Стэк что это
Стэк что это
Стэк что это


Добавление элемента, называемое также проталкиванием ( push ), возможно только в вершину стека (добавленный элемент становится первым сверху). Удаление элемента, называемое также выталкиванием ( pop ), тоже возможно только из вершины стека, при этом второй сверху элемент становится верхним.
Стеки широко применяются в вычислительной технике. Например, для отслеживания точек возврата из подпрограмм используется стек вызовов, который является неотъемлемой частью архитектуры большинства современных процессоров. Языки программирования высокого уровня также используют стек вызовов для передачи параметров при вызове процедур.
Арифметические сопроцессоры, программируемые микрокалькуляторы и язык Forth используют стековую модель вычислений.
В ЦВК стек называется магазином — по аналогии с магазином в огнестрельном оружии (стрельба начнётся с патрона, заряженного последним)
Стэк что это

Стек (от англ. stack — стопка) — структура данных, представляющая из себя упорядоченный набор элементов, в которой добавление новых элементов и удаление существующих производится с одного конца, называемого вершиной стека. Притом первым из стека удаляется элемент, который был помещен туда последним, то есть в стеке реализуется стратегия «последним вошел — первым вышел» (last-in, first-out — LIFO). Примером стека в реальной жизни может являться стопка тарелок: когда мы хотим вытащить тарелку, мы должны снять все тарелки выше. Вернемся к описанию операций стека:
Реализации [ править ]
Для стека с [math]n[/math] элементами требуется [math]O(n)[/math] памяти, так как она нужна лишь для хранения самих элементов.
На массиве [ править ]
Перед реализацией стека выделим ключевые поля:
Каждую операцию над стеком можно легко реализовать несколькими строками кода:
На саморасширяющемся массиве [ править ]
Возможна реализация стека на динамическом массиве, в результате чего появляется существенное преимущество над обычной реализацией: при операции push мы никогда не сможем выйти за границы массива, тем самым избежим ошибки исполнения.
На списке [ править ]
Стек можно реализовать и на списке. Для этого необходимо создать список и операции работы стека на созданном списке. Ниже представлен пример реализации стека на односвязном списке. Стек будем «держать» за голову. Добавляться новые элементы посредством операции [math] \mathtt
Заведем конструктор вида ListItem(next : ListItem, data : T)
Что такое стек
И почему так страшен стек-оверфлоу.
Постепенно осваиваем способы организации и хранения данных. Уже было про деревья, попробуем про стеки. Это для тех, кто хочет в будущем серьёзно работать в ИТ: одна из фундаментальных концепций, которая влияет на качество вашего кода, но не касается какого-то конкретного языка программирования.
👉 Стек — это одна из структур данных. Структура данных — это то, как хранятся данные: например, связанные списки, деревья, очереди, множества, хеш-таблицы, карты и даже кучи (heap).
Как устроен стек
Стек хранит последовательность данных. Связаны данные так: каждый элемент указывает на тот, который нужно использовать следующим. Это линейная связь — данные идут друг за другом и нужно брать их по очереди. Из середины стека брать нельзя.
👉 Главный принцип работы стека — данные, которые попали в стек недавно, используются первыми. Чем раньше попал — тем позже используется. После использования элемент стека исчезает, и верхним становится следующий элемент.

Классический способ объяснения принципов стека звучит так: представьте, что вы моете посуду и складываете одинаковые чистые тарелки стопкой друг на друга. Каждая новая тарелка — это элемент стека, а вы просто добавляете их по одной в стек.
Когда кому-то понадобится тарелка, он не будет брать её снизу или из середины — он возьмёт первую сверху, потом следующую и так далее.
🤔 Есть структура данных, похожая на стек, — называется очередь, или queue. Если в стеке кто последний пришёл, того первым заберут, то в очереди наоборот: кто раньше пришёл, тот раньше ушёл. Можно представить очередь в магазине: кто раньше её занял, тот первый дошёл до кассы. Очередь — это тоже линейный набор данных, но обрабатывается по-другому.
Стек вызовов
В программировании есть два вида стека — стек вызовов и стек данных.
Когда в программе есть подпрограммы — процедуры и функции, — то компьютеру нужно помнить, где он прервался в основном коде, чтобы выполнить подпрограмму. После выполнения он должен вернуться обратно и продолжить выполнять основной код. При этом если подпрограмма возвращает какие-то данные, то их тоже нужно запомнить и передать в основной код.
Чтобы это реализовать, компьютер использует стек вызовов — специальную область памяти, где хранит данные о точках перехода между фрагментами кода.
Допустим, у нас есть программа, внутри которой есть три функции, причём одна из них внутри вызывает другую. Нарисуем, чтобы было понятнее:

Программа запускается, потом идёт вызов синей функции. Она выполняется, и программа продолжает с того места, где остановилась. Потом выполняется зелёная функция, которая вызывает красную. Пока красная не закончит работу, все остальные ждут. Как только красная закончилась — продолжается зелёная, а после её окончания программа продолжает свою работу с того же места.
А вот как стек помогает это реализовать на практике:

Программа дошла до синей функции, сохранила точку, куда ей вернуться после того, как закончится функция, и если функция вернёт какие-то данные, то программа тоже их получит. Когда синяя функция закончится и программа получит верхний элемент стека, он автоматически исчезнет. Стек снова пустой.

С зелёной функцией всё то же самое — в стек заносится точка возврата, и программа начинает выполнять зелёную функцию. Но внутри неё мы вызываем красную, и вот что происходит:

При вызове красной функции в стек помещается новый элемент с информацией о данных, точке возврата и указанием на следующий элемент. Это значит, что когда красная функция закончит работу, то компьютер возьмёт из стека адрес возврата и вернёт управление снова зелёной функции, а красный элемент исчезнет. Когда и зелёная закончит работу, то компьютер из стека возьмёт новый адрес возврата и продолжит работу со старого места.
Переполнение стека
Почти всегда стек вызовов хранится в оперативной памяти и имеет определённый размер. Если у вас будет много вложенных вызовов или рекурсия с очень большой глубиной вложенности, то может случиться такая ситуация:
Переполнение — это плохо: данные могут залезать в чужую область памяти и записывать себя вместо прежних данных. Это может привести к сбою в работе других программ или самого компьютера. Ещё таким образом можно внедрить в оперативную память вредоносный код: если программа плохо работает со стеком, можно специально вызвать переполнение и записать в память что-нибудь вредоносное.
Стек данных
Стек данных очень похож на стек вызовов: по сути, это одна большая переменная, похожая на список или массив. Его чаще всего используют для работы с другими сложными типами данных: например, быстрого обхода деревьев, поиска всех возможных маршрутов по графу, — и для анализа разветвлённых однотипных данных.
Стек данных работает по такому же принципу, как и стек вызовов — элемент, который добавили последним, должен использоваться первым.
Что дальше
А дальше поговорим про тип данных под названием «куча». Да, такой есть, и с ним тоже можно эффективно работать. Стей тюнед.
Принципы программирования: стек и куча: что это такое?
 С каждым годом мы применяем для программирования всё более продвинутые языки, позволяющие писать меньше кода, но получать нужные нам результаты. Однако всё это не проходит даром для разработчиков. Так как программисты всё реже занимаются низкоуровневыми вещами, уже никого не удивляет ситуация, когда разработчик не вполне понимает, что означают такие понятия, как куча и стек. Что это такое, как происходит компиляция на самом деле, в чём разница между динамической и статической типизацией.
С каждым годом мы применяем для программирования всё более продвинутые языки, позволяющие писать меньше кода, но получать нужные нам результаты. Однако всё это не проходит даром для разработчиков. Так как программисты всё реже занимаются низкоуровневыми вещами, уже никого не удивляет ситуация, когда разработчик не вполне понимает, что означают такие понятия, как куча и стек. Что это такое, как происходит компиляция на самом деле, в чём разница между динамической и статической типизацией.
К сожалению, некоторые программисты, даже будучи «джуниорами» и работая на реальных проектах, не совсем чётко ориентируются в таких, казалось бы, олдскульных вещах. Именно поэтому в нашей сегодняшней статье мы вспомним, что же это такое — стек и куча, для чего они нужны и где применяются. Несмотря на то, что и стек, и куча связаны с управлением памятью, стратегия и принципы управления кардинально различаются.
Стек — что это такое?
Большое число задач, связанных с обработкой информации, поддаются типизированному решению. В результате совсем неудивительно, что многие из них решаются с помощью специально придуманных методов, терминов и описаний. Среди них нередко можно услышать и такое слово, как стек (стэк). Хоть и звучит этот термин, на первый взгляд, странно и даже сложно, всё намного проще, чем кажется.
Стек и простой жизненный пример
Представьте, что на столе в коробке лежит стопка бумажных листов. Чтобы получить доступ к самому нижнему листу, вам нужно достать самый первый лист, потом второй и так далее, пока не доберётесь до последнего. По схожему принципу и устроен стек: чтобы последний элемент стека стал верхним, нужно сначала вытащить все остальные. 
Стек и особенности его работы
Перейдя к компьютерной терминологии, скажем, что стек — это область оперативной памяти, создаваемая для каждого потока. И последний добавленный в стек кусочек памяти и будет первым в очереди, то есть первым на вывод из стека. И каждый раз, когда функцией объявляется переменная, она, прежде всего, добавляется в стек. А когда данная переменная пропадает из нашей области видимости (к примеру, функция заканчивается), эта самая переменная автоматически удаляется из стека. При этом если стековая переменная освобождается, то и область памяти, в свою очередь, становится доступной и свободной для других стековых переменных.
Благодаря природе, которую имеет стек, управление памятью становится весьма простым и логичным для выполнения на центральном процессоре. Это повышает скорость и быстродействие ЦП, и в особенности такое происходит потому, что время цикла обновления байта весьма незначительно (данный байт, скорее всего, привязан к кэшу центрального процессора).
Тем не менее у данной довольно строгой формы управления имеются и свои недостатки. Например, размер стека — это величина фиксированная, в результате чего при превышении лимита памяти, выделенной на стеке, произойдёт переполнение стека. Как правило, размер задаётся во время создания потока, плюс у каждой переменной имеется максимальный размер, который зависит от типа данных. Всё это позволяет ограничивать размеры некоторых переменных (допустим, целочисленных).
Кроме того, это вынуждает объявлять размер более сложных типов данных (к примеру, массивов) заранее, так как стек не позволит потом изменить его. Вдобавок ко всему, переменные, которые расположены на стеке, являются всегда локальными.
Для чего нужен стек?
Главное предназначение стека — решение типовых задач, предусматривающих поддержку последовательности состояний или связанных с инверсионным представлением данных. В компьютерной отрасли стек применяется в аппаратных устройствах (например, в центральном процессоре, как уже было упомянуто выше).
Практически каждый, кто занимался программированием, знает, что без стека невозможна рекурсия, так как при любом повторном входе в функцию требуется сохранение текущего состояния на вершине, причём при каждом выходе из функции, нужно быстро восстанавливать это состояние (как раз наша последовательность LIFO).
Если же копнуть глубже, то можно сказать, что, по сути, весь подход к запуску и выполнению приложений устроен на принципах стека. Не секрет, что прежде чем каждая следующая программа, запущенная из основной, будет выполняться, состояние предыдущей занесётся в стек, чтобы, когда следующая запущенная подпрограмма закончит выполняться, предыдущее приложение продолжило работу с места остановки.
Стеки и операции стека
Если говорить об основных операциях, то стек имеет таковых две: 1. Push — ни что иное, как добавление элемента непосредственно в вершину стека. 2. Pop — извлечение из стека верхнего элемента.
Также, используя стек, иногда выполняют чтение верхнего элемента, не выполняя его извлечение. Для этого предназначена операция peek.
Как организуется стек?
Когда программисты организуют или реализуют стек, они применяют два варианта: 1. Используя массив и переменную, указывающую на ячейку вершины стека. 2. Используя связанные списки.
У этих двух вариантов реализации стека есть и плюсы, и минусы. К примеру, связанные списки считаются более безопасными в плане применения, ведь каждый добавляемый элемент располагается в динамически созданной структуре (раз нет проблем с числом элементов, значит, отсутствуют дырки в безопасности, позволяющие свободно перемещаться в памяти программного приложения). Однако с точки зрения хранения и скорости применения связанные списки не столь эффективны, так как, во-первых, требуют дополнительного места для хранения указателей, во-вторых, разбросаны в памяти и не расположены друг за другом, если сравнивать с массивами.
Подытожим: стек позволяет управлять памятью более эффективно. Однако помните, что если вам потребуется использовать глобальные переменные либо динамические структуры данных, то лучше обратить своё внимание на кучу.
Стек и куча
Куча — хранилище памяти, расположенное в ОЗУ. Оно допускает динамическое выделение памяти и работает не так, как стек. По сути, речь идёт о простом складе для ваших переменных. Когда вы выделяете здесь участок памяти для хранения, к ней можно обращаться как в потоке, так и во всём приложении в целом (именно так и определяются переменные глобального типа). По завершении работы приложения все выделенные участки освобождаются.
Размер кучи задаётся во время запуска приложения, однако, в отличие от того, как работает стек, в куче размер ограничен только физически, что позволяет создавать переменные динамического типа.
Если сравнивать, опять же, с тем, как работает стек, то куча функционирует медленнее, т. к. переменные разбросаны по памяти, а не находятся вверху стека. Тем не менее данный факт не уменьшает важности кучи, и если вам надо работать с глобальными либо динамическими переменными, она больше подходит. Однако управлять памятью тогда должен программист либо сборщик мусора.
Итак, теперь вы знаете и что такое стек, и что такое куча. Это довольно простые знания, больше подходящие для новичков. Если же вас интересуют более серьёзные профессиональные навыки, выбирайте нужный вам курс по программированию в OTUS!
Значение слова «стек»

Источник (печатная версия): Словарь русского языка: В 4-х т. / РАН, Ин-т лингвистич. исследований; Под ред. А. П. Евгеньевой. — 4-е изд., стер. — М.: Рус. яз.; Полиграфресурсы, 1999; (электронная версия): Фундаментальная электронная библиотека
Чаще всего принцип работы стека сравнивают со стопкой тарелок: чтобы взять вторую сверху, нужно снять верхнюю.
В цифровом вычислительном комплексе стек называется магазином — по аналогии с магазином в огнестрельном оружии (стрельба начнётся с патрона, заряженного последним).
В 1946 Алан Тьюринг ввёл понятие стека. А в 1957 году немцы Клаус Самельсон и Фридрих Л. Бауэр запатентовали идею Тьюринга.
В некоторых языках (например, Lisp, Python) стеком можно назвать любой список, так как для них доступны операции pop и push. В языке C++ стандартная библиотека имеет класс с реализованной структурой и методами. И т. д.
СТЕК [тэ], а, м. [англ. stick] (спорт.). Твердый, эластичный хлыст, употр. при верховой езде.
Источник: «Толковый словарь русского языка» под редакцией Д. Н. Ушакова (1935-1940); (электронная версия): Фундаментальная электронная библиотека
стек I
1. короткая тонкая трость с ременной петлёй на конце ◆ Военный сурово слушал, ударяя стеком по голенищу сапога. В. В. Вересаев, «В тупике», 1923 г. (цитата из НКРЯ) ◆ Маленькую голову всадника венчала офицерская английская фуражка, в руке он держал стек. А. И. Пантелеев, «Ленька Пантелеев», 1938–1952 г. (цитата из НКРЯ)
стек II
1. комп. структура данных, отличающаяся возможностью доступа исключительно к своему последнему элементу ◆ Стек вызовов
2. техн. комп. группа сетевых устройств, протоколов, каких-либо технических средств, логически интегрированных в единую систему ◆ Стек коммутаторов логически представляет собой одно устройство, которое управляется внутри стека главным коммутатором. ◆ Для совместной работы устройств, занимающихся передачей аудио- и видеотрафика, применяют несколько схем работы, которые используют разные рекомендации и стеки протоколов. «Протоколы, используемые в IP-телефонии», 2004 г. // «Информационные технологии» (цитата из НКРЯ) ◆ Отметим, что при помещении BP в стек относительные смещения параметров увеличатся на 2, поскольку стек теперь увеличится на два. Алексей Калугин
3. игр. количество денег или фишек, которым игрок располагает за столом для игры
Фразеологизмы и устойчивые сочетания
стек III
1. то же, что стека, инструмент скульптора, применяемый при лепке из глины и других мягких материалов; деревянная, костяная или металлическая палочка с расширенными в виде лопатки концами ◆ Основная скульптурная техника — лепка. Художник вылепливает руками из воска или влажной глины формы, которые он затем «доводит» с помощью инструментов — шпателя или стека. «Всемирная энциклопедия искусства. Техники скульптуры»
стёк I
Делаем Карту слов лучше вместе
 Привет! Меня зовут Лампобот, я компьютерная программа, которая помогает делать Карту слов. Я отлично умею считать, но пока плохо понимаю, как устроен ваш мир. Помоги мне разобраться!
Привет! Меня зовут Лампобот, я компьютерная программа, которая помогает делать Карту слов. Я отлично умею считать, но пока плохо понимаю, как устроен ваш мир. Помоги мне разобраться!
Спасибо! Я обязательно научусь отличать широко распространённые слова от узкоспециальных.
Насколько понятно значение слова натаянный (прилагательное):
О стеке простыми словами — для студентов и просто начинающих
Привет, я студент второго курса технического университета. После пропуска нескольких пар программирования по состоянию здоровья, я столкнулся с непониманием таких тем, как «Стек» и «Очередь». Путем проб и ошибок, спустя несколько дней, до меня наконец дошло, что это такое и с чем это едят. Чтобы у вас понимание не заняло столько времени, в данной статье я расскажу о том что такое «Стек», каким образом и на каких примерах я понял что это такое. Если вам понравится, я напишу вторую часть, которая будет затрагивать уже такое понятие, как «Очередь»
Теория
На Википедии определение стека звучит так:
Стек (англ. stack — стопка; читается стэк) — абстрактный тип данных, представляющий собой список элементов, организованных по принципу LIFO (англ. last in — first out, «последним пришёл — первым вышел»).
Поэтому первое, на чем бы я хотел заострить внимание, это представление стека в виде вещей из жизни. Первой на ум мне пришла интерпретация в виде стопки книг, где верхняя книга — это вершина.

На самом деле стек можно представить в виде стопки любых предметов будь то стопка листов, тетрадей, рубашек и тому подобное, но пример с книгами я думаю будет самым оптимальным.
Итак, из чего же состоит стек.
Стек состоит из ячеек(в примере — это книги), которые представлены в виде структуры, содержащей какие-либо данные и указатель типа данной структуры на следующий элемент.
Сложно? Не беда, давайте разбираться.
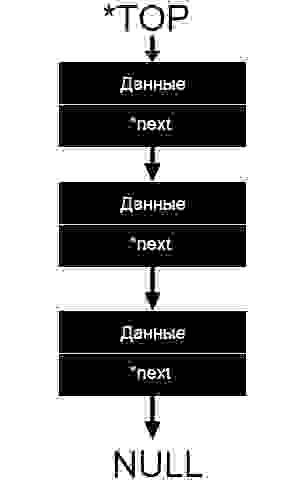
На данной картинке схематично изображен стек. Блок вида «Данные/*next» и есть наша ячейка. *next, как мы видим, указывает на следующий элемент, другими словами указатель *next хранит адрес следующей ячейки. Указатель *TOP указывает на вершину стек, то есть хранит её адрес.
С теорией закончили, перейдем к практике.
Практика
Для начала нам нужно создать структуру, которая будет являться нашей «ячейкой»
Новичкам возможно будет не понятно, зачем наш указатель — типа comp, точнее сказать указатель типа структуры comp. Объясню, для того чтобы указатель *next мог хранить структуру comp, ей нужно обозначить тип этой структуры. Другими словами указать, что будет хранить указатель.
После того как у нас задана «Ячейка», перейдем к созданию функций.
Функции
Функция создания «Стека»/добавления элемента в «Стек»
При добавлении элемента у нас возникнет две ситуации:
Разберем чуть чуть по-подробнее.
Во-первых, почему функция принимает **top, то есть указатель на указатель, для того чтобы вам было наиболее понятно, я оставлю рассмотрение этого вопроса на потом. Во-вторых, по-подробнее поговорим о q->next = *top и о том, что же означает ->.
-> означает то, что грубо говоря, мы заходим в нашу структуру и достаем оттуда элемент этой структуры. В строчке q->next = *top мы из нашей ячейки достаем указатель на следующий элемент *next и заменяем его на указатель, который указывает на вершину стека *top. Другими словами мы проводим связь, от нового элемента к вершине стека. Тут ничего сложного, все как с книгами. Новую книгу мы кладем ровно на вершину стопки, то есть проводим связь от новой книги к вершине стопки книг. После этого новая книга автоматически становится вершиной, так как стек не стопка книг, нам нужно указать, что новый элемент — вершина, для этого пишется: *top = q;.
Функция удаления элемента из «Стека» по данным
Данная функция будет удалять элемент из стека, если число Data ячейки(q->Data) будет равна числу, которое мы сами обозначим.
Здесь могут быть такие варианты:
Для лучшего понимания удаления элемента проведем аналогии с уже привычной стопкой книг. Если нам нужно убрать книгу сверху, мы её убираем, а книга под ней становится верхней. Тут то же самое, только в начале мы должны определить, что следующий элемент станет вершиной *top = q->next; и только потом удалить элемент free(q);
Если книга, которую нужно убрать находится между двумя книгами или между книгой и столом, предыдущая книга ляжет на следующую или на стол. Как мы уже поняли, книга у нас-это ячейка, а стол получается это NULL, то есть следующего элемента нет. Получается так же как с книгами, мы обозначаем, что предыдущая ячейка будет связана с последующей prev->next = q->next;, стоит отметить что prev->next может равняться как ячейке, так и нулю, в случае если q->next = NULL, то есть ячейки нет(книга ляжет на стол), после этого мы очищаем ячейку free(q).
Так же стоит отметить, что если не провести данную связь, участок ячеек, который лежит после удаленной ячейки станет недоступным, так как потеряется та самая связь, которая соединяет одну ячейку с другой и данный участок просто затеряется в памяти
Функция вывода данных стека на экран
Самая простая функция:
Здесь я думаю все понятно, хочу сказать лишь то, что q нужно воспринимать как бегунок, он бегает по всем ячейкам от вершины, куда мы его установили вначале: *q = top;, до последнего элемента.
Главная функция
Хорошо, основные функции по работе со стеком мы записали, вызываем.
Посмотрим код:
Вернемся к тому, почему же в функцию мы передавали указатель на указатель вершины. Дело в том, что если бы мы ввели в функцию только указатель на вершину, то «Стек» создавался и изменялся только внутри функции, в главной функции вершина бы как была, так и оставалась NULL. Передавая указатель на указатель мы изменяем вершину *top в главной функции. Получается если функция изменяет стек, нужно передавать в нее вершину указателем на указатель, так у нас было в функции s_push,s_delete_key. В функции s_print «Стек» не должен изменяться, поэтому мы передаем просто указатель на вершину.
Вместо цифр 1,2,3,4,5 можно так-же использовать переменные типа int.
Заключение
Полный код программы:
Так как в стек элементы постоянно добавляются на вершину, выводиться элементы будут в обратном порядке
В заключение хотелось бы поблагодарить за уделенное моей статье время, я очень надеюсь что данный материал помог некоторым начинающим программистам понять, что такое «Стек», как им пользоваться и в дальнейшем у них больше не возникнет проблем. Пишите в комментариях свое мнение, а так же о том, как мне улучшить свои статьи в будущем. Спасибо за внимание.
Алгоритмы и структуры данных для начинающих: стеки и очереди

В предыдущих частях мы рассматривали базовые структуры данных, которые, по сути, являлись надстройками над массивом. В этой статье мы добавим к коллекциям простые операции и посмотрим, как это повлияет на их возможности.
Стек — это коллекция, элементы которой получают по принципу «последний вошел, первый вышел» (Last-In-First-Out или LIFO). Это значит, что мы будем иметь доступ только к последнему добавленному элементу.

Наиболее часто встречающаяся аналогия для объяснения стека — стопка тарелок. Вне зависимости от того, сколько тарелок в стопке, мы всегда можем снять верхнюю. Чистые тарелки точно так же кладутся на верх стопки, и мы всегда будем первой брать ту тарелку, которая была положена последней.

Если мы положим, например, красную тарелку, затем синюю, а затем зеленую, то сначала надо будет снять зеленую, потом синюю, и, наконец, красную. Главное, что надо запомнить — тарелки всегда ставятся и на верх стопки. Когда кто-то берет тарелку, он также снимает ее сверху. Получается, что тарелки разбираются в порядке, обратном тому, в котором ставились.
Теперь, когда мы понимаем, как работает стек, введем несколько терминов. Операция добавления элемента на стек называется «push», удаления — «pop». Последний добавленный элемент называется верхушкой стека, или «top», и его можно посмотреть с помощью операции «peek». Давайте теперь посмотрим на заготовку класса, реализующего стек.
Класс Stack
Метод Push
Поскольку мы используем связный список для хранения элементов, можно просто добавить новый в конец списка.
Метод Pop
Push добавляет элементы в конец списка, поэтому забирать их будет также с конца. В случае, если список пуст, будет выбрасываться исключение.
Метод Peek
Метод Count
Зачем нам знать, сколько элементов находится в стеке, если мы все равно не имеем к ним доступа? С помощью этого поля мы можем проверить, есть ли элементы на стеке или он пуст. Это очень полезно, учитывая, что метод Pop кидает исключение.
Пример: калькулятор в обратной польской записи
Классический пример использования стека — калькулятор в обратной польской, или постфиксной, записи. В ней оператор записывается после своих операндов. То есть, мы пишем:
Другими словами, вместо «4 + 2» мы запишем «4 2 +». Если вам интересно происхождение обратной польской записи и ее названия, вы можете узнать об этом на Википедии или в поисковике.
То, как вычисляется обратная польская запись и почему стек так полезен при ее использовании, хорошо видно из следующего алгоритма:
То есть, для выражения «4 2 +» действия будут следующие:
В конце на стеке окажется одно значение — 6.
Очередь
Очереди очень похожи на стеки. Они также не дают доступа к произвольному элементу, но, в отличие от стека, элементы кладутся (enqueue) и забираются (dequeue) с разных концов. Такой метод называется «первый вошел, первый вышел» (First-In-First-Out или FIFO). То есть забирать элементы из очереди мы будем в том же порядке, что и клали. Как реальная очередь или конвейер.
Очереди часто используются в программах для реализации буфера, в который можно положить элемент для последующей обработки, сохраняя порядок поступления. Например, если база данных поддерживает только одно соединение, можно использовать очередь потоков, которые будут, как ни странно, ждать своей очереди на доступ к БД.
Класс Queue
Метод Enqueue
Новые элементы очереди можно добавлять как в начало списка, так и в конец. Важно только, чтобы элементы доставались с противоположного края. В данной реализации мы будем добавлять новые элементы в начало внутреннего списка.
Метод Dequeue
Поскольку мы вставляем элементы в начало списка, убирать мы их будем с конца. Если список пуст, кидается исключение.
Метод Peek
Метод Count
Двусторонняя очередь
Двусторонняя очередь (Double-ended queue), или дек (Deque), расширяет поведение очереди. В дек можно добавлять или удалять элементы как с начала, так и с конца очереди. Такое поведение полезно во многих задачах, например, планирование выполнения потоков или реализация других структур данных. Позже мы рассмотрим вариант реализации стека с помощью двусторонней очереди.
Класс Deque
Метод EnqueueFirst
Метод EnqueueLast
Метод DequeueFirst
Метод DequeueLast
Метод PeekFirst
Метод PeekLast
Метод Count
Пример: реализация стека
Двусторонняя очередь часто используется для реализации других структур данных. Давайте посмотрим на пример реализации стека с ее помощью.
У вас, возможно, возник вопрос, зачем реализовывать стек на основе очереди вместо связного списка. Причины две: производительность и повторное использование кода. У связного списка есть накладные расходы на создание узлов и нет гарантии локальности данных: элементы могут быть расположены в любом месте памяти, что вызывает большое количество промахов и падение производительности на уровне процессоров. Более производительная реализация двусторонней очереди требует массива для хранения элементов.
Тем не менее, реализация стека или очереди с помощью массива — непростая задача, но такая реализация двусторонней очереди и использование ее в качестве основы для других структур данных даст нам серьезный плюс к производительности и позволит повторно использовать код. Это снижает стоимость поддержки.
Позже мы посмотрим на вариант очереди с использованием массива, но сначала давайте взглянем на класс стека с использованием двусторонней очереди:
Хранение элементов в массиве
Как уже было упомянуто, у реализации очереди с использованием массива есть свои преимущества. Она выглядит простой, но на самом деле есть ряд нюансов, которые надо учесть.
Давайте посмотрим на проблемы, которые могут возникнуть, и на их решение. Кроме того, нам понадобится информация об увеличении внутреннего массива из прошлой статьи о динамических массивах.
При создании очереди у нее внутри создается массив нулевой длины. Красные буквы «h» и «t» означают указатели _head и _tail соответственно.

Добавляем элемент в начало

Добавляем элемент в конец

Добавляем еще один элемент в начало
Обратите внимание: индекс «головы» очереди перескочил в начало списка. Теперь первый элемент, который будет возвращен при вызове метода DequeueFirst — 0 (индекс 3).

И еще один в конец
Массив заполнен, поэтому при добавлении элемента произойдет следующее:

Добавляем значение в конец расширенного массива
Теперь посмотрим, что происходит при удалении элемента:

Удаляем элемент из начала

Удаляем элемент с конца
Ключевой момент: вне зависимости от вместимости или заполненности внутреннего массива, логически, содержимое очереди — элементы от «головы» до «хвоста» с учетом «закольцованности». Такое поведение также называется «кольцевым буфером».
Теперь давайте посмотрим на реализацию.
Класс Deque (с использованием массива)
Интерфейс очереди на основе массива такой же, как и в случае реализации через связный список. Мы не будем его повторять. Однако, поскольку список был заменен на массив, у нас добавились новые поля — сам массив, его размер и указатели на «хвост» и «голову» очереди.
Алгоритм роста
Когда свободное место во внутреннем массиве заканчивается, его необходимо увеличить, скопировать элементы и обновить указатели на «хвост» и «голову». Эта операция производится при необходимости во время добавления элемента. Параметр startingIndex используется, чтобы показать, сколько полей в начале необходимо оставить пустыми (в случае добавления в начало).
Обратите внимание на то, как извлекаются данные, когда приходится переходить в начало массива при проходе от «головы» к «хвосту».
Метод EnqueueFirst
Метод EnqueueLast
Метод DequeueFirst
Метод DequeueLast
Метод PeekFirst
Метод PeekLast
Метод Count
Продолжение следует
Вот мы и закончили четвертую часть нашего цикла статей. В ней мы рассмотрели стеки и очереди. В следующий раз мы перейдем к бинарным деревьям поиска.
Основные принципы программирования: стек и куча

Мы используем всё более продвинутые языки программирования, которые позволяют нам писать меньше кода и получать отличные результаты. За это приходится платить. Поскольку мы всё реже занимаемся низкоуровневыми вещами, нормальным становится то, что многие из нас не вполне понимают, что такое стек и куча, как на самом деле происходит компиляция, в чём разница между статической и динамической типизацией, и т.д. Я не говорю, что все программисты не знают об этих понятиях — я лишь считаю, что порой стоит возвращаться к таким олдскульным вещам.
Сегодня мы поговорим лишь об одной теме: стек и куча. И стек, и куча относятся к различным местоположениям, где происходит управление памятью, но стратегия этого управления кардинально отличается.
Стек — это область оперативной памяти, которая создаётся для каждого потока. Он работает в порядке LIFO (Last In, First Out), то есть последний добавленный в стек кусок памяти будет первым в очереди на вывод из стека. Каждый раз, когда функция объявляет новую переменную, она добавляется в стек, а когда эта переменная пропадает из области видимости (например, когда функция заканчивается), она автоматически удаляется из стека. Когда стековая переменная освобождается, эта область памяти становится доступной для других стековых переменных.
Из-за такой природы стека управление памятью оказывается весьма логичным и простым для выполнения на ЦП; это приводит к высокой скорости, в особенности потому, что время цикла обновления байта стека очень мало, т.е. этот байт скорее всего привязан к кэшу процессора. Тем не менее, у такой строгой формы управления есть и недостатки. Размер стека — это фиксированная величина, и превышение лимита выделенной на стеке памяти приведёт к переполнению стека. Размер задаётся при создании потока, и у каждой переменной есть максимальный размер, зависящий от типа данных. Это позволяет ограничивать размер некоторых переменных (например, целочисленных), и вынуждает заранее объявлять размер более сложных типов данных (например, массивов), поскольку стек не позволит им изменить его. Кроме того, переменные, расположенные на стеке, всегда являются локальными.
В итоге стек позволяет управлять памятью наиболее эффективным образом — но если вам нужно использовать динамические структуры данных или глобальные переменные, то стоит обратить внимание на кучу.
Куча — это хранилище памяти, также расположенное в ОЗУ, которое допускает динамическое выделение памяти и не работает по принципу стека: это просто склад для ваших переменных. Когда вы выделяете в куче участок памяти для хранения переменной, к ней можно обратиться не только в потоке, но и во всем приложении. Именно так определяются глобальные переменные. По завершении приложения все выделенные участки памяти освобождаются. Размер кучи задаётся при запуске приложения, но, в отличие от стека, он ограничен лишь физически, и это позволяет создавать динамические переменные.
Вы взаимодействуете с кучей посредством ссылок, обычно называемых указателями — это переменные, чьи значения являются адресами других переменных. Создавая указатель, вы указываете на местоположение памяти в куче, что задаёт начальное значение переменной и говорит программе, где получить доступ к этому значению. Из-за динамической природы кучи ЦП не принимает участия в контроле над ней; в языках без сборщика мусора (C, C++) разработчику нужно вручную освобождать участки памяти, которые больше не нужны. Если этого не делать, могут возникнуть утечки и фрагментация памяти, что существенно замедлит работу кучи.
В сравнении со стеком, куча работает медленнее, поскольку переменные разбросаны по памяти, а не сидят на верхушке стека. Некорректное управление памятью в куче приводит к замедлению её работы; тем не менее, это не уменьшает её важности — если вам нужно работать с динамическими или глобальными переменными, пользуйтесь кучей.
Заключение
Вот вы и познакомились с понятиями стека и кучи. Вкратце, стек — это очень быстрое хранилище памяти, работающее по принципу LIFO и управляемое процессором. Но эти преимущества приводят к ограниченному размеру стека и специальному способу получения значений. Для того, чтобы избежать этих ограничений, можно пользоваться кучей — она позволяет создавать динамические и глобальные переменные — но управлять памятью должен либо сборщик мусора, либо сам программист, да и работает куча медленнее.
Что такое стек технологий. Объясняем простыми словами
Стек технологий (от англ. stack — «стопка») — это набор технологий, на основе которых разрабатывается сайт или приложение.
Стек включает в себя языки программирования, фреймворки (программная среда для разработки), системы управления базами данных, компиляторы (переводят текст, написанный на языке программирования, в набор машинных кодов) и так далее.
Выбор конкретного стека зависит от архитектуры проекта, сложности и функциональности сайта, системных требований — какую выбрать операционную систему и систему управления базами данных, какой использовать веб-сервер и язык программирования.
Например, для веб-разработки стек технологий может выглядеть так:
Примеры употребления на «Секрете»
«ИТ-специалисты должны чётко представлять, что ключевое в EdTech — открытость API, возможность интегрироваться с другими платформами, а также использование современного стека технологий».
(Основательница Smart School Pro Елена Игнатьева — о типичных ошибках образовательных стартапов.)
«Если применить подход в лоб и ориентироваться только на цену, то вы рискуете получить команду, которая не даст вам искомых показателей эффективности. К примеру, при выборе рекламного агентства следует обратить внимание на размер и опыт команды, стек используемых технологий, клиентский портфель и отзывы».
(CEO Realweb Partners Эмин Аветисян — об ошибках офлайновых компаний при выходе в онлайн.)
Нюансы
Любое веб-приложение состоит из двух частей — клиентской и серверной. Клиентская сторона охватывает всё, что пользователи могут видеть на экране.
Важнейшие элементы технологического стека в клиентской части:
Серверная часть приложения готовит данные для клиентской части. Здесь придётся выбрать:
Выбранные технологии будут определять функционал продукта и то, можно ли будет его масштабировать в будущем. Также от выбранного стека будут зависеть оплата специалистов и время на разработку.
Если клиент планирует продавать одежду через небольшой онлайн-магазин, ему не понадобятся параллельная обработка больших объёмов данных (noSQL) и механизм распределения нагрузки (load balancing), заточенный на одновременную поддержку 1 млн пользователей. В то же время клиенту, который планирует продавать тысячи товаров в день, не подойдёт решение на базе бесплатного движка сайта (CMS) с дешёвым хостингом.
Разбираемся с управлением памятью в современных языках программирования
Привет, Хабр! Представляю вашему вниманию перевод статьи «Demystifying memory management in modern programming languages» за авторством Deepu K Sasidharan.
В данной серии статей мне бы хотелось развеять завесу мистики над управлением памятью в программном обеспечении (далее по тексту — ПО) и подробно рассмотреть возможности, предоставляемые современными языками программирования. Надеюсь, что мои статьи помогут читателю заглянуть под капот этих языков и узнать для себя нечто новое.
Углублённое изучение концептов управления памятью позволяет писать более эффективное ПО, потому как стиль и практики кодирования оказывают большое влияние на принципы выделения памяти для нужд программы.
Часть 1: Введение в управление памятью
Управление памятью — это целый набор механизмов, которые позволяют контролировать доступ программы к оперативной памяти компьютера. Данная тема является очень важной при разработке ПО и, при этом, вызывает затруднения или же вовсе остаётся черным ящиком для многих программистов.
Для чего используется оперативная память?
Когда программа выполняется в операционный системе компьютера, она нуждается в доступе к оперативной памяти (RAM) для того, чтобы:
Стек используется для статичного выделения памяти. Он организован по принципу «последним пришёл — первым вышел» (LIFO). Можно представить стек как стопку книг — разрешено взаимодействовать только с самой верхней книгой: прочитать её или положить на неё новую.

Использование стека в JavaScript. Объекты хранятся в куче и доступны по ссылкам, которые хранятся в стеке. Тут можно посмотреть в видеоформате
Куча используется для динамического выделения памяти, однако, в отличие от стека, данные в куче первым делом требуется найти с помощью «оглавления». Можно представить, что куча это такая большая многоуровневая библиотека, в которой, следуя определённым инструкциям, можно найти необходимую книгу.
Почему эффективное управление памятью важно?
В отличие от жёстких дисков, оперативная память весьма ограниченна (хотя и жёсткие диски, безусловно, тоже не безграничны). Если программа потребляет память не высвобождая её, то, в конечном итоге, она поглотит все доступные резервы и попытается выйти за пределы памяти. Тогда она просто упадет сама, или, что ещё драматичнее, обрушит операционную систему. Следовательно, весьма нежелательно относиться легкомысленно к манипуляциям с памятью при разработке ПО.
Различные подходы
Современные языки программирования стараются максимально упростить работу с памятью и снять с разработчиков часть головной боли. И хотя некоторые почтенные языки всё ещё требуют ручного управления, большинство всё же предоставляет более изящные автоматические подходы. Порой в языке используется сразу несколько подходов к управлению памятью, а иногда разработчику даже доступен выбор какой из вариантов будет эффективнее конкретно для его задач (хороший пример — C++). Перейдём к краткому обзору различных подходов.
Ручное управление памятью
Язык не предоставляет механизмов для автоматического управления памятью. Выделение и освобождение памяти для создаваемых объектов остаётся полностью на совести разработчика. Пример такого языка — C. Он предоставляет ряд методов (malloc, realloc, calloc и free) для управления памятью — разработчик должен использовать их для выделения и освобождения памяти в своей программе. Этот подход требует большой аккуратности и внимательности. Так же он является в особенности сложным для новичков.
Сборщик мусора
Сборка мусора — это процесс автоматического управления памятью в куче, который заключается в поиске неиспользующихся участков памяти, которые ранее были заняты под нужды программы. Это один из наиболее популярных вариантов механизма для управления памятью в современных языках программирования. Подпрограмма сборки мусора обычно запускается в заранее определённые интервалы времени и бывает, что её запуск совпадает с ресурсозатратными процессами, в результате чего происходит задержка в работе приложения. JVM (Java/Scala/Groovy/Kotlin), JavaScript, Python, C#, Golang, OCaml и Ruby — вот примеры популярных языков, в которых используется сборщик мусора.
Получение ресурса есть инициализация (RAII)
RAII — это программная идиома в ООП, смысл которой заключается в том, что выделяемая для объекта область памяти строго привязывается к его времени существования. Память выделяется в конструкторе и освобождается в деструкторе. Данный подход был впервые реализован в C++, а так же используется в Ada и Rust.
Автоматический подсчёт ссылок (ARC)
Данный подход весьма похож на сборку мусора с подсчётом ссылок, однако, вместо запуска процесса подсчёта в определённые интервалы времени, инструкции выделения и освобождения памяти вставляются на этапе компиляции прямо в байт-код. Когда же счётчик ссылок достигает нуля, память освобождается как часть нормального потока выполнения программы.
Автоматический подсчёт ссылок всё так же не позволяет обрабатывать циклические ссылки и требует от разработчика использования специальных ключевых слов для дополнительной обработки таких ситуаций. ARC является одной из особенностей транслятора Clang, поэтому присутствует в языках Objective-C и Swift. Так же автоматический подсчет ссылок доступен для использования в Rust и новых стандартах C++ при помощи умных указателей.
Владение
Это сочетание RAII с концепцией владения, когда каждое значение в памяти должно иметь только одну переменную-владельца. Когда владелец уходит из области выполнения, память сразу же освобождается. Можно сказать, что это примерно как подсчёт ссылок на этапе компиляции. Данный подход используется в Rust и при этом я не смог найти ни одного другого языка, который бы использовал подобный механизм. 
В данной статье были рассмотрены основные концепции в сфере управления памятью. Каждый язык программирования использует собственные реализации этих подходов и оптимизированные для различных задач алгоритмы. В следующих частях, мы подробнее рассмотрим решения для управления памятью в популярных языках.
Читайте так же другие части серии:
Ссылки
Вы можете подписаться на автора статьи в Twitter и на LinkedIn.
Для чего нужны стеки?
Когда я узнал, что такое стек, мне стало интересно его практическое применение. Оказалось, что чаще всего эта структура используется для имплементации операции “Отмена” ( то есть, ⌘+ Z или Ctrl+ Z).
Чтобы понять, как это работает, разберемся с определением стека.
Что такое стек?
Стек — список элементов, который может быть изменён лишь с одной стороны, называющейся вершиной стека.

Представьте приспособление для раздачи тарелок, в котором тарелки стоят в стопке. Новые тарелки можно добавлять только поверх уже имеющихся, а брать можно лишь сверху. Таким образом, чем позже тарелку положат в стопку, тем раньше её оттуда возьмут. В рамках структур данных это называется LIFO-принципом (последним пришёл — первым ушёл).
Если использовать терминологию, то стек поддерживает операции добавления ( push) и удаления ( pop) элементов на его вершине.

Зачем использовать стек для отмены?
Потому что обычно мы хотим отменить последнее действие.
Стек позволяет добавлять элементы к его вершине и удалять тот элемент, который был последним.
Что произойдёт, если ни одно действие не будет отменено? Стек ведь станет огромным!
Верно. Если не удалять элементы из стека отмены, то есть не использовать операцию отмены, то он станет очень большим. Именно поэтому такие приложения, как Adobe Photoshop, с увеличением времени работы над файлом используют всё больше и больше оперативной памяти. Стек отмены хранит все действия, произведённые над файлом, в памяти до тех пор, пока вы не сохраните и не закроете файл.
Имплементация стека
Стек можно реализовать, используя либо связные списки, либо массивы. Я приведу пример реализации стека на обеих структурах на Python и расскажу о плюсах и минусах каждой.
Стек на связном списке:
Стек на массиве:
Что лучше?
В коде я указал сложность каждой из операций, используя “О” большое. Как видите, имплементации мало чем отличаются.
Однако есть некоторые нюансы, которые стоит учесть.

Массив
Это непрерывный блок памяти. Из-за этого при маленьком размере стека массив будет занимать лишнее место. Ещё один недостаток в том, что каждый раз при увеличении размера массива придётся копировать все уже существующие элементы в новую ячейку памяти.
Связный список
Он состоит из отдельных блоков в памяти и может увеличиваться бесконечно. Поэтому, с одной стороны, имплементация стека с использованием этой структуры немного лучше с точки зрения сложности алгоритма. С другой стороны, каждый элемент должен хранить адреса предыдущего и следующего элемента, что требует больше памяти.
Заключение
Так как динамический массив увеличивается в два раза при заполнении очереди, необходимость выделить дополнительную память будет возникать всё реже и реже. Кроме того, так как указатели не занимают много места, дополнительные данные в связных списках не критичны.
Как видим, между этими двумя реализациями стека практически нет различий — используйте ту, что нравится вам.
Стек: что это такое и применение

Один из важных терминов в программировании – стек (английское «stack»). В переводе это слово означает «стопка, куча, штабель».
Термин указывает на то, для чего предназначена эта структура в IT технологиях и как она работает.
Без знания способа сохранения и использования информации нельзя создать компьютерную программу, пройти по цепочке весь технологический процесс без сбоев.
Что такое стек (Stack)
Абстрактную структуру сохранения данных «стек» создают по принципу заталкивания и выталкивания информации (puch и pop).
В некоторых языках программирования стеком называют любую структуру для хранения элементов. Но использовать сложенные в стопку данные можно только по правилу LIFO, сначала последние, а в конце – те, что попали сначала.

Особенностью стека является то, что:
После использования элемента из стека, он исчезает, уступая место следующему в очереди. Стеки могут освобождаться полностью, когда все элементы по порядку выполнят свою функцию.
Как и где используют
В современных компьютерах стеки поддерживают функцию вызова подпрограмм. В специальных ячейках сохраняется точки возврата для каждой части программы.
После вызова данные могут вернуться в стек, который содержится в оперативной памяти компьютера.
Расположенные в разных стеках локальные данные подпрограмм не мешают работать друг другу. При параллельном использовании элементов происходят общие процессы запуска программ, приложений.

Практикуется хранить в «стопках» данные. Тогда легче работать с информацией, найти нужный элемент среди разветвленной системы однотипных данных.
Советуют использовать хранилища данных, чтобы быстрее найти инструмент для создания подпрограммы, приложения. Даже новичку под силу будет справиться со сложными типами информации.
В программировании используют стек технологий. Без него нельзя создать сайт или разработать компьютерную игру.
Набор инструментов для IT-технологий хранится в определенной «стопке». Каждому программисту важно уметь подобрать необходимый для работы стек.
Эффективность будущих программ зависит от инструментов, используемых для их создания. При этом элементы последовательно должны располагаться в стеках.
Применять стеки можно в математике при работе с числами. Они эффективны при создании алгоритмов, как простых, так и сложных.
Типы стеков
Программисты в работе используют два вида стеков. Один из них связан с возможностью сохранить точки вызова программы при переходе на другой фрагмент кода. Это стек вызовов.

Анализом разветвленных однотипных данных можно с помощью другой структуры. Оба типа близки друг с другом по принципам работы, различаясь лишь нюансами использования.
Стек вызовов
Все вызванные функции используются по порядку. Сначала вынимается помещенная последней. И так по порядку до текущей точки выполнения. При этом после использования функция из стека удаляется.

Используя такую структуру в работе, можно сохранить в ней адрес, куда надо вернуться после выхода из функции вызова. В сегменте хранилища остаются копии тех регистров, к которым необходимо возвратиться.
Как только функции вызова выполнены, эта часть удаляется из общей стопки. Так освобождается память компьютера для других локальных данных.
Нельзя, чтобы вложенных в хранилище вызовов было много, когда функция «А» вызывает функцию «В», после следующую – «С» и так далее. Переполненные ячейки приведут к сбою в работе компьютера.
Стек данных
Этот тип структуры используется, когда надо:
Принцип работы стека данных: кладем первым – берем в последнюю очередь.

Простой системой хранения данных, стеком, пользоваться легко. Как базовая структура данных он применим в создании сложных и простых программ, используемых в технологическом производстве.
Преимущество в использовании этой структуры в том, что выделение памяти здесь происходит быстро. Функция, находясь внутри стопки, не исчезает. К ней можно обратиться в нужное время. После извлечения она уничтожается.
Минусом использования является то, что места в хранилище мало. Для сложных действий понадобятся другие структуры.
Стека или стек – инструмент художника-керамиста, детальный обзор

Название этого инструмента произошло от английского слова «steck», что означает палка. Внешне этот инструмент выглядит, как изящная лопаточка, с рабочей поверхностью с одной или обеих сторон, которые могут иметь вид лопаточки, зубчиков, конуса, петли, шарика, иглы или еще чего-либо.
Художнику- керамисту для работы кроме глины и «золотых» рук нужны еще некоторые рабочие инструменты. Это гончарный круг, турнетка, лезвия, струны, скребки, шпатели, гребешки, молды, штампы, каттеры, фольга, наждачная бумага, ножницы и многое другое.
Среди них свое важное место занимают стеки.
Стеки – это общее понятие широкой группы инструментов, которые используются художником-керамистом для декоративной отделки и моделирования своей работы.
Для чего нужны стеки
Новичок в гончарном деле запросто может спросить, а зачем нужен этот инструмент, можно и пальцами все прочувствовать и выполнить практически любую операцию с глиной. Это будет заблуждением.
Опытный мастер без доли сомнения опровергнет такие мысли и ответит, что нет в данной работе необходимости вновь изобретать велосипед, и придумывать, как выполнить тот или иной элемент пальцем или процарапать ногтем, если есть стека.

Эти инструменты проверены временем и с каждым годом только усовершенствуются. Поэтому ни у одного мастера, который работает с глиной не встанет вопрос, нужно ли приобретать стеки. Однозначно нужно.
Работа с глиной значительно упрощается, когда под рукой есть удобный инструмент. Совершать различные манипуляции с глиной этими ножечками и палочками намного удобнее, чем без них.
Кстати, работать стеками можно не только по глине, но и с пластилином, мастикой и любым другим пластичным материалом.
Стеки применяют для отделки изделия как с внешней, та и с внутренней стороны. Им удобно проводить мелкие работы. При помощи стеки легче придать нужную форму изделию при работе как вручную, так и на гончарном круге. Стек применяется для подрезания изделия и сверху и снизу. С его помощью можно легко убрать излишки глины с изделия. Стеком процарапывают узоры, линии, бороздки.
Стеки максимально помогают передать все тонкости изображения с большей точностью.
Из какого материала изготавливаются стеки
В давние времена, когда стеки изготавливали из слоновой кости или пальмового дерева, их стоимость была очень высокой.
В настоящее время этот инструмент изготавливается из различного материала. Это может быть дерево (яблоня, бук, самшит), силикон, металл, кость или пластик. Их стоимость вполне доступная.

Отдайте предпочтение качественному материалу, который прослужит у вас долгие годы.

Разновидности стеков
Стеки могут быть и односторонними, и двусторонними. В среднем они имеют длину около 20 см.
Форма ручки у всех стеков, как правило, цилиндрическая. Это тоже имеет свое предназначение.
Всегда можно раскатать материал или придать ему нужную форму при помощи именно цилиндрической ручки этого инструмента.
Диаметр цилиндра стека так же различен. Для работы с мелкими деталями используются и стеки с маленьким диаметром ручки, а при работе с крупными деталями – крупные стеки.
История возникновения стеков
Своими корнями стеки уходят в далекое прошлое.
Считается, что слово стека имеет итальянские корни.

В 1910 году вышел в свет словарь, составленный русским переводчиком и педагогом Чудиновым А. Н.. Это словарь иностранных слов, вошедших в русскую речь. В нем дается такое определение стеке. Стека – это лопаточка, употребляемая скульптурами при лепке.
Развеем мифы о стеках
Миф 1. Если купить много таких приспособлений, то точно все получится
Опытные художники-керамисты рекомендуют приобретать стеки в зависимости от характера вашей работы не набором, а поштучно. Кому то удобно работать одним универсальным инструментом, кто-то обзаводится полным набором и использует при этом каждую. Кому то по душе дерево, а кому то пластик.
Такой выбор каждый делает индивидуально. Нет единого ответа, на вопрос, а сколько же стеков должно быть у художника – керамиста.
Одно очевидно точно, чтобы стать хорошим художником-керамистом нужна практика и расположение души к своему делу, а не количество оборудования.

Миф 2. Если купить точно такой же стек или набор, как у знакомого мастера, тогда все получится с первого раза.
Давайте смотреть на мир реалистичным взглядом. Если что- то подошло вашему знакомому, это совсем не означает, что вам это тоже понравится. Кто-то работает только деревянными стеками и ругает силиконовые, кто-то имеет металлические и ругает деревянные.
Все эти инструменты имеют одну особенность — подбираются они индивидуально в соответствии с вашими навыками и спецификой работы.
Поэтому не нужно стремиться приобретать все, что есть у соседа, нужно искать свой вариант.
5 шагов для выбора стека технологий для вашего проекта
Перед началом любого проекта по разработке программного обеспечения важно выбрать для него правильный технологический стек, что часто бывает непростой задачей. Проекты могут быть разного размера и сложности, включая сторонние интеграции и т. д. Это могут быть веб-приложения, мобильные, кросс-платформенные и даже настольные приложения. Некоторым проектам требуется удобный и интерактивный пользовательский интерфейс, в то время как другие нацелены на быстрое выполнение, но простоту использования. Все зависит от целей, которые преследует ваш бизнес. Поэтому, прежде чем писать какой-либо код, вам необходимо тщательно рассмотреть требования вашего проекта. На рынке существует множество языков программирования, технологий, фреймворков и инструментов, и выбор неправильного стека может привести к серьезным последствиям для проекта и даже бизнеса. Плохая производительность, безопасность, масштабируемость и плохой пользовательский интерфейс — вот лишь некоторые из них.
Что такое технологический стек?
Технический стек — это набор технологий, используемых для создания программного проекта. Это комбинация языков программирования, фреймворков, библиотек, стороннего программного обеспечения и инструментов, используемых разработчиками.
Приложения состоят из двух программных компонентов: на стороне клиента и на стороне сервера, также называемых интерфейсом и сервером. Каждый уровень приложения строится с использованием вышеупомянутых функций, создавая стек.
В таблице ниже показаны слои, включенные в общий стек технологий.

Некоторые популярные технологические стеки
Сегодня существует множество технологий, сред и инструментов, которые разработчики объединяют для создания надежных, легко масштабируемых веб-приложений. Например, Facebook разработан с использованием комбинации фреймворков и языков, включая JavaScript, React, HTML, CSS, PHP.
Стек технологий может варьироваться в зависимости от размера проекта, его сложности и других факторов. Итак, как определиться со стеком технологий?
Ниже приведены несколько распространенных технологических стеков на выбор:

Как выбрать технический стек?
Существует множество передних и внутренних технологий на выбор. Для внешнего интерфейса в основном используется JavaScript, но набирают популярность и другие фреймворки, такие как Angular, React.JS, Vue.JS. Java и.Net — типичные примеры для серверной разработки, однако существует множество других языков программирования и фреймворков: PHP, Ruby on Rails, Python, C++, C# и т. д.
Для разных проектов могут потребоваться разные стеки разработки. Проверенные временем технологии могут оказаться неподходящим выбором для некоторых проектов, а новые передовые технологии могут не иметь необходимой функциональности или достаточной поддержки.
Давайте посмотрим на самые популярные технологии, используемые для различных типов проектов.
Для разработки веб-приложений
JavaScript обычно используется в качестве языка сценариев для обеспечения интерактивности веб-страниц. Существует множество библиотек JavaScript, таких как jQuery, Bootstrap и Slick, встроенных в такие платформы, как Angular, Vue.js и React.js, которые используются для улучшения функциональности пользовательского интерфейса.
HTML используется для создания и размещения контента. Все позиционирование и упорядочивание содержимого страницы осуществляется с помощью HTML.
В то время как HTML структурирует контент, CSS используется для форматирования структурированного контента. В основном это включает в себя реализацию шрифтов, цветов, элементов макета, фонового материала и так далее.
Для разработки мобильных приложений
Мобильные технологии можно разделить на нативные, гибридные и кроссплатформенные. Разработка нативных приложений основана на использовании нативных языков программирования, таких как Java и Kotlin для Android, Objective-C и Swift для iOS.
Гибридная разработка основана на использовании таких технологий, как HTML5, JavaScript, Ionic, Cordova, PhoneGap и Xamarin.
В свою очередь, для кроссплатформенной разработки в основном используются React Native, Xamarin и Flutter.
Использование нативного подхода к разработке мобильных приложений сегодня гораздо предпочтительнее, поскольку он обеспечивает больший контроль и упрощает доступ к оборудованию.
В любом случае, выбранная технология должна повышать производительность приложения, позволяя вашей команде разработчиков поддерживать кодовую базу продукта и ускорять итерации.
5 вещей, которые следует учитывать при выборе технологического стека
На самом деле есть несколько ключевых факторов, которые следует учитывать при выборе технического стека для вашего проекта, чтобы быстро сузить количество вариантов.
1. Личные требования
Вам нужно выбрать технологию, основанную на проблеме, которую вы хотите решить. Некоторые вещи лучше делать на одном языке, чем на другом; например, Java отлично подходит для крупномасштабных проектов со сложной бизнес-логикой и независимым от платформы кодом, который должен работать надежно.
Приложения должны создаваться с учетом потребностей пользователей. Подумайте о том, кто будет использовать ваше приложение и как обеспечить им удобство и производительность. Если вы хотите быстро выйти на рынок, вы можете начать с готовой среды, в которой вы можете развернуть свой код и приложения, прежде чем повышать производительность с помощью собственной инфраструктуры. Неразумно тратить много времени и денег, когда у вас небольшая пользовательская база, но как только вы достигнете соответствующего порога размера, вы можете начать думать о производительности.

2. Объем проекта
Небольшие проекты, как правило, выполняются быстрее и не обязательно требуют передовых технологий и фреймворков. Возможно, вам потребуется быстро создать минимально жизнеспособный продукт ( MVP ), представить его клиенту и получить ценную обратную связь. Для достижения этой цели вы можете использовать простые инструменты и платформы с открытым исходным кодом.
Для проектов среднего размера требуется более высокий уровень технологического участия. В зависимости от требований им может понадобиться комбинация нескольких языков программирования и фреймворков. Такие проекты требуют более продвинутых технологий, способных обеспечить более сложные функции.
Социальные сети, такие как Facebook, онлайн-рынки, такие как Amazon, ERP-системы и другие сложные системы разрабатываются с использованием большого количества языков программирования и сред, поскольку требуется множество функций, интеграций, а также большая безопасность и сложность, следовательно, технологический стек должен быть высокий уровень.
3. Время выхода на рынок
Минимально жизнеспособный продукт — отличный вариант, когда нужно как можно быстрее запустить свой проект. Вы можете начать с готовых решений, чтобы свести к минимуму время, затрачиваемое на подготовку к выходу на рынок. Например, вы можете сэкономить много времени, используя инфраструктуру Ruby on Rails, которая предоставляет доступ к набору основных библиотек.
Вы можете добавить функциональность в свое приложение с помощью сторонних интеграций и избежать написания кода с нуля, тем самым сэкономив время на поиске разработчиков. Кроме того, хорошо задокументированные технологии могут значительно облегчить разработку некоторых функций.
4. Масштабируемость
Если вы планируете быстрый рост, не забывайте, что используемый вами стек технологий должен иметь потенциал для достаточного масштабирования. Не каждый технологический стек может иметь достаточный потенциал для достаточного масштабирования. Вы можете масштабироваться либо по вертикали, добавляя новые функции в приложение, либо по горизонтали, добавляя на сервер больше физических машин или процессоров.
5. Безопасность
Крайне важно убедиться, что приложение создано с учетом лучших практик безопасности и снижения угроз. Чтобы устранить распространенные угрозы безопасности, вам может потребоваться выполнить тесты безопасности как на стороне клиента, так и на стороне сервера. Не все технологии одинаково безопасны, поэтому перед началом разработки необходимо тщательно обдумать свой выбор.
Заключение
Для разных мобильных и веб-приложений требуются разные инструменты разработки. К сожалению, единого эффективного стека технологий не существует. Выбирая стек технологий для своего проекта, в первую очередь нужно опираться на требования вашего проекта. Иногда проверенных временем технологий может быть недостаточно, потому что вам нужно быть реалистом и понимать плюсы и минусы каждой из них. Наша команда опытных и профессиональных разработчиков может помочь вам оценить требования вашего проекта и предложить лучшие инструменты для разработки масштабируемого и высокофункционального приложения, которое будет превосходить конкурентов.
11.8 – Стек и куча
Память, которую использует программа, обычно делится на несколько разных областей, называемых сегментами:
В этом уроке мы сосредоточимся в первую очередь на куче и стеке, так как именно там происходит большинство интересных вещей.
Сегмент кучи
Сегмент кучи (также известный как «free store», «свободное хранилище») отслеживает память, используемую для динамического распределения памяти. Мы уже говорили немного о куче в уроке «10.13 – Динамическое распределение памяти с помощью new и delete », поэтому это будет резюме.
В C++, когда вы используете оператор new для выделения памяти, эта память выделяется в сегменте кучи приложения.
Адрес этой памяти возвращается оператором new и затем может быть сохранен в указателе. Вам не нужно беспокоиться о механизме того, где расположена свободная память, и как она выделяется пользователю. Однако стоит знать, что последовательные запросы памяти могут не привести к выделению последовательных адресов памяти!
Когда динамически размещаемая переменная удаляется, память «возвращается» в кучу и затем может быть переназначена по мере получения будущих запросов на выделение. Помните, что удаление указателя не удаляет переменную, а просто возвращает память по соответствующему адресу обратно операционной системе.
У кучи есть достоинства и недостатки:
Стек вызовов
Стек вызовов (обычно называемый «стеком») играет гораздо более интересную роль. Стек вызовов отслеживает все активные функции (те, которые были вызваны, но еще не завершились) от начала программы до текущей точки выполнения и обрабатывает размещение всех параметров функций и локальных переменных.
Стек вызовов реализован в виде структуры данных стек. Итак, прежде чем мы сможем говорить о том, как работает стек вызовов, нам нужно понять, что такое структура данных стек.
Структура данных стек
Структура данных – это программный механизм для организации данных таким образом, чтобы их можно было эффективно использовать. Вы уже видели несколько типов структур данных, таких как массивы и структуры. Обе эти структуры данных предоставляют механизмы для хранения данных и эффективного доступа к ним. Существует множество дополнительных, обычно используемых в программировании структур данных, многие из которых реализованы в стандартной библиотеке, и стек является одной из них.
Представьте себе стопку тарелок в кафетерии. Поскольку каждая тарелка тяжелая и они сложены друг на друга, вы можете сделать только одно из трех:
В компьютерном программировании стек – это структура контейнера данных, который содержит несколько переменных (как массив). Однако в то время как массив позволяет вам получать доступ к элементам и изменять их в любом порядке (так называемый произвольный доступ), стек более ограничен. Операции, которые могут быть выполнены со стеком, соответствуют трем вещам, упомянутым выше:
Стек – это структура типа «последним пришел – первым ушел» (LIFO, «last-in, first-out»). Последний элемент, помещенный в стек, будет первым извлеченным элементом. Если вы положите новую тарелку поверх стопки, первая тарелка, удаленная из стопки, будет тарелкой, которую вы только что положили последней. Последней положена, первой снята. По мере того, как элементы помещаются в стек, стек становится больше – по мере того, как элементы извлекаются, стек становится меньше.
Например, вот короткая последовательность, показывающая, как работает стек при вставке (push) и извлечении (pop) данных:
Аналогия с тарелками – довольно хорошая аналогия того, как работает стек вызовов, но мы можем провести лучшую аналогию. Представьте себе группу почтовых ящиков, сложенных друг на друга. Каждый почтовый ящик может содержать только один элемент, и все почтовые ящики изначально пустые. Кроме того, каждый почтовый ящик прибивается к почтовому ящику под ним, поэтому количество почтовых ящиков не может быть изменено. Если мы не можем изменить количество почтовых ящиков, как мы можем добиться поведения, подобного стеку?
Во-первых, мы используем маркер (например, наклейку), чтобы отслеживать, где находится самый нижний пустой почтовый ящик. Вначале это будет самый нижний почтовый ящик (внизу стопки). Когда мы помещаем элемент в наш стек почтовых ящиков, мы помещаем его в отмеченный почтовый ящик (который является первым пустым почтовым ящиком) и перемещаем маркер на один ящик вверх. Когда мы извлекаем элемент из стека, мы перемещаем маркер на один почтовый ящик вниз так, чтобы он указывал на верхний непустой почтовый ящик, и удаляем элемент из этого почтового ящика. Всё, что ниже маркера, считается «в стеке». Всё, что находится на уровне маркера или над ним, – не в стеке.
Сегмент стека вызовов
Когда встречается вызов функции, эта функция помещается в стек вызовов. Когда текущая функция завершается, эта функция удаляется из стека вызовов. Таким образом, глядя на функции, помещенные в стек вызовов, мы можем увидеть все функции, которые были вызваны для перехода к текущей точке выполнения.
Приведенная выше аналогия с почтовыми ящиками в значительной степени похожа на то, как работает стек вызовов. Сам стек представляет собой блок адресов памяти фиксированного размера. Почтовые ящики – это адреса памяти, а «элементы», которые мы помещаем в стек, называются кадрами (фреймами) стека. Кадр стека отслеживает все данные, связанные с одним вызовом функции. Мы поговорим о стековых кадрах чуть позже. «Маркер» – это регистр (небольшой фрагмент памяти в CPU), известный как указатель стека (иногда сокращенно «SP», «stack pointer»). Указатель стека отслеживает текущее положение вершины стека вызовов.
Мы можем сделать еще одну оптимизацию: когда мы извлекаем элемент из стека вызовов, нам нужно только переместить указатель стека вниз – нам не нужно очищать или обнулять память, используемую извлекаемым кадром стека (эквивалент опустошению почтового ящика). Эта память больше не считается «в стеке» (указатель стека будет по этому адресу или ниже), поэтому к ней не будет доступа. Если мы позже поместим новый кадр стека в ту же самую память, он перезапишет старое значение, которое мы никогда не очищали.
Стек вызовов в действии
Давайте подробнее рассмотрим, как работает стек вызовов. Вот последовательность шагов, которые выполняются при вызове функции:
Когда функция завершается, происходят следующие шаги:
Возвращаемые значения могут обрабатываться разными способами в зависимости от архитектуры компьютера. Некоторые архитектуры включают возвращаемое значение как часть кадра стека. Другие используют регистры CPU.
Обычно неважно знать все подробности о том, как работает стек вызовов. Однако понимание того, что функции помещаются в стек при их вызове и удаляются при возврате, дает вам основы, необходимые для понимания рекурсии, а также некоторые другие концепции, полезные при отладке.
Техническое примечание: на некоторых архитектурах стек вызовов при увеличении изменяет адрес памяти в направлении от нуля. На других он при увеличении изменяет адрес в направлении нуля. Как следствие, новые добавленные кадры стека могут иметь более высокий или более низкий адрес памяти, чем предыдущие.
Пример стека вызовов
Рассмотрим следующее простое приложение:
Стек вызовов в отмеченных точках выглядит следующим образом:
Переполнение стека
Стек имеет ограниченный размер и, следовательно, может содержать только ограниченный объем информации. В Windows размер стека по умолчанию составляет 1 МБ. На некоторых Unix-машинах он может достигать 8 МБ. Если программа попытается поместить в стек слишком много информации, произойдет переполнение стека. Переполнение стека происходит, когда вся память в стеке была выделена – в этом случае дальнейшие размещения начинают переполняться в другие разделы памяти.
Переполнение стека обычно является результатом выделения слишком большого количества переменных в стеке и/или выполнения слишком большого количества вызовов вложенных функций (где функция A вызывает функцию B, вызывающую функцию C, вызывающую функцию D и т.д.). В современных операционных системах переполнение стека обычно приводит к тому, что ваша ОС выдаст нарушение прав доступа и завершит программу.
Вот пример программы, которая может вызвать переполнение стека. Вы можете запустить его на своей системе и посмотреть, как она завершится со сбоем:
Эта программа пытается разместить в стеке огромный массив (примерно 40 МБ). Поскольку стек недостаточно велик для обработки этого массива, размещение массива переполняется в части памяти, которые программе не разрешено использовать.
В Windows (Visual Studio) эта программа дает следующий результат:
-1073741571 – это c0000005 в шестнадцатеричном формате, что представляет собой код ОС Windows для нарушения прав доступа. Обратите внимание, что «hi» никогда не печатается, потому что программа завершается до этого момента.
Вот еще одна программа, которая вызовет переполнение стека, но по другой причине:
У стека есть достоинства и недостатки:
Стэк что это
С тек – наверное, самая простая структура данных, которую мы будем изучать и которой будем постоянно пользоваться. Стек – это структура данных, в которой элементы поддерживают принцип LIFO (“Last in – first out”): последним зашёл – первым вышел. Или первым зашёл – последним вышел.
Стек позволяет хранить элементы и поддерживает, обычно, две базовые операции:
Также часто встречается операция PEEK, которая получает элемент на вершине стека, но не снимает его оттуда.
Стек является одной из базовых структур данных и используется не только в программировании, но и в схемотехнике, и просто в производстве, для реализации технологических процессов и т.д.; стек используется в качестве вспомогательной структуры данных во многих алгоритмах и в других более сложных структурах.
Пусть, например, у нас есть стек чисел. Выполним несколько команд. Изначально стек пуст. Вершина стека – указатель на первый элемент, никуда не указывает. В случае си она может быть равна NULL.
Теперь стек состоит из одного элемента, числа 3. Вершина стека указывает на число 3.
Стек состоит из двух элементов, 5 и 3, при этом вершина стека указывает на 5.
Стек состоит из трёх элементов, вершина стека указывает на 7.
Вернёт значение 7, в стеке останется 5 и 3. Вершина будет указывать на следующий элемент – 5.
Вернёт 5, в стеке останется всего один элемент, 3, на который будет указывать вершина стека.
Вернёт 3, стек станет пуст.
 Последовательное выполнение операций push 3, push 5, push 7, pop, pop, pop
Последовательное выполнение операций push 3, push 5, push 7, pop, pop, pop
Часто сравнивают стек со стопкой тарелок. Чтобы достать следующую тарелку, необходимо снять предыдущие. Вершина стека – это вершина стопки тарелок.
Когда мы будем работать со стеком, возможны две основные и часто встречающиеся ошибки:
Программная реализация
Стек фиксированного размера, построенный на массиве
О тличительная особенность – простота реализации и максимальная скорость выполнения. Такой стек может применяться в том, случае, когда его максимальный размер известен заранее или известно, что он мал.
Сначала определяем максимальный размер массива и тип данных, которые будут в нём храниться:
Теперь сама структура
Здесь переменная size – это количество элементов, и вместе с тем указатель на вершину стека. Вершина будет указывать на следующий элемент массива, в который будет занесено значение.
Кладём новый элемент на стек.
Единственная проблема – можно выйти за пределы массива. Поэтому всегда надо проверять, чтобы не было ошибки Stack overflow:
Аналогично, определим операцию Pop, которая возвращает элемент с вершины и переходит к следующему
И функция peek, возвращающая текущий элемент с вершины
Ещё одно важное замечание – у нас нет функции создания стека, поэтому необходимо вручную обнулять значение size
Вспомогательные функции для печати элементов стека
Заметьте, что в функции печати мы использует int, а не size_t, потому что значение len может стать отрицательным. Функция печатает сначала размер стека, а потом его содержимое, разделяя элементы символом |
Рассмотрим также ситуации, когда есть ошибки использования. Underflow
Динамически растущий стек на массиве
Д инамически растущий стек используется в том случае, когда число элементов может быть значительным и не известно на момент решения задачи. Максимальный размер стека может быть ограничен каким-то числом, либо размером оперативной памяти.
Стек будет состоять из указателя на данные, размера массива (максимального), и числа элементов в массиве. Это число также будет и указывать на вершину.
Для начала понадобится некоторый начальный размер массива, пусть он будет равен 10
Алгоритм работы такой: мы проверяем, не превысило ли значение top значение size. Если значение превышено, то увеличиваем размер массива. Здесь возможно несколько вариантов того, как увеличивать массив. Можно прибавлять число, можно умножать на какое-то значение. Какой из вариантов лучше, зависит от специфики задачи. В нашем случае будем умножать размер на число MULTIPLIER
Максимального размера задавать не будем. Программа будет выпадать при stack overflow или stack underflow. Будем реализовывать тот же интерфейс (pop, push, peek). Кроме того, так как массив динамический, сделаем некоторые вспомогательные функции, чтобы создавать стек, удалять его и чистить.
Во-первых, функции для создания и удаления стека и несколько ошибок
Всё крайне просто и понятно, нет никаких подвохов. Создаём стек с начальной длиной и обнуляем значения.
Теперь напишем вспомогательную функцию изменения размера.
Здесь, заметим, в случае, если не удалось выделить достаточно памяти, будет произведён выход с STACK_OVERFLOW.
Функция push проверяет, вышли ли мы за пределы массива. Если да, то увеличиваем его размер
Функции pop и peek аналогичны тем, которые использовались для массива фиксированного размера
Напишем ещё одну функцию, implode, которая уменьшает массив до размера, равного числу элементов в массиве. Она может быть использована тогда, когда уже известно, что больше элементов вставлено не будет, и память может быть частично освобождена.
Можем использовать в нашем случае
Эта однопоточная реализация стека использует мало обращений к памяти, достаточно проста и универсальна, работает быстро и может быть реализована, при необходимости, за несколько минут. Она используется всегда в дальнейшем, если не указано иное.
У неё есть недостаток, связанный с методом увеличения потребляемой памяти. При умножении в 2 раза (в нашем случае) требуется мало обращений к памяти, но при этом каждое последующее увеличение может привести к ошибке, особенно при маленьком количестве памяти в системе. Если же использовать более щадящий способ выделения памяти (например, каждый раз прибавлять по 10), то число обращений увеличится и скорость упадёт. На сегодня, проблем с размером памяти обычно нет, а менеджеры памяти и сборщики мусора (которых нет в си) работают быстро, так что агрессивное изменение преобладает (на примере, скажем, реализации всей стандартной библиотеки языка Java).
Реализация стека на односвязном списке
Ч то такое односвязный список, будет подробнее рассказано дальше. Коротко: односвязный список состоит из узлов, каждый из которых содержит полезную информацию и ссылку на следующий узел. Последний узел ссылается на NULL.
Никакого максимального и минимального размеров у нас не будет (хотя в общем случае может быть). Каждый новый элемент создаётся заново. Для начала определим структуру узел
Функция вставки первого элемента проста: создаём новый узел. Указатель next кидаем на старый узел. Далее указатель на вершину стека перекидываем на вновь созданный узел. Теперь вершина стека указывает на новый узел.
Функция pop берёт первый элемент (тот, на который указывает вершина), перекидывает указатель на следующий элемент и возвращает первый. Здесь есть два варианта – можно вернуть узел или значение. Если вернём значение, то придётся удалять узел внутри функции
Теперь вместо проверки на длину массива везде используется проверка на равенство NULL вершины стека.
Простая функция peek
Итерирование достаточно интересное. Просто переходим от одного узла к другому, пока не дойдём до конца
И ещё одна проблема – теперь нельзя просто посмотреть размер стека. Нужно пройти от начала до конца и посчитать все элементы. Например, так
Конечно, можно хранить размер отдельно, можно обернуть стек со всеми данными ещё в одну структуру и т.д. Рассмотрим всё это при более подробном изучении списков.
Основы TCP/IP для будущих дилетантов
Предположим, что вы плохо владеете сетевыми технологиями, и даже не знаете элементарных основ. Но вам поставили задачу: в быстрые сроки построить информационную сеть на небольшом предприятии. У вас нет ни времени, ни желания изучать толстые талмуды по проектированию сетей, инструкции по использованию сетевого оборудования и вникать в сетевую безопасность. И, главное, в дальнейшем у вас нет никакого желания становиться профессионалом в этой области. Тогда эта статья для вас.

Вторая часть этой статьи, где рассматривается практическое применение изложенных здесь основ: Заметки о Cisco Catalyst: настройка VLAN, сброс пароля, перепрошивка операционной системы IOS
Понятие о стеке протоколов
Задача — передать информацию от пункта А в пункт В. Её можно передавать непрерывно. Но задача усложняется, если надо передавать информацию между пунктами A B и A C по одному и тому же физическому каналу. Если информация будет передаваться непрерывно, то когда С захочет передать информацию в А — ему придётся дождаться, пока В закончит передачу и освободит канал связи. Такой механизм передачи информации очень неудобен и непрактичен. И для решения этой проблемы было решено разделять информацию на порции.
На получателе эти порции требуется составить в единое целое, получить ту информацию, которая вышла от отправителя. Но на получателе А теперь мы видим порции информации как от В так и от С вперемешку. Значит, к каждой порции надо вписать идентификационный номер, что бы получатель А мог отличить порции информации с В от порций информации с С и собрать эти порции в изначальное сообщение. Очевидно, получатель должен знать, куда и в каком виде отправитель приписал идентификационные данные к исходной порции информации. И для этого они должны разработать определённые правила формирования и написания идентификационной информации. Далее слово «правило» будет заменяться словом «протокол».
Для соответствия запросам современных потребителей, необходимо указывать сразу несколько видов идентификационной информации. А так же требуется защита передаваемых порций информации как от случайных помех (при передаче по линиям связи), так и от умышленных вредительств (взлома). Для этого порция передаваемой информации дополняется значительным количеством специальной, служебной информацией.
В протоколе Ethernet находятся номер сетевого адаптера отправителя (MAC-адрес), номер сетевого адаптера получателя, тип передаваемых данных и непосредственно передаваемые данные. Порция информации, составленная в соответствии с протоколом Ethernet, называется кадром. Считается, что сетевых адаптеров с одинаковым номером не существует. Сетевое оборудование извлекает передаваемые данные из кадра (аппаратно или программно), и производит дальнейшую обработку.
Как правило, извлечённые данные в свою очередь сформированы в соответствии с протоколом IP и имеют другой вид идентификационной информации — ip адрес получателя (число размером в 4 байта), ip адрес отправителя и данные. А так же много другой необходимой служебной информации. Данные, сформированные в соответствии с IP протоколом, называются пакетами.
Далее извлекаются данные из пакета. Но и эти данные, как правило, ещё не являются изначально отправляемыми данными. Этот кусок информации тоже составлен в соответствии определённому протоколу. Наиболее широко используется TCP протокол. В нём содержится такая идентификационная информация, как порт отправителя (число размером в два байта) и порт источника, а так же данные и служебная информация. Извлечённые данные из TCP, как правило, и есть те данные, которые программа, работающая на компьютере В, отправляла «программе-приёмнику» на компьютере A.
Вложность протоколов (в данном случае TCP поверх IP поверх Ethernet) называется стеком протоколов.
ARP: протокол определения адреса
Существуют сети классов A, B, C, D и E. Они различаются по количеству компьютеров и по количеству возможных сетей/подсетей в них. Для простоты, и как наиболее часто встречающийся случай, будем рассматривать лишь сеть класса C, ip-адрес которой начинается на 192.168. Следующее число будет номером подсети, а за ним — номер сетевого оборудования. К примеру, компьютер с ip адресом 192.168.30.110 хочет отправить информацию другому компьютеру с номером 3, находящемуся в той же логической подсети. Это значит, что ip адрес получателя будет такой: 192.168.30.3
Важно понимать, что узел информационной сети — это компьютер, соединённый одним физическим каналом с коммутирующим оборудованием. Т.е. если мы отправим данные с сетевого адаптера «на волю», то у них одна дорога — они выйдут с другого конца витой пары. Мы можем послать совершенно любые данные, сформированные по любому, выдуманному нами правилу, ни указывая ни ip адреса, ни mac адреса ни других атрибутов. И, если этот другой конец присоединён к другому компьютеру, мы можем принять их там и интерпретировать как нам надо. Но если этот другой конец присоединён к коммутатору, то в таком случае пакет информации должен быть сформирован по строго определённым правилам, как бы давая коммутатору указания, что делать дальше с этим пакетом. Если пакет будет сформирован правильно, то коммутатор отправит его дальше, другому компьютеру, как было указано в пакете. После чего коммутатор удалит этот пакет из своей оперативной памяти. Но если пакет был сформирован не правильно, т.е. указания в нём были некорректны, то пакет «умрёт», т.е. коммутатор не будет отсылать его куда либо, а сразу удалит из своей оперативной памяти.
Для передачи информации другому компьютеру, в отправляемом пакете информации надо указать три идентификационных значения — mac адрес, ip адрес и порт. Условно говоря, порт — это номер, который, выдаёт операционная система каждой программе, которая хочет отослать данные в сеть. Ip адрес получателя вводит пользователь, либо программа сама получает его, в зависимости от специфики программы. Остаётся неизвестным mac адрес, т.е. номер сетевого адаптера компьютера получателя. Для получения необходимой данной, отправляется «широковещательный» запрос, составленный по так называемому «протоколу разрешения адресов ARP». Ниже приведена структура ARP пакета.

Сейчас нам не надо знать значения всех полей на приведённой картинке. Остановимся лишь на основных.
В поля записываются ip адрес источника и ip адрес назначения, а так же mac адрес источника.
Поле «адрес назначения Ethernet» заполняется единицами (ff:ff:ff:ff:ff:ff). Такой адрес называется широковещательным, и такой фрейм будер разослан всем «интерфейсам на кабеле», т.е. всем компьютерам, подключённым к коммутатору.
Коммутатор, получив такой широковещательный фрейм, отправляет его всем компьютерам сети, как бы обращаясь ко всем с вопросом: «если Вы владелец этого ip адреса (ip адреса назначения), пожалуйста сообщите мне Ваш mac адрес». Когда другой компьютер получает такой ARP запрос, он сверяет ip адрес назначения со своим собственным. И если он совпадает, то компьютер, на место единиц вставляет свой mac адрес, меняет местами ip и mac адреса источника и назначения, изменяет некоторую служебную информацию и отсылает пакет обратно коммутатору, а тот обратно — изначальному компьютеру, инициатору ARP запроса.
Таким образом ваш компьютер узнаёт mac адрес другого компьютера, которому вы хотите отправить данные. Если в сети находится сразу несколько компьютеров, отвечающих на этот ARP запрос, то мы получаем «конфликт ip адресов». В таком случае необходимо изменить ip адрес на компьютерах, что бы в сети не было одинаковых ip адресов.
Построение сетей
Задача построения сетей
На практике, как правило, требуется построить сети, число компьютеров в которой будет не менее ста. И кроме функций файлообмена, наша сеть должна быть безопасной и простой в управлении. Таким образом, при построении сети, можно выделить три требования:
Существует большое множество приложений, программных модулей и сервисов, которые, для своей работы отправляют в сеть широковещательные сообщения. Описанный в пункте ARP: протокол определения адреса лишь один из множества ШС, отправляемый вашим компьютером в сеть. Например, когда вы заходите в «Сетевое окружение» (ОС Windows), ваш компьютер посылает ещё несколько ШС со специальной информацией, сформированной по протоколу NetBios, что бы просканировать сеть на наличие компьютеров, находящихся в той же рабочей группе. После чего ОС рисует найденные компьютеры в окне «Сетевое окружение» и вы их видите.
Так же стоит заметить, что во время процесса сканирования той или иной программой, ваш компьютер отсылает ни одно широковещательное сообщение, а несколько, к примеру для того, что бы установить с удалёнными компьютерами виртуальные сессии или ещё для каких либо системных нужд, вызванных проблемами программной реализации этого приложения. Таким образом, каждый компьютер в сети для взаимодействия с другими компьютерами вынужден посылать множество различных ШС, тем самым загружая канал связи не нужной конечному пользователю информацией. Как показывает практика, в больших сетях широковещательные сообщения могут составить значительную часть трафика, тем самым замедляя видимую для пользователя работу сети.
Виртуальные локальные сети
Для решения первой и третьей проблем, а так же в помощь решения второй проблемы, повсеместно используют механизм разбиения локальной сети на более маленькие сети, как бы отдельные локальные сети (Virtual Local Area Network). Грубо говоря, VLAN — это список портов на коммутаторе, принадлежащих одной сети. «Одной» в том смысле, что другой VLAN будет содержать список портов, принадлежащих другой сети.
Фактически, создание двух VLAN-ов на одном коммутаторе эквивалентно покупке двух коммутаторов, т.е. создание двух VLAN-ов — это всё равно, что один коммутатор разделить на два. Таким образом происходит разбиение сети из ста компьютеров на более маленькие сети, из 5-20 компьютеров — как правило именно такое количество соответствует физическому местонахождению компьютеров по надобности файлообмена.
VLAN-ы, теория
Возможно, фраза «администратору достаточно удалить порт из одного VLAN-а и добавить в другой» могла оказаться непонятной, поэтому поясню её подробнее. Порт в данном случае — это не номер, выдаваемый ОС приложению, как было рассказано в пункте Стек протоколов, а гнездо (место) куда можно присоединить (вставить) коннектор формата RJ-45. Такой коннектор (т.е. наконечник к проводу) прикрепляется к обоим концам 8-ми жильного провода, называемого «витая пара». На рисунке изображён коммутатор Cisco Catalyst 2950C-24 на 24 порта:

Как было сказано в пункте ARP: протокол определения адреса каждый компьютер соединён с сетью одним физическим каналом. Т.е. к коммутатору на 24 порта можно присоединить 24 компьютера. Витая пара физически пронизывает все помещения предприятия — все 24 провода от этого коммутатора тянутся в разные кабинеты. Пусть, к примеру, 17 проводов идут и подсоединяются к 17-ти компьютерам в аудитории, 4 провода идут в кабинет спецотдела и оставшиеся 3 провода идут в только что отремонтированный, новый кабинет бухгалтерии. И бухгалтера Лиду, за особые заслуги, перевели в этот самый кабинет.
Как сказано выше, VLAN можно представлять в виде списка принадлежащих сети портов. К примеру, на нашем коммутаторе было три VLAN-а, т.е. три списка, хранящиеся во flash-памяти коммутатора. В одном списке были записаны цифры 1, 2, 3… 17, в другом 18, 19, 20, 21 и в третьем 22, 23 и 24. Лидин компьютер раньше был присоединён к 20-ому порту. И вот она перешла в другой кабинет. Перетащили её старый компьютер в новый кабинет, или она села за новый компьютер — без разницы. Главное, что её компьютер присоединили витой парой, другой конец которой вставлен в порт 23 нашего коммутатора. И для того, что бы она со своего нового места могла по прежнему пересылать файлы своим коллегам, администратор должен удалить из второго списка число 20 и добавить число 23. Замечу, что один порт может принадлежать только одному VLAN-у, но мы нарушим это правило в конце этого пункта.
Замечу так же, что при смене членства порта в VLAN, администратору нет никакой нужды «перетыкать» провода в коммутаторе. Более того, ему даже не надо вставать с места. Потому что компьютер администратора присоединён к 22-ому порту, с помощью чего он может управлять коммутатором удалённо. Конечно, благодаря специальным настройкам, о которых будет рассказано позже, лишь администратор может управлять коммутатором. О том, как настраивать VLAN-ы, читайте в пункте VLAN-ы, практика [в следующей статье].
Как вы, наверное, заметили, изначально (в пункте Построение сетей) я говорил, что компьютеров в нашей сети будет не менее 100. Но к коммутатору можно присоединить лишь 24 компьютера. Конечно, есть коммутаторы с большим количеством портов. Но компьютеров в корпоративной сети/сети предприятия всё равно больше. И для соединения бесконечно большого числа компьютеров в сеть, соединяют между собой коммутаторы по так называемому транк-порту (trunk). При настройки коммутатора, любой из 24-портов можно определить как транк-порт. И транк-портов на коммутаторе может быть любое количество (но разумно делать не более двух). Если один из портов определён как trunk, то коммутатор формирует всю пришедшую на него информацию в особые пакеты, по протоколу ISL или 802.1Q, и отправляет эти пакеты на транк-порт.
Всю пришедшую информацию — имеется в виду, всю информацию, что пришла на него с остальных портов. А протокол 802.1Q вставляется в стек протоколов между Ethernet и тем протоколом, по которому были сформированные данные, что несёт этот кадр.
В данном примере, как вы, наверное, заметили, администратор сидит в одном кабинете вместе с Лидой, т.к. витая пора от портов 22, 23 и 24 ведёт в один и тот же кабинет. 24-ый порт настроен как транк-порт. А сам коммутатор стоит в подсобном помещении, рядом со старым кабинетом бухгалтеров и с аудиторией, в которой 17 компьютеров.
Витая пара, которая идёт от 24-ого порта в кабинет к администратору, подключается к ещё одному коммутатору, который в свою очередь, подключён к роутеру, о котором будет рассказано в следующих главах. Другие коммутаторы, которые соединяют другие 75 компьютеров и стоят в других подсобных помещениях предприятия — все они имеют, как правило, один транк-порт, соединённый витой парой или по оптоволокну с главным коммутатором, что стоит в кабинете с администратором.
Выше было сказано, что иногда разумно делать два транк-порта. Второй транк-порт в таком случае используется для анализа сетевого трафика.
Примерно так выглядело построение сетей больших предприятий во времена коммутатора Cisco Catalyst 1900. Вы, наверное, заметили два больших неудобства таких сетей. Во первых, использование транк-порта вызывает некоторые сложности и создаёт лишнюю работу при конфигурировании оборудования. А во вторых, и в самых главных — предположим, что наши «как бы сети» бухгалтеров, экономистов и диспетчеров хотят иметь одну на троих базу данных. Они хотят, что бы та же бухгалтерша смогла увидеть изменения в базе, которые сделала экономистка или диспетчер пару минут назад. Для этого нам надо сделать сервер, который будет доступен всем трём сетям.
Как говорилось в середине этого пункта, порт может находиться лишь в одном VLAN-е. И это действительно так, однако, лишь для коммутаторов серии Cisco Catalyst 1900 и старше и у некоторых младших моделей, таких как Cisco Catalyst 2950. У остальных коммутаторов, в частности Cisco Catalyst 2900XL это правило можно нарушить. При настройке портов в таких коммутаторах, каждый пор может иметь пять режимов работы: Static Access, Multi-VLAN, Dynamic Access, ISL Trunk и 802.1Q Trunk. Второй режим работы именно то, что нам нужно для выше поставленной задачи — дать доступ к серверу сразу с трёх сетей, т.е. сделать сервер принадлежащим к трём сетям одновременно. Так же это называется пересечением или таггированием VLAN-ов. В таком случае схема подключения может быть такой:

Продолжение следует
Вторая часть этой статьи, где рассматривается практическое применение изложенных здесь основ: Заметки о Cisco Catalyst: настройка VLAN, сброс пароля, перепрошивка операционной системы IOS