Swagger что это
Swagger что это
Документация по веб-API ASP.NET Core с использованием Swagger (OpenAPI)
Swagger (OpenAPI) — это не зависящая от языка спецификация для описания REST API. Она позволяет компьютерам и пользователям лучше понять возможности REST API без прямого доступа к исходному коду. Ее основные цели:
OpenAPI и Swagger
Проект Swagger был передан OpenAPI Initiative в 2015 году и с тех пор называется OpenAPI. Оба имени взаимозаменяемы. Но «OpenAPI» относится к спецификации. «Swagger» относится к семейству с открытым исходным кодом и коммерческим продуктам от SmartBear, которые работают со спецификацией OpenAPI. Последующие продукты с открытым кодом, такие как OpenAPIGenerator, также относятся к семейству Swagger несмотря на то, что они не выпускаются SmartBear.
Спецификация OpenAPI (openapi.json)
Пользовательский интерфейс Swagger
Пользовательский интерфейс Swagger обеспечивает пользовательский веб-интерфейс, предоставляющий сведения о службе с использованием созданной спецификации OpenAPI. Swashbuckle и NSwag включают встроенную версию пользовательского интерфейса Swagger, чтобы его можно было разместить в приложении ASP.NET Core, используя вызов регистрации ПО промежуточного слоя. Пользовательский веб-интерфейс выглядит следующим образом:


На снимках экрана используется пользовательский интерфейс Swagger версии 2. Пример версии 3 см. в разделе Пример Petstore.
Документирование #микросервисов

Оригинальная статья является размышления на тему почему документация в мире микросервисов критично необходима и как ее можно создавать и публиковать используя swagger. Пошаговой инструкцией по настройке она точно не является.
Вступление
Несколько месяцев назад один из наших бекенд разработчиков интернов получил задачу — разработать новый простой сервис. Сервис должен был генерировать емайл отчеты о пользовательской активности. В задаче не было ничего сложного и у интерна все получилось. Однако через несколько недель мы захотели включить в отчет более детальную информацию о некоторых конкретных пользователях. Я решил обновить этот сервис самостоятельно. “Просто получи данные из нашего пользовательского сервиса и вставь их в емайл”, — думал тогда я.
На это у меня ушло несколько часов, и даже пришлось подключить двоих других разработчиков только для того, чтобы найти правильные REST endpoints и необходимые мен структуры. “Никогда больше. Должен быть более правильный метод это сделать…”, — крутилось у меня в голове все это время.
Микросервисная архитектура подразумевает набор самостоятельных сервисов, которые общаются друг с другом, а для конечного пользователя выглядит как единая программа. Один из самых популярных протоколов для обмена сообщениями между микросервисами — это REST. Проблема в том, что REST не является само описательным протоколом. Это значит, что клиент должен знать конкретную комбинацию URL, HTTP метода и формата ответа. В некоторых случаях необходимо также знать также формат тела запроса. Обычно реализация REST интерфейса базируется на общих принципах и традициях, принятых в вашей организации. В любом случае, REST endpoints всегда должны быть описаны в одном конкретном документе, доступном для всех остальных разработчиков. О том, как и где хранить, мы поговорим чуть позже, а пока давайте обсудим основы — формат документации.
Swagger

Документацию должно быть легко читать, писать, парсить, генерировать, исправлять, обновлять и прочее. Решение должно быть настолько простым, чтобы даже самые ленивые разработчики им пользовались. После небольшого исследования мы в Ataccama решили использовать Swagger для документирования наших REST APIs.
Swagger — это фреймворк и спецификация для определения REST APIs в формате, дружественном к пользователю и компьютеру (в нашем случае JSON или YAML). Но Swagger — это не просто спецификация. Основная его мощь заключается в дополнительных инструментах. Для Swagger существует огромное количество бесплатных утилит (как официальных, так и написанных сообществом), которые могут сделать жизнь (вашу и ваших коллег) немного более счастливой. Вы можете установить все это на свои собственные сервера и посмотреть, как это работает — например, попробовать работу с браузером документов или Swagger онлайн-редактором.
Как мы это делаем?
Если вы тоже думаете, что Swagger — это здорово, то читайте дальше. Сейчас будет немного подробностей о том, как мы используем его в Ataccama, в таинственном мире микросервисов.
У каждого микросервиса в определенной папке лежит файл со Swagger описанием и хранится это все прямо в git-репозитории. Описания могут быть как сгенерированы при помощи Swagger generator, так и записаны туда вручную. Прелесть заключается в том, что для записи определений используются JSON и YAML форматы. Их легко распарсить, и во время сборки проекта мы можем автоматически проверять соответствие REST endpoints и документации. Несоответствия будут генерировать предупреждения, и тем самым стимулировать разработчика поддерживать документацию в актуальном состоянии.
Хранение документации внутри микросервиса позволяет нам отображать её в любое время прямо из этого микросервиса в процессе работы. Это помогает тестировать и отлаживать REST endpoints в процессе развертывания сервиса на собственной машине. А ещё у Swagger есть инструмент с веб интерфейсом для тестирования REST endpoints.
Поскольку каждый микросервис предоставляет собственную документацию, мы можем настроить специальную задачу для Дженкинса (или любого другого CI сервера), которая сгенерирует полную документацию для всего проекта. Эта задача собирает Swagger файлы из всех микросервисов, производит некоторые минимальные модификации (дедупликация, удаление ненужных атрибутов) и на выходе генерирует единый Swagger файл, содержащий полную актуальную информацию для всего проекта.
Публикация документации.
Централизованное хранение и редактирование документации — это только первый шаг. Следующий — сделать ее доступной для всех разработчиков, тестеров и остальных заинтересованных людей в компании. И Swagger UI — это именно то, что вам для этого понадобится. При помощи небольшой JavaScript библиотеки Swagger UI генерирует HTML элементы для всех ваших REST endpoints, которые далее можно упорядочивать с помощью HTML разметки.

По умолчанию Swagger UI подгружает собственный Swagger файл с примерами. Все остальные API должны быть загружены вручную. Но конфигурация занимает всего несколько секунд.
Теперь у нас есть сгенерированная документация в читабельном виде. Время отправить её на сервер.
Некоторое время назад мы в Ataccama начали использовать Docker, и поэтому подумали, а почему бы не упаковать всю документацию в отдельный докер контейнер, загрузить его в наш частный репозитарий, а потом задеплоить в докер кластер? Дженкинc может это сделать буквально за несколько секунд. Как результат мы всегда имеем обновленную документацию доступную к просмотру через браузер.
Кроме того, использование докера дает нам еще несколько преимуществ:
Каждый разработчик может просто загрузить документацию и запустить её на собственном компьютере всего одной командой.
И это только начало.
Это только общая идея того как мы генерируем документацию для REST endpoints и публикуем ее при помощи докера для наших микросервисов. К сожалению, синхронный REST это не все, что нам надо документировать в этом лабиринте микросервисов. В какой-то момент хочется перейти на более продвинутые системы общения, на асинхронный обмен сообщениями, очереди, подписки на события и прочее.
Несмотря на расхваливание Swaggerа мы все еще не нашли удобного метода документирования асинхронных сообщений. По факту, в Атаккаме мы недовольны нашим текущим решением и все еще пытаемся найти что-нибудь более простое и красивое для описания очередей сообщений и их структур. Если у вас есть идеи как это можно сделать лучше, пишите в комментариях. Любые интересные идеи приветствуются.
Автор Lubos Palisek
Backend software developer in Ataccama. Greedy for new cloud based technologies and ideas.
Ataccama Corporation – международная компания, производитель программного обеспечения, специализирующаяся в области решений по управлению качеством данных, управлению мастер-данными и управления данными предприятия (data governance), решениями которого уже воспользовались более 250 компаний, начиная от предприятий среднего размера и заканчивая международными компаниями из различных отраслей.
Все ваши вопросы и рекомендации с удовольствием переведу автору.
Swagger
Swagger — это набор инструментов, который позволяет автоматически описывать API на основе его кода. API — интерфейс для связи между разными программными продуктами, и у каждого проекта он свой. Документация, автоматически созданная через Swagger, облегчает понимание API для компьютеров и людей.

На основе кода или набора правил Swagger автоматически генерирует документацию в формате JSON-файла. Ее можно встроить на страницу сайта или в приложение, чтобы пользователи могли интерактивно знакомиться с документацией, можно отправлять клиентам — сгенерировать такое описание намного быстрее, чем написать с нуля.
Swagger иногда называют фреймворком. Фреймворк — набор инструментов и правил, которым по сути является Swagger. Часть инструментов доступна бесплатно и имеет открытый исходный код, еще часть — платная и предназначена для компаний.
Название читается как «Сваггер». Альтернативное название — OpenAPI. Так называется спецификация, по которой работает Swagger, но иногда название применяют при описании продукта.
Кто пользуется Swagger
Для чего нужен Swagger
Документация API. Основное назначение Swagger — автоматически генерировать документацию, понятную для людей и для машин. Соответственно, чаще всего он применяется, чтобы быстро и легко документировать код API. Обычно используется в связке с архитектурой RESTful API.
Разработка API. Swagger используется, когда, например, разработчику нужно свериться с документацией при доработке продукта, или он хочет сгенерировать ее из кода. Иногда требуется обратный процесс — генерация кода на основе документации, возможная благодаря компоненту Swagger Codegen. Мы поговорим о нем ниже.
Взаимодействие с API. Возможность генерации кода используется при взаимодействии с API других проектов. Swagger Codegen может генерировать код для конечного клиента, который будет работать с API, — это удобно, когда стоит задача сэкономить время.
Два способа создания документации
На основе кода. Инструмент «читает» код API и на его основе генерирует документацию. Такой способ считается более простым, потому что от разработчика не требуется знать спецификацию и писать что-то помимо самого кода. Но его рекомендуют применять только тогда, когда документация нужна срочно, — потому что второй способ позволяет создавать более подробные и понятные описания.
На основе спецификации. Второй способ — использовать спецификацию Swagger, которая называется OpenAPI. Он сложнее, потому что необходимо знать язык формальных правил — на нем нужно описать сущности кода, чтобы инструмент понял написанное и сгенерировал документ. Но этот подход более правильный, потому что такая документация более понятна и человекочитаема. Писать необходимо с помощью форматов JSON или YAML либо в специальном редакторе Swagger Editor — о нем мы подробнее расскажем ниже.
Что такое спецификация Swagger
Swagger работает на основе спецификации OpenAPI 3.0. Раньше она тоже называлась Swagger, но ее переименовали в 2015 году, когда проект передали другой команде разработчиков.
Спецификация — набор правил, которые описывают, как должна выглядеть и работать та или иная технология. Это теоретический «каркас» для будущего программного проекта. На его основе пишется код, реализация, которая работает по описанной в спецификации логике. Соответственно, OpenAPI — это набор правил и стандартов для описания API.
Работа происходит так: специалист описывает код с помощью формальных текстовых правил. Swagger «понимает» написанное и на его основе создает человекопонятную интерактивную документацию.
Как устроена спецификация
В спецификации есть основные сущности, каждая из которых включает в себя более мелкие. С их помощью происходит описание документации. Синтаксис примерно такой:
Объект может представлять собой, например, имя пользователя, название модуля, ссылку или что-то еще. Основных объектов восемь; остальные вложены в них:
Четыре компонента Swagger
Swagger можно разделить на четыре основных компонента. Есть и другие, которые относятся к коммерческой версии, но о них говорят реже и использую не так часто.
Swagger Core. Это ядро Swagger — программная реализация спецификации OpenAPI 3.0. Выше мы говорили, что на основе спецификации пишется код, который реализует описанную в ней логику. В случае со Swagger это и есть Core.
Swagger Core написан на языке Java, поэтому для его корректной работы понадобится Java не старше версии 8.0. Также нужны будут фреймворк Apache Maven 3.0.3 или новее и JSON-процессор Jackson 2.4.5 или новее.
После установки в проект Swagger Core позволит автоматически генерировать документацию на основе кода при сборке проекта. Правила генерации описываются с помощью специальных команд — аннотаций: они размещаются в коде и показывают, что именно представляет собой та или иная его часть. Это один из минусов способа генерации на основе кода — он становится очень массивным и громоздким из-за обилия аннотаций.
Swagger UI. UI расшифровывается как user interface, графический интерфейс. Этот компонент делает работу со Swagger нагляднее и понятнее: он визуализирует документацию, представляет ее в более простом для понимания виде. Более того, она становится не просто визуальной, но интерактивной, с ней можно взаимодействовать — без написания кода, просто с помощью интерфейса.
С помощью Swagger UI можно создавать и отправлять запросы разных типов, можно быстро перемещаться по документации и тестировать проект. Визуальный интерфейс можно встроить в приложение или разместить на странице, его поддерживают все браузеры — поэтому им пользуются в том числе для того, чтобы разъяснять пользователям и клиентам особенности взаимодействия с API.
Swagger Codegen. Мы уже упоминали этот компонент выше — он может генерировать код на основе правил. Автоматически сгенерированный код решает только шаблонные задачи, так что Codegen не заменяет программиста, но серьезно облегчает ему задачу. Он позволяет избавиться от части рутины.
Swagger Codegen генерирует:
Компонент поддерживает множество языков: Java и ряд фреймворков для него, C++ и C#, Kotlin, Node.js, Scala, Haskell. Для генерации клиентских библиотек API также поддерживаются Groovy и Bash, а для заглушек серверов — PHP, Python, Ruby и Rust. Генератор документации поддерживает HTML и Confluence — вики-проект для внутренних баз знаний.
Swagger Editor. Это редактор спецификаций: он позволяет просматривать написанные правила, изменять и дополнять их. Существуют онлайн-версия редактора и версия для скачивания. Выглядит он как разделенное на две части окно: слева по спецификации пишется код описания API, справа генерируется визуальный интерфейс Swagger UI. Интерфейс одновременно интерактивен и функционален: можно, не выходя из редактора, посмотреть, как будет выглядеть документация. Там же можно протестировать ее и сразу внести изменения.
Редактор автоматически проверяет то, что пользователь написал в левой части, и указывает на ошибки в использовании спецификации. Если они есть, это покажется в режиме реального времени.
Плюсы использования Swagger
Минусы Swagger
Некоторые разработчики не любят Swagger, считают его бесполезным или избыточным, только усложняющим работу с API. Есть мнение, что он делает менее наглядной коммуникацию между бэкендерами, отвечающими за серверную часть, и фронтендерами, создающими клиентский интерфейс. Такое действительно возможно: Swagger генерирует большое количество кода, и одной части команды разработчиков кажется, будто этого достаточно, тогда как другой тяжело в этом разобраться. Документация не получается наглядной, и это проблема.
Вторая причина, по которой Swagger критикуют, — отсутствие подробной разметки. Для создания документации многие используют такие инструменты, как Markdown. Они позволяют выделять смысловые части, создавать сноски на разные части документа, добавлять якорные ссылки. В Swagger таких возможностей нет. Ведь созданная с ним документация «изнутри» представляет собой JSON-файл, а этот формат в принципе не подразумевает средств выделения текста.
Как начать работать со Swagger
Редактором Swagger можно пользоваться онлайн. Также можно скачать его: все бесплатные компоненты проекта доступны на GitHub и на официальном сайте. Для корректной работы понадобится Java и несколько фреймворков — мы описали технологии выше.
Есть проект SwaggerHub, облачная платформа, которая позволяет использовать возможности Swagger онлайн. Для доступа к ней предлагается три тарифных плана. План Free — бесплатный; платные планы Teams и Enterprise предназначены для компаний. Так что начинающий разработчик может пользоваться проектом и не платить за него.
Подробнее узнать про инструменты создания документации и познакомиться с правилами коммерческой разработки вы можете на курсах.
Swagger – умная документация вашего RESTful web-API — обзор Junior back-end developer-а для новичков

Предисловие
Команда, в которой я сделала свои первые шаги на поприще написания промышленного кода, занималась разработкой удобного API к функциональности программного продукта на C# (для удобства назовем его, скажем, буквой E), существовавшего уже много лет и зарекомендовавшего себя на рынке с весьма положительной стороны. И здесь вроде бы у юного падавана пока не должно возникать вопросов, однако же представим себе, что ранее вы, скорей всего, конечно, писали собственные web-API, но вряд ли для широкой аудитории, а значит жили по принципу «Сам создал – сам пользуюсь», и если вдруг кого-то бы заинтересовала функциональность вашего API, то вы, наверное, кинули бы ему pdf-файл с подробной инструкцией (по крайней мере я бы сделала именно так). «Где посмотреть функционал апи» — спросила я тимлида ожидая получить ссылку на текстовый документ. «Загляни в Swagger» — ответил он.
Постой, как так получается, что продукт успешно функционирует уже давно, а API вы к нему пишете только сейчас?
Все верно, как такового удобного публичного API у E до недавнего времени не существовало. Фактически вся работа происходила через web-интерфейс, а back-end состоял из множества внутренних микросервисов, с которыми невозможно было интегрироваться извне без четкого понимания внутренней бизнес-логики, уж не говоря о том, что сами они на значительную долю состояли из легаси. Нужно было обратить внимание на клиентов, которые хотят непосредственно напрямую взаимодействовать с сервером, а значит предоставить им красивое и удобное API. Что для этого потребуется? Все, о чем было написано чуть раньше – самим взять и наладить работу со всеми внутренними микросервисами, а также обеспечить удобную и красивую документацию, сделав это красиво, понятно, и самое главное – коммерчески успешно.
Хорошо, так что же есть такое Swagger и в чем его полезность миру?
По сути Swagger – это фреймворк для спецификации RESTful API. Его прелесть заключается в том, что он дает возможность не только интерактивно просматривать спецификацию, но и отправлять запросы – так называемый Swagger UI, вот так это выглядит:

Как мы видим – полное описание методов, включая модели, коды ответов, параметры запроса – в общем, наглядно.
И как это работает?
Отличное руководство для внедрения Swagger в ASP.NET Core
с нуля есть вот в этой этой статье.
Идея в конфигурации отображения с помощью специальных аннотаций у методов API, вот пример:


Swagger Codegen
Если очень хочется, то можно сгенерировать непосредственно клиента или сервер по спецификации API Swagger, для этого нужен генератор кода Swagger-Codegen. Описание из документации, думаю, пояснять не требуется:
This is the Swagger Codegen project, which allows generation of API client libraries (SDK generation), server stubs and documentation automatically given an OpenAPI Spec. Currently, the following languages/frameworks are supported:
Прочая информация, в частности инструкция по использованию, представлена здесь:
Общая информация
Swagger (OpenAPI 3.0)
Всем привет. Это мой первый пост на Хабре и я хочу поделиться с вами своим опытом в исследовании нового для себя фреймворка.
Мне предоставился момент выбрать тему и подготовить презентацию для своей команды. Вдохновившись спикером Евгений Маренковым, я решил выбрать данную тему. В процессе подготовки, я облазил много статей и репозиториев, чтобы компактно и эффективно донести нужную информацию.
Сейчас хочу поделиться ею в надежде, что кому-то она поможет в изучение Swagger (OpenApi 3.0)
Введение
Я на 99% уверен у многих из вас были проблемы с поиском документации для нужного вам контроллера. Многие если и находили ее быстро, но в конечном итоге оказывалось что она работает не так как описано в документации, либо вообще его уже нет.
Сегодня я вам докажу, что есть способы поддерживать документацию в актуальном виде и в этом мне будет помогать Open Source framework от компании SmartBear под названием Swagger, а с 2016 года он получил новое обновление и стал называться OpenAPI Specification.
Также возможно сгенерировать непосредственно клиента или сервер по спецификации API Swagger, для этого понадобится Swagger Codegen.
Основные подходы
Swagger имеет два подхода к написанию документации:
Документация пишется на основании вашего кода.
Данный подход позиционируется как «очень просто». Нам достаточно добавить несколько зависимостей в проект, добавить конфигурацию и уже мы будем иметь нужную документацию, хоть и не настолько описанной какою мы хотели.
Код проекта становится не очень читабельным от обилия аннотаций и описания в них.
Вся документация будет вписана в нашем коде (все контроллеры и модели превращаются в некий Java Swagger Code)
Подход не советуют использовать, если есть возможности, но его очень просто интегрировать.
Документация пишется отдельно от кода.
Данный подход требует знать синтаксис Swagger Specification.
Документация пишется либо в YAML/JSON файле, либо в редакторе Swagger Editor.
Swagger Tools
Swagger или OpenAPI framework состоит из 4 основных компонентов:
Теперь давайте поговорим о каждом компоненте отдельно.
Swagger Core
Для того что бы использовать Swagger Core во все орудие, требуется:
Java 8 или больше
Apache Maven 3.0.3 или больше
Jackson 2.4.5 или больше
Что бы внедрить его в проект, достаточно добавить две зависимости:
Также можно настроить maven плагин, что бы наша документация при сборке проект генерировалсь в YAML
Дальше нам необходимо добавить конфиг в проект.
Для конфигурации Swagger необходимо добавить два бина. Где нам нужно будет описать название приложения, версию нашего API, так же можно добавить контакт разработчика, который отвечает за данные API.
После добавления нужных нам зависимостей, у нас появятся новые аннотация с помощью которых можно документировать наш код.
Вот некоторые из них:
Swagger Codegen
В настоящее время поддерживаются следующие языки / фреймворки:
Java (Jersey1.x, Jersey2.x, OkHttp, Retrofit1.x, Retrofit2.x, Feign, RestTemplate, RESTEasy, Vertx, Google API Client Library for Java, Rest-assured)
Scala (akka, http4s, swagger-async-httpclient)
Node.js (ES5, ES6, AngularJS with Google Closure Compiler annotations)
Haskell (http-client, Servant)
C# (.net 2.0, 3.5 or later)
C++ (cpprest, Qt5, Tizen)
Java (MSF4J, Spring, Undertow, JAX-RS: CDI, CXF, Inflector, RestEasy, Play Framework, PKMST)
C# (ASP.NET Core, NancyFx)
C++ (Pistache, Restbed)
Ruby (Sinatra, Rails5)
API documentation generators:
Что бы внедрить его в проект, достаточно добавить зависимость, если используете Swagger:
и если используете OpenApi 3.0, то:
Можно настроить maven плагин, и уже на процессе сборки мы можем сгенерировать нужный для нас клиент либо мок сервиса.
Также все это можно выполнить с помощью командной строки.
Запустив джарник codegen и задав команду help можно увидеть команды, которые предоставляет нам Swagger Codegen:
Для нас самые нужные команды это validate, которая быстро проверять на валидность спецификации и generate, с помощью которой мы можем сгенерировать Client на языке Java
Swagger UI
Вот пример Swagger UI который визуализирует документацию для моего pet-project:


Нажавши на кнопку «Try it out», мы можем выполнить запрос за сервер и получить ответ от него:

Swagger Editor
На верхнем уровне в спецификации OpenAPI 3.0 существует восемь объектов. Внутри этих верхнеуровневых объектов есть много вложенных объектов, но на верхнем уровне есть только следующие объекты:
Для работы над документацией со спецификацией используется онлайн-редактор Swagger Редактор Swagger имеет разделенное представление: слева пишем код спецификации, а справа видим полнофункциональный дисплей Swagger UI. Можно даже отправлять запросы из интерфейса Swagger в этом редакторе.
Редактор Swagger проверит контент в режиме реального времени, и укажет ошибки валидации, во время кодирования документа спецификации. Не стоит беспокоиться об ошибках, если отсутствуют X-метки в коде, над которым идет работа.
Первым и важным свойством для документации это openapi. В объекте указывается версия спецификации OpenAPI. Для Swagger спецификации это свойство будет swagger:
Объект info содержит основную информацию о вашем API,включая заголовок, описание, версию, ссылку на лицензию, ссылку на обслуживания и контактную информацию. Многие из этих свойство являются не обязательными.
Объект components уникален среди других объектов в спецификации OpenAPI. В components хранятся переиспользуемые определения, которые могут появляться в нескольких местах в документе спецификации. В нашем сценарии документации API мы будем хранить детали для объектов parameters и responses в объекте components
Conclusions
Документация стала более понятней для бизнес юзера так и для техническим юзерам (Swagger UI, Open Specifiation)
Можно проверять насколько совместимы изменения. Можно настраивать это в дженкинсе
Нет ни какой лишней документации к коде, код отдельно, документация отдельно
Swagger: что это такое и как с ним работать?




Для взаимодействия с любой программой используется API. Он может быть закрытым для внешнего взаимодействия или открытым. В любом случае разработчикам следует уделять внимание его спецификации. Это в том числе нужно для того, чтобы новые члены команды быстрее и проще вовлекались в проект.

«Купи мне истребитель». Сбор средств для Воздушных Сил ВСУ
Ручное формирование документации — утомительное занятие. Поэтому разработчики придумали Swagger. С его помощью на основе кода можно автоматически сгенерировать спецификации API.
Что такое Swagger?
Swagger — это набор инструментов, которые помогают описывать API. Благодаря ему пользователи и машины лучше понимают возможности REST API без доступа к коду. С помощью Swagger можно быстро создать документацию и отправить ее другим разработчикам или клиентам.
В 2015 году проект Swagger сделали открытым и передали OpenAPI Initiative. Теперь сама спецификация называется OpenAPI. Swagger — инструментарий для работы с OpenAPI, название которого используется в коммерческих и некоммерческих продуктах. Если кто-то называет саму спецификацию Swagger, то это не совсем верно.
Документ спецификации OpenAPI использует YAML, но также может быть написан в формате JSON. Сам по себе он является объектом JSON.
Основные подходы
Swagger предлагает два основных подхода к генерированию документации:
Первый подход проще. Мы добавляем зависимости в проект, конфигурируем настройки и получаем документацию. Сам код из-за этого может стать менее читабельным, документация тоже не будет идеальной. Но задача минимум решена — код задокументирован.
Чтобы пользоваться вторым подходом, нужно знать синтаксис Swagger. Описания можно готовить в формате YAML/JSON. Можно упростить эту задачу, используя Swagger Editor. Конечно, второй подход позволяет сделать документацию более качественной и кастомной для каждого конкретного проекта и его особенностей, к тому же все не так сложно как может показаться, это потребует минимальных дополнительных усилий.
Swagger Core
Это Java-реализация спецификации. Для ее использования потребуется:
Для его внедрения в проект используются две зависимости. Вот примеры:
Другой способ — настроить maven-плагин. Тогда описания при сборке проекта будут генерироваться в файл YAML. Пример:
После настройки конфигурации мы получим аннотации, которые можно использовать для документирования кода.
| Аннотация | Использование |
| @Operation | Для описания операции или метода HTTP |
| @Parameter | Для представления одного параметра в операции |
| @RequestBody | Для представления тела запроса в операции |
| @ApiResponse | Для представления тела ответа в операции |
| @Tag | Для представления тегов операции или определения OpenAPI |
| @Server | Для представления серверов операции или определения OpenAPI |
| @Callback | Для описания набора запросов |
| @Link | Для представления ссылки времени разработки для ответа |
| @Schema | Для определения входных и выходных данных |
| @ArraySchema | Для определения входных и выходных данных для типов массивов |
| @Content | Для представления схемы и примеров для мультимедиа |
| @Hidden | Для скрытия ресурса, операции или свойства |
Swagger Codegen
Это проект для автоматического генерирования клиентских библиотек API, заглушек сервера и документации. Поддерживает большое количество технологий. Посмотреть полный список можно в репозитории Swagger Codegen на GitHub.
В этом же репозитории вы найдёте примеры того, как можно генерировать документацию, используя различные шаблоны.
| API клиенты | ActionScript, Ada, Apex, Bash, C#, C++, Clojure, Dart, Elixir, Elm, Eiffel, Erlang, Go, Groovy, Haskell, Java (Jersey1.x, Jersey2.x, OkHttp, Retrofit1.x, Retrofit2.x, Feign, RestTemplate, RESTEasy, Vertx, Google API Client Library for Java, Rest-assured), Kotlin, Lua, Node.js, Objective-C, Perl, PHP, PowerShell, Python, R, Ruby, Rust (rust, rust-server), Scala (akka, http4s, swagger-async-httpclient), Swift (2.x, 3.x, 4.x, 5.x), Typescript |
| Заглушки | Ada, C# (ASP.NET Core, NancyFx), C++ (Pistache, Restbed), Erlang, Go, Haskell (Servant), Java (MSF4J, Spring, Undertow, JAX-RS: CDI, CXF, Inflector, RestEasy, Play Framework, PKMST), Kotlin, PHP (Lumen, Slim, Silex, Symfony, Zend Expressive), Python (Flask), NodeJS, Ruby (Sinatra, Rails5), Rust (rust-server), Scala (Finch, Lagom, Scalatra) |
| Генераторы документации | HTML, Confluence Wiki |
| Файлы конфигурации | Apache2 |
| Другое | JMeter для нагрузочного тестирования |
Плюсы Swagger Codegen:
Чтобы добавить Swagger Codegen в проект, используйте зависимость:
Как и в случае с Swagger Core, можно настроить maven-плагин для генерации клиента или мок-сервера.
Swagger Codegen предоставляет следующие команды:
Swagger/OpenAPI Specification как основа для ваших приёмочных тестов
Человеческая жизнь слишком коротка, чтобы тратить ее на интеграцию и документацию. С помощью контрактов и кодогенераторов можно сократить рутинные операции и переписывание кода, обеспечить недосягаемое иными способами покрытие и достигнуть невыразимой чёткости бытия тестировщиков, разработчиков и систем.
Я занимаюсь автоматизацией тестирования в Яндексе с 2013 года. Из них более четырёх лет автоматизирую тестирование REST API-сервисов. На Heisenbug я рассказал об использовании OpenAPI-спецификации как основы для приёмочных тестов, а также о том, как легко поддерживать автотесты на огромное количество REST API-сервисов и добавлять автотесты на новые проекты.

Под катом — видеозапись и расшифровка моего доклада. Примеры из доклада есть на GitHub.
Как всё устроено
Яндекс.Вертикали — это три больших сервиса: Яндекс.Недвижимость, Яндекс.Работа и Auto.ru. Они имеют микросервисную архитектуру. Большинство бэкендов — это REST API-сервисы с разной кодовой базой, которые активно развиваются. К тому же у каждого REST API может быть несколько версий, которые также необходимо тестировать, чтобы старые клиенты не ломались при глобальных изменениях.
Команда
Наша команда — это четыре-пять человек. Это люди, которые занимаются инструментами для автоматизации, инфраструктурой, пишут и встраивают автотесты в процесс разработки. Я занимаюсь также мобильным направлением: инфраструктурой для автоматизации тестирования под iOS и Android. В автотестах на клиенты мы активно используем моки, поэтому мы не можем позволить себе тестировать наш REST API через клиент.
С каким опытом мы подошли к нашей задаче
Три года назад картина у нас была следующая. У нас были автоматизаторы тестирования, которые имели достаточно стандартный подход и писали автотесты на Apache HTTP-клиенте. У нас были ручные тестировщики, которые не могли писать достаточно сложный код, поэтому использовали инструменты в виде Postman и писали автотесты, используя JavaScript. И у нас были разработчики, которые писали в основном юнит-тесты, интеграционные тесты. А некоторые вообще не понимали, зачем нужны автотесты, так как считали, что ничего не сломается.
Получалось, что все члены команды имели разные подходы к автоматизации тестирования. К тому же есть ещё одна важная проблема — наши REST API активно развиваются. Это означает, что при новых релизах в наших сервисах нам нужно править тестовый клиент. По факту у нас происходит гонка нашего тестового клиента и REST API. Наши клиенты устаревают очень быстро. Скажем так, у нас есть несколько десятков REST API и несколько десятков тестовых клиентов, которые нужно поддерживать. И это адский труд, который отнимает огромное количество времени и вообще не имеет никакого отношения к автоматизации тестирования.
Таким образом, у нас было очень много автотестов сомнительного качества. Они были понятны только тем, кто их пишет, тестовые клиенты моментально устаревали, а поддерживать их было некому. И главное, разработка не участвовала в тестировании.
В связи с этим мы сформировали определённые требования к автотестам:
Об эволюции автотестов на REST API
Необходимо понимать, с каким опытом мы пришли к этой задаче. Давайте поговорим об эволюции автотестов, которую мы прошли. Изначально мы писали автотесты на Apache HTTP client. Поняв, что дублируем много кода и он очень громоздкий, мы написали свою обвязку над HTTP client-ом. Это немного сокращало наши труды. Когда появились специализированные инструменты для автоматизации и появился REST Assured, мы начали его использовать. Потом мы осознали, что его тоже неудобно использовать, и написали свою обвязку над REST Assured. Всё это была эра клиента.
В какой-то момент мы поняли, что очень часто дублируем bean-ы для реквестов, для респонсов и решили их генерировать из JSON Schema. Это оказалось очень удобно: у нас переиспользуется код. Код упростился, и нам это очень понравилось. Стало ясно, что можно генерировать не только bean-ы, но и из них генерировать assertion-ы и получать типизированные assertion-ы для этих bean-ов.
Позже мы поняли, что можно генерировать не только bean-ны, assertion-ы, но ещё и тестовый клиент. Мы стали генерировать клиент на основе RAML-спецификации. Это тоже экономило много времени и делало клиент единообразным. У нас уменьшалось время внедрения людей в новый проект автотестов. Затем мы решили не генерировать bean-ы, а сразу брать их напрямую из кода и генерировать их в проекте автотестов. Мы назвали это эрой кодогенерации.

Ещё очень важный момент. У нас во всех проектах есть спецификации. В основном это спецификации двух версий — это OpenAPI-спецификации v1.0 и OpenAPI-спецификации v2.0. В какой-то момент пришёл менеджер и сказал, что мы больше не будем релизить новые REST API-сервисы без спецификаций.
Зачем мы вообще используем спецификацию? Всё благодаря этой замечательной странице Swagger UI.
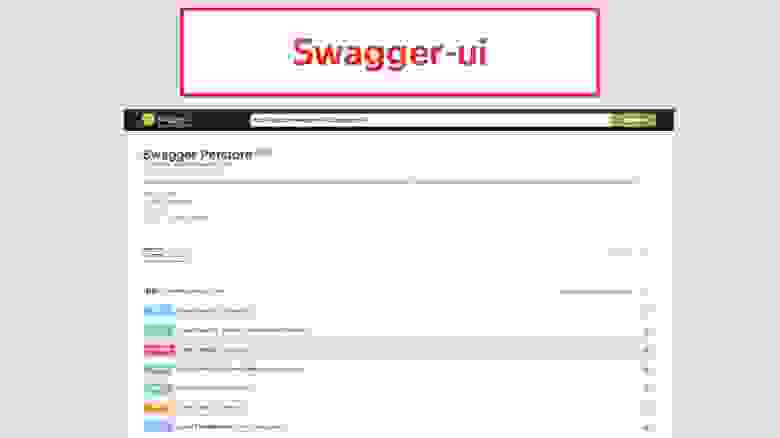
Из неё нам понятно, какой перед нами API, понятны все операции, понятно, как API используется и что вернётся. Это экономит огромное количество времени разработке для коммуникации с фронтендерами, разработчиками мобильных приложений, с ребятами, которые занимаются клиентами. Более того, через эту страницу можно делать запросы и получать ответы. Это оценили наши тестировщики, которые могут, не используя Curl, тестировать релиз. Исходя из этого мы решили, что будем строить наши автотесты на основе кодогенерации, и в качестве основы мы возьмём Swagger/OAS.
Мы решили строить такой процесс: у нас будет REST API, из него мы будем получать OpenAPI-спецификацию, а затем из OpenAPI-спецификации — тестовый клиент, с помощью которого мы и будем писать автотесты.
Что такое OpenAPI-спецификация
OpenAPI-спецификация — это opensource-проект, описывающий спецификацию и поддерживаемый линукс-сообществом (Linux Foundation Collaborative Project). Это популярный проект, у него 16000 звёздочек на GitHub.
OpenAPI-спецификация определяет стандартизированное описание для REST API-сервисов, независимо от того, на каком языке программирования они написаны, удобна для использования как человеком, так и компьютерной программой, не требует доступа к коду. Спецификация может быть двух форматов. Это может быть JSON, которая понятна для машин и не очень понятна для человека и YAML-спецификация, которая более или менее читаема для человека.
Давайте подробнее разберём, что она собой представляет. У нас есть блок с общим описанием API. Мы там ставим версию нашего API, устанавливаем хосты, базовые пути, схемы и прочее. Также у нас есть блок с описанием всех возможных операций, в которых мы указываем параметры и все возможные ответы.

Наш Swagger UI и строится на основе этого файла спецификации — swagger.json.

Как получить OpenAPI-спецификацию
Самый простой способ — написать её в текстовом файлике. Это долго и не очень удобно.
Второй способ — использовать специализированные средства для написания спецификаций. Например, Swagger Editor. Вы в нем описываете вашу спецификацию, там есть удобный редактор, который сразу её валидирует. В правой части она у вас отображается в красивом виде.
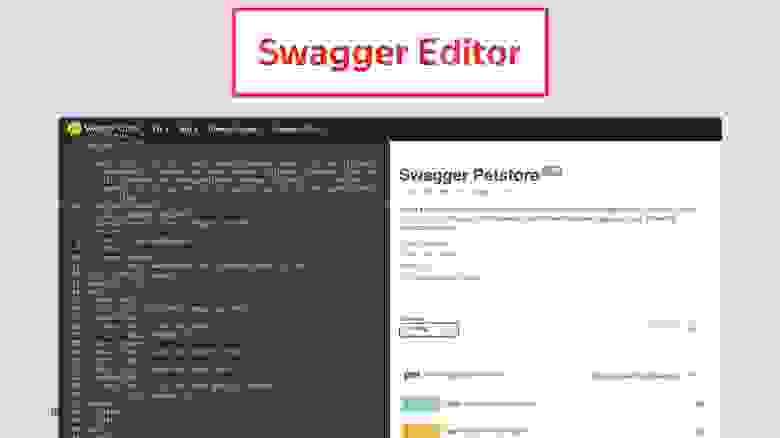
Эти два инструмента полезны, когда у вас нет кода. Вы можете сначала написать спецификацию, потом на ее основе написать код.
Есть третий способ для получения спецификации: через Swagger-annotation в коде. Допустим, у вас есть какой-то API-ресурс, вы описываете для него Swagger-annotation. Annotation processor обработает аннотации вашего сервиса и вернёт спецификацию. Для каждого релиза вашего REST API получаем всегда актуальную OpenAPI-спецификацию. Если вы что-то удаляете, у вас автоматически это удаляется из OpenAPI-спецификации. И этот процесс постоянный.

Генерация клиента
Давайте разберёмся теперь с генерацией клиента. В opensource есть два больших, достаточно популярных проекта. Это Swagger Codegen, он на данный момент поддерживается компанией SmartBear. У него 11000 звёздочек на GitHub. И OpenAPI Generator, тоже opensource-проект, но он поддерживается комьюнити. В основном про него я и буду говорить.
По факту OpenAPI Generator является форком Swagger Codegen. Он отбренчевался от этого проекта в 2018 году.
Это произошло в связи с независимым развитием Swagger Codegen 3.X и Swagger Codegen 2.X. Из-за этого нарушилась обратная совместимость. Очень много клиентов исчезли и не были поддержаны. И ещё одна причина — это нестабильность релизного цикла. Релизы в Swagger Codegen были довольно редкие, тесты часто падали и комьюнити это не устраивало.
Давайте сгенерируем какой-нибудь клиент. Если у вас есть Docker, вы просто выполняете команду, указываете путь до спецификации, указываете язык, на котором хотите получить клиент, и папку для результата.
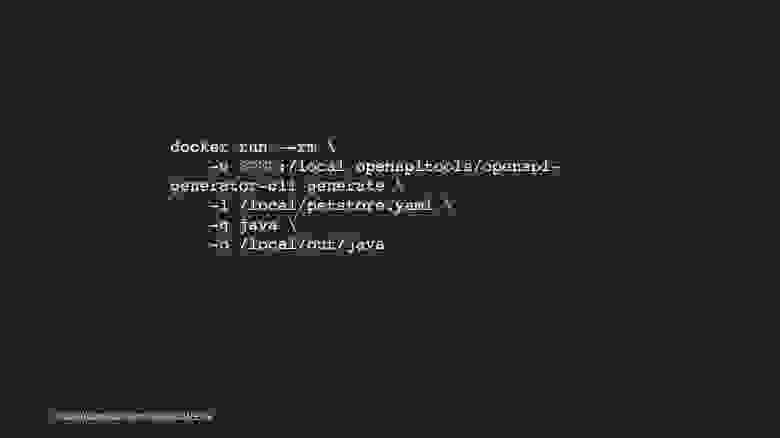
Есть второй способ: устанавливаете себе локальную консольную программу, выполняете команду и получаете клиент.
Вы получаете готовый проект. Там есть и клиент, и тест, даже скрипт, который пушит код на GitHub. По факту этот проект уже можно использовать. Но как только вы его начнёте использовать, то поймёте, что что-то идёт не так. Ниже реальный пример, где я использовал генерацию кода.

На самом деле мы пытаемся генерировать клиент из спецификации, которая на это не рассчитана. Данная спецификация использовалась только для Swagger UI, а мы хотим получить клиент. И мы можем получить что-то невразумительное. Вместо методов вашего тестового клиента у вас будут route1, route2, route16.
Проблемы, с которыми мы столкнулись при генерации
Также вы получите другие различные проблемы. Например, опечатки, потому что Swagger Annotation пишется руками разработчиков. Опечатки можно поправить — это не проблема. Могут быть различные проблемы с повторением моделей. Это достаточно легко решается, если к модели добавить имя пакета. И ещё одна проблема — неполнота спецификаций. Скоро вы обнаружите, что в вашем API есть внутренние операции, о которых вы не знали, но которые тоже надо тестировать. Самое приятное, что всё это легко исправляется.
Но есть тонкий момент — этот клиент и весь проект мы получаем один раз во время генерации. То есть проблема осталась: напомню, что при любом изменении REST API нам придётся снова поддерживать тестовые клиенты. Тогда мы решили, что будем генерировать клиент до запуска тестов и будем делать это с помощью плагина. OpenAPI Generator поддерживает множество плагинов. Например, это maven-plugin, gradle-plugin, sbt-plugin и bazel-plugin. В качестве примера я возьму maven-plugin.
Мы добавляем в наш pom.xml maven-plugin с определёнными настройками, указываем путь к нашей спецификации, папку для результата, язык генерации, dateLibrary, флаги «валидировать вашу спецификацию или нет во время генерации», «генерировать ли ваш клиент, если спецификация не менялась».

После компиляции у нас получается готовый клиент в target. Его можно использовать. По факту мы получили постоянный процесс: прямо из REST API с помощью Swagger-annotation мы получаем OpenAPI-спецификацию; из OpenAPI-спецификации мы получаем наш тестовый клиент.
Что делать, если у REST API несколько версий?

После компиляции у нас происходит генерация клиента для версии v1 и генерация клиента для версии v2.
Как добавляли клиент
Вернёмся в 2018 год. Когда мы только всё начинали, мы рассматривали множество клиентов в Swagger Codegen, написанных под разные языки, но ни один нас не устроил. Все эти клиенты очень жёстко привязаны к документации. В них мало точек расширения, и они не рассчитаны на то, что наша спецификация будет меняться. Мы решили, что напишем свой API-клиент, который будет обладать всеми необходимыми для нас возможностями.
В качестве библиотеки мы выбрали REST Assured. Она имеет fluent interface, эта библиотека предназначена для тестирования. В ней есть механизм Request specification и Response specification.
Сама генерация клиента в OpenAPI Generator основана на mustache template (Logic-less Mustache engine). Это круто, потому что генерация не зависит от языка программирования. Вы можете использовать mustache-шаблоны как для C#, так и для С++, так и для любого языка и получить клиент. Ещё один плюс — эти клиенты легко добавлять. Вам надо только добавить набор mustache-шаблонов, и у вас готовый клиент. И третья очень крутая фича — эти клиенты очень легко кастомизировать. Достаточно добавить свои шаблоны, которые просто будут использоваться при генерации.
Для того чтобы написать шаблоны, нам нужны переменные. В документации OpenAPI Generator описано, как их получить. Надо просто запустить нашу генерацию с флагом DebugOperations, и в итоге мы получим переменные для операций, которые будем использовать в шаблонах.
Аналогично можно получить те же переменные, но уже для моделей.
Итак, мы получили все переменные, написали все шаблоны и соответственно сделали pull request в Swagger Codegen. И этот pull request приняли. Теперь у нас есть собственный клиент.
Давайте рассмотрим его подробнее. Возьмём в качестве примера простейшую операцию GET /store/Inventory из Story API и попробуем написать тест. Мы будем делать простейший запрос без параметров и валидировать ответ.
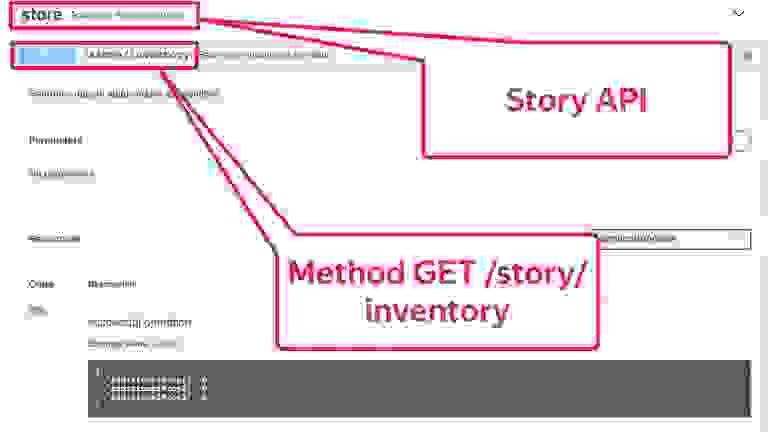
Retrofit
В качестве библиотеки для сравнения я возьму готовую библиотеку Retrofit, которая есть в OpenAPI Generator и Swagger Codegen. Так выглядит код теста, написанного на Retrofit.
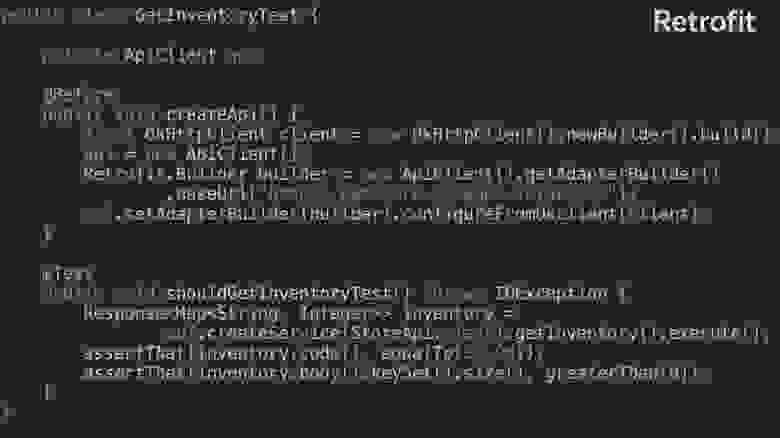
Здесь есть создание клиента: OkHttp сlient — из него билдится и настраивается Retrofit-клиент. Это простой тест: мы берём и проверяем, что конкретно у этого запроса статус OK и количество элементов больше нуля.
Давайте рассмотрим тест подробнее. Здесь api. — входная точка на наш клиент.

Здесь Story API, мы вызываем метод getInventory и его выполняем.

Здесь же валидация кода ответа. Мы просто проверяем, что код — 200.
REST Assured
Давайте напишем тот же тест, но уже на REST Assured. Вот у нас идёт создание клиента, мы его настраиваем, устанавливаем config, устанавливаем mapper, добавляем filter, добавляем BaseUri.

Это простейший тест, он чуть поменьше. Давайте его рассмотрим поподробнее. Что здесь происходит? Есть API-клиент, есть вызов Story API и метод getInventory.

Далее мы используем response specification — это особенность REST Assured. И валидируем сразу ответ, проверяем, что код — 200.

Два примера очень похожи. Возьмём пример посложнее. Возьмём ручку search.

Пусть у неё будет множество параметров. Метод, который получится в Retrofit, будет выглядеть вот так.
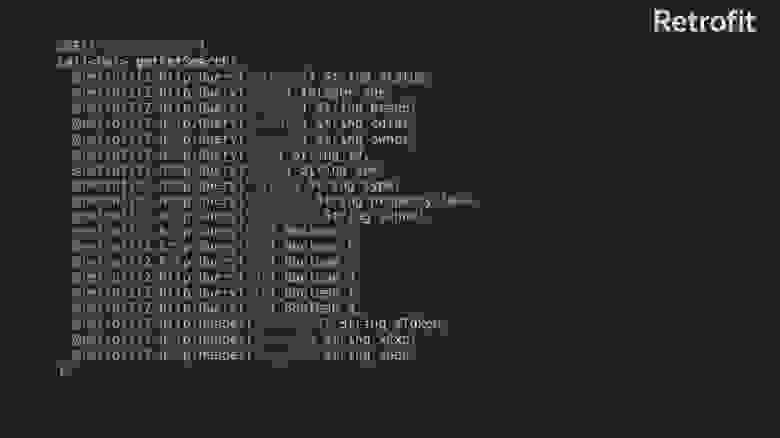
Когда вы начнёте писать тест, то получите тест с множеством null. Он не очень понятен.
В том же REST Assured мы использовали builder-паттерн, и у каждого вызова параметра собственный метод. И тест на REST Assured будет выглядеть вот так.

Добавим ещё один параметр к нашей ручке search. У нас есть спецификация, мы добавляем ещё один параметр, происходит генерация, и наш тест, написанный в Retrofit, ломается. Возникает ошибка компиляции, потому что мы добавили ещё один параметр, о котором мы ничего не знаем конкретно в этом методе.

В REST Assured ошибки не будет, потому что у нас builder-паттерн. Проблемы не возникает.
В стандартном Retrofit-клиенте параметры типизированы, для тестирования это не очень удобно. Нам бы хотелось, чтобы параметры были не типизированы, и мы могли вставить любые параметры, получить ошибку и её валидировать.
В REST Assured нетипизированные параметры. У Retrofit ответ всегда мапится на ответ из спецификации по умолчанию. В REST Assured ответ может мапиться на ответ из спецификации, а может не мапиться. Потому что, если мы тестируем невалидные кейсы, например, статус-коды не 200, то нам бы хотелось как-то кастомизировать наш ответ, чтобы получать что-то невалидное.
Retrofit не очень удобно кастомизировать. Например, если мне захочется добавить какой-то хедер, то в Retrofit это сделать не очень удобно. В REST Assured у нас есть механизм Request Specification, которым вы можете на любом этапе кастомизировать ваш запрос: как на этапе группы операций, так и на этапе самого запроса.
В данном случае я просто добавил к нашему запросу header — «x-real-ip».

Вообще, это полезно иметь для любого тестового клиента:
REST Assured сlient и Retrofit есть в OpenAPI Generator, их можно попробовать и использовать.
В Swagger Codegen с переходом на другой template-engine остался один Retrofit-клиент. REST Assured-клиента на данный момент нет, но есть открытое issue на его возвращение.
Тяжело ли поддерживать клиент
Главное, для чего создавался клиент, — чтобы добавление нового в спецификацию почти никогда не ломало компиляцию клиента. Ключевое слово — «почти». Понятно, что если мы добавим параметры, как я рассматривал раньше, всё будет хорошо. Но есть некоторые исключения.
Например, рассмотрим редкий случай. Допустим, у нас есть e-num с элементами c одинаковым префиксом. Есть enum, состоящий из следующего: PREFIX_SOLD, PREFIX_AVAIBLE, PREFIX_PENDING.
После генерации сам генератор вырезает этот префикс, и мы уже в тестах используем enum без префикса: SOLD, AVAILABLE, PENDING. Если мы в e-num добавляем значение RETURNED, то после генерации произойдёт следующее: PREFIX возвращается, и наши тесты, которые использовали этот enum без префикса, ломаются. Ломается компиляция. Это первая ситуация за два года, в которой я столкнулся с тем, что когда что-то добавляется, то ломается компиляция.
Удаление или изменение спецификации может сломать компиляцию клиента. Здесь более или менее всё понятно. Допустим, удаляем параметр status. Мы этот параметр используем в тесте, но его уже нет в клиенте. Получаем ошибку компиляции.

Ещё вариант — поиск с множеством параметров. Поменяем pet на search. Этого метода в API api.pet нет — и получаем ошибку компиляции. Что вполне ожидаемо.

И ещё: изменим в спецификации path. У нас был path /pet/search/, а мы его поменяем на /search/pet/. Что будет?

Поменяется только одна константа внутри нашей операции. И получится, что ошибок компиляции нет. Это неожиданно и ломает все представления об автотестах. Они должны ловить такие случаи, но сейчас получается, что всё работает. Чтобы отлавливать такие случаи, мы используем diff-спецификации, о которых чуть позже.
Несмотря на всё это, мы получили одну важную вещь: правим автотесты тогда, когда меняется бизнес-логика. Более того, у нас всегда актуальный клиент.
Про тесты и другие возможности
Здесь важно следующее: чем подробнее у нас спецификация, тем больше у нас возможностей.
Например, у наших спецификаций есть модели. Мы можем попробовать сгенерировать assertions на модели ответов с помощью плагина. Получается генерация в кубе. У вас есть в коде модели, эти модели переносятся в OpenAPI-спецификацию, из OpenAPI-спецификации у нас генерятся bean-ы и на эти bean-ы мы генерим assertions.
Например, мы возьмём в качестве библиотеки для генерации assertion такую популярную библиотеку как AssertJ. В AssertJ есть два плагина: есть плагин под Maven, есть плагин под Gradle. С помощью плагина получаем типизированный assertion, который можно использовать.
После настройки этого плагина мы просто указываем пакет, где у нас сгенерированные модели.

Вместо кода, где у нас не типизированные assertions, а стандартные hamcrest матчеры, мы получаем типизированные assertions — более удобные и понятные. Если у нас кроме модели ещё есть примеры значений параметров, то можем попробовать сгенерировать реальные шаблоны тестов и сами тесты. Нужно добавить парочку темплейтов, и получим тесты.
Нам пришла идея, почему бы не использовать свои темплейты. Тогда мы получим шаблоны тестов, которые можно использовать и писать. Значения в OpenAPI-спецификации второй версии хранятся в поле «x-exаmple». На это поле нет жёстких ограничений.
Какие тесты можно сгенерировать
Для того чтобы настроить генерацию тестов, нам надо прописать template_directory с нужными темплейтами и добавить шаблон для тестов.
Я буду рассматривать контрактные тесты и тесты на сравнение.
Давайте поговорим про контрактные тесты. Мы можем генерировать тесты на статус-коды, можем генерировать тесты на модели и тесты на параметры. Это почти всё, что у нас есть в спецификации по контракту. Здесь я привёл в пример mustache шаблон для генерации теста на статус-коды. Давайте чуть подробнее его рассмотрим. Мы проходим по всем респонсам, пишем бизнес-логику. Я ещё указал Allure-аннотации. Также делаем шаблон для имени теста. Мы устанавливаем в переменные нужные нам значения из спецификации и прокидываем их в вызов реквестов с тестового клиента. В конце добавлена валидация: проверка, что статус код — 200.

После генерации у нас в папке target возникают такие тесты. Это реальный тест «на 200», его можно запустить.
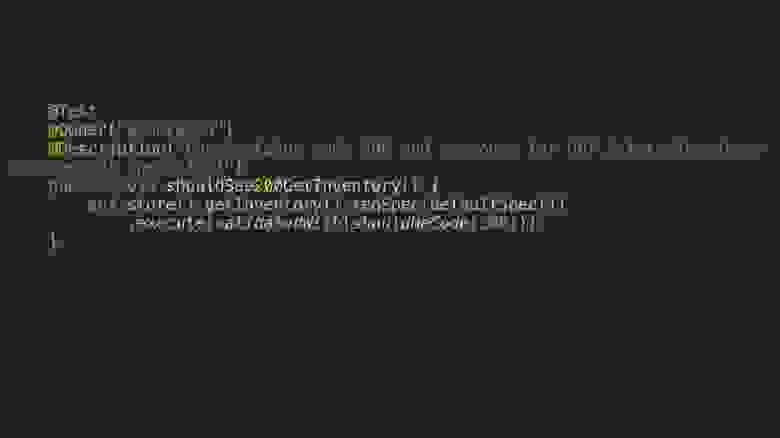
Код 404 будет выглядеть точно так же. Основная идея, что mustache-темплейты — logic-less, и тяжёлую логику нельзя таким образом сгенерировать. И потому это не совсем реальные тесты, а шаблоны тестов. Но дописав логики, вы получите вполне реальные тесты.
Аналогично можно сгенерировать тесты для параметров и моделей. Для параметров происходит то же самое. Вы просто проходите по всем параметрам и добавляете шаблоны тестов, чтобы для каждого параметра сгенерировались аналогичные тесты.
С моделями всё интересней. Мы можем проверять в тестах, что наш ответ после запроса соответствует определённой модели, которая описана в спецификации. Но в реальности это очень маленькое, узкое покрытие. Мы проверяем только модели и не проверяем значения. Если это, например, JSON, то мы проверяем только поля и что они соответствуют схеме. Но нам бы хотелось понимать, что ответ нашего запроса правильный.
Я обычно предпочитаю тесты на сравнение. Что это и как это работает? Допустим, у нас REST API, который мы тестируем. Рядом поднимаем тот же REST API, но со стабильной версией, о котором мы знаем, что он работает правильно. Делаем два запроса: запрос к REST API, который тестируем, и тот же запрос к стабильному REST API. Получаем два ответа. Первый ответ нам нужно протестировать, второй ответ мы считаем эталоном — expected response. Сравнивая два ответа, можем проанализировать, правильно всё работает или нет.
Давайте попробуем написать это в виде шаблонов. Для этого я привёл пример параметров для такого теста. У нас есть механизм в REST Assured Response и Request specification. Здесь параметром выступает Request specification. Мы устанавливаем в Request specification все возможные параметры со значениями, которые описаны у нас в спецификации.
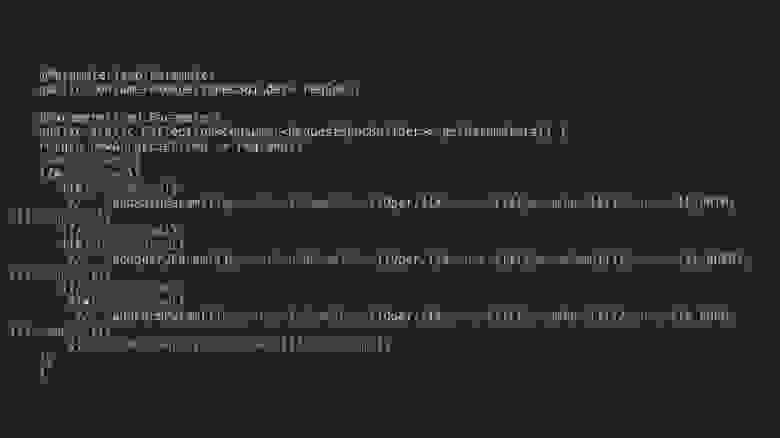
Здесь пример теста, который просто сравнивает эти два ответа. У нас есть функция, которую принимает API-клиент и возвращает ответ, который мы сравниваем через matcher jsonEquals.

Тест после генерации будет выглядеть так. Здесь значения x-example такие же, как и в спецификации. И это получается вполне реальный тест. Осталось добавить реальных тестовых данных и можно его использовать.

Как в итоге мы стали писать тесты
У нас генерируются тестовые классы, мы можем поправить их в target, запустить и использовать. Через IDE нажимаем клавишу F6, и у нас возникает окошко.

Мы выбираем первый пункт, указываем пакет, выбираем нужный модуль, если их несколько, и у нас получается тест. Работа выполнена.
Что мы получили:
Для тестировщиков головная боль — именование тестовых методов и тестовых классов. У нас единое наименование на основе OpenAPI-спецификации. Из-за этого единообразия мы пришли к тому, что наши автотесты могут писать все. Их могут писать автоматизаторы тестирования и понимать ручные тестировщики и разработчики. Всю эту красоту мы вынесли в шаблон проекта с автотестами.
На GitHub создали project-template, где указали клиент, модуль с тестами, настроили генерацию. Если нам нужен проект автотестов на какой-то новый сервис, мы берём и наследуемся от этого шаблона. Чтобы проект заработал, нам достаточно поменять значения двух property, и получаем готовые тесты и сгенерированные клиенты.

По факту мы получили «фабрику» автотестов, используя которую стало легко добавлять автотесты на любой проект.
Об инструментах
Давайте поговорим об инструментах.
Бывает так, что проект автотестов не компилируется из-за изменений спецификации сервиса. Необходимо понимать, почему это происходит. Для этого нам надо получить разницу в документации, например, используя swagger-diff.
Swagger-diff — это opensource-проект, который помогает сравнить две спецификации. Я взял его в качестве примера, но есть и другие проекты.
В качестве сравнения берём старую и новую спецификацию: из стабильной версии REST API и тестовой. Далее сравнивая их, мы получаем diff в виде HTML.
Из HTML видим, что удалили параметры search, status и добавили header x-geo.

Из HTML понятно, что изменилось.
Мы также можем анализировать обратную совместимость. Выявлять случайное удаление параметров и другие изменения.
Swagger-coverage. Как его использовать?
С течением времени количество проектов стало расти, REST API постоянно менялись. При этом наши REST API имеют большое количество операций. В самом большом REST API, который я покрывал автотестами, было около 700 операций. Наши автотесты пишут все члены команды: ручные тестировщики, разработчики, автоматизаторы. Ещё мы наняли стажёров, которые тоже пишут тесты и которых тоже нужно контролировать. Возникает вопрос, как вообще понять, что покрыто тестами, а что нет?
Мы решили, что нам нужен инструмент, который позволит измерить это покрытие на основе OpenAPI-спецификации. Я хочу рассказать про Swagger-coverage, который мы недавно реализовали.
Как он работает? У вас есть исходная спецификация. Для каждого реквеста вы можете получить информацию в формате OpenAPI-спецификации. Далее мы агрегируем всю информацию из реквестов, сравниваем с исходной спецификацией и получаем coverage.
В результате мы получаем HTML-страницу, на которой видим общую информацию о покрытии операций, общую информацию по покрытию тегов, сколько условий мы покрываем.

На странице есть фильтры. Мы знаем, какие операции у нас полностью покрыты, какие частично, какие вообще не покрыты. Также, если мы рассмотрим подробнее операцию, то увидим условия. Эти условия формируются на основе OpenAPI-спецификации. Например, если в OpenAPI-спецификации есть пять кодов ответа, то сформируется пять условий на эти коды ответа. В нашем примере видим, что у нас не проверяются все значения параметра status, мы не используем значение enum-а sold.

Все эти условия настраиваются через Config JSON.
Так же выглядят и теги — это группа операций. Мы можем понять, сколько операций покрывается, сколько вообще не покрыты. Ещё есть фильтры по условиям, можем посмотреть, какие условия не покрываются совсем.
Зачем это нужно, и как это использовать? Есть несколько способов использования.
Как построить процесс
Теперь давайте построим процесс, объединив всё в одну большую систему.
У нас есть два инструмента: Swagger-diff и Swagger-coverage. Swagger-diff возвращает json с диффом, Swagger-coverage тоже возвращает json о покрытии.
Мы можем сделать такие выводы: что-то изменилось и покрыто тестами или что-то изменилось, но не покрыто тестами.
Мы можем красить build в красный цвет и тем самым стимулировать разработчиков писать тесты.
Как построить процесс? У нас собрался build, и запустился Swagger-diff, и мы уже заранее знаем на этом этапе, сломалась ли обратная совместимость и изменилось ли что-нибудь. Это же может показать запуск тестов. Потом мы можем по результатам тестов построить coverage, чтобы понять, что покрыто, а что — нет, и на основе этого выбирать дальнейшую стратегию тестирования.
Подведём итог
Что такое Swagger/OAS как основа приёмочных тестов?
Минутка рекламы: читать расшифровки докладов по тестированию интересно, но ещё интереснее смотреть новые доклады в прямом эфире с возможностью задать вопрос спикеру. Уже на днях, 4 ноября, стартует Heisenbug 2020 Moscow — и там докладов по тестированию будет сразу множество.
Документирование API с помощью OpenAPI 3 и Swagger
Веб-приложение часто содержит API для взаимодействия с ним. Документирование API позволит клиентам быстрее понять, как использовать ваши сервисы. Если API закрыт от внешнего мира, то все равно стоит уделить время спецификации

Что такое Swagger?
Swagger автоматически генерирует спецификацию вашего API в виде json. А проект Springdoc создаст удобный UI для визуализации. Вы не только сможете просматривать документацию, но и отправлять запросы, и получать ответы.
Также возможно сгенерировать непосредственно клиента или сервер по спецификации API Swagger, для этого нужен генератор кода Swagger-Codegen.
Swagger использует декларативный подход, все как мы любим. Размечаете аннотациями методы, параметры, DTO.
Используемые версии
Java 17
Spring Boot 2.7.1
Swagger 2.2.1
SpringDoc 1.6.9
Изменения статьи
29.06.22: Обновил до Java 17. Обновил все зависимости до актуальных.
Создание REST API
Чтобы документировать API, для начала напишем его 😄 Вы можете перейти к следующей главе, чтобы не тратить время.
Добавим примитивные контроллеры и одно DTO. Суть нашей системы – программа лояльности пользователей
В качестве DTO у нас будет класс UserDto – это пользователь нашей системы. У него пять полей, из которых 3 обязательны:
UserController отвечает за добавление, обновление и получение пользователей.
PointContoller отвечает за взаимодействие с баллами пользователя. Один метод этого контроллера отвечает за добавление и удаление балов пользователям.
Метод destroy в SecretContoller может удалить всех пользователей.
Настраиваем Swagger
Теперь добавим Swagger в наш проект. Для этого добавьте следующие зависимости в проект.
Актуальные вресии в Maven Central: Swagger, SpringDoc
Swagger автоматически находит список всех контроллеров, определенных в нашем приложении. При нажатии на любой из них будут перечислены допустимые методы HTTP (DELETE, GET, HEAD, OPTIONS, PATCH, POST, PUT).
Для каждого метода доступные следующие данные: статус ответа, тип содержимого и список параметров.
Поэтому после добавления зависимостей, у нас уже есть документация. Чтобы убедиться в этом, переходим по адресу: localhost:8080/swagger-ui.html
 Swagger запущенный с дефолтными настройками
Swagger запущенный с дефолтными настройками
Также можно вызвать каждый метод с помощью пользовательского интерфейса. Откроем метод добавления пользователей.

Пока у нас не очень информативная документация. Давайте исправим это.
Эти данные больше для визуальной красоты UI документации.
Добавление авторов
Добавьте разработчиков API, чтобы было понятно, кто в ответе за это безобразие 😄
Разметка контроллеров

Скрыть контроллер
Наша документация стала намного понятнее, но давайте добавим описания для каждого метода контроллера.
Разметка методов
Аннотация @Operation описывает возможности методов контроллера. Достаточно определить следующие значения:
Разметка переменных метода
При помощи аннотации Parameter также опишем переменные в методе, который отвечает за управление баллами пользователей.
С помощью параметра required можно задать обязательные поля для запроса. По умолчанию все поля необязательные.
Разметка DTO
Сваггер заполнит переменные, формат которых он понимает: enum, даты. Но если некоторые поля DTO имеют специфичный формат, то помогите разработчикам добавив пример.
Выглядеть это будет так:


Но подождите, зачем мы передаем дату регистрации. Да и уникальный ключ чаще всего будет задаваться сервером. Скроем эти поля из swagger с помощью параметра Schema.AccessMode.READ_ONLY :
Валидация
Про валидацию я подробно рассказывал в статье: «Валидация данных в SpringBoot». Здесь я лишь хочу показать, что валидация параметров методов контроллеров также отображается в Swagger.
Давайте посмотрим на изменения спецификации.

Этих аннотаций вам хватит, чтобы сделать хорошее описание API вашего проекта.
Если нужны более тонкие настройки, то вы без труда сможете разобраться открыв документацию к аннотациям сваггера.
Разработка REST-серверов на Go. Часть 4: применение OpenAPI и Swagger
Перед вами четвёртый материал о разработке REST-серверов на Go. Здесь мы поговорим о том, как можно воспользоваться OpenAPI и Swagger для реализации стандартизированного подхода к описанию REST API, и о том, как генерировать Go-код на основе спецификации OpenAPI.

Зачем это всё?
В первой части этой серии материалов, когда мы описывали REST API, я говорил о том, что описание этого API создано специально для нашего примера. Это описание представляет собой просто список методов (путей) с комментариями:
Было бы неплохо, если бы существовал стандартный способ описания API. «Стандартным» я называю такое описание, которое могло бы играть роль контракта между серверами и клиентами. Более того, стандартное описание API выглядело бы совершенно понятным для тех разработчиков, которые не знакомы с особенностями конкретного проекта. Такое описание, кроме того, могло бы быть понятным не только людям, но и машинам, что привело бы к возможности автоматизации различных задач, связанных с API.
Swagger и OpenAPI
Проект Swagger появился в 2011 году как IDL (Interface Description Language, язык описания интерфейсов) для описания REST API.

В 2014 году вышла версия Swagger 2.0, а в 2016 множество крупных IT-компаний объединили усилия в деле создании спецификация OpenAPI, жёстко стандартизированного варианта Swagger 3.0.
Официальный сайт Swagger и OpenAPI, https://swagger.io, поддерживает Компания SmartBear Software.
Во всех этих хитросплетениях технологий можно и запутаться. Легче всего разложить сведения о них в голове можно, если помнить о том, что OpenAPI — это современное название спецификации, а словом «Swagger» обычно называют инструменты, построенные на основе этой спецификации (правда, можно ещё столкнуться и с таким понятием, как «спецификация Swagger», особенно — если речь идёт о версиях Swagger, вышедших раньше, чем версия 3.0).
Создание сервиса системы управления задачами с применением OpenAPI
Начнём с повторения нашего любимого упражнения — с переписывания сервиса приложения для управления задачами. В этот раз мы воспользуемся OpenAPI и Swagger.
Для того чтобы это сделать, я почитал документацию OpenAPI 3.0 и воспользовался редактором Swagger для ввода спецификации в формате YAML. Это заняло некоторое время. В результате в моём распоряжении оказался этот файл.
Здесь components/schemas/Task представляет собой ссылку на модель Task :
Это — описание схемы данных. Обратите внимание на то, что мы можем указывать типы для полей данных, что (как минимум — в теории) может пригодиться при автоматическом генерировании кода для валидации этих данных.
Вся эта работа принесла плоды сразу же после её завершения. А именно — она дала мне приятно выглядящую, цветную документацию для API.

Фрагмент документации из редактора Swagger
Это — всего лишь скриншот. В настоящей документации можно щёлкать по её элементам, их можно раскрывать, можно видеть чёткие описания параметров запросов, ответов, JSON-схем и прочего подобного.
Представьте себе, что занимаетесь разработкой API в рамках приложения, предназначенного для управления задачами. На определённом этапе работы принято решение о том, что этот API можно опубликовать для того чтобы к нему можно было бы обращаться с клиентских систем различных видов (это могут быть веб-клиенты, мобильные клиенты и так далее). Если ваш API описан с использованием OpenAPI/Swagger, это значит, что у вас имеется автоматически созданная документация и интерфейс для клиентов, позволяющий им экспериментировать с API. Это вдвойне важно в том случае, если среди пользователей вашего API есть люди, не являющиеся программистами. Например, это могут быть UX-дизайнеры, технические писатели, продакт-менеджеры, которым нужно разобраться в API, но которые не особенно привыкли к самостоятельному написанию скриптов.
Более того, OpenAPI стандартизирует и такие вещи, как авторизация, что тоже может оказаться очень кстати. Наш подход из первой статьи, когда мы пользовались произвольным описанием API, ни в какое сравнение не идёт с тем, что даёт нам OpenAPI.
После того, как подготовлена спецификация API, можно взглянуть на дополнительные инструменты, имеющиеся в экосистеме Swagger. Например — это Swagger UI и Swagger Inspector. Спецификацию API можно даже использовать в роли вспомогательного инструмента при интеграции REST-сервера в инфраструктуру облачного провайдера. Например, в GCP имеется система управления API Cloud Endpoints, поддерживающая спецификацию OpenAPI. Она, кроме прочего, позволяет настраивать мониторинг и анализ опубликованных API. Описание API предоставляется этой системе с использованием OpenAPI.
Автоматическое генерирование базового кода для Go-сервера
Возможности, которые обещают нам OpenAPI/Swagger, выходят далеко за пределы автоматического создания документации. На основе соответствующих спецификаций можно автоматически генерировать код клиентов и серверов.
В процессе работы я сделал некоторые выводы относительно ограничений такого подхода:
Инструмент swagger-codegen умеет ещё и создавать код клиентов, в том числе и на Go. Иногда это может оказаться очень кстати, но с моей точки зрения подобный код выглядит несколько запутанным. Он, как и в случае с серверным кодом, возможно, может сыграть роль хорошей отправной точки в деле написания собственного клиента, но механизм его автоматического создания вряд ли может стать частью некоего CI/CD-процесса.
Испытание альтернативных генераторов кода
Спецификации OpenAPI представлены в виде YAML (или JSON), их формат хорошо документирован. В результате неудивительно то, что существует далеко не один инструмент, позволяющий генерировать на основе этих спецификаций серверный код. В предыдущем разделе мы рассмотрели «официальный» генератор кода Swagger, но есть и другие подобные инструменты.
В случае с Go популярным инструментом такого рода является go-swagger. В README этого проекта есть следующий раздел:
Чем этот генератор отличается от генератора из swagger-codegen?
tl;dr В настоящий момент его главное отличие заключается в том, что он реально работает.
Проект swagger-codegen генерирует рабочий Go-код лишь для клиента, и даже тут он поддерживает лишь плоские модели. А код Go-сервера, сгенерированный swagger-codegen — это, в основном, нечто вроде кода-заглушки.
Я попробовал сгенерировать код сервера с помощью go-swagger. Так как код, сгенерированный этим средством, достаточно велик, я не привожу тут ссылку на него. Тут я лишь поделюсь впечатлениями от работы с go-swagger.
В первую очередь отмечу, что go-swagger поддерживает лишь спецификацию Swagger 2.0, а не более новую версию OpenAPI 3.0. Это довольно-таки печально, но я нашёл один онлайновый инструмент, который умеет конвертировать описания API, выполненные с использованием спецификации OpenAPI 3.0 в описания формата OpenAPI 2.0 (Swagger). Описание нашего API в формате Swagger 2.0 тоже имеются в репозитории проекта.
В серверном коде, сгенерированном go-swagger, определённо, реализовано больше возможностей, чем в коде, сгенерированном swagger-codegen. Но за всё надо платить. Дополнительные возможности означают привязку к особому фреймворку, разработанному создателями go-swagger. Сгенерированный код имеет множество зависимостей от пакетов из репозиториев go-openapi, в нём код из этих пакетов широко используется для обеспечения работы сервера. Там есть даже код для разбора флагов. Собственно, почему бы ему там не быть?
Если вам нравится фреймворк, используемый в коде, генерируемом go-swagger, то вам вполне может подойти этот код. Но если у вас на этот счёт есть свои идеи — вроде использования Gin или собственного маршрутизатора, то решения разработчиков go-swagger, отразившиеся на готовом коде, могут вас не устроить.
С помощью go-swagger можно сгенерировать и код клиента, который, как и код сервера, отличается хорошим функционалом и отражает точку зрения разработчиков go-swagger на то, каким должен быть такой код. Правда, если нужно всего лишь быстро создать такой код для целей тестирования, то, что он отражает мнение других людей, не будет выглядеть серьёзной проблемой.
После публикации этого материала мне посоветовали попробовать ещё один инструмент для генерирования кода — oapi-codegen. Код нашего сервера, созданный с помощью этого инструмента, можно найти здесь.
Я должен признать, что результаты работы oapi-codegen понравились мне гораздо больше, чем код, созданный другими опробованными мной инструментами. Это — простой и чистый код, при работе с которым легко отделить то, что сгенерировано автоматически, от того, что написано самостоятельно. Средство oapi-codegen даже понимает спецификации OpenAPI 3! Единственное, к чему я могу придраться, это то, что тут используется зависимость от пакета стороннего разработчика лишь для того, чтобы реализовать привязку параметров запроса. Лучше было бы, если бы это можно было как-то настраивать. Например — чтобы имелся бы некий параметр, позволяющий выбрать между использованием кода, входящего в состав сервера, и кода, получаемого из стороннего пакета.
Генерирование спецификаций на основе кода
Что если у вас уже имеется реализация REST-сервера, но вам очень понравилась идея его описания с помощью OpenAPI? Можно ли сгенерировать это описание на основе кода сервера?
Да — можно! Сгенерировать OpenAPI-описание сервера (правда, это снова будет описание в формате спецификации 2.0) можно с помощью специальных комментариев-аннотаций и инструментов наподобие swaggo/swag. Затем с полученным описанием можно поработать, используя различные Swagger-инструменты и, например, создать на его основе документацию.
На самом деле, это выглядит как весьма привлекательная возможность для тех, кто привык писать REST-серверы по-своему и не хочет переходить к новой схеме работы только ради того, чтобы пользоваться Swagger.
Итоги?
Представьте, что у вас имеется приложение, которому необходимо работать с REST API, и при этом вам приходится выбирать между двумя сервисами.
Я с удовольствием опишу мой API в формате OpenAPI и воспользуюсь инструментом для создания документации. А вот в деле автоматического генерирования кода я буду действовать уже более осторожно. Лично я предпочитаю достаточно сильно контролировать мой серверный код. В частности, речь идёт об используемых в нём зависимостях и о его структуре. Я вижу смысл в автоматическом создании серверного кода для целей быстрого прототипирования или для каких-то экспериментов, но я не использовал бы автоматически сгенерированный серверный код как базу для собственного проекта. Конечно, я иначе бы смотрел на этот вопрос, если бы мне надо было бы еженедельно выпускать новую версию REST-сервера. В поисках баланса между использованием чужого кода и кода своего, стоит помнить о том, что преимущества от использования зависимостей обратно пропорциональны усилиям, потраченным на программный проект.
На самом деле, инструменты вроде swaggo/swag могут предложить разработчикам отличный баланс между зависимостями и собственными усилиями. Серверный код пишут с использованием самостоятельно выбранного подхода или фреймворка и оснащают его особыми комментариями, описывающими REST API. После этого соответствующий инструмент генерирует на основе этих комментариев спецификацию OpenAPI. Эту спецификацию можно использовать для создания документации к проекту или чего угодно другого, что можно создать на её основе. При таком подходе у нас появляется дополнительная полезная возможность — наличие единственного источника истины в виде комментариев. Этот источник расположен в максимальной близости к исходному коду, реализующему механизмы, описываемые в комментариях. А такой подход, кстати, всегда полезен в деле разработки программного обеспечения.
Пользуетесь ли вы спецификациями OpenAPI при создании REST-серверов?
Руководство Swagger UI
Swagger UI предоставляет Фреймворк, который читает спецификацию OpenAPI. и создает веб-страницу с интерактивной документацией. В этом руководстве показано, как интегрировать документ спецификации OpenAPI в интерфейс Swagger.
Концептуальный обзор OpenAPI и Swagger можно посмотреть в разделе Знакомство со спецификациями OpenAPI и Swagger. Пошаговое руководство по созданию документа спецификации OpenAPI смотрим в Обзоре руководства OpenAPI 3.0.
Обзор Swagger UI
Прежде чем мы углубимся в Swagger, нужно прояснить ключевые термины.
Swagger
OpenAPI
Официальное название спецификации OpenAPI. Спецификация OpenAPI предоставляет набор свойств, которые можно использовать для описания REST API. Рабочий, валидный документ можно использовать для создания интерактивной документации, создания клиентских SDK, запуска модульных тестов и многого другого. Подробности спецификации можно изучить на GitHub по адресу https://github.com/OAI/OpenAPI-Specification. В рамках инициативы Open API с Linux Foundation спецификация OpenAPI направлена на то, чтобы быть независимой от производителя (многие компании участвуют в ее разработке).
Swagger Editor
Онлайн-редактор, который проверяет документацию OpenAPI на соответствие правилам спецификации OpenAPI. Редактор Swagger помечает ошибки и дает советы по форматированию.
Swagger UI
Swagger Codegen
Знакомство со Swagger при помощи Petstore
Чтобы лучше понять интерфейс Swagger, давайте рассмотрим пример Swagger Petstore. В примере Petstore сайт генерируется с помощью Swagger UI.

Конечные точки сгруппированы следующим образом:
Авторизация запроса
Прежде чем делать какие-либо запросы, нужна авторизация. Нажимаем кнопку Authorize и заполняем информацию, требуемую в окне «Авторизация», изображенном ниже:

Пример Petstore имеет модель безопасности OAuth 2.0. Код авторизации только для демонстрационных целей. Нет никакой реальной логики авторизации этих запросов, поэтому просто закрываем окно Авторизации.
Создание запроса
Теперь создадим запрос:
Пользовательский интерфейс Swagger отправляет запрос и показывает отправленный curl. Раздел Ответы показывает ответ. (Если выбрать JSON вместо XML в раскрывающемся списке «Response content type», формат ответа будет показан в формате JSON.)

Проверка создания питомца
Примеры сайтов с документаций по Swagger UI
Прежде чем мы перейдем к другому API с этим пособием по Swagger (кроме демонстрации Petstore), посмотрим на другие реализации Swagger:
Некоторые из этих сайтов выглядят одинаково, но другие, такие как The Movie Database API и Zomato, были легко интегрированы в остальную часть их сайта документации.
👨💻 Практическое занятие: Создание спецификации OpenAPI в Swagger UI
На этом занятии мы создадим документацию в Swagger UI в спецификации OpenAPI. Если вы используете один из предварительно созданных файлов OpenAPI, вы можете увидеть демонстрацию того, что мы создадим здесь: OpenWeatherMap Swagger UI или Sunrise/sunset Swagger UI).

Для интеграции спецификации OpenAPI в Swagger UI:
Swagger (OpenAPI 3.0)
Всем привет. Это мой первый пост на Хабре и я хочу поделиться с вами своим опытом в исследование нового для себя фреймворка.
Мне предоставился момент выбрать тему и подготовить презентацию для своей команды. Вдохновившись спикером Евгений Маренков, я решил выбрать данную тему. В процессе подготовки, я облазил много статей и репозиториев что бы компактно и эффективно донести нужную информацию.
Сейчас хочу поделиться ею в надежде, что кому-то она поможет в изучение Swagger (OpenApi 3.0)
Введение
Я на 99% уверен у многих из вас были проблемы с поиском документации для нужного вам контроллера. Многие если и находили ее быстро, но в конечном итоге оказывалось что она работает не так как описано в документации, либо вообще его уже нет.
Сегодня я вам докажу, что есть способы поддерживать документацию в актуальном виде и в этом мне будет помогать Open Source framework от компании SmartBear под названием Swagger, а с 2016 года он получил новое обновление и стал называться OpenAPI Specification.
Также возможно сгенерировать непосредственно клиента или сервер по спецификации API Swagger, для этого понадобиться Swagger Codegen.
Основные подходы
Swagger имеет два подхода к написанию документации:
Документация пишется на основании вашего кода.
Данный подход позиционируется как «очень просто». Нам достаточно добавить несколько зависимостей в проект, добавить конфигурацию и уже мы будем иметь нужную документацию, хоть и не настолько описанной какою мы хотели.
Код проекта становиться не очень читабельным от обилия аннотаций и описания в них.
Вся документация будет вписана в нашем коде (все контроллеры и модели превращаются в некий Java Swagger Code)
Подход не советуют использовать, если есть возможности, но его очень просто интегрировать.
Документация пишется отдельно от кода.
Данный подход требует знать синтаксис Swagger Specification.
Документация пишется либо в JAML/JSON файле, либо в редакторе Swagger Editor.
Swagger Tools
Swagger или OpenAPI framework состоит из 4 основных компонентов:
Теперь давайте поговорим о каждом компоненте отдельно.
Swagger Core
Для того что бы использовать Swagger Core во все орудие, требуется:
Java 8 или больше
Apache Maven 3.0.3 или больше
Jackson 2.4.5 или больше
Что бы внедрить его в проект, достаточно добавить две зависимости:
Также можно настроить maven плагин, что бы наша документация при сборке проект генерировалсь в YAML
Дальше нам необходимо добавить конфиг в проект.
Для конфигурации Swagger необходимо добавить два бина. Где нам нужно будет описать название приложения, версию нашего API, так же можно добавить контакт разработчик который отвечает за данные API
После добавление нужных нам зависимостей, у нас появятся новые аннотация с помощью которых можно документировать наш код.
Вот некоторые из них:
Swagger Codegen
В настоящее время поддерживаются следующие языки / фреймворки:
Java (Jersey1.x, Jersey2.x, OkHttp, Retrofit1.x, Retrofit2.x, Feign, RestTemplate, RESTEasy, Vertx, Google API Client Library for Java, Rest-assured)
Scala (akka, http4s, swagger-async-httpclient)
Node.js (ES5, ES6, AngularJS with Google Closure Compiler annotations)
Haskell (http-client, Servant)
C# (.net 2.0, 3.5 or later)
C++ (cpprest, Qt5, Tizen)
Java (MSF4J, Spring, Undertow, JAX-RS: CDI, CXF, Inflector, RestEasy, Play Framework, PKMST)
C# (ASP.NET Core, NancyFx)
C++ (Pistache, Restbed)
PHP (Lumen, Slim, Silex, Symfony, Zend Expressive)
Ruby (Sinatra, Rails5)
Scala (Finch, Lagom, Scalatra)
API documentation generators:
Что бы внедрить его в проект, достаточно добавить зависимость, если используете Swagger:
и если используете OpenApi 3.0, то:
Можно настроить maven плагин, и уже на процессе сборки мы можем сгенерировать нужный для нас клиент либо мок сервиса.
Также все это можно выполнить с помощью командной строки.
Запустив джарник codegen и задав команду help можно увидеть команды, которые предоставляет нам Swagger Codegen:
Для нас самые нужные команды это validate, которая быстро проверять на валидность спецификации и generate, с помощью которой мы можем сгенерировать Client на языке Java
Swagger UI
Вот пример Swagger UI который визуализирует документацию для моего pet-project:


Нажавши на кнопку «Try it out», мы можем выполнить запрос за сервер и получить ответ от него:

Swagger Editor
На верхнем уровне в спецификации OpenAPI 3.0 существует восемь объектов. Внутри этих верхнеуровневых объектов есть много вложенных объектов, но на верхнем уровне есть только следующие объекты:
Для работы над документацией со спецификацией используется онлайн-редактор Swagger Редактор Swagger имеет разделенное представление: слева пишем код спецификации, а справа видим полнофункциональный дисплей Swagger UI. Можно даже отправлять запросы из интерфейса Swagger в этом редакторе.
Редактор Swagger проверит контент в режиме реального времени, и укажет ошибки валидации, во время кодирования документа спецификации. Не стоит беспокоиться об ошибках, если отсутствуют X-метки в коде, над которым идет работа.
Первым и важным свойством для документации это openapi. В объекте указывается версия спецификации OpenAPI. Для Swagger спецификации это свойство будет swagger:
Объект info содержит основную информацию о вашем API,включая заголовок, описание, версию, ссылку на лицензию, ссылку на обслуживания и контактную информацию. Многие из этих свойство являются не обязательными.
Объект components уникален среди других объектов в спецификации OpenAPI. В components хранятся переиспользуемые определения, которые могут появляться в нескольких местах в документе спецификации. В нашем сценарии документации API мы будем хранить детали для объектов parameters и responses в объекте components
Conclusions
Документация стала более понятней для бизнес юзера так и для техническим юзерам (Swagger UI, Open Specifiation)
Можно проверять насколько совместимы изменения. Можно настраивать это в дженкинсе
Нет ни какой лишней документации к коде, код отдельно, документация отдельно
Знакомство со спецификациями OpenAPI и Swagger
OpenAPI является спецификацией для описания REST API. Можно рассматривать спецификацию OpenAPI как спецификацию DITA. В DITA существуют определенные элементы XML, используемые для определения компонентов справки, а также требуемый порядок и иерархия для этих элементов. Различные инструменты могут читать DITA и создавать веб-сайт документации на основе информации.
В OpenAPI вместо XML существует набор объектов JSON с определенной схемой, которая определяет их наименование, порядок и содержимое. Этот файл JSON (часто выражается в YAML вместо JSON) описывает каждую часть API. Описывая API в стандартном формате, инструменты публикации могут программно анализировать информацию об API и отображать каждый компонент в стилизованном интерактивном виде.
Взгляд на спецификацию OpenAPI
Чтобы лучше понять спецификацию OpenAPI, давайте взглянем на некоторые выдержки из спецификации. Углубимся в каждый элемент в следующих разделах.
Это формат YAML, взят из Swagger PetStore
Вот что значат объекты в этом коде:
Проверка спецификации
При создании спецификации OpenAPI, вместо того, чтобы работать в текстовом редакторе, можно написать свой код в редакторе Swagger. Редактор Swagger динамически проверяет контент, чтобы определить, является ли созданная спецификация валидной.

Если допустить ошибку при написании кода в редакторе Swagger, можно быстро исправить ее, прежде чем продолжить, вместо того, чтобы ждать запуска сборки и устранять ошибки.
YAML зависим от пробелов и двоеточий, устанавливающих синтаксис объекта. Такое пространственно-чувствительное форматирование делает код более понятным для человека. Однако, иногда могут возникнуть сложности с расстановкой правильных интервалов.
Автоматическая генерация файла OpenAPI из аннотаций кода
Вместо того, чтобы кодировать документ в спецификации OpenAPI вручную, также можно автоматически сгенерировать его из аннотаций в программном коде. Этот подход, ориентированный на разработчиков, имеет смысл, если есть большое количество API-интерфейсов или если для технических писателей нецелесообразно создавать эту документацию.
Swagger предлагает множество библиотек, которые можно добавлять в свой программный код для создания документа в спецификации. Эти библиотеки Swagger анализируют аннотации, которые добавляют разработчики, и генерируют документ в спецификации OpenAPI. Эти библиотеки считаются частью проекта Swagger Codegen. Методы аннотации различаются в зависимости от языка программирования. Например, вот справочник по аннотированию кода с помощью Swagger для Scalatra. Для получения дополнительной информации о Codegen см. Сравнение инструментов автоматического генерирования кода API для Swagger по API Evangelist. Дополнительные инструменты и библиотеки см. В разделах «Интеграции и инструменты Swagger» и «Интеграция с открытым исходным кодом».
Хотя этот подход и «автоматизирует» генерацию спецификации, нужно еще понимать, какие аннотации добавить и как их добавить (этот процесс не слишком отличается от комментариев и аннотаций Javadoc). Затем нужно написать контент для каждого из значений аннотации (описывая конечную точку, параметры и т. Д.).
Если идти по этому пути, нужно убедиться, что есть доступ к исходному коду для внесения изменений в аннотации. В противном случае разработчики будут писать документацию (что может и хорошо, но часто приводит к плохим результатам).
Подход: разработка по спецификации
 Spec-first development это философия о том, как разрабатывать API более эффективно. Если вы следуете философии «сначала спецификация», вы сначала пишете спецификацию и используете ее в качестве контракта, к которому разработчики пишут код.
Spec-first development это философия о том, как разрабатывать API более эффективно. Если вы следуете философии «сначала спецификация», вы сначала пишете спецификацию и используете ее в качестве контракта, к которому разработчики пишут код.
Другими словами, разработчики обращаются к спецификации, чтобы увидеть, как должны называться имена параметров, каковы должны быть ответы и так далее. После того, как этот «контракт» или «план» был принят, Стоу говорит, можно поместить аннотации в свой код (при желании), чтобы сгенерировать документ спецификации более автоматизированным способом. Но не стоит кодировать без предварительной спецификации.
Слишком часто команды разработчиков быстро переходят к кодированию конечных точек API, параметров и ответов, без пользовательского тестирования или исследования, соответствует ли API тому, что хотят пользователи. Поскольку управление версиями API-интерфейсов чрезвычайно сложно (необходимо поддерживать каждую новую версию в дальнейшем с полной обратной совместимостью с предыдущими версиями), есть желание избежать подхода «быстрый сбой», который так часто отмечают agile энтузиасты. Нет ничего хуже, чем выпустить новую версию вашего API, которая делает недействительными конечные точки или параметры, используемые в предыдущих выпусках. Постоянное версионирование в API может стать кошмаром документации.
Компания Smartbear, которая делает SwaggerHub (платформу для совместной работы команд над спецификациями API Swagger), говорит, что теперь для команд чаще встречается ручное написание спецификации, а не встраивание аннотаций исходного кода в программный код для автоматической генерации. Подход “spec-first development” в первую очередь помогает работать документации среди большего количества членов команды, нежели только инженеров. Определение спецификации перед кодированием также помогает командам создавать лучшие API.
Даже до создания API спецификация может генерировать ложный ответ, добавляя определения ответа в спецификацию. Мок-сервер генерирует ответ, который выглядит так, как будто он исходит от реального сервера, но это просто предопределенный ответ в коде, и кажется динамичным для пользователя.
Роль технического писателя в спецификации
В большинстве проектов Тома Джонсона разработчики были не очень хорошо знакомы с Swagger или OpenAPI, поэтому он обычно создавал документ спецификации OpenAPI вручную. Кроме того, он часто не имел доступа к исходному коду, и для разработчиков английский язык был не родным. Документация была для них сложным делом.
Возможно, и нам будут попадаться инженеры, не знакомые с Swagger или OpenAPI, но заинтересованные в использовании их в качестве подхода к документации API (подход, основанный на схемах, соответствует инженерному мышлению). Таким образом, нам, вероятно, придется взять на себя инициативу, чтобы направлять инженеров к необходимой информации, подходу и другим деталям, которые соответствуют лучшим практикам для создания спецификации.
В этом отношении технические писатели играют ключевую роль в сотрудничестве с командой в разработке спецификации API. Если придерживаться философии разработки, основанной на спецификациях, эта роль (техписателя) может помочь сформировать API до его кодирования и блокировки. Это означает, что может быть возможность влиять на имена конечных точек, консистенцию и шаблоны, простоту и другие факторы, которые влияют на разработку API (на которые, обычно, не влияют технические писатели).
Визуализация спецификации OpenAPI с помощью Swagger UI
После того, как получился действующий документ по спецификации OpenAPI, описывающий API, можно “скормить” эту спецификацию различным инструментам, чтобы проанализировать ее и сгенерировать интерактивную документацию, аналогичную примеру Petstore.
Наиболее распространенным инструментом, используемым для анализа спецификации OpenAPI, является Swagger UI. (Помните, что «Swagger» относится к инструментам API, тогда как «OpenAPI» относится к независимой от поставщика спецификации, не зависящей от инструмента.) После загрузки пользовательского интерфейса Swagger его довольно легко настроить с помощью собственного файла спецификации. Руководство по настройке Swagger UI есть в этом разделе.
Код пользовательского интерфейса Swagger генерирует экран, который выглядит следующим образом:
 На изображении видно, как Swagger отображает спецификацию Open API
На изображении видно, как Swagger отображает спецификацию Open API
Можно ознакомиться с примером интеграции Swagger UI с примером API сервиса погоды, использованным в качестве примера курса.
Некоторые дизайнеры критикуют выпадающие списки Swagger UI как устаревшие. В то же время разработчики считают одностраничную модель привлекательной и способной уменьшать или увеличивать детали. Объединяя все конечные точки на одной странице в одном представлении, пользователи могут сразу увидеть весь API. Такое отображение дает пользователям представление в целом, что помогает уменьшить сложность и позволяет им начать. Во многих отношениях отображение Swagger UI является кратким справочным руководством по API.
👨💻 Практическое занятие: Исследуем API PetStore в Swagger UI
Давайте познакомимся с пользовательским интерфейсом Swagger, используя Petstore.
 Окно авторизации в Swagger UI
Окно авторизации в Swagger UI
Разворачиваем конечную точку Pet
 Выполнение примера Petstore запроса
Выполнение примера Petstore запроса
Swagger UI отправляет запрос и показывает отправленный curl. В примере был отправлен curl:
В разделе “Ответы” Swagger UI выдает ответ сервера. По умолчанию ответ возвращает XML:
Если выбрать в выпадающем списке “Response content type” JSON, то в ответе вернется JSON вместо XML.

Другие инструменты визуализации
Помимо Swagger UI есть и другие инструменты, которые могут анализировать нашу документацию OpenAPI. Вот список из нескольких инструментов: Restlet Studio, Apiary, Apigee, Lucybot, Gelato, Readme.io, swagger2postman, отзывчивую тему swagger-ui, Postman Run Buttons и многое другое.
Кастомизация Swagger UI
Однако, помимо этих простых модификаций, потребуется немного мастерства веб-разработчика, чтобы существенно изменить отображение пользовательского интерфейса Swagger. Возможно, понадобятся навыки веб-разработки.
Недостатки OpenAPI и Swagger UI
Несмотря на то, что Swagger обладает интерактивными возможностями апеллировать к желаниям пользователей «дай мне попробовать», у Swagger и OpenAPI есть некоторые недостатки:
Некоторые утешения
Несмотря на недостатки спецификации OpenAPI, он все же настоятельно рекомендуется ее для описания API. OpenAPI быстро становится средством для все большего и большего количества инструментов (от кнопки запуска Postman для почти каждой платформы API), для быстрого получения информации о нашем API и для превращения ее в доступную и интерактивную документацию. С помощью своей спецификации OpenAPI можно портировать свой API на многие платформы и системы, а также автоматически настраивать модульное тестирование и создание прототипов.
Swagger UI обеспечивает определенно хорошую визуальную форму для API. Можно легко увидеть все конечные точки и их параметры (например, краткий справочник). Основываясь на этой структуре, можно помочь пользователям понять основы вашего API.
Кроме того, изучение спецификации OpenAPI и описание своего API с его объектами и свойствами поможет расширить свой собственный словарь API. Например, станет понятно, что существует четыре основных типа параметров: параметры «пути», параметры «заголовка», параметры «запроса» и параметры «тела запроса». Типы данных параметров в REST: «Boolean», «number», «integer» или «string». В ответах содержатся «objects», содержащие «strings» или «arrays».
Короче говоря, реализация спецификации даст еще и представление о терминологии API, которая, в свою очередь, поможет описать различные компоненты своего API достоверными способами.
OpenAPI может не подходить для каждого API, но если API имеет довольно простые параметры, без большого количества взаимозависимостей между конечными точками, и если нет проблем исследовать API с данными пользователя, OpenAPI и Swagger UI могут быть мощным дополнением к документации. Можно давать пользователям возможность опробовать запросы и ответы.
С таким интерактивным элементом документация становится больше, чем просто информация. С помощью OpenAPI и Swagger UI мы создаем пространство для пользователей, которые одновременно могут читать нашу документацию и экспериментировать с нашим API. Эта комбинация имеет тенденцию предоставлять мощный опыт обучения для пользователей.
Ресурсы для дальнейшего чтения
Вот источники для получения дополнительной информации об OpenAPI и Swagger: