данных с немедленной выдачей результатов. Прост в настройке, позволяет одновременно вести несколько широкомасштабных парсеров проектов.
Этот сервис — удобный парсер сайтов онлайн. Причем бесплатный, что делает его отличным выбором для начинающих. Усовершенствованный алгоритм позволяет парсить нужные данные, просто щелкая мышкой по кнопкам. И загружать полученную информацию в удобном виде для дальнейшей обработки.
Сервис без проблем позволяет получать различные типы и массивы данных с сайтов в Интернете. Точность и аккуратность всех операций с любого URL-адреса обеспечивают парсеры искусственного интеллекта AI.
Сервис располагает средствами расширенного лингвистического анализа. Это позволяет ему работать не только с контентом сайтов, но и с социальными сетями. Для полноценного парсинга достаточно задать набор метаданных, в том числе тегов, по которым будет проводиться поиск.
Сервис поддерживает парсинг сайтов, краулинг, экранное сканирование, выполнение динамических сценариев на платформе Windows или Mac OS.
Это библиотека для JavaScript, поддерживающая широкие возможности парсинга и краулинга. Помогает вести разработку и парсинг с помощью так называемых безголовых браузеров — ПО, которое работает с URL-адресами напрямую, без отрисовки содержимого на экране.
Sequentum — визуально простое решение для работы с многопоточными массивами информации. Парсинг осуществляется через понятный графический интерфейс, что позволяет быстро настроить работу и получать нужные данные.
Это высокопроизводительный сервис парсинга, предоставляющий миллионы прокси. С его помощью можно спарсить базу данных с такими возможностями, как рендеринг JavaScript и обход капч.
Scrapingdog предлагает следующие виды парсеров:
Mozenda — коммерческое программное обеспечение для парсинга, разработанное для всех видов задач по извлечению данных. Компания работает с 30% компаний из списка Fortune 500 по таким задачам как крупномасштабный мониторинг цен, исследование рынка, мониторинг конкурентов. Услуги Mozenda по парсингу данных доступны как на локальном ПК, так и в облаке. ПО поможет подготовить данные для анализа стратегии, финансов, маркетинговых исследований, торговых операций и продаж. Подходит для больших корпораций с крупными проектами. Mozenda также может создать индивидуальный парсер по запросам заказчика.
Эта десктопная программа позволяет спарсить даже сложные и динамические сайты с разветвленными сценариями. Несмотря на широкий функционал, ParseHub отличается простотой настроек и понятным интерфейсом. Он может выполнять парсинг с нескольких страниц одновременно, взаимодействовать с Ajax, формами, раскрывающимися списками и так далее. Сама обработка информации происходит на серверах Parsehub, нужно только создать парсеру инструкцию в приложении.
ScrapingHub — одна из самых известных компаний, занимающихся веб-парсингом. Предоставляет облачную платформу и хостинг Scrapy с множеством шаблонов для парсинга — как с открытым исходным кодом, так и коммерческих. Сервис предназначен для технологических компаний и индивидуальных разработчиков.
Octoparse — десктопная программа для парсинга веб-сайтов всех типов. Она удобна для тех, кто мало что понимает в программировании. Есть даже шаблон для парсинга экрана, позволяющий пользователям просматривать страницы входа, заполнять формы, вводить условия поиска, отображать бесконечную прокрутку, выполнять JavaScript и многое другое. В рамках бесплатного тарифа можно создать до 10 собственных парсеров. Octoparse работает только на ОС Windows.
Webharvy — хорошее ПО для простого парсинга. Десктопная версия загружается на ваш локальный компьютер и не использует облачные ресурсы. Если вы работаете над небольшими проектами и ищете ответ на вопрос, как пользоваться парсером без лишних усилий, установите Webhatvy. С его помощью можно обрабатывать данные по входу в систему, регистрации пользователей и даже отправке форм. Позволяет распарсить несколько страниц за считанные минуты. Однако есть серьезные ограничения. Если нужно выполнить крупномасштабный парсинг, это может занять много времени, так как возможности ограничены техническими характеристиками локального компьютера. Также ПО не поддерживает обход капчи.
80legs существует уже много лет. Ресурс предлагает возможности быстрого парсера ссылок. Что это такое и для чего нужен такой функционал? Проще говоря, если вам необходимо обработать много простых запросов, переходя по многочисленным ссылкам с веб-страниц. Однако в прошлом сервис использовали для DDOS-атак, поэтому при повышенной частоте парсинга он может блокироваться. Работать с ним просто — достаточно ввести один или несколько URL-адресов, с которых нужно собрать данные. Поддерживает обработку до нескольких тысяч веб-страниц.
Grepsr — целая платформа для парсинга веб-страниц. Поможет собрать нужные данные, отсортировать их и интегрировать в нужную систему аналитики. Позиционируют себя как сервис для всех — от маркетологов до инвесторов. Позволяет сделать парсинг новостей с других сайтов, сбор финансовых данных или данных о конкурентах, обработку информации для программ генерации лидов, и так далее.
ProWebScraper — онлайн-инструмент для визуального парсинга веб-страниц. Не требует навыков программирования. Достаточно просто выбрать интересующие элементы. А ProWebScraper добавит их в набор данных для парсера. Это пока единственный сервис на рынке, который предоставляет бесплатную настройку парсинга.
Есть возможность собирать данные с 90% сайтов в Интернете — инструмент позволяет запускать широкомасштабные проекты. Разработан специально для тех, кто хочет провести парсинг без особых усилий. Компания также предлагает создание индивидуальных парсеров за дополнительную плату, если по каким-то причинам не хочется создавать его самому.
ScrapeBox — программное обеспечение для настольных ПК, позволяющее выполнять многие задачи парсера. Программа продолжает развиваться — регулярно выпускаются обновления. Позволяет парсить практически любой тип данных — от электронной почты до ключевых слов.
Scrapy — бесплатный фреймворк для парсинга и веб-сканирования с открытым исходным кодом, написанный на Python. Первоначально разработанный для парсинга, он также может использоваться для извлечения данных с помощью API или даже в качестве универсального поискового робота. Отлично подходит для крупномасштабной обработки веб-страниц с повторяющимися задачами. Требует навыков программирования.
Web Scraper предоставляет не только услуги парсинга, но и облачную платформу для доступа к собранным данным. Может извлекать данные с динамических сайтов. Простой интерфейс не требует навыков программирования. Если для решения ваших задач требуются прокси-сервера или работу нужно выполнять, например, ежедневно, поможет Web Scraper. Он предоставляет облачное серверное решение, где можно запускать созданный парсер, с ежемесячной оплатой.
Плагин Outwit для Firefox
Это плагин для браузера Firefox, который легко загрузить из официального магазина Mozilla AMO. Есть 3 различных варианта ПО в соответствии с нужными требованиями: профессиональная версия, экспертная версия и бизнес-версия.
Плагин Web Scraper для Chrome
Web Scraper — плагин для Chrome, который помогает выполнять парсинг веб-страниц и сбор данных. Позволяет масштабировать проекты и обрабатывать несколько страниц сразу, есть возможности динамического извлечения данных.
Плагин Simplescraper для Chrome
Simplescraper — простой в использовании плагин для Chrome, позволяющий быстро спарсить данные с нужного сайта. Для этого потребуется указать нужные элементы и сделать несколько простых настроек.
Плагин Dataminer для Chrome и Edge
Dataminer — один из самых известных плагинов для веб-сканирования и парсинга. У него довольно много функций по сравнению с другими — обычно плагины проще в использовании, чем, например, десктопное ПО, но это не тот случай. Вполне подойдет даже для разработчиков как удобный и понятный инструмент.
Плагин Scraper для Chrome
Scraper — это еще один плагин Chrome, своего рода мини-парсер. Задание определённого запроса обеспечивает легкий сбор данных с веб-страниц. Плагин предлагает интеллектуальный анализ для облегчения работы, когда нужно быстро преобразовать данные в электронную таблицу. Задуман как простой в использовании инструмент для пользователей среднего и продвинутого уровня, знакомых с языком запросов XPath.
Плагин Data Scraper для Chrome
Data Scraper — это быстрый способ того, как программой парсить данные с сайта. Он может извлекать данные из любых HTML-кодов. Извлеченные данные сохраняются в электронных таблицах Excel. Им может пользоваться кто угодно — от студентов и рекрутеров до аналитиков и менеджеров по рекламе.
Частые вопросы
Иногда такие сервисы называют парсерами текста с сайта. Они онлайн собирают всю нужную информацию со статических или динамических веб-страниц, а затем преобразуют ее в нужный формат. Часто такие решения используют для глубокого анализа контента — сопоставления источников новостей, выявления плагиата, сбор определенной информации по темам и так далее.
Парсинг: что это такое простыми словами
Сегодня парсинг настолько распространен, что о нем должен знать каждый вебмастер, а маркетолог и подавно. Когда-нибудь его надо включать в список обязательных инструментов, ведь при грамотном использовании можно извлечь немало пользы. Процесс этот отличается от взлома, а если следовать инструкциям (прописанным в robots.txt на сайтах), то и вполне законный.

Что такое парсинг и что значит парсить
Дословный перевод слова parsing — делать грамматический разбор или структурировать. В программировании/информатике, это автоматический сбор и систематизация необходимых сведений, размещенных на веб-ресурсах с помощью специальных программ.
Принцип работы парсинга основывается на сравнении готового общепринятого шаблона и найденной в сети информации. Например, вы создали интернет-магазин и хотите его продвигать. Вам нужно скопировать данные о товарах (цены, изображения, описания) у конкурентов, а потом разместить на своем сайте. Делать это вручную — длительная и рутинная работа, особенно когда речь идет о 500-1000 товарах. Поэтому процесс автоматизируется, и сбор данных доверяется программе/сервису. Результатом станет колоссальная экономия времени.

Подробнее о преимуществах автоматического сбора данных:
Единственное, что не умеет делать парсер, это уникализировать информацию — контент просто собирается из открытых источников.
Программа парсер
В роли парсера может выступить программа, сервис или скрипт. Функция у них одна — собрать данные с указанных web-сайтов, анализировать и выдать в нужном формате. Обычно используют десктопные и облачные парсеры, основное преимущество которых в отсутствии необходимости скачивать программу и устанавливать на свой комп. Вся работа производится в облаке.
Вот, например, несколько облачных парсеров на русском языке.
А это пара десктопных сервисов:
Что такое парсинг слов и зачем нужно
Парсинг также активно применяется вебмастерами и оптимизаторами для сбора семантического ядра с дальнейшей кластеризацией запросов. Таким образом, инструмент может решить вопросы с продвижением сайта и составлением рекламной кампании в Яндекс.Директе и Гугл Адс.
Среди популярных программ для парсинга в Seo:
В этапы работ над семантическим ядром сайта входит — определение поисковых фраз, анализ конкурентов, сбор данных со всех источников и т. д.
Что такое парсинг товаров и зачем нужно
Парсить товары, значит — собирать нужную информацию о продукции из готового каталога онлайн-магазинов. Обычно это делается в целях анализа ценовой политики конкурентов или для заполнения витрины своих сайтов. Ручной сбор такой информации и тщательная сортировка занимает много времени, поэтому автоматизация процесса напрашивается априори.

Например, парсинг товаров часто используется владельцами крупных интернет-магазинов. Это позволяет избавиться от рутинной работы, увеличить скорость сбора данных и сделать процесс более качественным.
Вот как работает парсинг:
Что такое парсинг сайтов и зачем нужно
Парсинг сайтов бывает двух типов:
Алгоритм работы простой — машинальное извлечение открытых данных. Парсер переходит по ссылкам исследуемого сайта и собирает информацию по каждой странице. Сведения записываются в Excel или какой-нибудь другой файл.
Что такое парсинг аудитории и зачем нужно
Автоматический поиск и выгрузка данных о пользователях соцсетей по конкретному алгоритму называется парсингом аудитории. Данный процесс проводится на автомате (специальными программами) или вручную (таргетологи) — целью является выгрузка собранной информации в соответствующий рекламный кабинет.
 Парсинг аудиторий из Инстаграма и Фейсбука
Парсинг аудиторий из Инстаграма и Фейсбука
Чаще всего аудиторию группы парсят по активным ее пользователям — админам, модераторам, редакторам или просто старожилам, регулярно публикующим контент. Такой метод позволяет быстро и точно подобрать ЦА под свою нишу. Это будут потенциальные покупатели, которых реально заинтересует товар или услуга. Таким образом, маркетолог сэкономит средства и время, а реклама не будет показываться всем подряд.
Парсинг по аудитории можно настроить еще точнее, используя различные критерии выбора — возраст, семейное положение, финансовый статус, хобби и интересы. В таком случае бюджет РК сократится еще больше, а вероятность покупок и целевых действий возрастет.
Что такое парсинг в программировании и зачем нужно
Принцип работы парсинга в программировании — сравнение строк или конкретных символов с готовым шаблоном, написанном на одном из языков. Другими словами, это процесс сопоставления и проверки стоковых данных, проводимый по определенным правилам. Цель — найти проблемы производительности, несоответствие кода требованиям и другие недостатки сайтов/ресурсов/приложений.
Обычно айтишники разрабатывают собственные парсеры на таких языках, как C++, Java Programing. Делается это из-за того что иногда требуемый синтаксический анализатор невозможно найти в свободном доступе.
На самом деле, парсинг в программировании не является чем-то сверх сложным. Рассмотрим, как он работает на примере разбора даты из строки.

С первого взгляда это какой-то непонятный код, но если приглядеться, то можно разобрать узнаваемые части.

Примерно таким же способом осуществляется синтаксический анализ целого языка. Строки делятся на маленькие биты синтаксиса. Парсинг применяется не только в программировании, но также в аналитике и любой другой области, где можно работать с данными в стоковом формате.
Что такое парсинг в Инстаграм и зачем нужно
Парсинг в Инсте используют как один из инструментов для работы с ЦА — чтобы отсортировать пользователей, заинтересованных в товаре. Благодаря этому снижается рутина и экономится время.

У парсинга в Instagram имеются широкие возможности анализа и мониторинга. Инструмент помогает собрать всю нужную информацию и наладить взаимодействие с пользователями. Вот что с его помощью получится сделать в Инстаграме:
Все эти функции позволят точечно запустить рекламную кампанию, настроить таргет и оформить «вкусное» коммерческое предложение.
Что такое парсинг Авито и зачем нужно
Парсинг полезен также в Авито — самой популярной доски объявлений в Рунете. С его помощью можно получить информацию обо всех постах, размещенных в определенных категориях, включая номера телефонов и адреса.

Чтобы спарсить данные с Avito, достаточно сделать так:
Инструмент соберет всю требуемую информацию в течение дня (в зависимости от объема данных) и выгрузит в документ. Обычно арбитражникам и маркетологам бывают нужны имена/контакты людей, цены на товары и изображения.
Полученные сведения можно использовать для отправки уведомлений на email, Gold calling, заполнения собственных площадок, анализа конкурентов и много чего еще. Сейчас есть возможность применять несколько парсеров для Авито — AvitoMonsterParser, FastParserAvito, Avi2-parser и другие.
Что такое парсер выдачи и зачем нужно
Парсеры для мониторинга поисковой выдачи входят в обязательный джентльменский набор опытного вебмастера, оптимизатора и маркетолога. Инструмент в этом случае настроен на сбор информации с заданного источника (Гугл, Яндекс, соцсети, форумы).
 Ттак выглядит парсер на Яндекс
Ттак выглядит парсер на Яндекс
В первую очередь такой сбор данных нужен для анализа сайтов конкурентов. Парсинг даст возможность определить лидеров топа, узнать их характеристики в разрезе Seo. Например, вот какие данные чужих ресурсов:
Предоставленная информация поможет специалисту найти качественные сайты-доноры для размещения на них обратных ссылок, потенциальных клиентов/партнеров, а также площадки для рекламы.
Что такое парсинг цен и зачем нужно
Обычно ценовая «разведка», а в частности про оборот товара осложняется тем, что некоторые компании скрывают такую информацию. Напротив, такие гиганты, как Wildberries, Lamoda, Leroy Merlin ее открыто выставляют. На основе этих данных можно будет составить общее представление о продажах и сделать полезные выводы. К примеру, определить самые продаваемые позиции и сфокусироваться на них, а дешевые отсечь.

Цены можно парсить из разметки shema.org — это самый простой способ. Но если стоимость бывает зачеркнута или прайс с остатками товара загружается отдельными запросами к серверу, приходится использовать более функциональные программы. Сегодня есть такие проги, которые умеют раскрывать информацию методом эмулирования.
Кейсы по заработку на парсинге
Существует несколько способов заработка на парсинге. Но обычно заказчиков интересуют:
Ниже представлен интересный кейс от CatalogLoader, решивший задачи компании, закупающейся в буржунете и продающей на Яндекс.Маркете.
Что надо было сделать:
Задача решилась эффективно, клиент получил все необходимые данные. Использовался парсер сервиса CatalogLoader.com, собравший всю актуальную информацию с зарубежного интернет-магазина по нужным категориям/брендам. Сведения выгрузили в Price-Matrix.ru, где можно их анализировать и делать переоценку.

Еще один кейс, выложенный на сайте im-business. К ним обратился клиент, занимающийся грузоперевозками Россия-Беларусь. Ниша оказалась весьма конкурентной, поэтому человеку приходилось держать постоянный штат операторов и регулярно обновлять сайты с запросами на перевозку — чтобы не упустить заказы, иначе конкуренты не спят.
Задача для команды была следующая: спарсить информацию с 5 сайтов, которые постоянно мониторят заявки и отбирают их по определенным критериям. Сложность была в том, что все площадки разные — для некоторых требовалась регистрация. Пришлось в настройках прописать код для авторизации.
Дальше сделали так:
Все полученные данные сохраняли в общей таблице, каждый параметр по своим ячейкам. Заказчику давалась возможность отфильтровывать грузы, отмечать взятые в работу, а обработанные заявки выгружать для логиста.

Результат — удалось сбросить значительную нагрузку с операторов фирмы, заявки стали обнаруживаться гораздо быстрее. Все это позволило опережать конкурентов и выходить в профит.
Заключение
Если у вас растущий бизнес или вы просто торгуете широко распространенными товарами, с парсингом вам придется столкнуться рано или поздно. Ничего противозаконного в нем нет, особенно при получении информации с интернет-магазинов. Здесь вы не нарушите закон о персональных данных или чьи-то авторские права