Snapshot что это
Snapshot что это
Как правильно работать со снапшотами виртуальных машин
«Snapshot» в переводе с английского означает «выстрел» или «мгновенный фотоснимок». Снапшот — это своего рода фотоснимок виртуальной машины (ВМ), слепок её конкретного состояния. Виртуальная машина может использоваться для различного рода экспериментов, или в нее могут вноситься изменения, которые затем нужно быстро откатить назад. Именно для того, чтобы каждый раз не мучиться восстановлением предыдущего состояния ВМ и существуют снапшоты, возвращающие ВМ к исходному состоянию. Снапшоты — не такая уж простая операция, во всяком случае, делаться она должна по правилам, о которых мы сегодня и расскажем.

Что такое снапшот?
Снапшот сохраняет состояние виртуальной машины и данные по ней в определенный момент времени.
Лучшие практики
Чтобы получить максимальную пользу от снапшотов, необходимо следовать нескольким правилам, которые позволят использовать снапшоты по максимуму и предотратить возникновение проблем.
Используйте отдельные инструменты для резервного копирования. Делайте снапшот, вносите изменения в виртуальную машину и удаляйте снапшот, как только будет подтверждено ее корректное состояние.
2) Снапшоты образуют цепочки или деревья.
VMware советует делать в одной цепочке только 2–3 снапшота:
a. Большее число снапшотов или снапшоты большого размера могут вызвать уменьшение производительности виртуальной машины и хоста.
b. Создание большого файла снапшота может заполнить доступное пространство хранилища, отключив таким обазом все виртуальные машины до тех пор, пока не будут внесены коррективы. Другими словами, снапшот на каждом отдельно взятом хосте может оказывать влияние на все виртуальные машины, использующее данное устройство хранения.
c. Файл снапшота может оказаться поврежденным.
d. Размер диска снапшотов оказывает непосредственное влияние на продолжительность времени, которое потребуется на удаление снапшота, относящегося к данной виртуальной машине. 
Деревья снапшотов на Windows и Linux
3) Не делайте снапшотов памяти виртуальной машины:
a. Продолжительность времени, которое занимает у ESX хоста запись памяти на диск, коррелирует с объемом памяти, на использование которого настроена виртуальная машина. Это может увеличить время на завершение операции, что в свою очередь может замедлить производительность виртуальной машины.
b. Если нет острой потребности в возвращении виртуальной машины к конкретному состоянию памяти, отключите опцию «Память». Состояние памяти редко может потребоваться.
4) Используйте более одного снапшота для промежутка времени в 24–72 часа.
Хотя 2–3 дня — это рекомендуемый период, иногда снапшот хранится 5 дней, а затем автоматически удаляется:
a. Это предотвращает снапшоты от разрастания до такого большого размера, который может вызвать проблемы при удалении его с диска виртуальной машины.
b. Сделайте снапшот и удалите его сразу после того, как внесете необходимые коррективы.
c. Будьте аккуратны со снапшотами высокозагруженных виртуальных машин, таких как серверы баз данных и почтовые серверы. Такие снапшоты могут быстро увеличиваться в размерах, заполняя пространство хранилища. Удаляйте снапшоты с виртуальных машин, как только они перестают быть необходимыми.
5) Виртуальные машины с несколькими дисками:
a. Снапшот может повлиять на дочерний или резервный диск: чем больше операций совершается с диском, тем больше он становится.
b. Требования к свободному пространству дочернего диска дополняют требования к родительскому диску, от которого он зависит.
c. Дочерний диск может вырасти до такого размера, что заполнит все пространство для хранения.
d. Существует правило «Без снапшотов» для дополнительных дисков размером 100 Гб и больше, поскольку есть вероятность заполнения хранилища данных и прекращения работы всех виртуальных машин, которые используют одно и то же хранилище.
e. Дополнительные диски более 100 Гб размером считаются независимыми — это предотвращает переход влияние снапшота с родительского диска на дочерний. 
Вместо заключения
Снапшот позволяет запечатлеть состояние виртуальной машины в конкретный момент времени. Снапшоты полезны в том случае, если требуется вернуться к одному состоянию виртуальной машин без необходимости создавать новые.
Снапшот несет следующую информацию:
snapshot
1 snapshot
2 snapshot
3 snapshot
4 snapshot
5 snapshot
снимок (в информационных технологиях)
Копия данных на некоторый момент времени. Снимок состояния виртуальной машины в определенный момент времени, включая все данные гостевой операционной системы, конфигурацию виртуальной машины, которые могут быть возвращены в последующем, откатывая любые изменения, которые были сделан с момента создания снимка. Снимки обычно используются для отката изменений или же для восстановления после аварий.
[ http://www.dtln.ru/slovar-terminov]
Тематики
снимок состояния
(ITIL Continual Service Improvement)
(ITIL Service Transition)
Текущее состояние конфигурационной единицы, процесса или любой другой набор данных, зафиксированный на определённый момент времени. Снимки могут формироваться средством обнаружения или вручную, например, при помощи обследования.
См. тж. базовое состояние; контрольная точка.
[Словарь терминов ITIL версия 1.0, 29 июля 2011 г.]
EN
snapshot
(ITIL Continual Service Improvement)
(ITIL Service Transition)
The current state of a configuration item, process or any other set of data recorded at a specific point in time. Snapshots can be captured by discovery tools or by manual techniques such as an assessment.
See also baseline; benchmark.
[Словарь терминов ITIL версия 1.0, 29 июля 2011 г.]
Тематики
6 snapshot
7 snapshot
делать снимок, фотографировать
8 snapshot
9 snapshot
The book is an accurate snapshot of upper-class English life. — Книга точно описывает образ жизни верхних слоёв английского общества.
10 snapshot
11 snapshot
12 snapshot
13 snapshot
14 snapshot
15 snapshot
16 snapshot
17 snapshot
18 snapshot
19 snapshot
20 snapshot
См. также в других словарях:
Snapshot — may refer to:* Snap shot, a shot from a firearm that is aimed and fired quickly * Snapshot (photography), a photograph that is taken in a short moment of opportunity * Snap shot (ice hockey), a shot type in Ice hockey * Snapshot algorithm, a… … Wikipedia
Snapshot — (от английского слова snap shot, что в дословном переводе значит выстрел навскидку): В фотографии Snapshot фотокросс (фотоконкурс с временными и тематическими ограничениями). В информатике Snapshot снимок файловой системы моментальный снимок,… … Википедия
Snapshot — steht für: Snapshot (Satellit) (militärische Bezeichnung OPS 4682), experimenteller Technologiesatellit der United States Air Force Snapshot (Film), Film aus dem Jahr 1979 Siehe auch: Schnappschuss (Begriffsklärung) … Deutsch Wikipedia
snapshot — UK US /ˈsnæpʃɒt/ noun [C] INFORMAL ► the way that a particular figure or set of figures gives an understanding of a situation at a particular time: »Credit rating agencies provide a snapshot of the risks an investment poses at any one time … Financial and business terms
snapshot — also snap shot, 1808, a quick shot with a gun, without aim, at a fast moving target, from SNAP (Cf. snap) + SHOT (Cf. shot) (n.). Photographic sense is attested from 1890 … Etymology dictionary
snapshot — ► NOUN ▪ an informal photograph, taken quickly … English terms dictionary
snapshot — [snap′shät΄] n. 1. a hurried shot fired with little or no aim 2. an informal photograph, usually intended for private use, taken with a small camera … English World dictionary
Snapshot — La palabra snapshot puede referirse a: Snapshot. Es un formato de archivo de Microsoft Access. Snapshot o copia instantánea de volumen. Es una función de algunos sistemas que realizan copias de seguridad de ficheros almacenándolos tal y como… … Wikipedia Español
snapshot — snap|shot [ˈsnæpʃɔt US ʃa:t] n 1.) a photograph taken quickly and often not very skilfully = ↑snap snapshot of ▪ a snapshot of his girlfriend 2.) a piece of information that quickly gives you an idea of what the situation is like at a particular… … Dictionary of contemporary English
snapshot — 1. noun a) A photograph, especially one taken quickly or in a moment of opportunity. He carried a snapshot of his daughter. b) A glimpse of something; a portrayal of something at a moment in time. The article offered a snapshot of life in that… … Wiktionary
В чем разница между Backup и Snapshot
Что такое Backup
Backup (бэкап) – это резервная копия данных. Она нужна, чтобы данные можно было восстановить, если они повреждены из-за физической поломки дисков, где они хранятся, атаки вируса-шифровальщика, человеческой ошибки и так далее. Главная цель бэкапов – сохранность данных.
Чтобы сделать бэкап, достаточно перенести файлы на новый носитель. Например, разместить фотоотчет с выпускного в облаке или скопировать его на флешку. Можно сделать резервную копию любых данных: файлов (тех же фото), ключей доступа, содержимого сайта, базы данных, исходного кода приложения.
Бэкапы появились десятки лет назад, тогда копии данных хранили на дисках, магнитных лентах и других физических носителях. Сегодня копии можно хранить и в облаке. Облачное хранение позволяет вернуть данные, даже если там, где установлены серверы и хранятся бэкапы, случится пожар, который уничтожит все носители информации.
Существует несколько видов резервного копирования.
Полный бэкап. Во время создания полного бэкапа сохраняются все данные без исключения. Когда старые бэкапы теряют актуальность, они удаляются, чтобы освободить место.
Такой бэкап занимает столько же места, сколько и оригинальные файлы. Это не страшно, если нужен дубликат исходников небольшого приложения – понадобится лишь несколько гигабайт. Но если необходимо сделать резервную копию всех данных какого-нибудь сервера, понадобится столько же места, сколько занимают эти данные: это еще один сервер с диском такого же размера либо столько же места в облачном хранилище.
Инкрементный и разностный бэкапы. Проблема с занимаемым местом и временем копирования решается с помощью разностного (дифференциального) и инкрементного бэкапов. В обоих случаях сначала создается полный бэкап, а затем производятся бэкапы тех данных, которые были изменены. При этом:

Чем отличаются разностный и инкрементный бэкапы
Недостаток обоих методов − в том, что восстановить информацию невозможно, если повредится первоначальный полный бэкап либо – в случае инкрементного – какой-то фрагмент цепочки. Поэтому чаще всего находят компромисс между полным и частичным бэкапированием. Например, ежемесячно создается полная копия данных, а каждую неделю – инкрементный бэкап.
Что такое Snapshot
Snapshot (снепшот) – это «заморозка» не только данных, но и всего состояния системы. Снепшот также называют моментальным снимком (от английского snapshot – снимок). Главная идея снепшотов − возможность в любой момент легко откатиться к более старому состоянию. Удобнее всего оказалось использовать снепшоты при работе с виртуальными машинами – многие среды виртуализации поддерживают их создание и возвращение к старым снимкам за пару простых действий.
С помощью снепшотов можно смело делать вещи, которые могут «испортить» компьютер или приложения на нем – например, ставить обновления критичных для бизнеса приложений и тестировать их работу. При любых неприятностях можно просто вернуться в определенную точку в прошлом. Это оказалось особенно ценно для разработки и тестирования.
Исходные данные «замораживаются» в виде файла или набора файлов, которые запрещено изменять. Все новые операции записываются в отдельные файлы. В этом отношении снепшот похож на инкрементальные бэкапы, так же можно создавать цепочки (последовательности) или деревья снимков – множество снепшотов системы на определенных этапах, что позволяет обратиться к нужной версии.

Дерево снепшотов. Можно вернуться к любой точке во времени, когда был снят снепшот
Но файлы снепшотов обычно хранятся рядом с «замороженными» исходными данными для быстроты доступа. Поэтому, в отличие от бэкапа, снепшот не требует отдельного хранилища.
Можно сделать как моментальный снимок системы целиком, так и каких-то отдельных данных. Моментальный снимок удастся сделать и с выключенным компьютером – у бэкапа такой возможности нет.
Когда используют бэкап
Создание бэкапа (резервное копирование) позволяет сохранить данные на длительный срок, чтобы их можно было восстановить в случае сбоя, повреждения или утраты носителя.
Лучше всего бэкап подходит в следующих ситуациях:
Когда лучше использовать снепшот
Смысл снепшотов − не в надежности, а в быстром и удобном восстановлении состояния системы. Если бэкапы надо хранить подальше от основной системы, чтобы не складывать все яйца в одну корзину, то есть – застраховаться от физического уничтожения системы вместе с бэкапами, то данные снепшота должны быть как можно ближе, чтобы сама передача данных не затягивала восстановление.
Использовать снепшот можно, чтобы потестировать приложения, обновления, патчи, обезопасить данные, если есть вероятность их повреждения.
Бэкапы и снепшоты работают вместе
Бэкапы и снепшоты − для разного: одни для надежности, другие для гибкости. Но когда нужно и то, и другое, они работают вместе.
Например, полное бэкапирование занимает много времени, это мешает сделать точную копию. В бэкапе может оказаться копия данных, отличная от оригинала, так что его нельзя будет восстановить из бэкапа. Представьте себе три папки: «Кошки», «Еноты» и «Ежи». Кошки уже скопировались в бэкап, сейчас копируются еноты. Если в этот момент взять ежа #8 и из «Ежей» перенести в «Кошек», система создания бэкапов этого не заметит. Когда она дойдет до «Ежей», #8 не попадет в бэкап− копия не будет содержать его ни в «Ежах», ни в «Кошках».
Конечно, на время создания копии можно переключить данные в режим «только для чтения», но в этот момент придется заблокировать работу с данными для всех приложений. Это подходит для домашнего компьютера, но не подходит для систем, которые должны быстро отвечать на запросы. В этом случае сначала создается снепшот системы − а это гораздо быстрее бэкапа. Потом системе разрешают меняться дальше, а бэкап создается уже с файла со снепшотом. Когда бэкап готов, к снепшоту применяются все дальнейшие изменения, после этого он удаляется.
Резюме
Бэкапы − для надежности хранения данных и возможности их восстановления или «клонирования» на другие компьютеры.
Снепшоты − для быстрого и удобного возвращения системы в прошлое состояние. Это помогает проводить «опасные» эксперименты.
Снапшоты — что это и зачем они нужны
Информацию, содержащуюся в цифровом виде, очень легко потерять. Об этом простом правиле знают не только разработчики, но и обыкновенные пользователи. Именно поэтому для любого владельца компьютерной техники чрезвычайно актуальной является задача сохранения цифровых данных. Это можно сделать при помощи резервного копирования.
Данная возможность позволяет создавать копии как отдельных файлов на компьютере и сервере, так и их совокупности. Более того, сегодня существует возможность копирования даже дисковых томов или операционных систем. 
Плюсы и минусы бэкапа
Главным преимуществом резервного копирования считается возможность быстрого восстановления любых данных. Но бэкап (именно так принято называть резервную копию цифровых данных) далеко не всегда позволяет полностью восстановить работу диска или ОС. Такая проблема чаще всего обусловлена тем, что сразу же после бэкапа может происходить существенное изменение копируемых данных. Следовательно, многие файлы и приложения ОС изменяются и уже не могут быть связаны с копией. 
Поэтому перед тем как сделать бэкап, следует воспользоваться снапшотом. Snapshot — это снимок или фотография текущего состояния системы. Снапшот(иногда говорят «снепшот») позволяет запечатлеть то состояние системы, в котором она сейчас находится, а затем «откатить» Операционную Систему до того момента, когда был сделан снимок.
Этот способ сохранения информации применяется тогда, когда требуется вернуться к одному состоянию виртуальной машины без необходимости создания нового.
Снапшоты содержат следующую информацию:
Снапшоты — что это и как их использовать
Первое, что стоит отметить – снапшот виртуальной машины может быть выполнен даже на выключенном устройстве. Однако выполнение снимка на несколько секунд приостанавливает работу компьютера. Но потом оборудование продолжает работать в своем прежнем режиме.
Snapshot можно сделать двумя способами:
Все созданные снимки файловой системы можно найти на странице с дисками. Особенностью «снимков» является их размер. Снапшоты «весят» на порядок меньше, чем диски. Еще одна особенность заключается в том, что сделанные снимки представляют собой своеобразную цепочку или дерево. Поэтому если удалить один из снимков, его «соседи» объединяться между собой. Процесс удаления ненужных снимков не занимает много времени.
Вот как выглядят «деревья» снапшотов на Windows и Linux:

Существенным преимуществом снапшотов является их многочисленность. Разработчики могут делать до 60 снимков, тем самым страхуя себя от случайной потери важной информации. Но не стоит переусердствовать, все-таки снапшоты тоже «подгружают» ОЗУ, а потому существует вероятность возникновения определенных ограничений в функционировании виртуальной инфраструктуры. Поэтому любой разработчик должен знать, что длительное хранение снепшотов не является целесообразным.
Экономия денег и времени при использовании снапшота
Разобравшись с тем, что такое snapshot и как он работает, можно перейти к описанию главного преимущества этой функции – экономии денег и времени. Финансовая выгода обусловлена тем, что иногда потерянные цифровые данные могут стоить огромных денег. При этом хранение снимков дисков или ОС на виртуальных серверах стоит несколько рублей за 1 гигабайт информации.
Что касается экономии времени, то функция snapshot позволяет восстановить все файлы и нормальную работу диска (ОС) в течение нескольких минут. Благодаря снапшоту разработчики могут быть застрахованы от финансовых и временных потерь.
Различия между Backup и Snapshot
Некоторые пользователи зачастую путают snapshot с резервным копированием (бэкапом). Но эти две функции имеют совершенно разный механизм действия.
Backup предусматривает архивацию определенного участка системы (или всей системы целиком). Бэкап – это длительный процесс, который вынуждает остановить все дисковые операции над участком файловой системы, который подлежит копированию. Главной проблемой бэкапа является возможность изменения скопированных участков. Именно поэтому зачастую возникают проблемы с восстановлением работы различных сервисов.
Снапшоты не требуют остановки операций и проводятся в течение нескольких секунд. Благодаря этому сервисы не успевают измениться и, следовательно, без проблем восстановятся в случае необходимости. 
Преимущества быстрого отката изменений при использовании снапшотов
Технология Snapshot имеет следующие преимущества:
Отдельно стоит сказать о безопасности копируемых данных. Снапшот виртуальной машины защищает информацию от записи и предоставляет ее в режиме ReadOnly. Поэтому в сделанном снимке будут хранится исключительно неповрежденные и статичные копии, которые можно восстановить при случайном повреждении или удалении оригинальных данных.
Отличия между Backup и Snapshot
Многие путают между собой термины backup и snapshot. Оба связаны с резервированием данных и возможностью «отката» к предыдущему состоянию, но принцип действия в обоих случаях – разный. Разберемся, что такое снапшот и бэкап, какая разница существует между определениями и в каких случаях их используют.
Подробнее о backup
 Этот термин обозначает резервное копирование данных. Она создается для того, чтобы восстановить все файлы в случае их повреждения или потери. Это может произойти после физической неисправности оборудования, вирусной атаки, ошибки сисадмина и так далее.
Этот термин обозначает резервное копирование данных. Она создается для того, чтобы восстановить все файлы в случае их повреждения или потери. Это может произойти после физической неисправности оборудования, вирусной атаки, ошибки сисадмина и так далее.
Главная цель создания бэкапа – сохранность данных и возможность их воссоздания в случае непредвиденных ситуаций.
Backup files создаются при помощи копирования данных на сторонний носитель. Чаще всего для размещения копии выбирается физический сервер или облачное хранилище. Лучше всего – если они будут располагаться на другом оборудовании или даже в другом дата-центре. Бэкап можно создать для любых данных: файлов (например, тех же изображений), паролей, ключей доступа, баз данных, системных папок, исходного кода и т. д. То есть, практически любая информация ИТ-инфраструктуры.
Первые бэкапы стали делать десятки лет назад, однако тогда копии файлов размещались на дисках и других физических носителях. Сегодняшние технологии позволяют перенести все данные в облачные хранилища.
Существует несколько вариантов бэкапов:
Недостатком последних двух способов является то, что в случае повреждения первоначальной копии, восстановить данные будет невозможно. Поэтому чаще всего используются все варианты резервирования, но с различной периодичностью. Например, раз в месяц делается полный бэкап, раз в неделю – инкрементный.
Так же к числу видов бэкапа можно отнести и частичное резервирование. В этом случае создаются копии файлов определенного типа. Например, ключи доступа.
Необходимые данные для резервирования и частоту их обновления каждый должен определять самостоятельно. Но стоит помнить, что backup требует определенных ресурсов: это и сетевой трафик, и вычислительные мощности, и дисковое пространство. Стоит заранее продумать, как часто потребуется создавать копию и насколько критичным будет отказ от частого резервирования.
Подробнее о snapshot
 Snapshot (снэпшот или снапшот) – это термин, который означает «заморозку» имеющихся данных и состояния системы. Свое название он получил от английского слова, которое в переводе обозначает «снимок».
Snapshot (снэпшот или снапшот) – это термин, который означает «заморозку» имеющихся данных и состояния системы. Свое название он получил от английского слова, которое в переводе обозначает «снимок».
Главная цель использования снэпшотов – упрощение отката системы к более раннему состоянию. Чаще всего такой инструмент используется при работе с виртуальными серверами. Многие системы виртуализации разрешают создание «снимков» и всего за пару действий производят откат к предыдущему состоянию.
Такое резервирование удобно делать перед установкой обновлений ПО или тестированием новых приложений. При появлении любых неисправностей в работе системы достаточно будет вернуться к определенному моменту в прошлом.
При использовании «моментального снимка» исходные данные сохраняются в виде файла, который не допускает изменений. Любые новые операции записываются в новые файлы. Если сравнивать с бэкапом, то снапшоты напоминают инкрементальные копии. Во время их использования также создается последовательность копий, которая отражает систему на определенных этапах.
Снапшоты обычно располагаются вместе с исходными данными, что увеличивает скорость быстродействия. То есть, в отличие от бэкапов, они не потребуют отдельного хранилища. Снимки сохраняют копию всей системы или только отдельных компонентов. И кстати, снапшот делается даже с выключенным компьютером (что невозможно при стандартном резервировании файлов).
Впрочем, есть и свои недостатки. Например, если на сервере выполняется множество дисковых операций, то размер файлов с изменениями быстро увеличится и превысит размер «замороженных» дисков. Одновременно произойдет замедление всех дисковых операций, что скажется на работе системы.
Когда использовать
Теперь обсудим, когда потребуется использовать бэкап, а когда – можно обойтись snapshots.
Резервное копирование помогает обезопасить файлы и сохранить их на длительный срок, их можно воссоздать в случае повреждения или утраты носителя, а также при сбое системы. Лучше всего бэкапы подходят для следующих целей:
Смысл снапшотов не в их надежности, а в мгновенном восстановлении предыдущего состояния системы. Бэкапы обычно хранят на другом сервере, чтобы избежать потери всех копий сразу, а моментальные снимки – должны располагаться как можно ближе, чтобы восстановление данных происходило практически мгновенно.
Использование snapshot рекомендовано в следующих случаях:
Сравним возможности инструментов:
| Задача | Снапшот | Бэкап |
|---|---|---|
| Эксперименты с ПО и возможность отката в предыдущее состояние | + | – |
| Восстановление работоспособности системы после сбоя | – | + |
| Сохранение копии данных на случай потери основного хранилища | – | + |
| Архивирование на долгий срок | – | + |
По сути бэкапы и снэпшоты используются для разных целей: одни служат для надежности, другие – для гибкости. Поэтому все чаще инструменты применяются совместно. Такой подход является наиболее рациональным, так как помогает обезопасить все данные и избежать проблем с восстановлением.
Надеемся, что вы разобрались в том, что такое snapshot и backup и какая разница существует между инструментами. Советуем не пренебрегать их использованием, так как они помогут избежать потери данных и восстановить информацию даже в случае серьезных сбоев.
Специалисты Xelent всегда готовы помочь с настройкой резервирования вашей системы и подобрать дополнительные решения для сохранности ваших данных. Если у вас остались вопросы, задайте их при помощи формы на нашем сайте!
Snapshot и Backup: в чем разница?
Рано или поздно все мы сталкиваемся с таким неприятным явлением, как потеря данных. Причины могут быть разными — от выхода из строя оборудования до сбоя программного обеспечения. Последствия потери данных могут быть тоже самыми разными — от потери времени до потери огромных средств. Для предотвращения потерь данных платформа xelent.cloud предоставляет два инструмента: Snapshot и Backup. В этой статье мы разберемся, в чем между ними разница.
Резервное копирование
Инструмент резервного копирования (backup) в своей классической интерпретации известен всем. Администратор может настроить резервное копирование файлов, папок, всей операционной системы и даже целых дисковых томов (поблочно).
В случае необходимости из созданной резервной копии можно восстановить данные, операционную систему или даже весь диск.
Цели резервного копирования могут быть самыми разными, например, простое архивирование данных на случай их использования в будущем, создание бэкапа для восстановления данных в случае их повреждения или утери, для восстановления операционной системы и приложений.
Нужно понимать, что данные постоянно меняются и созданная резервная копия устаревает сразу же после ее создания. Скажем так, пусть в 7:00:00 вы инициировали создание резервной копии и в 7:30:00 она была создана. Если вы в 7:30:01 инициируете восстановление данных, то есть огромная вероятность, что система после восстановления в 8:00:00 все равно не будет такой, какой она была в 7:30:00 — на момент создания резервной копии. В некоторых случаях это не важно, поскольку нужно восстановить только содержимое файлов данных. В некоторых случаях — очень важно, поскольку будут потеряны все данные с момента создания резервной копии. Все просто: пусть вы создали резервную копию файла в 7:00, а в 17:00 случайно удалил этот файл. Вы можете его восстановить, но только по состоянию на 7:00 — все изменения за 10 часов работы будут утеряны.
Делать резервное копирование слишком часто — тоже не выход, поскольку создание резервной копии требует вычислительной мощности, занимает дисковое пространство и забивает сетевой канал (нет смысла делать локальную резервную копию, бэкап нужно хранить на другой машине, поэтому при создании бэкапа генерируется сетевой трафик).
Резервное копирование может быть полным и инкрементным. Инкрементное используется для экономии ресурсов. При инкрементном резервном копировании копируются не все данные, а только измененные. Восстановить оригинал при использовании инкрементного копирования возможно только при наличии всей цепочки копий.
При полном резервном копировании сохраняются все данные, но при этом требуется больше дискового пространства для хранения бэкапа и времени — на его создание.
Платформа xelent.cloud предоставляет возможность резервного копирования. Для включения бэкапа нужно перейти в раздел Backup панели управления виртуальным сервером и нажать кнопку Включить. После включения резервного копирования каждый день будет создаваться полная резервная копия всех данных сервера. Резервное копирование выполняется 1 раз в сутки на территориально удаленный дисковый массив.

Рис. 1. Включение резервного копирования виртуального сервера
Снапшоты в Kubernetes: что это и как ими пользоваться
С появлением snapshot-controller в Kubernetes появилась возможность создавать снапшоты для совместимых с ними CSI-драйверов и облачных провайдеров.

Как и всё в Kubernetes, имплементация API является универсальной и не зависит от какого-либо вендора, что позволяет нам рассмотреть данный функционал в общем порядке. Как же устроены снапшоты и какую пользу они могут принести пользователям Kubernetes?
Введение
Для начала давайте разберёмся, что такое снапшоты. Снапшот — это возможность сделать моментальный снимок состояния файловой системы для последующего сохранения или восстановления из него. Создание снапшота занимает крайне малое время. После создания снапшота все изменения в оригинальной файловой системе начинают записываться в отдельные блоки.
Так как данные снапшота хранятся в том же хранилище, что и оригинальные данные, снапшоты не заменяют полноценный бэкап, но снятие бэкапа из снапшота, а не из живых данных, позволяет сделать его более консистентным. Обусловлено это тем, что при создании снапшота мы можем гарантировать актуальность всех данных на тот момент, когда этот снапшот был сделан.
Для того, чтобы возможность создания снапшотов заработала, в Kubernetes-кластере должен быть установлен snapshot-controller (общий компонент для всех CSI-драйверов), а также соответствующие CRD:
Помимо этого, наш CSI-драйвер должен иметь соответствующий контроллер csi-snapshotter и поддерживать создание снапшотов.
Как работают снапшоты в Kuberbetes?
Логика простая. У нас есть несколько сущностей, в VolumeSnapshotClass описываются параметры для создания снапшотов. В первую очередь это используемый CSI-драйвер, а также там можно указать дополнительные настройки, например, должны ли снапшоты быть инкрементальными и где они должны храниться.
Когда CSI-драйвер успешно выполняет процедуру создания снапшота, он создаёт в кластере ресурс, который называется VolumeSnapshotContent и указывает данные созданного снапшота в нём (как правило, его ID).
Конфигурация
Кейс 1: Темплейты PVC

В первом кейсе представим, что мы хотим иметь некоторый шаблон PVC с данными и клонировать его по мере необходимости. Это бывает удобно в следующих случаях:
Вся магия заключается в том, что создаётся стандартный PVC, заполняется нужными данными, а когда нам потребуется его склонировать, создаём ещё один PVC, где в качестве источника указываем оригинальный:
В итоге получаем клон с данными из оригинального PVC, которые можем сразу использовать. Механизм снапшотов здесь работает абсолютно прозрачно, именно поэтому нам даже не пришлось использовать какой-либо из описанных выше ресурсов.
Кейс 2: Снапшоты для тестирования

Этот кейс демонстрирует, как можно безопасно протестировать миграцию БД на живых данных, не затрагивая production.
Мы точно так же создаём клон уже существующего PVC, с которым работает наше приложение, и запускаем новую версию приложения уже со склонированным PVC, чтобы протестировать обновление. В процессе можно обнаружить, что что-то пошло не так, создать новый клон и попробовать ещё раз.
После обновления, если возникнет такая необходимость, всегда можно вернуться к этому состоянию, указав снапшот в качестве источника для создания PVC:
Кейс 3: Снапшоты для консистентного бэкапа

Снапшоты являются неотъемлемой частью для создания консистентных бэкапов в работающем окружении. Без снапшотов априори не получится создать такой бэкап PVC без приостановки работы приложения.
Причина заключается в том, что при снятии бэкапа всего тома с работающего приложения велика вероятность перезаписи отдельных частей этого тома. Чтобы этого избежать, можно сделать снапшот и бэкапить уже его.
Есть различные решения, которые позволяют бэкапить в Kubernetes, учитывая логику вашего приложения и/или используя механизм снапшотов. Одно из таких решений — Velero — позволяет автоматизировать использование снапшотов, назначать дополнительные хуки для сброса данных на диск, а также приостанавливать и возобновлять работу приложения для лучшей консистентности бэкапа.
Тем не менее, некоторые вендоры имеют встроенный функционал для создания бэкапов. Так, например, LINSTOR позволяет автоматически отправлять снапшоты на удалённый S3-сервер. Поддерживаются как полные, так и инкрементальные бэкапы.
Теперь при создании снапшота он будет отправлен на удалённый S3-сервер:
Теперь можно создать новый PVC из бэкапа:
Модуль снапшотов в Deckhouse
Недавно мы внедрили модуль снапшотов для совместимых CSI-драйверов в нашу Kubernetes-платформу Deckhouse. Начиная с релиза v1.33 он включается автоматически для всех поддерживаемых облачных провайдеров и систем хранения, не требуя настройки.
В документации можно найти больше примеров использования.
Заключение
Снапшоты позволяют более эффективно использовать возможности вашего хранилища, позволяя создавать консистентные бэкапы, клонировать тома, а также избежать необходимости полного копирования ваших данных в случаях, когда это в действительности не требуется.
Спасибо за внимание — надеюсь, со снапшотами ваша жизнь станет проще и лучше! 🙂
Снапшоты для виртуальных машин в облаке
Summary: Пост рассказывает о том, что такое снапшоты в облаке, как их использовать, и как они устроены.
Одна из самых заметных новых фич в облаке, появившаяся в этом году — снапшоты. Всё, что мы делаем, делится на три категории — то, что полезно нам (биллинг, сервисные утилиты и т. д.), то, что полезно клиентам, но визуально не заметно (например, СХД, смена версий гипервизора, уже ранее запущенных серверов), и то, что полезно клиентам и визуально заметно — и вот снапшоты как раз из этой третьей категории).
Хочу предупредить, что статья будет очень сложная. Я сначала расскажу про простые вещи — как с этим работать и какая от этого польза, а потом расскажу как это устроено внутри. И если с удобством и понятностью на «пользовательском» уровне мы, я надеюсь, справились, то вот с описанием устройства… Так сказать, мужайтесь или пропускайте.
Как использовать снапшоты?
Самым типовым применением снапшотов является создание резервных копий на случай ошибки в настройке машины. Сразу хочу предупредить, это важно: снапшоты хранятся там же, где и диски. Это означает, что если на нас упадёт метеорит или придёт другое стихийное бедствие федерального значения, то снапшоты будут утеряны одновременно с дисками, то есть для полноценных резервных копий следует использовать другое, географически от нас удалённое, место хранения. Мы совершенно не планируем терять диски клиентов или допускать стихийные бедствия в серверную, но предупредить я всё-таки обязан. 
Снапшот может быть выполнен в любой момент времени, на включенной или выключенной машине. В момент выполнения снапшотов дисковая активность машины слегка приостанавливается (речь идёт о чём-то порядка секунды), после чего продолжается «как ни в чём ни бывало». Методов сделать снапшот два: в свойствах диска на странице с виртуальными машинами (там же есть кнопка «откатиться на предыдущий снапшот») и в списке снапшотов на странице с дисками. Там же есть список всех снапшотов диска. Заметим, для виртуальной машины мы обычно не даём возможности создать снапшот во время установки. Особо пронырли внимательные клиенты могут найти, что кнопка «создать снапшот» на странице дисков всё-таки активна (и работает). Ничего интересного (кроме полу-установившегося линукса) в таком снапшоте не будет, но мы решили не забирать у людей возможность стрелять себе в ногу делать то, что они хотят со своими машинами.
Итак, созданный снапшот содержит в себе копию диска на момент создания. По размеру он чаще всего значительно меньше, чем диск. Если кому-то интересно, как высчитывается размер снапшота — смотрите вторую часть. Снапшоты образуют цепочку (если снапшоты делаются подряд) или дерево (как такое получается — см. раздел про откат на снапшот). Если удалить снапшот, то он начинает «растворяться» — объединяться с соседними (при этом общий объём снапшотов уменьшается). Процесс довольно быстрый (несколько минут — и снапшота нет).
Самой «вкусной» функцией снапшотов лично я считаю возможность подключить снапшот как диск. Подключается он в режиме read only (только для чтения), и позволяет посмотреть на «предыдущее» состояние диска. Никто не мешает сделать у диска 10 снапшотов и подключить все 10 к одной и той же машине — в этом случае диски будут представлять из себя хронологию «основного» диска.
Более того, снапшот можно подключать к любому количеству машин одновременно. (Сразу отвечаю на вопрос — можно ли грузиться с снапшота — формально, да, фактически файловая система очень нервничает от read only на root’е — мы работаем над этим вопросом).
Второй по важности функцией является откат диска на снапшот, то есть восстановление состояния диска. При этом изменения теряются, так что лучше перед откатом на старый снапшот сделать новый. В этом случае диск можно будет «переключать» между снапшотами (откатывать туда/обратно). У процесса отката на снапшот есть некоторые мелкие неудобства — становится недоступна статистика по дисковым операциям и неправильно показывается потребление машины в прошлом. Общее потребление по акаунту при этом высчитывается правильно, но так как образовывается новый VBD (блочное устройство), то данные для VM показываются для нового VBD. (Мы знаем про эту не очень очевидную особенность нашего биллинга и планируем его поменять на более удобную в обозримом времени).
Для удобства использования в последние несколько дней перед анонсом мы добавили «последний штрих» — если диск откатывается из снапшота, то у него появляется поле reverted_at (то есть «восстановлен из снапшота»). Мелочь, но полезная. Это поле будет преследовать диск до самой его смерти (и после, хе-хе, мы данные об объектах не удаляем).
Важный момент: каждый раз, когда делается или откатывается снапшот, наблюдается синдром «COW» (copy-on-write) — первая запись будет медленнее последующих. Так что на очень нагруженных серверах с большим количеством записи с созданию снапшотов следует относиться аккуратно.
Если сделать у диска несколько снапшотов, потом откатить диск на снапшот в «середине», потом сделать несколько снапшотов, потом откатить его на другой снапшот, потом снова откатить его, то образуется дерево снапшотов. Мы храним в нашей БД отношения — какой снапшот чьим является. К сожалению, визуализация пока в работе (программисты сильно протестуют, получив задачу «нарисовать дерево на JS», и пусть им будет стыдно при чтении этого поста).
Лимиты. К сожалению, вся эта роскошь не безгранична. Наши ограничения: длина цепочки снапшотов не более 20 дисков, максимальное количество снапшотов в дереве (с учётом ветвлений) — не более 60 шт. По нашим оценкам этого более чем достаточно для нормальной работы.
На странице «дисков» у каждого диска есть вкладка «снапшоты», где приводится список всех снапшотов диска. Снапшоты можно называть и давать им многострочное описание (но все ленивые, да, я тоже люблю, когда эти поля заполнены, но заполнять их обычно очень лень). В любом случае снапшот может быть уникально идентифицирован по абсолютно бесполезному номеру (англ. universally useless ID, uuid) и (частично) по дате создания.

Немного о поле «итого». В силу некоторых особенностей работы системы информация о снапшотах обновляется неравномерно — список снапшотов обновляется сразу после создания снапшотов, а вот поле «итого» может запаздывать некоторое время — до двух минут. В отличие от остальных ресурсов, которые мы обсчитываем в реальном времени, диски и снапшоты учитываются с (примерно) двухминутным интервалом. Поле «итого» высчитывается в момент вычисления объёма потребления, так что «итого» сразу после создания снапшота будет некорректным (но точно придёт в норму к следующему тику списания).
Как это устроено?
(просьба убрать от экранов несовершеннолетних детей и лиц с повышенной восприимчивостью, сейчас будет хардкор).
Наши снапшоты (как и диски) основываются на VHD-формате, который был придуман microsoft, отдан в публичное пользование и использован citrix. Он поддерживает очень эффективные снапшоты (они много эффективнее, чем снапшоты LVM, которые увеличивают количество записей пропорционально числу снапшотов). Когда выстраивается цепочка снапшотов, там неявным образом подразумевается «нулевой» снапшот, относительно которого фиксируются изменения всех остальных (без этого «нулевого» снапшота становится не понятно — что за «изменения» хранятся в первом снапшоте). Нулевой снапшот, разумеется, не оплачивается (т.к. физически места на диске не занимает).
При записи в «дырявый» блок этот блок копируется из «старого» снапшота в текущий диск (та часть, которую записали, заменяется, остальное берётся в предыдущей копии). После записи в текущем диске становится на одну дырку меньше и чтение этого места в дальнейшем идёт с «текущего» диска. Дисковые операции для дисков с снапшотами стоят столько же, сколько и обычные дисковые операции (лично я не уверен, насколько операции над снапшотами оказываются тяжелее обычных для наших СХД, так что решили эту область не трогать).
Что происходит при создании снапшота? (Техническая часть).

Текущий диск объявляется так называемым ‘base copy’, то есть read only копией состояния машины. Так как у диска могли быть предшественники в цепочке снапшотов, то base copy ссылается на другие base copy (заметим, base copy всегда ссылается только на base copy). Кроме этого делается ещё «снапшот» — это read/write копия текущего состояния (то есть отличия снапшота от base copy). В общем случае в снапшоты можно писать, но мы это запрещаем, так как в этом случае получится thin provision, а мы не можем его допустить из соображений гарантированности зарезервированного пространства (см раздел ниже). Но даже «незаписанный» снапшот содержит в себе 8Мб мета-данных. Таким образом, каждый снапшот состоит из двух половинок: метаданных (8Мб) и содержимого base copy. Диск ссылается одним видом ссылок на base copy предыдущего снапшота, а вторым видом ссылок на «снапшот». Когда происходит откат диска, то снапшот клонируется (не копируется — отсюда и нюансы с COW), ссылаясь на тот же самый base copy, на который ссылался снапшот, который был клонирован.
Если же кто-то два-три раза подряд сделает снапшот (без изменений данных), то получится одна base copy и три снапшота с мета-данными.
Когда снапшот удаляется (из середины), то происходит следующее: сам снапшот (метаданные) удаляется сразу, а вот base copy начинает расформировываться — данные переносятся либо в «предыдущее» состояние, либо в «будущее», либо вообще выкидываются (если есть альтернативное состояние и в прошлом, и в будущем). Этот процесс и есть «таяние» снапшота, которое происходит не мгновенно. Нужно сказать, что данные фактически не копируются, а всего лишь «перемаркируются» в рамках LVM (LE перекидываются между разными LV), либо удаляются (если в предыдущей копии есть другая версия блока).
Немного о thin provision
Один из вопросов, который нам задают по СХД, связан с thin provision. Что такое thin provision? Это когда потребителю декларируется некоторый объём места, а реально занятое место меньше — и увеличивается по мере фактической записи. Это отлично ложится на нашу модель с снапшотами, COW из «пустого места», да и в XCP реализовано отлично. Фактически, thin provision — это «запись в снапшот», то есть запись в «пустое место», которое от этого начинает занимать место в реальности.
Однако, thin provision опасен. Обратная сторона thin provision — overselling (он же oversubscription). Грубо говоря, есть у нас 100Тб места. Мы разрешили создать на таком хранилище 200 дисков по 1Тб. Фактический размер дисков в начале — гигабайт по 30-50, так что свободного места вволю. Но, вдруг, клиенты начинают писать на диски. Диски-то им уже выделены. Проходит немного времени, и… да, среднее заполнение дисков подползает к 500Гб. А потом… Потом кто-то хочет записать очередной гигабайт, но получает ошибку. Потому что место закончилось.
Мы не властны над дисками клиентов, и если мы им предоставили ресурсы — эти ресурсы их, и не наше дело говорить «сейчас можно, а сейчас нет». Если в отношении других ресурсов может быть компромисс (кому-то 3% процессора не дали, кого-то мигрировали на другой хост, чтобы обеспечить запас производительности), то есть незначительная «недопоставка» просто не ощутима, то в отношении дискового пространства такое не получится. Не дали записать хотя бы один сектор — по всему блочному устройству фиксируется ошибка.
Так что по здравому размышлению мы решили так не делать.
Из-за того, что снапшоты делаются в R/O, а после создания только уменьшаются, мы можем отказать в создании нового снапшота (всякое бывает — может и место внезапно кончиться), но мы точно не откажем в работе уже созданных дисков и снапшотов.
Snapshots — «фото на память (дисковую;)»

Всегда странно представлять себе времена, когда чего-то не было. Сложно сегодня представить себе, как мы жили без персональных компьютеров, без интернета, без торрентов, mp3, или без электрокопировальных аппаратов, в просторечии «ксероксов». Тем не менее всегда были времена, когда что-то привычное нам еще не существовало. Также обстояло дело и с понятием «снэпшота данных». Но сперва — что же такое «снэпшот»?
«Снэпшот» (дословно — «фотография», «моментальный снимок», здесь и далее под этим словом мы будем понимать конкретно, не уточняя, «снэпшот данных») это моментальная копия состояния данных в системе хранения, или программе, зафиксированная на определенный момент времени. Это может быть моментальное состояние содержимого файла, базы данных, или файловой системы (как частного случая «базы данных»).
В применении к системам хранения данных этот термин появился вместе с первыми системами хранения NetApp и был, на тот момент первой и главной их «фичей».
Ранее я уже рассказывал о внутренней файловой структуре WAFL, придуманной основателями NetApp для своего продукта, и о том, каким образом она работает. Интересующихся техническими деталями отошлю к прекрасной авторской публикации, которая сейчас переведена на русский язык. Именно эта, несколько необычная, на первый взгляд, по принципам работы, файловая структура сделала возможной реализацию концепции снэпшотов — мгновенных копий состояния данных, хранимых на дисках такой системы.
Как я уже рассказывал в статье про WAFL, основной принцип ее работы состоит в том, что однажды записанные на диск данные, в дальнейшем, не изменяются. Данные (например файл) можно на WAFL либо записать (целиком), либо стереть (целиком). В случае же необходимости изменения его содержимого эти изменения «дописываются» в свободное место дискового пространства, после чего на блоки с записанным содержимым изменений переставляется указатель содержимого файла (старый блок содержимого помечается как свободный, или не помечается, если на него ссылается более одного файла, или он использован в снэпшоте). Следовательно, для того, чтобы сохранить текущее состояние данных, при таком алгоритме работы записи, все что нам нужно, это сохранить «корневой inode» на данный момент времени.

Inode, напомню, это блок данных, определяющий содержимое файла. Он может ссылаться либо прямо на конкретные блоки, либо, для больших файлов, на промежуточные inodes, образуя «дерево» от «корня», единственного на всю файловую систему тома, так называемого «корневого» inode.
Таким образом, создав копию ровно одного блока, корневого inode данной файловой системы, мы получим, обратившись к нему, вместо текущего «корня», «псевдо-файловую систему», хранящую без изменений (read-only) все данные на момент времени, когда мы скопировали этот inode. Ведь, как вы помните, однажды записанные блоки данных файлов в дальнейшем не изменяются.

Каким же образом это выглядит на практике?
Для упрощения рассказа я буду рассматривать NAS-вариант работы NetApp, хотя, как вы знаете, аналогичным образом тот же самый сторадж может работать и как SAN-устройство.
Каждый том на системе хранения NetApp является отдельной файловой системой. На каждой файловой системе можно создать до 254 снэпшотов ее состояния, по методике, описанной выше.
Все созданные снэпшоты автоматически доступны через директорию /.snapshot (или /
snapshot) в корне тома. Зайдя туда, мы увидим имена созданных снэпшотов (они могут носить либо «собственное имя», например «/lets_fix_this_small_bug…oh_shit. «, будучи созданными вручную, либо, если создаются по расписанию, будут располагаться в поддиректориях hourly.0(1,2,3…), daily.0(1,2,3) и так далее.

Войдя в такую папку мы увидим полностью все содержимое нашего тома, со всеми файлами в нем, причем все файлы будут доступны на чтение, и читаться из них будет все то содержимое, которое было в них на момент взятия снэпшота.

Причем это даже выглядит несколько странно, на первый взгляд.
Допустим, что у вас есть том, размером 1TB, на котором лежит файл базы данных, размером 750GB. Для этого тома вы создаете снэпшоты каждый час по расписанию. Войдя в /.snapshot вы увидите в ней поддиректории /hourly.0, /hourly.1, и так далее, причем в каждой из них будет лежать «файл размером 750GB». При этом на собственно томе, емкостью 1TB, на котором как бы и лежат эти 24 (каждый час) копии базы по 750 гиг размером каждая, еще будет гигабайт 200 свободного места.
При этом любой из этих 24 «файлов» мы можем скопировать в резервную копию на внешнее хранилище, смонтировать как независимый read-only и использовать (читать) эти данные, как если бы это была реальная база данных, восстановить из нее данные, скопировав ее на место «активной», например в случае «все сломали, надо откатится на состояние час назад», и так далее.
Где же все это хранится?
Дело в том, что все эти «файлы», это просто ссылки на одни и те же блоки неизмененных данных. Место же на диске занимают только изменения, между снятыми снэпшотами. Допустим, что за сутки мы наменяли в этой базе блоков на 50 гигабайт. Тогда занятое место на дисках, в томе размером 1TB, на котором лежит файл базы на 750GB, и снэпшоты каждый час, будет 1TB — 750GB файл — 50GB изменений = 200GB свободно.
Если изменений за час между двумя снэпшотами (hourly.0 и hourly.1) получилось на 1% объема базы, то hourly.1 займет 7,5GB места на диске, указывая своими inodes на измененные, по сравнению с предыдущим снэпшотом, блоки. Все же остальные inodes по прежнему будут ссылаться на прежние, неизмененные блоки.
Чем удобно использование снэпшотов?
Простейший пример я уже привел. Допустим мы, или наши пользователи, «все сломали». Это может быть база данных, или же, допустим, экселевский файл, в котором, случайно, грохнули не те данные, успели записать, а потом обнаружили это, а восстановить надо срочно, «или нас всех убьют». Но мы знаем, что час (два, три, сутки, неделю, месяц назад, все зависит от частоты и регулярности снэпшотов) нужный нам файл был исправен.
Мы (это может сделать, кстати, даже сам пользователь) просто заходим в папку /.snapshots и вытаскиваем оттуда простым копированием нужный нам файл, на нужный момент времени, час, два, сутки, и так далее назад.
Либо, если у нас есть специальная лицензия SnapRestore, одной командой из консоли стораджа, «откатываем» состояние тома на нужный момент времени целиком (что удобно, если нужно восстановить не отдельный одиночный файл, а содержимое всего тома, в целом).
Таким образом, снэпшоты это, для пользователя, очень оперативная резервная копия, доступная тут же, на этом же сторадже. Кстати, в случае использования Windows XP или 7, вы будете видеть файлы в снэпшоте в панели «Previous versions» свойства файла или папки, NetApp интегрируется в этот механизм Windows как VSS-provider.

Теперь рассмотрим более сложный вариант. Допустим, мы эксплуатируем большую, ответственную, mission-critical SQL-базу данных предприятия.
Разумеется, каждый вечер, эта база данных бэкапится на ленту, для создания резервной копии.
База большая, и резервная копия копируется на ленту примерно час.
«Ничто не предвещало беды», но однажды, посреди рабочего дня, допустим в 3 часа дня, база необратимо портится.
Какие действия предпринимает сисадмин, для того, чтобы базу восстановить?
Мы считываем резервную копию по состоянию на конец прошлого рабочего дня (читаться она будет, допустим, столько же, сколько писалась — час), а затем нам следует «накатить» на нее redo-log-и, от момента создания бэкапа, вечером, и до момента, предшествующего сбою, то есть до 3 часов следующего дня. Этот «накат» часто довольно объемен, и также занимает какое-то время, ведь операции в SQL происходят не мгновенно. Допустим, через 30 минут, после окончания считывания бэкапа, база восстановлена в рабочем состоянии на момент предшествующий сбою, и мы готовы продолжать работу. Итого — 1:30.
В случае использования снэпшотов дела будут происходить следующим образом. У нас также делается ежедневная копия на ленту для обеспечения безопасности хранения, например на случай полного выхода из строя системы хранения, но у нас хранилище живо, повреждены только данные на нем. Мы знаем, что час назад база была жива и здорова. Мы восстанавливаем базу по состоянию на 2 часа дня, и так как снэпшот создается и восстанавливается практически мгновенно, то это занимает не час, а всего несколько секунд, и накатываем на нее redo-logs, но не со вчерашнего вечера, как в предыдущем случае, а всего за один час, с 2 часов, то есть момента создания снэпшота, до момента аварии, в 3 часа дня. Это занимает также не полчаса, а всего несколько минут.
Итог: спустя несколько минут, а не полтора часа, как обычно, наша база вновь в рабочем состоянии.
Очевидные преимущества использования снэпшотов привели к тому, что, на сегодня, практически все производители систем хранения предлагают для своих систем ту или иную реализацию «снэпшотов» как идеи.
Однако, как мы помним, «не все йогурты одинаково полезны».
В чем же принципиальное отличие «настоящих снэпшотов» (Название Snapshots ™ для систем хранения это зарегистрированная торговая марка NetApp) от всех остальных, «контрафактных копий». 😉
Принципиальное отличие, позволяющее реализовать снэпшоты так, как это было описано мной выше — устройство WAFL, которое, как я уже рассказывал, не позволяет изменять уже записанные данные. Такая модель позволяет реализовать снэпшоты легко и просто. Но все обстоит хуже, если структура записи традиционна. При этом нам придется сперва, до начала использования, выделить зарезервированное пространство блоков, заранее отняв его у данных, затем, при каждом изменении блока на диске, копировать его содержимое в специальный зарезервированный пул, затем изменять его содержимое на его прежнем месте, затем изменять метаданные, указывающие на старое содержимое, для снэпшота.
Эта технология носит название Copy-on-Write (COW), и широко применяется в системах хранения других производителей, в их реализации снэпшотов.
Как вы видите из описания выше, даже само наличие включенного механизма снэпшотов для тома превращает одну операцию записи для системы хранения в три (чтение исходного содержимого, запись исходного содержимого на новое место, запись измененного содержимого на старое место).
Результат не заставляет себя ждать. Использование COW-snapshots резко ухудшает производительность системы хранения его использующего. Это разительный контраст с системами NetApp, в которых снэпшоты вообще никак не влияют на производительность, ведь никакого копирования при записи в них не происходит, все данные остаются на своих местах.
(демонстрация результатов производительности на тесте SPC-1)

Следствием такого неприятного поведения при использовании COW-snapshots является рекомендация вендоров свести использование таких «неправильных снэпшотов» к минимуму, или не использовать их вовсе на primary-системах, предъявляющих повышенные требования к производительности.
Однако системы NetApp такой проблемой не страдают и никаких ограничений на использование снэпшотов не предъявляют.
Кроме этого, часто (по той же причине) общее количество снэпшотов на таких системах ограничено всего парой десятков максимум, отмечу, для контраста, что на системах NetApp можно использовать до 254 снэпшотов на каждый том, что, при общем количестве томов, допустимых систему, равного 500, достигает теоретического максимума в 127 тысяч.
Это позволяет, при использовании классической «ротации» резервных копий, хранить в 254 снэпшотах резервные копии данных тома до года включительно.
Также немаловажной является возможность создавать «по настоящему мгновенные» копии данных, причем независимо от размера «копируемых» данных. Хоть базу на 100MB, хоть на 100TB, снэпшот с нее будет всегда создан мгновенно. Например, мы можем создать «резервную копию» не «за час», а «за секунду», а затем, уже не нагружая нашей задачей реальную боевую базу, потихоньку копировать на резервное хранилище содержимое такого снэпшота.
Практика показывает, что люди, попробовавшие простоту и удобство использования снэпшотов, очень скоро уже просто не представляют себе жизни без них, считая это «само собой разумеющейся» возможностью любой системы хранения. Попробуйте и вы.
Напомню, что взять на тестирование систему хранения NetApp можно у любого партнера, список которых можно посмотреть на российской странице вебсайта NetApp.
www.netapp.com/ru/how-to-buy/resellers/distributor-ru.html
www.netapp.com/ru/how-to-buy/resellers/platinum-ru.html
www.netapp.com/ru/how-to-buy/resellers/gold-ru.html
PS: На традиционном «фото для привлечения внимания» в заголовке — задняя часть контроллера самой младшей модели NetApp — FAS2020. Самой младшей, но, тем не менее, обладающей всеми возможностями хранилищ NetApp, в том числе и работой со снэпшотами.
На фото, слева направо — два порта FC 4Gb/s, порт последовательной консоли, порт out-of-band микроконтроллера удаленного администрирования, и два порта Gigabit Ethernet.
PPS: А еще можно было бы написать на этой неделе про 5 место NetApp в Fortune’s list Best Plaсes to Work, вон Intel стррашно гордится аж 51-м местом (из ста), но мне показалось, что все эти радости пиар-отдела Хабру не очень интересны, поэтому упомяну об этом «бегущей строкой» в самом конце. Да, пятое место в сотне лучших работодателей США, и пятнадцатое (выше Google (30) и Apple (20), кстати) по списку сайта Glassdoor, оценивающего компании не «снаружи», как Fortune, а изнутри, анонимными голосами самих работников. «Пустячок, а приятно».
Моментальный снимок | Snapshot
Дата публикации: 1 июня 2020 г.

Моментальный снимок (Snapshot) – это копия диска (тома/раздела) на уровне блоков физических или виртуальных систем, выполненная без остановки системных служб, включает в себя структуру папок, файлов и информацию о состоянии системы на фиксированный момент времени. Snapshot не является резервной копией, применяется/используется как временный источник для создания согласованных резервных копий. Snapshots применяют в резервном копировании баз данных или файловых систем большого объема, работающих в непрерывном режиме 24 на 7.
Плюсы /преимущества моментальных снимков (snapshots)
Минусы / недостатки моментальных снимков (snapshots)
СОЗДАНИЕ МОМЕНТАЛЬНЫХ СНИМКОВ (CREATE SNAPSHOT)
В зависимости от источника хранения данных (файловая система, менеджер дисков/томов или дисковый массив) для создания моментальных снимков применяют алгоритмы «Копирования при записи» (Copy-on-write) или «Перенаправления при записи» (Redirect-on-write), другое название «Зеркальный снимок».
Процесс создания моментальных снимков файловой системы состоит из следующих этапов:
В процессе создания снапшота важную роль играет поставщик моментальных снимков (Snapshots Provider). В зависимости от инициатора, поставщиков делят на Hardware и Software Provider.
SNAPSHOT PROVIDER
Hardware Provider это утилита в составе системы хранения данных, которая выступает инициатором создания снимка от имени поставщик оборудования. Каждый поставщик систем хранения данных имеет свой уникальный Hardware Provider (NetApp Data ONTAP, HPE RMC, EMC Unisphere и др.). Hardware Provide является посредником между службой теневого копирования томов (VSS) и «железом», работая в связке с сетевым адаптером и контроллером хранения данных. Таким образом, нагрузка по созданию и поддержке теневой копии лежит на системе хранения данных.
В случаи программного снимка (Software Provider) программа-инициатор на системном уровне перехватывает запросы чтения / записи для операций ввода / вывода между файловой системой и менеджером томов.
Так как Software Provider создают теневые копии на уровне операционной системы, это является более универсальным методом в отличие от Hardware Provider.
SNAPSHOT WINDOWS
Snapshot в системах резервного копирования
В Windows роль Software Provider, выполняет встроенная служба теневого копирования VSS (Volume Shadow Copy Service). VSS по умолчанию встроена в систему Windows и отвечает за создание моментальных снимков на уровне файловой системы NTFS, применяя метод «Копирования при записи» (Copy-on-write). VSS используется, как для физических систем, так и для виртуальных машин Hyper-V, включая файлы конфигурации виртуальных машин, состояние системы (system snapshot) и виртуальные жесткие диски (VHD). Как правило, большинство программ/систем резервного копирования используют службу VSS для создания своих резервных копий в Windows.
SNAPSHOT LINUX
В Linux системах роль Software Provider и поставщика моментальных снимков в зависимости от типа файловой системы (EXT, JFS, ReiserFS, XFS, Btrfs), как правило, выполняет служба Logical Volume Manager (LVM) или специальные модули ядра Linux (Samba и др.).
Снэпшоты для Облачных серверов
В этой статье мы подробно расскажем, что такое снапшот сервера, как создавать, разворачивать и удалять снапшоты.
Что такое снэпшот
Снэпшот — мгновенный снимок сервера, который может быть использован как для резервного копирования и последующего восстановления, так и для удобства разворачивания данных на новых серверах.
Стоимость хранения снэпшота — 3 рубля за 1 ГБ в месяц. Скорость создания снэпшота напрямую зависит от объема данных.
Доступно 2 способа создания снэпшотов:
Работа с облачными серверами происходит через панель управления. Перейдите в панель по ссылке или:
На открывшейся странице выберите услугу «Облачные серверы»:
Как сделать снэпшот
Кликните по названию сервера, для которого вы хотите сделать снэпшот. На странице управления сервера нажмите кнопку Создать снэпшот, затем укажите имя снэпшота, способ создания и нажмите Создать:
Как создать снапшот виртуальной машины
Готово, созданный снэпшот появится в разделе Снэпшоты:
Как развернуть снэпшот
Перейдите во вкладку Снэпшоты. Выберите снэпшот, который необходимо развернуть и нажмите иконку возле его названия. Снэпшот можно развернуть на существующий или на новый сервер, для этого выберите соответствующий пункт:
Как развернуть снапшот диска
Готово, снэпшот будет распакован на сервере.
Как удалить снэпшот
Перейдите во вкладку Снэпшоты. Напротив снэпшота, который нужно удалить, нажмите на корзину:
Как удалить снапшот системы
Готово, снэпшот будет удалён и исчезнет из списка.
Облачные серверы нового поколения
Виртуализация KVM, почасовая оплата, резервные копии, готовые шаблоны, 8 доступных ОС на выбор!
Snapshot (computer storage)
Снимок файловой системы или снапшот — моментальный снимок, копия файлов и директорий файловой системы на определённый момент времени.
Содержание
Описание
Создание резервной копии большого объёма данных может занять длительное время. В многозадачных или многопользовательских системах, во время резервного копирования может происходить запись или изменение файлов и папок, что может привести к неверной резервной копии данных. Например, пользователь перемещает файл из директории, которая ещё не была сохранена в бэкап, в директорию которая уже сохранена. Такой файл может вообще не войти в бэкап. Также, файл предназначенный для резервного копирования может записываться в момент его чтения процедурой бэкапа и может быть сохранён в неверной версии.
Одним из методов безопасного создания бэкапа является запрещение записи в данные, которые подлежат резервному копированию, на время создания резервной копии. Ещё одним методов является остановка всех приложений, которые могут изменять эти данные, или блокировка этих приложений форсированным включением режима только для чтения средствами API операционной системы. Эти методы используются в системах низкой доступности (домашние компьютеры, сервера небольших рабочих групп, для которых регулярная недоступность (downtime) позволительна). В системах высокой доступности 24/7 эти методы применять нельзя, так как это может повлечь отказ в обслуживании сервисов.
Для избежания недоступности (downtime), системы высокой доступности могут, вместо прямого резервного копирования сначала создать снапшот-ную, только для чтения, копию информации, заморожённой в определенный момент времени. А затем, позволив приложениям продолжить обновлять данные, создавать бэкап. Большинство реализаций снапшотов эффективны, они создают снапшот за O(1). Другими словами, время и количество операций ввода-вывода необходимое для создания снапшота не увеличивается с ростом объёма данных, в то время, как те же параметры для создания прямого бэкапа пропорциональны размеру сохраняемых данных.
Снапшоты для чтения-записи иногда приводят к ветвлению снапшотов, так как они неявно создают различные версии своих данных. Помимо резервного копирования и восстановления данных, снапшоты часто используются в виртуализации, в различных песочницах и в виртуальном хостинге, благодаря их эффективности в ведении изменений большого набора данных.
Реализация
Управление томами
Некоторые Unix системы (включая HP-UX) обладают менеджером логического раздела, в котором реализована поддержка снапшотов. Эта реализация копии-на-записи на целых блоковых устройствах путем копирования измененных блоков, до того, как они будут перезаписаны, в другое место, сохраняет целостность снапшота на блоковом устройстве. Файловые системы на этом снапшоте могут быть позднее подключены только в режиме чтения. Снапшоты блокового уровня почти всегда менее эффективно используют место, чем снапшоты в файловых системах которые их поддерживают.
Файловые системы
Некоторые файловые системы, такие как WAFL, fossil для Plan 9 from Bell Labs или ODS-5, внутренне отслеживают старые версии файлов и делают снапшоты доступными через специальное пространство имен. Другие, например UFS2, предоставляют для операционной системы API для доступа к своей истории файлов. В Windows XP и Winodws 2003, и через Shadow Copy в Windows Vista. Снапшоты также доступны в NSS (Novell Storage Services) файловой системы для Netware, начиная с версии 4.11, и более новых на Open Enterprise Server (OES).
ZFS имеет гибридную реализацию, которая отслеживает чтение-запись снапшотов на блоковом уровне, но создает разветвленные наборы файлов известные пользовательским приложениям как «клоны».
В базах данных
Спецификация изоляции транзакций. На самом высоком уровне — сериализационном, снапшот создается при старте каждой транзакции. Утилиты для бэкапа большинства популярных SQL баз данных используют эту технологию для создания самосогласованного образа таблицы данных.
Другие приложения
Программная транзакционная память это схема, которая применяет туже концепцию для структуры данных, хранящейся только в оперативной памяти.
Что такое снапшоты виртуальной машины и зачем они нужны.
«Snapshot» переводится с английского, как «выстрел навскидку» или «моментальный фотоснимок». Снапшот – это снимок виртуальной машины (ВМ), слепок её состояния. Для чего нам нужна ВМ? Ну конечно же, прежде всего для того, чтобы ставить различные эксперименты! И, чтобы каждый раз не заниматься мучительным отмыванием ВМ от осколков очередного эксперимента с помощью всяких чистильщиков, можно воспользоваться такой любопытной функцией, как «снимок» и быстро вернуться к исходному состоянию. Но надо уметь это делать, иначе можно угробить ВМ. Далее я буду излагать свои соображения для самой популярной ВМ – VirtualBox.
Немного теории для тех, кто не в курсе.
Снимки образуют цепочку (если снимки делаются подряд) или дерево (если делаются откаты на снимки). Даже если часть из исходных 10Гбайт образа удалить, они сотрутся с точки зрения машины-гостьи, но останутся в файле ВМ до момента снимка.
Итак, текущий образ ВМ складывается из первоначального образа плюс все промежуточные снимки, которые наслаиваются сверху. Если удалить какой-то из снимков, то все состояния после него будут потеряны. Отмена (discard) снимка будет объединять его содержимое с последующим снимком или с текущим состоянием ВМ, если это последний снимок. Восстановление ВМ из снимка влияет на все виртуальные жесткие диски подключенные к вашей ВМ, поскольку данные на диске будут также восстановлены из снимка.
Короче, вы можете создавать снимки, восстанавливать ВМ из снимков и удалять снимки. Несложно, правда? Всего три базовых операции! Однако, учитывайте, что, хотя создание и восстановление снимков выполняется за несколько секунд, удаление снимка может занять несколько минут, поскольку при этом будет копироваться большой объем данных.
Вы можете увидеть все снимки вашей ВМ, выбрав ее в окне менеджера VirtualBox и кликнув на «Снимки» в верхнем правом углу. Пока вы не сделали ни одного снимка, список снимков, естественно, будет пуст, за исключением элемента «Текущее состояние», который символизирует отправную точку жизненного цикла вашей ВМ.
Будем что-нибудь тестировать.
Вообще-то описанным далее способом можно тестировать что угодно. Но пользователи почему-то очень любят тестировать именно браузеры. Идея простая: делаем снимок ВМ без браузеров, устанавливаем очередной браузер, делаем снимок, возвращаемся к исходному состоянию ВМ без браузеров, устанавливаем следующий браузер и т.д. В итоге получаем одну и ту же ВМ, но с разными браузерами. Этим мы, во-первых, исключили влияние браузеров друг на друга, и, во-вторых, избавились от чистки ОС. Поехали!
Первоначальный снимок. Загрузите VirtualBox (VB), выберите ОС, но не запускайте её! Сделайте снимок:

Поименуйте этот снимок, как org. Итак, первоначальное состояние ВМ зафиксировано:

Запустите виртуальную ОС и установите что-нибудь, например, браузер1. Когда он установится, откройте окно ВМ и сделайте новый снимок. Дайте снимку имя и нажмите ОК. Потребуется несколько. секунд, чтобы записать снимок. Почему так мало? Потому что на самом деле новый снимок будет содержать всего лишь разницу по сравнению с оригинальным снимком.

Протестируйте установленный браузер, если хотите. Впрочем, вы это можете сделать и позже, восстановив всё из снимка. Завершите работу виртуальной ОС.
Чтобы начать тестировать следующий браузер, в окне VB изберите обязательно! корневой снапшот (он поименован, как org) и кликните «восстановить снапшот». Иконка «восстановить снапшот» похожа на стрелку на вкладке.

Далее откроется дополнительное окно, предупреждающее, о возможных потерях. Снимите птичку в чекбоксе «сохранить текущее состояние», так как вы его уже сохранили, и жмите «Восстановить». Пройдёт несколько секунд, пока состояние ВМ будет восстанавливаться из корневого снимка. Теперь стартуйте свою ВМ.
Установите следующий браузер2. Когда он установится, откройте окно ВМ и сделайте новый снимок. Дайте снимку имя и нажмите ОК.
Завершите работу ВМ.
Повторяйте шаги 3 и 4 со всеми браузерами, которые желаете протестировать.
Получится линейка снимков, порождённых корневым снимком.

Каждый из снимков в этой линейке – это разница с корневым снимком.
И теперь можете запускать разные состояния ОС с установленными браузерами и тестировать их столько раз, сколько требуется. Надо просто выбрать нужный снимок и начать кнопку «Восстановить». Как только снимок с тестируемым браузером будет загружен, стартуйте свою ВМ и тестируйте выбранный браузер.
Не правда ли просто? Но это далеко не всё, что можно вытворять с помощью снимков ВМ. (Продолжение следует.)
Снапшоты
Снапшот — это копия данных виртуальной машины и всего состояния системы. С его помощью можно вернуться к работоспособному состоянию машины после неудачного обновления, тестирования приложений или других потенциально опасных действий.
Хранятся снапшоты максимально близко к виртуальной машине, поскольку основное их назначение — быстро вернуть ее предыдущее состояние. После использования снапшота рекомендуется его удалить, чтобы не занимать место на диске. Снапшот не предназначен для долгосрочного хранения копий машин, как резервные копии.
Снапшоты — не резервные копии. В отличии от снапшотов, резервные копии хранятся отдельно от VM, чтобы копии не повредились вместе с оригиналами. Их назначение — восстановить данные в случае аварии, непредвиденного события.
Функция создания снапшотов входит в стоимость услуги аренды виртуального ЦОД.
В консоли управления Enterprise хранится только один снапшот для каждой VM. Каждый новый снапшот заменяет предыдущий.
Создание снапшота
Снапшоты не фиксируют сетевые параметры виртуальной машины (NIC).
Рассмотрим создание снапшота для VM.
Найдите нужную VM.
Снапшот для vApp создается аналогично. В этом случае появляются снапшоты всех VM в vApp.
Восстановление из снапшота
Найдите нужную VM.
Восстановление из снапшота для vApp происходит аналогично. В этом случае восстанавливаются все VM в vApp.
Удаление снапшота
В противном случае, размер измененных данных может достичь критических размеров и занять все свободное место на диске, что вызовет проблемы при восстановлении из снапшота, а также может привести к проблемам в работе VM.
Удаленный снапшот нельзя восстановить.
Найдите нужную VM.
Снапшот vApp удаляется аналогично. В этом случае удаляются снапшоты всех VM в vApp.
Использование моментальных снимков (Snapshots) в Hyper-V
Моментальные снимки: сложно о простом
Наверняка многие знакомы с достаточно полезной функцией многих продуктов виртуализации – моментальными снимками, в простонародье – «снапшоты» (snapshots). Снапшот виртуальной машины – это как сохранение в игре: в случае, если где-то сильно накосячил (патч Бармина применил, например) – можно вернуться назад и повторить все заново. В этой статье я попытаюсь более-менее подробно рассказать о работе моментальных снимках и о некоторых нюансах их применения. В статье речь пойдет о Microsoft Hyper-V, но с некоторыми натяжками материал статьи применим и для других систем виртуализации (в частности — VMWare).
Прежде, чем продолжать – вспомним, из каких компонентов состоит виртуальная машина:
Файл конфигурации – основа виртуальной машины, хранит все настройки, касающиеся виртуалки. Представляет собой XML-файл, имеющий, как ни странно, расширение XML. В VirtualPC/Virtual Server этот файл имел расширение VMC.
Файл виртуального диска. Обычно в качестве жесткого диска виртуальные машины используют специальные файлы-образы, имеющие расширение VHD. Этот формат, изначально разработанный фирмой Connectix, после приобретения ее корпорацией Microsoft стал использоваться в продуктах виртуализации, и не только в них: в частности, они используются в Microsoft Software iSCSI Target, а в ОС Windows 7 и Windows Server 2008 R2 с VHD-дисками можно работать на уровне ОС, вплоть до загрузки с них самой операционки.
Дифференциальные диски – основа технологии снапшотов. При создании снапшота запись в VHD-файл прекращается, и все последующие изменения записываются в отдельный файл, имеющий расширение VHD.
Сохранение состояния (Save State) – одна из полезных функций системы виртуализации. При сохранении состояния все содержимое памяти виртуальной машины, регистров процессора и т.д. сохраняется в специальные файлы, и виртуалка переходит в состояние «Выключено». После этого можно делать все что угодно, вплоть до перезагрузки хостовой машины, а потом снова запустить виртуалку – и она будет работать, как ни в чем не бывало, ровно в том же состоянии, в каком она была до сохранения. Примерно так же работает функция Hibernate в Microsoft Windows с единственным лишь отличием – сохранение состояния происходит на уровне самой виртуальной машины, а не на уровне гостевой ОС. В VirtualPC и Virtual Server для сохранения содержимого памяти использовался файл с расширением VSV, в Hyper-V же их стало аж целых два – BIN и VSV.
Файл экспорта. Если виртуальную машину Hyper-V нужно склонировать, или же перенести на другой хост – необходимо произвести операцию экспорта, а затем импорта. При экспорте конфигурационный XML-файл преобразуется в файл с расширением EXP. В VirtualPC и Virtual Server для этого достаточно просто скопировать файлы виртуальной машины, а в Hyper-V придумали импорт/экспорт – как они сами говорят, в целях безопасности.
Различают два типа моментальных снимков: онлайновый и оффлайновый. Онлайновым называют снапшот, сделанный на виртуальной машине с запущенной гостевой ОС. Соответственно, если виртуальная машина была в состоянии «выключено» — то снапшот будет называться оффлайновым. Для пользователя нет абсолютно никаких различий между онлайновыми и оффлайновыми снапшотами. Различаются они только по составу файлов, потому что при создании снапшота на запущенной виртуалке происходит операция Save State, и данные Save State включаются в состав снапшота
Что можно и что нельзя делать с моментальными снимками?
Как уже было сказано, снапшоты виртуальных машин – это то же самое, что и сохранение в игре. И единственное их назначение – обеспечение точки возврата на случай возможных ошибок. Снапшоты – это не бэкап, и использовать их для аварийного восстановления не получится. Использовать моментальные снимки в production-среде не рекомендуется, потому что это может привести к падению производительности, почему это так – будет понятно далее из статьи. Если необходимо часто создавать резервные копии для защиты от ошибок пользователей – необходимо использовать другие средства, к примеру – инкрементные бэкапы или журналы транзакций, если речь идет о базах данных.
Помимо этого, необходимо помнить, что управлять снапшотами можно и нужно только через стандартные средства Hyper-V (оснастка MMC Hyper-V Manager, WMI-провайдеры, командлеты PowerShell) и сторонний софт, использующий такие средства – например Microsoft SystemCenter Virtual Machine Manager.
Ну и теперь скажу несколько слов в заключение.
Во-первых – как я уже говорил, нужно помнить про «Delete means Apply, Apply means Delete», и думать перед нажатием кнопки, дабы не потерять ничего.
Во-вторых, если виртуальная машина содержит онлайновые снапшоты – ее крайне не рекомендуется экспортировать и переносить на другой сервер. Дело в том, что онлайновый снапшот содержит состояние регистров процессора и содержимое памяти, и применение такого снапшота в другом аппаратном окружении может привести к краху гостевой ОС.
В-третьих, как уже было сказано – снапшоты не рекомендуется использовать в производственной среде. Наверняка вам известно, что для продакшна рекомендуется использовать виртуальные диски фиксированного размера – для того, чтобы избавиться от фрагментации VHD-файла. Создавая же снапшоты, мы искусственно делим наш виртуальный диск на отдельные файлы – VHD и множество AVHD. На высоконагруженных системах это может привести к некоторому падению производительности. Кроме этого, при удалении снапшотов происходит операция объединения, которая тоже может сказаться на общей производительности системы, а к тому же может повысить время простоя при перезагрузках виртуальной машины. К примеру, если вы удалили один или несколько снапшотов на виртуальной машине, а потом потребовалось ее перезагрузить (к примеру – при установке апдейтов), то загрузка ОС не начнется, пока не завершится полностью операция объединения. Поэтому снапшоты можно использовать перед вводом в продакшн, для экономии времени при установке ПО и начальной настройке. После этого все снапшоты нужно удалить, дождаться окончания объединения, и только затем вводить в продакшн.
Еще один небольшой момент: в настройках Hyper-V можно задавать отдельно путь для размещения файлов виртуальных машин и путь для размещения VHD. По умолчанию и то и другое хранится на диске C:. Если для хранения VHD планируется использовать, к примеру, высокоскоростной RAID-массив – необходимо хранить на нем не только VHD, но и файлы виртуальных машин. Дело в том, что при создании снапшотов файлы AVHD будут храниться именно в том месте, которое было выбрано для хранения виртуальных машин. И может получиться так, что сам VHD будет храниться на отдельном дисковом массиве, а куча AVHD будет на диске С:, что не есть хорошо.
На этом я закончу этот пост, и без того уже большой. Прошу прощения за некоторый сумбур, тема при кажущейся простоте немного нетривиальна для объяснения. Для лучшего понимания советую посмотреть скринкаст, с анимированной презентацией и демонстрацией: www.techdays.ru/videos/1490.html
Если хаброобщественность не будет возражать – я могу дать ссылки на другие свои скринкасты и статьи про Hyper-V, дабы не кросспостить и не копипастить. Надеюсь, кого-то моя статья заинтересовала, в любом случае – спасибо заранее.
Знакомимся с альфа-версией снапшотов томов в Kubernetes

Прим. перев.: оригинальная статья была недавно опубликована в блоге Kubernetes и написана сотрудниками компаний Google и Huawei (Jing Xu, Xing Yang, Saad Ali), активную деятельность которых вы непременно видели в GitHub’е проекта, если когда-либо интересовались фичами и проблемами K8s, связанными с хранением данных. Инженеры рассказывают о предназначении снапшотов томов (volume snapshots), их текущих возможностях и основах работы с ними.
Kubernetes v1.12 представил альфа-версию поддержки снапшотов для томов. Эта возможность позволяет создавать и удалять снапшоты томов, а также создавать новые тома из снапшотов «родными» средствами системы — через Kubernetes API.
Что такое снапшот?
Многие системы хранения (вроде Google Cloud Persistent Disks, Amazon Elastic Block Storage и многочисленных систем хранения категории on-premise) предлагают возможность создания снапшота («снимка») для постоянного тома. Снапшот представляет собой копию тома на конкретный момент времени. Его можно использовать для provision’а нового тома (уже наполненного данными из снапшота) или восстановления существующего тома к предыдущему состоянию (которое представлено в снапшоте).
Зачем добавлять снапшоты в Kubernetes?
В системе плагинов томов Kubernetes уже доступна мощная абстракция, автоматизирующая provisioning, подключение и монтирование блочных и файловых хранилищ.
Обеспечение всех этих возможностей входит в цели Kubernetes по переносимости рабочих нагрузок: Kubernetes стремится создать уровень абстракции между приложениями, работающими как распределённые системы, и нижележащими кластерами таким образом, что приложения не зависят от специфики кластера, на котором они запущены, и развёртывание приложения не требует каких-либо специфичных для кластера знаний.
Группа Kubernetes Storage SIG определила операции со снашпотами как критически важные возможности для множества рабочих нагрузок категории stateful. Например, администратор баз данных может захотеть снапшот своей БД перед тем, как выполнять с ней какую-то операцию.
Получив в Kubernetes API стандартный способ для вызова операций над снапшотами, пользователи Kubernetes могут работать с ними без необходимости в обходных путях (и ручного вызова операций, которые специфичны для системы хранения). Вместо этого, пользователям дали возможность встраивать операции над снашпотами в свои инструменты и политики со спокойным пониманием, что всё будет работать с любыми кластерами Kubernetes вне зависимости от нижележащего хранилища.
Ко всему прочему, эти примитивы Kubernetes функционируют как базовые строительные блоки, открывающие возможности для разработки более продвинутых фич enterprise-уровня по управлению хранилищем — например, по защите, репликации и миграции данных.
Какие плагины томов поддерживают снапшоты в Kubernetes?
Kubernetes поддерживает три типа плагинов томов: in-tree, Flex и CSI. Подробности смотрите в Kubernetes Volume Plugin FAQ.
Снапшоты поддерживаются только для драйверов CSI (они не поддерживаются ни для in-tree, ни для Flex). Чтобы воспользоваться этой возможностью, убедитесь, что в кластере Kubernetes развёрнут CSI-драйвер, в котором реализована поддержка снапшотов.
К моменту этой публикации в блоге (9 октября 2018 г. — прим перев.), снапшоты поддерживаются следующими CSI-драйверами:
Kubernetes API для снапшотов
Для управления снапшотами в Kubernetes Volume Snapshots представлено три новых объекта API аналогично тому, как это сделано в API для управления постоянными томами (Kubernetes Persistent Volumes):
CSI-драйверы, поддерживающие снапшоты, автоматически установят необходимые CRD. Конечным пользователям Kubernetes потребуется лишь проверить, что CSI-драйвер, поддерживающий снапшоты, развёрнут в кластере.
В дополнение к этим новым объектам у уже существующего PersistentVolumeClaim появилось новое поле DataSource :
Это поле (в статусе альфа-версии) позволяет при создании нового тома автоматически наполнять его данными из существующего снапшота.
Требования к снапшотам Kubernetes
Перед использованием снапшотов томов в Kubernetes необходимо:
Наконец, перед созданием снапшота необходимо создать том через CSI-драйвер и наполнить его данными, которые вы хотите там увидеть (см. эту публикацию с подробностями о том, как использовать тома CSI).
Создание нового снапшота в Kubernetes
Источник для снапшота определяется двумя параметрами:
Если класс снапшота не задан, external-snapshotter попытается найти класс по умолчанию и воспользоваться им для создаваемого снапшота. При этом CSI-драйвер, на который указывает snapshotter в классе по умолчанию, должен соответствовать CSI-драйверу, на который указывает provisioner в классе хранилища PVC.
Обратите внимание, что альфа-релиз снапшотов для Kubernetes не обеспечивает гарантий консистентности. Для обеспечения целостных данных в снапшоте требуется соответствующим образом подготовить приложение (остановить приложение, заморозить файловую систему и т.п.) перед его снятием.
Импортирование существующего снапшота в Kubernetes
Объект VolumeSnapshotContent должен создаваться со следующими полями, представляющими предварительно подготовленный (pre-provisioned) снапшот:
Объект VolumeSnapshot должен быть создан, чтобы пользователь мог работать со снапшотом. В нём:
Подготовка нового тома из снапшота в Kubernetes
Когда объект PersistentVolumeClaim будет создан, он вызовет provisioning нового тома, предварительно наполненного данными из указанного снапшота.
Как добавить поддержку снапшотов в мой CSI-драйвер, если я разработчик хранилища?
Хотя Kubernetes даёт самые минимальные указания по пакетированию и развёртыванию CSI Volume Driver, имеется рекомендуемый механизм для деплоя произвольного контейнеризированного CSI-драйвера в Kubernetes, чтобы упростить этот процесс.
Как часть рекомендуемого процесса деплоя команда Kubernetes предлагает использовать множество sidecar- (т.е. вспомогательных) контейнеров, в том числе — sidecar-контейнер с external-snapshotter.

В этом примере Deployment представлены два sidecar-контейнера, external provisioner и external snapshotter, а CSI-драйверы деплоятся вместе с плагином CSI hostpath в рамках StatefulSet-пода. CSI hostpath — это пример плагина, который не предназначен для использования в production.
Каковы ограничения альфа-версии?
Альфа-версия реализации снапшотов в Kubernetes имеет следующие ограничения:
Что дальше?
Команда Kubernetes планирует довести реализацию снапшотов для CSI до бета-версии в релизах 1.13 или 1.14 в зависимости от полученной обратной связи и адаптации технологии.
Бэкап для Linux, или как создать снапшот
Всем привет! Я работаю в Veeam над проектом Veeam Agent for Linux. С помощью этого продукта можно бэкапить машину с ОС Linux. «Agent» в названии означает, что программа позволяет бэкапить физические машины. Виртуалки тоже бэкапит, но располагается при этом на гостевой ОС.
Вдохновением для этой статьи послужил мой доклад на конференции Linux Piter, который я решил оформить в виде статьи для всех интересующихся хабражителей.
В статье я раскрою тему создания снапшота, позволяющего произвести бэкап и поведаю о проблемах, с которыми мы столкнулись при создании собственного механизма создания снапшотов блочных устройств.
Всех заинтересовавшихся прошу под кат!

Немного теории в начале
Исторически так сложилось, что есть два подхода к созданию бэкапов: File backup и Volume backup. В первом случае мы копируем каждый файл как отдельный объект, во втором – копируем всё содержимое тома в виде некоего образа.
У обоих способов есть масса своих плюсов и минусов, но мы рассмотрим их через призму восстановления после сбоя:
Как же нам взять и сохранить весь том целиком? Само собой, простым копированием мы ничего хорошего не добьёмся. Во время копирования на томе будет происходить какая-то активность с данными, в итоге в бэкапе окажутся несогласованные данные. Структура файловой системы будет нарушена, файлы баз данных повреждены, как и прочие файлы, с которыми во время копирования будут производиться операции.
Чтобы избежать всех этих проблем, прогрессивное человечество придумало технологию моментального снимка – снапшота. В теории всё просто: создаём неизменную копию – снапшот – и бэкапим данные с него. Когда бэкап окончен – снапшот уничтожаем. Звучит просто, но, как водится, есть нюансы.
Из-за них было рождено множество реализаций этой технологи. Например, решения на основе device mapper, такие, как LVM и Thin provisioning, обеспечивают полноценные снапшоты томов, но требуют специальной разметки дисков ещё на этапе установки системы, а значит, в общем случае не подходят.
BTRFS и ZFS дают возможность создавать моментальные снимки подструктур файловой системы, что очень здорово, но на данный момент их доля на серверах невелика, а мы пытаемся сделать универсальное решение.
Предположим, на нашем блочном девайсе есть банальная EXT. В этом случае мы можем использовать dm-snap (кстати, сейчас разрабатывается dm-bow), но тут — свой нюанс. Нужно иметь на готове свободное блочное устройство, чтобы было куда отбрасывать данные снапшота.
Обратив внимание на альтернативные решения для бэкапа, мы заметили что они, как правило, используют свой модуль ядра для создания снапшотов блочных устройств. Этим путём решили пойти и мы, написав свой модуль. Решено было распространять его по GPL лицензии, так что в открытом доступе он доступен на github.
How it works — в теории
Снапшот под микроскопом
Итак, теперь рассмотрим общий принцип работы модуля и более подробно остановимся на ключевых проблемах.
По сути, veeamsnap (так мы назвали свой модуль ядра) – это фильтр драйвера блочного устройства.
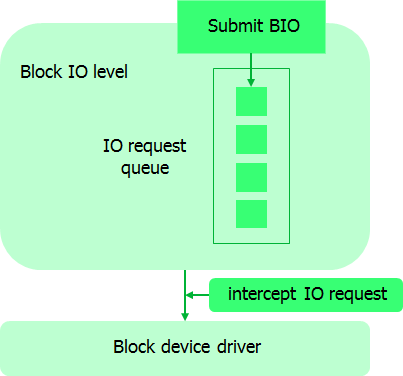
Его работа заключена в перехвате запросов к драйверу блочного устройства.
Перехватив запрос на запись, модуль производит копирование данных с оригинального блочного устройства в область данных снапшота. Назовём эту область снапсторой.

А что такое сам снапшот? Это виртуальное блочное устройство, копия оригинального устройства на конкретный момент времени. При обращении к блокам данных на этом устройстве они могут быть считаны либо со снапсторы, либо с оригинального устройства.
Хочу отметить, что снапшот – это именно блочное устройство, полностью идентичное оригинальному на момент снятия снапшота. Благодаря этому мы можем смонтировать файловую систему на снапшоте и произвести необходимый предпроцессинг.
Например, мы можем получить карту занятых блоков от файловой системы. Самый простой способ это сделать – воспользоваться ioctl GETFSMAP.
Данные о занятых блоках позволяют читать со снапшота только актуальные данные.
Также, можно исключить некоторые файлы. Ну, и совсем опциональное действие: проиндексировать файлы, которые попадают в бэкап, для возможности гранулярного рестора в будущем.
CoW vs RoW
Давайте немного остановимся на выборе алгоритма работы снапшота. Выбор тут не особо обширен: Copy-on-Write или Redirect-on-Write.
Redirect-on-Write при перехвате запроса на запись перенаправит его в снапстору, после чего все запросы на чтение этого блока будут уходить туда же. Замечательный алгоритм для систем хранения, построенных на базе В+ деревьев, таких, как BTRFS, ZFS и Thin Provisioning. Технология стара как мир, но особенно хорошо она проявляет себя в гипервизорах, где можно создать новый файл и писать туда новые блоки на время жизни снапшота. Производительность – отличная, по сравнению с CoW. Но есть жирный минус – структура оригинального устройства меняется, а при удалении снапшота надо скопировать все блоки из снапсторы в оригинальное место.
Copy-on-Write при перехвате запроса копирует в снапстору данные, которые должны подвергнуться изменению, после чего позволяет их перезаписать в оригинальном месте. Используется для создания снапшотов для LVM томов и теневых копий VSS. Очевидно, для создания снапшотов блочных устройств он подходит больше, т.к. не меняет структуру оригинального устройства, и при удалении (или аварии) снапшот можно просто отбросить, не рискуя данными. Минус такого подхода – снижение производительности, так как на каждую операцию записи добавляется пара операций чтение/запись.
Поскольку обеспечение сохранности данных для нас основной приоритет, мы остановились именно на CoW.
Пока всё выглядит просто, поэтому давайте пройдёмся по проблемам из реальной жизни.
How it works — на практике
Согласованное состояние
Ради него всё и задумывалось.
Например, если в момент создания снапшота (в первом приближении можно считать, что создаётся он моментально) в какой-то файл будет производиться запись, то в снапшоте файл окажется недописанным, а значит — повреждённый и бессмысленный. Аналогичная ситуация и с файлам баз данных и самой файловой системой.
Но мы же в 21-м веке живём! Есть же механизмы журналирования, предохраняющие от подобных проблем! Замечание верное, правда, есть важное “но”: эта защита не от сбоя, а от его последствий. При восстановлении в согласованное состояние по журналу незавершённые операции будут отброшены, а значит — потеряны. Поэтому важно сместить приоритет на защиту от причины, а не лечить последствия.
Систему можно предупредить о том, что сейчас будет создан снапшот. Для этого в ядре есть функции freeze_bdev и thaw_bdev. Они дёргают функции файловой системы freeze_fs и unfreeze_fs. При вызове первой система должна сбросить кэш, приостановить создание новых запросов к блочному устройству и дождаться завершения всех ранее сформированных запросов. А при вызове unfreeze_fs файловая система восстанавливает своё нормальное функционирование.
Получается, что файловую систему мы можем предупредить. А что с приложениями? Тут, к сожалению, всё плохо. В то время, как в Windows существует механизм VSS, который с помощью Writer-ов обеспечивает взаимодействие с другими продуктами, в Linux каждый идёт своим путём. На данный момент это привело к ситуации, что задача администратора системы самостоятельно написать (скопировать, украсть, купить, etc) pre-freeze и post-thaw скрипты, которые будут подготавливать их приложение к снапшоту. Со своей стороны, в ближайшем релизе мы внедрим поддержку Oracle Application Processing, как наиболее часто запрашиваемую нашими клиентами функцию. Потом, возможно, будут поддержаны и другие приложения, но в целом ситуация довольно печальна.
Где расположить снапстору?
Это вторая встающая на нашем пути проблема. С первого взгляда проблема не очевидна, но, немного разобравшись, увидим, что это та ещё заноза.
Конечно же, самое простое решение — расположить снапстору в RAM. Для разработчика вариант просто отличный! Всё быстро, очень удобно делать отладку, но есть косяк: оперативка — ресурс ценный, и расположить там большую снапстору нам никто не даст.
ОК, давайте сделаем снапстору обычным файлом. Но возникает другая проблема – нельзя бэкапить том, на котором расположена снапстора. Причина проста: мы перехватываем запросы на запись, а значит, будем и перехватывать свои собственные запросы на запись в снапстору. Кони бегали по кругу, по-научному — deadlock. Следом возникает острое желание использовать для этого отдельный диск, но никто ради нас в сервера диски добавлять не будет. Работать надо уметь на том что есть.
Расположить снапстору удалённо — идея отличная, но реализуема в очень уж узких кругах сетей с большой пропускной способностью и микроскопических латенси. Иначе во время удержания снапшота на машине будет пошаговая стратегия.
Значит, надо как-то хитро расположить снапстору на локальном диске. Но, как правило, всё место на локальных дисках уже распределено между файловыми системами, и заодно надо крепко подумать, как обойти проблему deadlock’a.
Направление для раздумий, в принципе, одно: надо как-то аллоцировать у файловой системы пространство, но с блочным устройством работать напрямую. Решение этой проблемы было реализовано в user-space коде, в сервисе.
Существует системный вызов fallocate, который позволяет создать пустой файл нужного размера. При этом фактически на файловой системе создаются только метаданные, описывающие расположение файла на томе. А ioctl FIEMAP позволяет нам получить карту расположения блоков файла.
И вуаля: мы создаём файл под снапстору с помощью fallocate, FIEMAP отдаёт нам карту расположения блоков этого файла, которую мы можем передать для работы в наш модуль veeamsnap. Далее при обращении к снапсторе модуль делает запросы напрямую к блочному устройству в известные нам блоки, и никаких deadlock’ов.
Но тут есть нюанс. Системный вызов fallocate поддерживается только XFS, EXT4 и BTRFS. Для остальных файловых систем вроде EXT3 для аллокации файла его приходится полностью записывать. На функционале это сказывается увеличением времени на подготовку снапсторы, но выбирать не приходится. Опять таки, работать надо уметь на том что есть.
А что, если ioctl FIEMAP тоже не поддерживается? Это реальность NTFS и FAT32, где нет даже поддержки древнего FIBMAP. Пришлось реализовать некий generic алгоритм, работа которого не зависит от особенностей файловой системы. В двух словах алгоритм такой:
Переполнение снапшота
Вернее, заканчивается место, которые мы выделили под снапстору. Суть проблемы в том, что новые данные некуда отбрасывать, а значит, снапшот становится непригоден для использования.
Что делать?
Очевидно, надо увеличивать размер снапсторы. А насколько? Самый простой способ задания размера снапсторы – это определить процент от свободного места на томе (как сделано для VSS). Для тома в 20 TB 10% будет 2TB – что очень много для ненагруженного сервера. Для тома в 200 GB 10% составит 20GB, что может оказаться слишком мало для сервера, интенсивно обновляющего свои данные. А есть ещё тонкие тома…
В общем, заранее прикинуть оптимальный размер требуемой снапсторы может только системный администратор сервера, то есть придётся заставить человака подумать и выдать своё экспертное мнение. Это не соотвествует принципу «It just work».
Для решения этой проблемы мы разработали алгоритм stretch snapshot. Идея состоит в разбиении снапсторы на порции. При этом, новые порции создаются уже после создания снапшота по мере необходимости.

Опять же коротенько алгоритм:
Что делать в других случаях? Пытаемся угадать необходимый размер и создаём всю снапстору целиком. Но по нашей статистике, подавляющее большинство Linux серверов сейчас используют EXT4 и XFS. EXT3 встречается на старых машинах. Зато в SLES/openSUSE можно наткнуться на BTRFS.
Change Block Tracking (CBT)
Инкрементальный или дифференциальный бэкап (кстати, слаще хрен редьки или нет, предлагаю читать тут) – без него нельзя представить ни один взрослый продукт для бэкапа. А чтобы это работало, нужен CBT. Если кто-то пропустил: CBT позволяет отслеживать изменения и записывать в бэкап только изменённые с последнего бэкапа данные.

Свои наработки в этой области есть у многих. Например, в VMware vSphere эта функция доступна с 4-ой версии в 2009 году. В Hyper-V поддержка внедрена с Windows Server 2016, а для поддержки более ранних релизов был разработотан собственный драйвер VeeamFCT ещё в 2012-м. Поэтому, для нашего модуля мы не стали оригинальничать и использовали уже работающие алгоритмы.
Коротенько о том, как это работает.

Весь отслеживаемый том разбит на блоки. Модуль просто отслеживает все запросы на запись, помечая изменившиеся блоки в таблице. Фактически, таблица CBT – это массив байт, где каждый байт соответствует блоку и содержит номер снапшота, в котором он был изменён.
Во время бэкапа номер снапшота записывается в метаданные бэкапа. Таким образом, зная номера текущего снапшота и того, с которого был сделан предыдущий успешный бэкап, можно вычислить карту расположения изменившихся блоков.
Тут есть два нюанса.
Как я сказал, под номер снапшота в таблице CBT выделен один байт, значит, максимальная длина инкрементальной цепочки не может быть больше 255. При достижении этого порога таблица сбрасывается и происходит полный бэкап. Может показаться неудобным, но на самом деле цепочка в 255 инкрементов – далеко не самое лучшее решение при создании бэкап-плана.
Вторая особенность – это хранение CBT таблицы только в оперативной памяти. А значит, при перезагрузке целевой машины или выгрузке модуля она будет сброшена, и опять-таки, понадобится создавать полный бэкап. Такое решение позволяет не решать проблему старта модуля при старте системы. Кроме того, отпадает необходимость сохранять CBT таблицы при выключении системы.
Проблема производительности
Бекап — это всегда хорошая такая нагрузка на IO вашего оборудования. Если на нём и так хватает активных задач, то процесс резервного копирования может превратить вашу систему в этакого ленивца.
Давайте посмотрим, почему.
Представим, что сервер просто линейно пишет какие-то данные. Скорость записи в таком случае максимальна, все задержки минимизированы, производительность стремится к максимуму. Теперь добавим сюда процесс бэкапа, которому при каждой записи надо ещё успеть выполнить алгоритм Copy-on-Write, а это дополнительная операция чтения с последующей записью. И не забывайте, что для бэкапа надо ещё читать данные с этого же тома. Словом, ваш красивый linear access превращается в беспощадный random access со всеми вытекающими.
С этим явно надо что-то делать, и мы реализовали конвейер, чтобы обрабатывать запросы не по одному, а целыми пачками. Работает это так.

При перехвате запросов они укладываются в очередь, откуда их порциями забирает специальный поток. В это время создаются CoW-запросы, которые также обрабатываются порциями. При обработке CoW-запросов вначале производятся все операции чтения для всей порции, после чего выполняются операции записи. Только после завершения обработки всей порции CoW-запросов выполняются перехваченные запросы. Такой конвейер обеспечивает обращения к диску крупными порциями данных, что минимизирует временные потери.
Throttling
Уже на стадии отладки всплыл ещё нюанс. Во время бэкапа система становилась неотзывчивой, т.е. системные запросы ввода-вывода начинали выполняться с большими задержками. Зато, запросы на чтение данных со снапшота выполнялись на скорости, близкой к максимальной.
Пришлось немного придушить процесс бэкапа, реализовав механизм тротлинга. Для этого читающий из образа снапшота процесс переводится в состояние ожидания, если очередь перехваченных запросов не пуста. Ожидаемо, система ожила.

В результате, если нагрузка на систему ввода-вывода резко возрастает, то процесс чтения со снапшота будет ждать. Тут мы решили руководствоваться принципом, что лучше мы завершим бэкап ошибкой, чем нарушим работу сервера.
Deadlock
Я думаю, надо немного подробней объяснить, что это такое.
Уже на этапе тестирования мы стали сталкиваться с ситуациями полного повисания системы с диагнозом: семь бед – один ресет.
Стали разбираться. Выяснилось, что такую ситуацию можно наблюдать, если например создать снапшот блочного устройства, на котором расположен LVM-том, а снапстору расположить на том же LVM-томе. Напомню, что LVM использует модуль ядра device mapper.
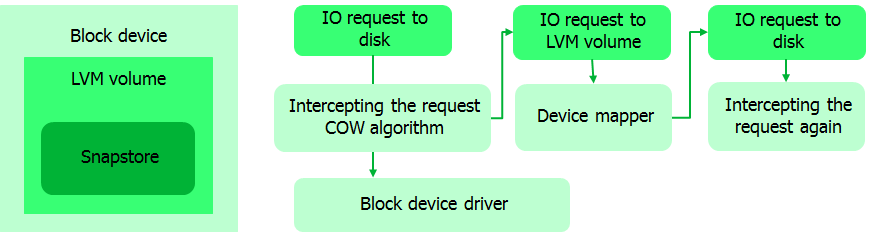
В данной ситуации при перехвате запроса на запись, модуль, копируя данные в снапстору, отправит запрос на запись LVM-тому. Device mapper перенаправит этот запрос на блочное устройство. Запрос от device mapper-а снова будет перехвачен модулем. Но новый запрос не может быть обработан, пока не обработан предыдущий. В итоге, обработка запросов заблокирована, вас приветствует deadlock.
Чтобы не допустить подобной ситуации, в самом модуле ядра предусмотрен таймаут для операции копирования данных в снапстору. Это позволяет выявить deadlock и аварийно завершить бэкап. Логика здесь всё та же: лучше не сделать бэкап, чем подвесить сервер.
Round Robin Database
Это уже проблема, подкинутая пользователями после релиза первой версии.
Оказалось, есть такие сервисы, которые только и занимаются тем, что постоянно перезаписывают одни и те же блоки. Яркий пример – сервисы мониторинга, которые постоянно генерируют данные о состоянии системы и перезаписывают их по кругу. Для таких задач используют специализированные циклические базы данных (RRD).
Выяснилось, что при бэкапе таких баз снапшот гарантированно переполнится. При детальном изучении проблемы мы обнаружили недочёт в реализации CoW алгоритма. Если перезаписывался один и тот же блок, то в снапстору каждый раз копировались данные. Результат: дублирование данных в снапсторе.
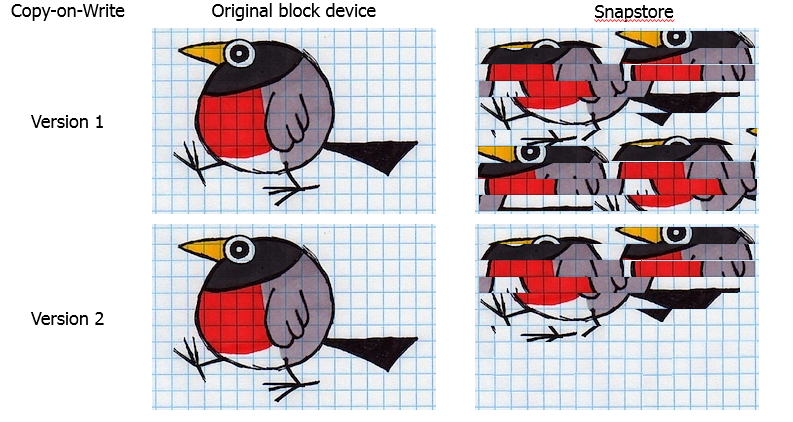
Естественно, алгоритм мы изменили. Теперь том разбит на блоки, и данные копируются в снапстору блоками. Если блок уже был один раз скопирован, то повторно этот процесс не производится.
Выбор размера блока
Теперь, когда снапстора разбита на блоки встает вопрос: а какого, собственно, размера делать блоки для разбиения снапсторы?
Проблема двоякая. Если блок сделать большим, им легче оперировать, но при изменении хотя-бы одного сектора, придётся отправить весь блок в снапостору и, как следствие, повышаются шансы на переполнение снапсторы.
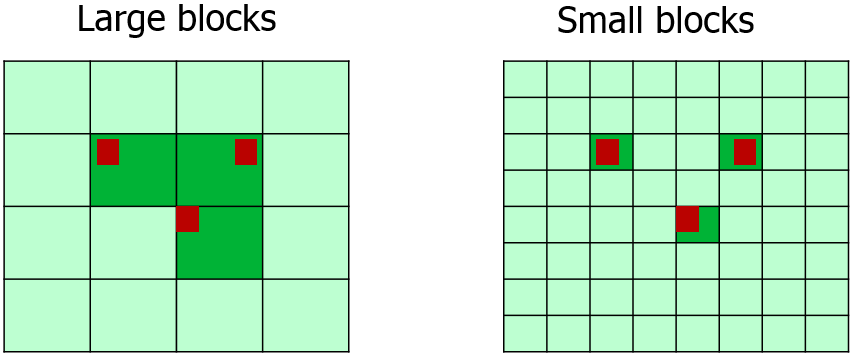
Очевидно, что чем меньше размер блока, тем больший процент полезных данных отправляется в снапстору, но как это ударит по производительности?
Правду искали эмпирическим путём и пришли в результату в 16KiB. Также отмечу, что в Windows VSS тоже используются блоки в 16 KiB.
Вместо заключения
На этом пока всё. За бортом оставлю множество других, не менее интересных проблем, таких, как зависимость от версий ядра, выбор вариантов распространения модуля, kABI совместимость, работа в условиях бекпортов и т.д. Статья и так получилась объёмной, поэтому я решил остановиться на самых интересных проблемах.
Сейчас мы готовим к релизу версию 3.0, код модуля лежит на github, и каждый желающий может использовать его в рамках GPL лицензии.