звука это процесс получения цифровой формы звука








Цифровой звук. Принципы работы со звуком.
Цифровой звук – это способ представления электрического сигнала посредством дискретных численных значений его амплитуды.
хранение без потерь данных (lossless);
хранение с безвозвратной потерей данных (lossy);
Все это огромное множество преобразований сводится, в конечном счете, к следующим основным типам:
1. Амплитудные преобразования. Выполняются над амплитудой сигнала и приводят к ее усилению/ослаблению или изменению по какому-либо закону на определенных участках сигнала.
2. Частотные преобразования. Выполняются над частотными составляющими звука: сигнал представляется в виде спектра частот через определенные промежутки времени, производится обработка необходимых частотных составляющих, например, фильтрация, и обратное «сворачивание» сигнала из спектра в волну.
3. Фазовые преобразования. Сдвиг фазы сигнала тем или иным способом; например, такие преобразования стерео сигнала, позволяют реализовать эффект вращения или «объёмности» звука.
4. Временные преобразования. Реализуются путем наложения, растягивания/сжатия сигналов; позволяют создать, например, эффекты эха или хора, а также повлиять на пространственные характеристики звука.
Практические примеры использования указанных видов преобразований при создании реальных звуковых эффектов:
Программное обеспечение, необходимое для цифровой записи и обработки звука: Adobe Audition, Sound Forge, Cool Edit Pro, Wavelab и т.д.
Таким образом, весьма высокие еще для начала 90-х параметры цифрового звука «16 бит/44,1 кГц» сейчас могут считаться лишь минимально допустимыми для понятий «качественный звук» и «Hi-Fi». В студийной работе происходит переход на стандарт «24 бита/96 кГц», который по теоретически достижимому качеству пока заметно перекрывает возможности существующих звуковых систем. Внутри стандарта «компакт-диск», ограниченного своими 16 разрядами и 44,1 кГц частоты дискретизации, используется преобразование цифрового звука под большую частоту дискретизации и разрядность с последующей интерполяцией промежуточных значений. Само по себе это не улучшает качества звука, однако позволяет заметно снизить погрешности, возникающие из-за неидеальности ЦАП, фильтров и прочих элементов тракта.
Цифровое представление аналогового аудиосигнала. Краткий ликбез

Дорогие читатели, меня зовут Феликс Арутюнян. Я студент, профессиональный скрипач. В этой статье хочу поделиться с Вами отрывком из моей презентации, которую я представил в университете музыки и театра Граца по предмету прикладная акустика.
Рассмотрим теоретические аспекты преобразования аналогового (аудио) сигнала в цифровой.
Статья не будет всеохватывающей, но в тексте будут гиперссылки для дальнейшего изучения темы.
Чем отличается цифровой аудиосигнал от аналогового?
Аналоговый (или континуальный) сигнал описывается непрерывной функцией времени, т.е. имеет непрерывную линию с непрерывным множеством возможных значений (рис. 1).

Цифровой сигнал — это сигнал, который можно представить как последовательность определенных цифровых значений. В любой момент времени он может принимать только одно определенное конечное значение (рис. 2).
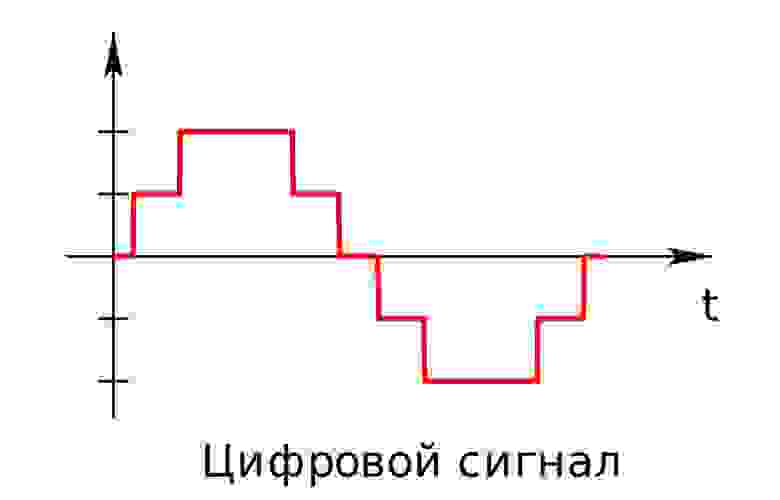
Аналоговый сигнал в динамическом диапазоне может принимать любые значения. Аналоговый сигнал преобразуется в цифровой с помощью двух процессов — дискретизация и квантование. Очередь процессов не важна.
Дискретизацией называется процесс регистрации (измерения) значения сигнала через определенные промежутки (обычно равные) времени (рис. 3).
Квантование — это процесс разбиения диапазона амплитуды сигнала на определенное количество уровней и округление значений, измеренных во время дискретизации, до ближайшего уровня (рис. 4).
Дискретизация разбивает сигнал по временной составляющей (по вертикали, рис. 5, слева).
Квантование приводит сигнал к заданным значениям, то есть округляет сигнал до ближайших к нему уровней (по горизонтали, рис. 5, справа).
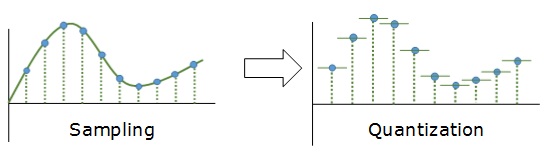
Эти два процесса создают как бы координатную систему, которая позволяет описывать аудиосигнал определенным значением в любой момент времени.
Цифровым называется сигнал, к которому применены дискретизация и квантование. Оцифровка происходит в аналого-цифровом преобразователе (АЦП). Чем больше число уровней квантования и чем выше частота дискретизации, тем точнее цифровой сигнал соответствует аналоговому (рис. 6).
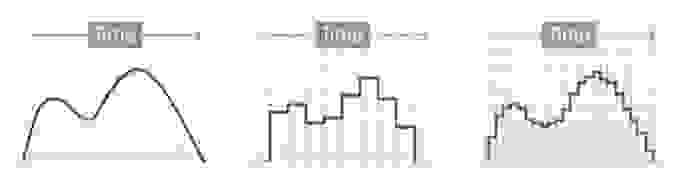
Уровни квантования нумеруются и каждому уровню присваивается двоичный код. (рис. 7)
Количество битов, которые присваиваются каждому уровню квантования называют разрядностью или глубиной квантования (eng. bit depth). Чем выше разрядность, тем больше уровней можно представить двоичным кодом (рис. 8).

Данная формула позволяет вычислить количество уровней квантования:
Если N — количество уровней квантования,
n — разрядность, то

Обычно используют разрядности в 8, 12, 16 и 24 бит. Несложно вычислить, что при n=24 количество уровней N = 16,777,216.
При n = 1 аудиосигнал превратится в азбуку Морзе: либо есть «стук», либо нету. Существует также разрядность 32 бит с плавающей запятой. Обычный компактный Аудио-CD имеет разрядность 16 бит. Чем ниже разрядность, тем больше округляются значения и тем больше ошибка квантования.
Ошибкой квантований называют отклонение квантованного сигнала от аналогового, т.е. разница между входным значением  и квантованным значением
и квантованным значением  (
( )
)
Большие ошибки квантования приводят к сильным искажениям аудиосигнала (шум квантования).
Чем выше разрядность, тем незначительнее ошибки квантования и тем лучше отношение сигнал/шум (Signal-to-noise ratio, SNR), и наоборот: при низкой разрядности вырастает шум (рис. 9).

Разрядность также определяет динамический диапазон сигнала, то есть соотношение максимального и минимального значений. С каждым битом динамический диапазон вырастает примерно на 6dB (Децибел) (6dB это в 2 раза; то есть координатная сетка становиться плотнее, возрастает градация).
Ошибки квантования (округления) из-за недостаточного количество уровней не могут быть исправлены.
50dB SNR
примечание: если аудиофайлы не воспроизводятся онлайн, пожалуйста, скачивайте их.
Теперь о дискретизации.
Как уже говорили ранее, это разбиение сигнала по вертикали и измерение величины значения через определенный промежуток времени. Этот промежуток называется периодом дискретизации или интервалом выборок. Частотой выборок, или частотой дискретизации (всеми известный sample rate) называется величина, обратная периоду дискретизации и измеряется в герцах. Если
T — период дискретизации,
F — частота дискретизации, то 
Чтобы аналоговый сигнал можно было преобразовать обратно из цифрового сигнала (точно реконструировать непрерывную и плавную функцию из дискретных, «точечных» значении), нужно следовать теореме Котельникова (теорема Найквиста — Шеннона).
Теорема Котельникова гласит:
Если аналоговый сигнал имеет финитный (ограниченной по ширине) спектр, то он может быть восстановлен однозначно и без потерь по своим дискретным отсчетам, взятым с частотой, строго большей удвоенной верхней частоты.
Вам знакомо число 44.1kHz? Это один из стандартов частоты дискретизации, и это число выбрали именно потому, что человеческое ухо слышит только сигналы до 20kHz. Число 44.1 более чем в два раза больше чем 20, поэтому все частоты в цифровом сигнале, доступные человеческому уху, могут быть преобразованы в аналоговом виде без искажении.
Но ведь 20*2=40, почему 44.1? Все дело в совместимости с стандартами PAL и NTSC. Но сегодня не будем рассматривать этот момент. Что будет, если не следовать теореме Котельникова?
Когда в аудиосигнале встречается частота, которая выше чем 1/2 частоты дискретизации, тогда возникает алиасинг — эффект, приводящий к наложению, неразличимости различных непрерывных сигналов при их дискретизации.

Как видно из предыдущей картинки, точки дискретизации расположены так далеко друг от друга, что при интерполировании (т.е. преобразовании дискретных точек обратно в аналоговый сигнал) по ошибке восстанавливается совершенно другая частота.
Аудиопример 4: Линейно возрастающая частота от
100 до 8000Hz. Частота дискретизации — 16000Hz. Нет алиасинга.
Аудиопример 5: Тот же файл. Частота дискретизации — 8000Hz. Присутствует алиасинг
Пример:
Имеется аудиоматериал, где пиковая частота — 2500Hz. Значит, частоту дискретизации нужно выбрать как минимум 5000Hz.
Следующая характеристика цифрового аудио это битрейт. Битрейт (bitrate) — это объем данных, передаваемых в единицу времени. Битрейт обычно измеряют в битах в секунду (Bit/s или bps). Битрейт может быть переменным, постоянным или усреднённым.
Следующая формула позволяет вычислить битрейт (действительна только для несжатых потоков данных):
Битрейт = Частота дискретизации * Разрядность * Количество каналов
Например, битрейт Audio-CD можно рассчитать так:
44100 (частота дискретизации) * 16 (разрядность) * 2 (количество каналов, stereo)= 1411200 bps = 1411.2 kbit/s
При постоянном битрейте (constant bitrate, CBR) передача объема потока данных в единицу времени не изменяется на протяжении всей передачи. Главное преимущество — возможность довольно точно предсказать размер конечного файла. Из минусов — не оптимальное соотношение размер/качество, так как «плотность» аудиоматериала в течении музыкального произведения динамично изменяется.
При кодировании переменным битрейтом (VBR), кодек выбирает битрейт исходя из задаваемого желаемого качества. Как видно из названия, битрейт варьируется в течение кодируемого аудиофайла. Данный метод даёт наилучшее соотношение качество/размер выходного файла. Из минусов: точный размер конечного файла очень плохо предсказуем.
Усреднённый битрейт (ABR) является частным случаем VBR и занимает промежуточное место между постоянным и переменным битрейтом. Конкретный битрейт задаётся пользователем. Программа все же варьирует его в определенном диапазоне, но не выходит за заданную среднюю величину.
При заданном битрейте качество VBR обычно выше чем ABR. Качество ABR в свою очередь выше чем CBR: VBR > ABR > CBR.
ABR подходит для пользователей, которым нужны преимущества кодирования VBR, но с относительно предсказуемым размером файла. Для ABR обычно требуется кодирование в 2 прохода, так как на первом проходе кодек не знает какие части аудиоматериала должны кодироваться с максимальным битрейтом.
Существуют 3 метода хранения цифрового аудиоматериала:
Несжатый (RAW) формат данных
Другой формат хранения несжатого аудиопотока это WAV. В отличие от RAW, WAV содержит заголовок файла.
Аудиоформаты с сжатием без потерь
Принцип сжатия схож с архиваторами (Winrar, Winzip и т.д.). Данные могут быть сжаты и снова распакованы любое количество раз без потери информации.
Как доказать, что при сжатии без потерь, информация действительно остаётся не тронутой? Это можно доказать методом деструктивной интерференции. Берем две аудиодорожки. В первой дорожке импортируем оригинальный, несжатый wav файл. Во второй дорожке импортируем тот же аудиофайл, сжатый без потерь. Инвертируем фазу одного из дорожек (зеркальное отображение). При проигрывании одновременно обеих дорожек выходной сигнал будет тишиной.
Это доказывает, что оба файла содержат абсолютно идентичные информации (рис. 11).
Кодеки сжатия без потерь: flac, WavPack, Monkey’s Audio…
При сжатии с потерями
акцент делается не на избежание потерь информации, а на спекуляцию с субъективными восприятиями (Психоакустика). Например, ухо взрослого человек обычно не воспринимает частоты выше 16kHz. Используя этот факт, кодек сжатия с потерями может просто жестко срезать все частоты выше 16kHz, так как «все равно никто не услышит разницу».
Другой пример — эффект маскировки. Слабые амплитуды, которые перекрываются сильными амплитудами, могут быть воспроизведены с меньшим качеством. При громких низких частотах тихие средние частоты не улавливаются ухом. Например, если присутствует звук в 1kHz с уровнем громкости в 80dB, то 2kHz-звук с громкостью 40dB больше не слышим.
Этим и пользуется кодек: 2kHz-звук можно убрать.
Кодеки сжатия с потерям: mp3, aac, ogg, wma, Musepack…
Оцифровка звука: как это работает
Как переводят голос в бездушную цифру.
Начинаем рассказывать, как работают привычные технологии: компьютерный звук, видео, MP3, вещание и стриминги, всевозможные алгоритмы и всё подобное.
👍 У этой статьи нет никакой практической ценности, она просто для удовольствия. Иногда можно себя побаловать 🙂
Немного школьной физики
Звук — это колебания воздуха. Как волны на воде, только в воздухе. Воздух давит нам на уши, а в ушах есть чувствительные части, которые тонко чувствуют колебания воздуха. Эти колебания люди воспринимают как звук. В открытом космосе звуков нет, потому что там нет воздуха. И людей.
Частота. Чем быстрее колебания, тем тоньше воспринимаемый нами звук. Человек воспринимает колебания от 20 раз в секунду до примерно 20 тысяч раз в секунду. По-другому это называется частотой колебаний: герцами. То есть диапазон, который мы слышим — от 20 герц до 20 килогерц.
Для сравнения, собаки слышат от 40 герц до 60 килогерц, поэтому собачий свисток не воспринимается людьми, но очень хорошо слышен собакам. Собачий свисток как раз звучит в диапазоне 23–54 КГц.
Амплитуда. Чем сильнее колебания — тем громче, и наоборот. Можно представить, что это высота волн на поверхности пруда: может быть мелкая рябь (тихий звук), а могут быть большие мощные волны.
График. Если мы произнесём фразу «Привет, это журнал „Код“», то с точки зрения волн он будет выглядеть как-то так (очень примерно):

Делим звук на отрезки
Давайте увеличим наш график и посмотрим, что происходит, например, за одну секунду (опять же, очень примерно и упрощённо!):
 Упрощённо!
Упрощённо!
А теперь сделаем вот что: разделим секунду на 4 части, и для каждой найдём значение амплитуды:
 Мы за секунду четыре раза измерили состояние волны. Это называется дискретизацией
Мы за секунду четыре раза измерили состояние волны. Это называется дискретизацией
Мы измерили значение амплитуды в каждой из четырёх точек, получили, условно говоря, четыре числа: +30, −50, −50 и −60. Теоретически, если взять ток и подать эти четыре напряжения на динамик, у нас получится воспроизвести тот же звук. Но есть несколько проблем:
Дискретизация с частотой 4 (сколько значений мы измеряем в секунду) — это слишком мало для звука. Чтобы получить более или менее разборчивую речь, нужно секунду делить на 8 тысяч отрезков, а для музыки обычно хватает 41 тысячи.
Увеличим частоту дискретизации: нарежем звук на более мелкие кусочки за ту же единицу времени:
 Теперь измерения будут намного точнее, а получившийся звук — естественнее
Теперь измерения будут намного точнее, а получившийся звук — естественнее
Переводим в цифру
После того как мы разбили звук на мелкие отрезки и измерили значение амплитуды для каждого из них, мы можем записать это в виде таблички:
| Время | Амплитуда |
| 0.01 сек. | 5 |
| 0.02 сек. | 7 |
| 0,03 сек | 10 |
| . | . |
| 1 сек | −21 |
Если мы весь звук разбиваем на одинаковые отрезки, то время можно не писать, потому что мы знаем, как оно меняется, достаточно записать в строчку только значения амплитуды:
Чтобы компьютер понимал эти числа, переведём эти числа в двоичную систему счисления. Для простоты будем считать, что одно число занимает ровно один байт памяти, но на самом деле чем больше байт выделяется на число, тем точнее будет измерение и качество звука. После перевода получим такое:
Последнее большое число получилось оттого, что нам нужно хранить и отрицательные значения, поэтому первая единица в байте означает, что это отрицательное число и его нужно считать немного иначе.
Вот эту последовательность компьютер уже может понять и воспроизвести в виде звука.
Как теперь воспроизвести звук
Чтобы что-то зазвучало, нужно сделать следующие шаги:
Что дальше
У такого способа есть одна проблема: файл получается слишком большим, чтобы им было удобно пользоваться. Представьте: 44 тысячи чисел за одну секунду!
Чтобы уменьшить размер файла, придумали два решения: сжатие с потерями и без них. Каждое разберём отдельно, несмотря на то, что у них много общего.
Простыми словами о цифровом и аналоговом звуке

На очереди транскрипт десятого выпуска (22.05.2014) подкаста «Звук». В нем Дмитрий Кабанов беседует с Анатолием Дмитриевичем Арсёновым, к. т. н., физиком по образованию, экспертом в области IT и цифрового звука, инженером в компании F-Lab на тему цифрового и аналогового звука.
Дмитрий Кабанов: Мы продолжаем беседовать с экспертами и инженерами «Аудиомании», и сегодня мы попытаемся копнуть глубже, посмотреть на природу цифрового и аналогового звука, и, наверное, мы начнем с вопроса о том, что такое звук в принципе. Чем в базовом понимании, простыми словами, отличается аналоговый звук от цифрового звука или аналоговое представление звука и цифровое представление звука?
Анатолий Арсёнов: Отвечая на этот вопрос, я думаю, уместно привести простые модели, знакомые, может быть, [из] школьного курса любому российскому образованному человеку. В частности, история звука [как] цифрового, [так] и аналогового начинается давно, как ни странно, еще до появления цифровых устройств. Всем знакома передача голоса человека с помощью обычного проводного телефона. Вот это [и является] реальным примером передачи аналогового звука на расстоянии. В данном случае говорящий имеет перед собой телефонную трубку, в которой есть микрофон и мембрана, колеблющаяся в соответствии с голосом человека, на противоположном конце происходит обратная процедура, то есть колеблется мембрана телефона, находящегося у уха абонента.
Что передается по кабелю? Мы имеем сигнал переменного напряжения: ток в кабеле изменяется в соответствии с тем, как говорит человек, вот так скажем, чтобы не вдаваться в подробности. Что такое цифровой звук? Здесь [можно привести аналогичный пример] из того же времени – телеграфная передача сигнала, азбука Морзе. В данном случае диктор имеет перед собой какой-то текст, но он должен знать азбуку Морзе. Дальше, кем кодируется текст? Самим человеком, который знает как передать букву «А», как передать букву «Б» и т. д. Что отправляется в сигнальную линию? Отправляются сигналы: точка и тире, то, как примерно кодируется сейчас звук – нулями и единицами, двумя сигналами передаются два состояния.
Что должен сделать абонент на противоположной стороне [если он] хочет понять, принять этот текст, получить это сообщение? Он должен знать азбуку Морзе, он должен получать вот эти самые точки и тире, а зная их, уже понимать, о чем идет речь. Вот вся, собственно говоря, разница. В одном случае передается сигнал, который носит характер модели голоса человека, передающегося путем электрических сигналов, во втором случае мы имеем передачу символов, которые закодированы каким-то условным образом. В данном случае это были точки и тире. Спустя много лет, в современную эпоху, мы уже имеем два типа передачи сигналов, которые очень далеко разошлись между собой от той старой истории.
Дмитрий: Получается что цифровой звук или цифровое представление звука можно понимать, как некий компромисс, который мы получаем, беря аналоговый звук и преобразовывая его в цифру.
Анатолий: Ну, компромисс это или нет…Компромисс с чем? С возможностями аппаратуры? Да, это компромисс. Дальше, с потребностями современной техники передать большее количество информации за единицу времени на более дальние расстояния с высоким качеством и способностью к последующей коррекции? Да, это компромисс. Конечно, для того, чтобы передавать аналоговый звук на дальние расстояния с высоким качеством, аппаратура должна иметь соответствующие мощности, и я не скажу, что она будет дешевой, она будет всегда материалоемкой.
На определенном этапе развития техники оказалось наиболее продуктивным передавать сигналы не в явной форме, как это происходит в аналоговой аппаратуре, а в виде некоторой модели, таблицы чисел, здесь я могу привести аналогичный пример из несколько другой практики тоже знакомой, наверное, каждому. Значит, имея географическую карту…вот как можно своему товарищу передать информацию, если стоит задача добраться из одной точки в другую? Нужно взять карту, начертить карандашом линию, как ты шел или как ты собираешься идти, и эту карту переслать, вот вам, пожалуйста – мы передаем информацию в явной форме.
Можно поступить другим образом – зная, что у товарища есть точно такая же карта, передать табличку с координатами точек. Что в данном случае будет передаваться? Листочек, на котором будет записана таблица: широта, долгота, широта, долгота, широта, долгота и т. д. В данном случае это будет просто таблица чисел. Товарищ, получив эту таблицу, взяв свою карту и отметив эти точки по координатам, сразу же определит, как идти. Что мы передали в [этом] случае? Саму карту с маршрутом или мы передали таблицу, какую-то кодировку?
Вот это все происходит и в цифровой технике. Непременным элементом в цифровой технике является кодировщик или раскодировщик, ну это раньше так говорили, в цифровой технике принято говорить, что это цифро-аналоговое преобразование.
Дмитрий: Отличный пример, мне кажется, а стоит ли нам здесь зацепить [тему] хранения? Формат, понимание форматов, понимание их разницы, потому что существует много мифов о том, какие форматы у нас есть – с потерями, без потерь, по-разному сжимающие файл и т. д.
Анатолий: Как видно из приведенных примеров, цифровая форма является условной формой передачи сигнала – это система формализации, если говорить математическим языком. Сигнал передается в условной форме математической модели — если говорить еще более глубоко, то это матрица, которая содержит определенные числа, [характеризующие] сигнал в каждый момент времени.
Если говорить применительно к звуку, то что цифры передают? Цифры передают спектр сигнала, его амплитуду, громкость. Частоты этого сигнала, высокие, низкие, [то] как эти частоты связаны между собой тембрально и т. д. – это спектральная характеристика, переведенная в числовую форму, которая передается [на устройство].
На заре компьютерной техники возможности персональных компьютеров были не очень широки. Для того, чтобы реализовать простые задачи, необходимо было компьютерному устройству иметь достаточные емкость памяти и производительность центрального процессора. Это не позволяло цифровой форме детально отображать записанный звук. Простой пример: если к старому компьютеру пятнадцатилетней давности присоединить звуковую карту, подключить микрофон, оцифровать свой голос, то я не думаю, что [результат] понравился бы многим, [а именно] качество записанного голоса.
Ну объективно, почему? На вход звуковой карты подавался сигнал с микрофона. Частотные характеристики цифрового тракта были тогда достаточно скромными, и поэтому преобразование аналогового сигнала, то есть звука в схему, которая позволяет в цифровом виде отображать этот звук внутри компьютеров…это был сложный процесс и, естественно, производители и разработчики устройств того времени, пытаясь экономить память и производительность процессора, создавали простые схемы кодирования звука в ту форму, в которой он может храниться в компьютере.
К чему это приводило? К потерям. В качестве звука прежде всего. С ростом производительности компьютерной техники, производительности центрального процессора, увеличения объемов памяти, эта проблема потихонечку стала сниматься с повестки дня, но тем не менее подходы, которые были сформированы в то время, наложили свой отпечаток на развитие цифровой техники. В свое время, если память мне не изменяет, это [был] 1994 год, [велись] работы Фраунгоферского института по созданию формата MP3 – этот формат и на сегодняшний день очень популярен для хранения музыки и различных аудиоданных в портативной технике, в частности, в смартфонах.
Дмитрий: Приведем краткую вики-справку: MP3 (более точно, англ. MPEG-1/2/2.5 Layer 3; но не MPEG3) — это кодек третьего уровня, разработанный командой MPEG, лицензируемый формат файла для хранения аудиоинформации. MP3 разработан рабочей группой института Фраунгофера под руководством Карлхайнца Бранденбурга из универститета Эрланген-Нюрнберг в сотрудничестве с AT&T Bell Labs и Thomson.
Основой разработки MP3 послужил экспериментальный кодек ASPEC (Adaptive Spectral Perceptual Entropy Coding). Первым кодировщиком в формат MP3 стала программа L3Enc, выпущенная летом 1994 года. Спустя один год появился первый программный MP3-плеер – Winplay3. При разработке алгоритма тесты проводились на вполне конкретных популярных композициях. Основной стала песня Сюзанны Веги Tom’s Diner. Отсюда возникла шутка, что «MP3 был создан исключительно ради комфортного прослушивания любимой песни Бранденбурга», а Вегу стали называть «мамой МP3».
Анатолий: Чем он характеризуется? [Каково] его отличие от звука, который никаким образом, кроме преобразования в цифру, не отличается от аналогового сигнала (эти файлы мы раньше называли wave-формы)? Кто знаком с компьютерами Apple, там [такие] файлы имели формат, который называется AIFF, насколько я помню.
Дмитрий: Да, так и есть.
Анатолий: Форма этих двух файлов, формат этого файла, представляет из себя просто цифровое отображение аналогового звука. Но в компьютерах того времени он занимал очень большой объем и таких файлов в компьютере могло храниться немного. Чем отличался MP3?
Дмитрий: Поэтому информацию можно выкинуть.
Анатолий: Никто [этот звук] не услышит. Если разница между самым громким и самым тихим звуком в данный момент времени больше 90 дБ, то спокойно можно эти звуки из записи удалить, вырезать. Это один из способов. То, что здесь происходит, специалисты [называют] маскированием низкоуровневого сигнала сигналом более высокого уровня.
Другой способ: как правило, Hi-Fi аппаратура позволяет зафиксировать сигналы с определенными частотами – если говорить о частотах и не использовать такие понятия как высокие, низкие и средние частоты. Сигналы с частотами от 20 Гц до 20000 Гц – это полоса, которую аппаратура может воспроизвести. Услышит ли человек весь этот диапазон? Если посмотреть с точки зрения восприятия человека и ввести такой термин, как психоакустика, то [также] можно произвести некоторые упрощения сигнала.

Тем, кто хочет проверить остроту слуха и сравнить звучание различных аудиосистем, Аудиомания предлагает услугу прослушивания техники на дому. На фото – работа инсталляторов Аудиомании
Большинство взрослых людей – те, кто перевалил за подростковый возраст, как правило не слышат частоты выше 16 кГц, значит, диапазон выше 16 кГц тоже каким-то образом можно математически редуцировать и, таким образом, убрать эту информацию из того файла, который был записан с помощью цифрового микрофона, поскольку он тоже не будет адекватно воспринят слушателем. То же самое происходит и в низком диапазоне: те, кто заняты физиологией человека, знают о том, что любой человек, если он нормален, конечно, и у него нет никакой патологии, не воспринимает низкочастотные сигналы ниже 16 Гц ухом – он воспринимает [такие сигналы] либо тактильно, либо органами тела.
Заначит, все эти звуки тоже можно безболезненно [удалить], не потеряв основного качества звукового сигнала, если это, например, было музыкальное произведение. В принципе, этих методов на сегодняшний день существует достаточно много: схемы, которые используются в цифровом звуке, форматах MP3, маскировка чистого тона шумом и т. д. и т. д.
Для краткой иллюстрации [того], что это такое: после процедур преобразования цифровой модели аналогового звука, которую мы видим в форматах wave или AIFF, к формату MP3 – после того, как произведены вот эти процедуры (маскирование, удаление тех звуков, которые не могут быть восприняты человеком) – звук на промежуточной стадии не очень комфортен для прослушивания, он носит на себе отпечаток купирования, слух человека, особенно музыканта, может ощущать дискомфорт, поэтому, чтобы спрятать огрехи на последней стадии, в цифровые форматы «подмешивается» шумовой сигнал низкого амплитудного уровня.
Это делается специальным алгоритмом. В принципе, можно проиллюстрировать это таким примером: если вы находитесь в какой-то комнате и в соседней комнате кто-то разговаривает, и вам это мешает, включите пылесос. Шум пылесоса является более низкочастотным сигналом по отношению к речи человека, а низкочастотные сигналы всегда маскируют высокочастотные сигналы, но не наоборот. Вы перестанете слышать назойливых собеседников. Примерно то же самое происходит и в цифровых форматах, на последней стадии после оцифровки происходит подмешивание шумового сигнала определенной амплитуды, определенного спектрального состава, это может быть разновидность белого шума.
Дмитрий: Хорошо, тогда давайте попробуем поговорить о тех случаях, когда мы можем утверждать, что все-таки что-то теряем, используя MP3 – не всегда он идеален для применения, не всегда он подходит, некоторый класс оборудования может позволить нам что-то большее.
Анатолий: Совершенно правильно, MP3, как формат для компактного хранения аудиоданных в компьютерной технике и как один из самых старых форматов, потихонечку, с течением времени, стал терять популярность. Почему? Ну [прежде всего], компьютерная техника увеличила свою производительность и объемы памяти, [а это значит, что] потребность в сжатии, купировании звуковых данных исчезла, нет такой напряженности – памяти у нас сейчас на современных компьютерах достаточно, производительность процессоров достаточна, поэтому мы можем слушать не сжатый цифровой звук.
Какие были предприняты в свое время шаги ухода от компактного ранения музыки? Прежде всего, появились конкурирующие форматы для сжатого хранения звука. Те, кто пользуются компьютерами компании Apple и планшетными компьютерами, смартфонами, айфонами, они знают, в каком формате продается музыка в Apple Store [iTunes] – если я не ошибаюсь, это MP4, да?
Анатолий: Кто-то скажет, что это тоже цифровой звук и тоже сжатый и что у него [также] есть недостатки. Ну да. Только он появился позже, чем MP3, работы по этому формату начались в где-то в 1997 году, то есть почти на 3-4 года позже [создания] MP3, значит, те разработчики, которые разрабатывали эту систему кодирования сжатого звука, учли проблемы и недостатки, которые были в предыдущих форматах, усовершенствовали [продукт].
К чему я привожу эти примеры: цифровой звук, возникнув на определенном этапе, при появлении компьютерных устройств прошел определенную эволюцию, эволюционировали форматы как несжатого хранения звуковых данных, так и форматы [хранения] сжатого звука. Современный способ кодирования звука в форматах MP3 или аналогичных достаточно совершенен.
Получив популярность на определенном этапе, сейчас [формат] фактически зафиксировался на определенной группе устройств: прежде всего на портативной технике мобильной связи – смартфонах, телефонах, плеерах и т. д. В силу малых габаритов, небольшой мощности, невысоких возможностей динамиков, встроенных в смартфоны, он органично вписался в эту структуру. Если говорить об аппаратуре серьезной, для домашнего прослушивания, в частности, Hi-Fi аппаратуре, то здесь, конечно, не всякий взыскательный слушатель согласится с тем, что цифровые форматы хранения аудиоданных в сжатой форме годятся.

Для тех, кто не приемлет цифровые форматы хранения данных в сжатой форме, у Аудиомании есть аналоговые решения. На фото – фрагмент инсталляции от Аудиомании
Анатолий: Это базовые характеристики любого аудиотракта современного компьютера, будь он настольный или портативный. Такие же характеристики (то есть разрядность процессоров) имеют и стандартные проигрыватели компакт-дисков. Не вдаваясь в подробности, следует сказать, что этот стандарт появился давно. Разрабатывали стандарт хранения аудиоданных такого рода (16 бит и 44 кГц) производители бытовой аудиоаппаратуры, которая у нас у всех очень популярна – Phillips, Sony, Toshiba. По мере развития компьютерной техники аудиокарты приобретали дополнительные возможности, в частности, увеличился ряд частот, на которых может работать аудиокарта – 48 кГц, 96 кГц, 192 кГЦ, разрядность процессора, который установлен на аудиокарте, тоже увеличилась – 16 бит, 24 бита…
Анатолий: И сейчас 32. Если говорить профессиональным языком, то частота 44 кГц это та необходимая частота, которая позволяет сохранить волновую форму звукового сигнала, например, музыкального произведения или голоса человека. Откуда возникло это число и почему аудиокарта должна работать на этой частоте? Был такой математик Котельников, который своей теоремой доказал эту границу технического устройства, которая позволяет оцифровать сигнал с достаточно высоким качеством.
Уместно привести такой пример: простейший звук, например, звук свирели и детской дудочки…форма его звукового сигнала похожа на синусоиду, скажем так. Что же такое 44 кГц? Это частота работы аудиокарты. Такой сигнал, попав в аудиокарту, будет разрезан моментально на 44 тысячи вертикальных полоcочек. Что мы получим в результате этой разрезки? Мы получим значение громкости сигнала в каждой точке времени – одной сорока четырех тысячной секунды.
Дмитрий: И теперь нам нужно все эти полоски зашифровать.
Анатолий: Теперь нам эти полоски нужно зашифровать и сохранить в компьютере. Как мы можем [их] зашифровать? Можно запомнить значение громкости в каждой полосочке. Ну вот здесь как раз уже и играет значение другая характеристика аудиокарты – ее разрядность. В частности, 16 бит. Что такое 16 бит? Компьютерщики говорят так: два в шестнадцатой степени.
Анатолий: Какое это число, 65 тысяч с копейками? Получается, что я могу использовать число от нуля до 65 536, если говорить точно, чтобы выразить высоту вот этой самой полосочки. Это будет какое-то число. В одном случае это будет 60 тысяч, в другом случае – 30 тысяч и т. д. [Значит], в данном случае мы за секунду времени получим таблицу, которая будет содержать 44 тысячи цифр, каждая из которых будет выражаться числом от нуля до 65 536. Вот эта таблица и будет являться несжатым звуковым файлом.
Дмитрий: Теперь мы работаем с этой таблицей дальше…
Анатолий: Что мы здесь видим? Что, если бы скорость работы аудиокарты была выше, [тогда], наверное, мы получили бы гораздо большее количество этих цифр, которое более точно описывало бы наш сигнал. Естественно, стремление разработчиков и производителей – приблизиться к истинной форме сигнала. Вот отсюда [происходит] стремление конструкторов техники увеличивать частоты. Год от года, так сказать, от одного класса устройств, к другому и т. д.
Это развитие привело к тому, что [начиная] с частоты 44 кГц потихоньку эти частоты увеличивались. Я применил неудачное слово «потихонечку», потому что на самом деле развитие было гораздо сложнее, использовались все частоты: и 32 кГц, и 24 кГц. Слушатель или кто-то любопытный может спросить: «А где эти частоты используются?» потому что явно, что звук [при использовании частот ниже 44кГц] будет грубее. Например, при передаче телесигналов в телефонной технике. Там нет необходимости очень точно описывать сигнал, а вот при передаче сложного музыкального сигнала, какой-то концертной партии, как оказалось, 44 кГц не удовлетворяют требованиям взыскательного слуха. Поэтому частотные характеристики карт неизменно, из поколения в поколение, увеличивались.
Чтобы закончить разговор на эту тему и не вдаваться в подробности, пожалуй, стоит привести такой пример – рождение HD-аудио, это был 2004 год, компания Intel разработала как раз в этот год спецификации HD-аудио, которые заключаются в следующих двух значениях: 32 бита и 192 кГц. Значит, после того, как были разработаны спецификации HD-аудио…что такое HD, как мы его расшифруем?
Дмитрий: High definition. Высокое разрешение.
Анатолий: Высокое разрешение, то есть это аудио высокого разрешения. Такой стандарт уже может быть базовым для очень качественной аудиоаппаратуры, для источников сигнала, которые, например, будут конкурировать, не побоюсь этого слова, с винилом. Чем закончилась история разработки HD аудио? Intel передал свои разработки трем компаниям-производителям интерфейсов, а потом, на основе этих интерфейсов, компании, которые производят аудиокодеки уже для конкретных технических устройств, начиная с Realtek и заканчивая Wolfson, разработали кодеки, каждый для своих цифровых процессоров.